

Cet article présente principalement la méthode de filtrage des données par pandas selon la combinaison de plusieurs colonnes. Il a une certaine valeur de référence. Maintenant, je le partage avec vous. Les amis dans le besoin peuvent s'y référer
. Parlons en images
Un fichier :

Pour Par exemple, je souhaite filtrer les données dont les trois colonnes "type de puits de conception", "type de puits mis en service" et "type de puits actuel" sont toutes 11. Les résultats sont les suivants :
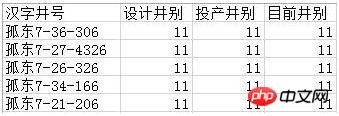
Bien sûr, les conditions de filtrage ici peuvent être librement ajustées en fonction des besoins de l'utilisateur. Le code est le suivant :
# -*- coding: utf-8 -*- """ Created on Wed Nov 29 10:46:31 2017 @author: wq """ import pandas as pd #input.csv是那个大文件,有很多很多行 df1 = pd.read_csv(u'input.csv', encoding='gbk') #加encoding=‘gbk'是因为文件中存在中文,不加可能出现乱码 #这里的筛选条件可以根据用户需要进行修改 outfile = df1[(df1[u'设计井别']=='11') & (df1[u'投产井别']=='11') &(df1[u'目前井别']=='11')] outfile.to_csv('outfile.csv', index=False, encoding='gbk')
Parfois, nous avons également l'exigence inverse et devons supprimer "Design Well". Catégorie", "Catégorie de puits de mise en service" et "Actuellement. Pour les lignes où les trois colonnes de données sont 11, l'effet est le suivant :

Le code est le suivant :
#input.csv是那个大文件,有很多很多行 df1 = pd.read_csv(u'input.csv', encoding='gbk') df2 = pd.read_csv(u'outfile.csv', encoding='gbk') #加encoding=‘gbk'是因为文件中存在中文,不加可能出现乱码 index = ~df1[u'汉字井号'].isin(df2[u'汉字井号']) df4 = df1[index] df4.to_csv('outfile1.csv', index=False, encoding='gbk')
Recommandations associées :
Méthode de sélection des lignes et des colonnes des échantillons de données pandas ,
Traitement des données Pandas, filtrage de base Données dans la ligne ou la colonne spécifiée
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Code écran bleu 0x000009c
Code écran bleu 0x000009c
 Que signifie bios ?
Que signifie bios ?
 qu'est-ce que le pissenlit
qu'est-ce que le pissenlit
 Comment ouvrir un fichier XML
Comment ouvrir un fichier XML
 Qu'est-ce qu'un concepteur d'interface utilisateur ?
Qu'est-ce qu'un concepteur d'interface utilisateur ?
 qu'est-ce que jpa
qu'est-ce que jpa
 Comment centrer la page Web dans Dreamweaver
Comment centrer la page Web dans Dreamweaver
 Comment créer une base de données dans MySQL
Comment créer une base de données dans MySQL
 Introduction aux caractéristiques de l'espace virtuel
Introduction aux caractéristiques de l'espace virtuel








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



