
 interface Web
js tutoriel
Comment implémenter le robot d'indexation Baidu à l'aide de la technologie de reconnaissance d'image Puppeteer
interface Web
js tutoriel
Comment implémenter le robot d'indexation Baidu à l'aide de la technologie de reconnaissance d'image Puppeteer
Comment implémenter le robot d'indexation Baidu à l'aide de la technologie de reconnaissance d'image Puppeteer
Cet article présente principalement l'exemple de reconnaissance d'image Node Puppeteer pour implémenter le robot d'indexation Baidu. L'éditeur pense que c'est plutôt bon, je vais donc le partager avec vous maintenant et le donner comme référence. Suivons l'éditeur pour y jeter un œil
J'ai déjà lu un article éclairant, qui présentait les techniques anti-crawler frontales de divers grands fabricants, mais comme le dit cet article, il n'existe pas d'anti-crawler à 100% crawler. Méthode Crawler, cet article présente une méthode simple pour contourner toutes ces méthodes anti-crawler frontales.
Le code suivant prend Baidu Index comme exemple. Le code a été intégré dans une bibliothèque de nœuds d'exploration Baidu Index : https://github.com/Coffcer/baidu-index-spider
remarque : veuillez ne pas abuser des robots d'exploration pour causer des problèmes aux autres
Stratégie anti-crawler de Baidu Index
Observez l'interface de Baidu Index. Les données d'index sont un graphique de tendance Lorsque la souris survole un certain jour, deux requêtes seront déclenchées et les résultats seront affichés dans la boîte flottante :
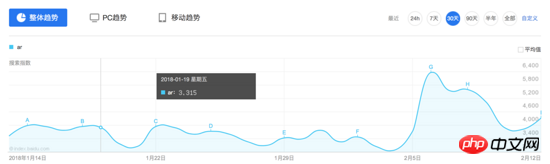
Suivant le général. idée, regardons d'abord le contenu de cette demande :
Demande 1 :
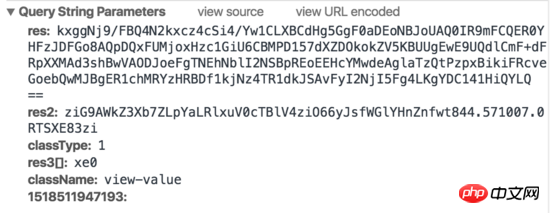
Demande 2 :

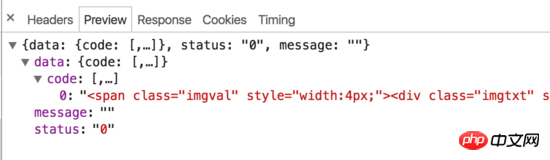
On peut constater que Baidu Index a en fait mis en œuvre certaines stratégies anti-crawler sur le front-end. Lorsque la souris se déplace sur le graphique, deux requêtes seront déclenchées, une requête renvoie un morceau de code HTML et une requête renvoie une image générée. Le code HTML ne contient pas de valeurs réelles, mais affiche les caractères correspondants sur l'image en définissant la largeur et la marge gauche. De plus, les paramètres de requête contiennent des paramètres tels que res et res1 que nous ne savons pas comment simuler, il est donc difficile d'explorer les données de l'index Baidu à l'aide de requêtes simulées conventionnelles ou de méthodes d'exploration HTML.
Idées de robots d'exploration
Comment percer la méthode anti-crawler de Baidu C'est en fait très simple, il suffit d'ignorer comment il combat les robots d'exploration. Il nous suffit de simuler les opérations de l'utilisateur, de capturer les valeurs requises et d'effectuer une reconnaissance d'image. Les étapes sont en gros :
Simuler la connexion
Ouvrir la page d'index
Déplacer la souris à la date spécifiée
Attendez la fin de la demande, interceptez la partie numérique de l'image
Reconnaissance d'image pour obtenir la valeur
Bouclez les étapes 3 à 5, obtenez la valeur correspondant à chaque date
Cette méthode peut théoriquement explorer le contenu de n'importe quel site Web. Ensuite, nous allons. implémentez le robot étape par étape. Nous l'utiliserons ci-dessous. La bibliothèque est arrivée :
-
node-tesseract
package tesseract, utilisé pour la reconnaissance d'images -
jimp
Recadrage d'images -
Installez Puppeteer et simulez les opérations des utilisateurs
Puppeteer est un outil d'automatisation de Chrome produit par l'équipe Google Chrome, utilisé pour contrôler les commandes d'exécution de Chrome. Vous pouvez simuler les opérations des utilisateurs, effectuer des tests automatisés, des robots d'exploration, etc. L'utilisation est très simple. Il existe de nombreux tutoriels d'introduction sur Internet. Vous saurez probablement comment l'utiliser après avoir lu cet article. Documentation API : https://github.com/GoogleChrome/puppeteer/blob/master/docs/api.md
Installation :
Puppeteer est en cours d'installation Chrome est automatiquement téléchargé pour assurer un fonctionnement normal. Cependant, les réseaux nationaux peuvent ne pas être en mesure de télécharger Chromium avec succès. Si le téléchargement échoue, vous pouvez utiliser cnpm pour l'installer, ou modifier l'adresse de téléchargement sur le miroir Taobao, puis l'installer :npm install --save puppeteer
npm config set PUPPETEER_DOWNLOAD_HOST=https://npm.taobao.org/mirrors npm install --save puppeteer
Implémentation
// npm
npm install --save puppeteer --ignore-scripts
// node
puppeteer.launch({ executablePath: '/path/to/Chrome' });Pour garder la mise en page soignée, seules les parties principales sont répertoriées ci-dessous, et le code impliqué. La partie sélecteur est remplacée par.... Pour le code complet, consultez le dépôt github en haut de l'article.
Ouvrez la page de l'index Baidu et simulez la connexionCe qui est fait ici est de simuler les opérations de l'utilisateur, de cliquer et de saisir étape par étape. Il n'est pas nécessaire de gérer le code de vérification de connexion. La gestion du code de vérification est un autre sujet. Si vous vous êtes connecté à Baidu localement, vous n'avez généralement pas besoin d'un code de vérification.
Simulez le déplacement de la souris pour obtenir les données requises
// 启动浏览器,
// headless参数如果设置为true,Puppeteer将在后台操作你Chromium,换言之你将看不到浏览器的操作过程
// 设为false则相反,会在你电脑上打开浏览器,显示浏览器每一操作。
const browser = await puppeteer.launch({headless:false});
const page = await browser.newPage();
// 打开百度指数
await page.goto(BAIDU_INDEX_URL);
// 模拟登陆
await page.click('...');
await page.waitForSelecto('...');
// 输入百度账号密码然后登录
await page.type('...','username');
await page.type('...','password');
await page.click('...');
await page.waitForNavigation();
console.log(':white_check_mark: 登录成功');Vous devez faire défiler la page jusqu'à la zone du graphique de tendance, puis déplacer la souris jusqu'à une certaine date et attendez la demande. A la fin, l'info-bulle affiche la valeur, puis prend une capture d'écran pour enregistrer l'image.
Capture d'écran
// 获取chart第一天的坐标
const position = await page.evaluate(() => {
const $image = document.querySelector('...');
const $area = document.querySelector('...');
const areaRect = $area.getBoundingClientRect();
const imageRect = $image.getBoundingClientRect();
// 滚动到图表可视化区域
window.scrollBy(0, areaRect.top);
return { x: imageRect.x, y: 200 };
});
// 移动鼠标,触发tooltip
await page.mouse.move(position.x, position.y);
await page.waitForSelector('...');
// 获取tooltip信息
const tooltipInfo = await page.evaluate(() => {
const $tooltip = document.querySelector('...');
const $title = $tooltip.querySelector('...');
const $value = $tooltip.querySelector('...');
const valueRect = $value.getBoundingClientRect();
const padding = 5;
return {
title: $title.textContent.split(' ')[0],
x: valueRect.x - padding,
y: valueRect.y,
width: valueRect.width + padding * 2,
height: valueRect.height
}
});Calculez les coordonnées de la valeur, prenez une capture d'écran et utilisez jimp pour recadrer l'image.
Reconnaissance d'images
await page.screenshot({ path: imgPath });
// 对图片进行裁剪,只保留数字部分
const img = await jimp.read(imgPath);
await img.crop(tooltipInfo.x, tooltipInfo.y, tooltipInfo.width, tooltipInfo.height);
// 将图片放大一些,识别准确率会有提升
await img.scale(5);
await img.write(imgPath);Ici, nous utilisons Tesseract pour la reconnaissance d'images. Tesseracts est un outil OCR open source de Google qui est utilisé pour identifier le texte dans les images. la précision peut être améliorée grâce à la formation. Il existe déjà un simple package de nœuds sur github : node-tesseract. Vous devez d'abord installer Tesseract et le définir sur les variables d'environnement. 实际上未经训练的Tesseracts识别起来会有少数几个错误,比如把9开头的数字识别成`3,这里需要通过训练去提升Tesseracts的准确率,如果识别过程出现的问题都是一样的,也可以简单通过正则去修复这些问题。 封装 实现了以上几点后,只需组合起来就可以封装成一个百度指数爬虫node库。当然还有许多优化的方法,比如批量爬取,指定天数爬取等,只要在这个基础上实现都不难了。 反爬虫 最后,如何抵挡这种爬虫呢,个人认为通过判断鼠标移动轨迹可能是一种方法。当然前端没有100%的反爬虫手段,我们能做的只是给爬虫增加一点难度。 上面是我整理给大家的,希望今后会对大家有帮助。 相关文章: 在Node.js中使用cheerio制作简单的网页爬虫(详细教程) 在React中使用Native如何实现自定义下拉刷新上拉加载的列表 Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!Tesseract.process(imgPath, (err, val) => {
if (err || val == null) {
console.error(':x: 识别失败:' + imgPath);
return;
}
console.log(val);const recognition = require('./src/recognition');
const Spider = require('./src/spider');
module.exports = {
async run (word, options, puppeteerOptions = { headless: true }) {
const spider = new Spider({
imgDir,
...options
}, puppeteerOptions);
// 抓取数据
await spider.run(word);
// 读取抓取到的截图,做图像识别
const wordDir = path.resolve(imgDir, word);
const imgNames = fs.readdirSync(wordDir);
const result = [];
imgNames = imgNames.filter(item => path.extname(item) === '.png');
for (let i = 0; i < imgNames.length; i++) {
const imgPath = path.resolve(wordDir, imgNames[i]);
const val = await recognition.run(imgPath);
result.push(val);
}
return result;
}
}

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Développement Java : comment implémenter la reconnaissance et le traitement d'images
Sep 21, 2023 am 08:39 AM
Développement Java : comment implémenter la reconnaissance et le traitement d'images
Sep 21, 2023 am 08:39 AM
Développement Java : Un guide pratique sur la reconnaissance et le traitement d'images Résumé : Avec le développement rapide de la vision par ordinateur et de l'intelligence artificielle, la reconnaissance et le traitement d'images jouent un rôle important dans divers domaines. Cet article expliquera comment utiliser le langage Java pour implémenter la reconnaissance et le traitement d'images, et fournira des exemples de code spécifiques. 1. Principes de base de la reconnaissance d'images La reconnaissance d'images fait référence à l'utilisation de la technologie informatique pour analyser et comprendre des images afin d'identifier des objets, des caractéristiques ou du contenu dans l'image. Avant d'effectuer la reconnaissance d'image, nous devons comprendre certaines techniques de base de traitement d'image, comme le montre la figure
 Comment utiliser Express pour gérer le téléchargement de fichiers dans un projet de nœud
Mar 28, 2023 pm 07:28 PM
Comment utiliser Express pour gérer le téléchargement de fichiers dans un projet de nœud
Mar 28, 2023 pm 07:28 PM
Comment gérer le téléchargement de fichiers ? L'article suivant vous expliquera comment utiliser Express pour gérer les téléchargements de fichiers dans le projet de nœud. J'espère qu'il vous sera utile !
 Une analyse approfondie de l'outil de gestion de processus de Node « pm2 »
Apr 03, 2023 pm 06:02 PM
Une analyse approfondie de l'outil de gestion de processus de Node « pm2 »
Apr 03, 2023 pm 06:02 PM
Cet article partagera avec vous l'outil de gestion de processus de Node "pm2" et expliquera pourquoi pm2 est nécessaire, comment installer et utiliser pm2, j'espère qu'il sera utile à tout le monde !
 Enseignement du nœud PI: Qu'est-ce qu'un nœud PI? Comment installer et configurer le nœud PI?
Mar 05, 2025 pm 05:57 PM
Enseignement du nœud PI: Qu'est-ce qu'un nœud PI? Comment installer et configurer le nœud PI?
Mar 05, 2025 pm 05:57 PM
Explication détaillée et guide d'installation pour les nœuds de pignon Cet article introduira l'écosystème de pignon en détail - nœuds PI, un rôle clé dans l'écosystème de pignon et fournir des étapes complètes pour l'installation et la configuration. Après le lancement du réseau de test de la blockchain pèse, les nœuds PI sont devenus une partie importante de nombreux pionniers participant activement aux tests, se préparant à la prochaine version du réseau principal. Si vous ne connaissez pas encore Pinetwork, veuillez vous référer à ce qu'est Picoin? Quel est le prix de l'inscription? PI Utilisation, exploitation minière et sécurité. Qu'est-ce que Pinetwork? Le projet Pinetwork a commencé en 2019 et possède sa pièce exclusive de crypto-monnaie PI. Le projet vise à en créer un que tout le monde peut participer
 Implémentation d'un système de reconnaissance d'images hautement concurrent utilisant Go et Goroutines
Jul 22, 2023 am 10:58 AM
Implémentation d'un système de reconnaissance d'images hautement concurrent utilisant Go et Goroutines
Jul 22, 2023 am 10:58 AM
Utiliser Go et Goroutines pour mettre en œuvre un système de reconnaissance d'images hautement concurrent Introduction : Dans le monde numérique d'aujourd'hui, la reconnaissance d'images est devenue une technologie importante. Grâce à la reconnaissance d'images, nous pouvons convertir des informations telles que des objets, des visages, des scènes, etc. dans les images en données numériques. Cependant, pour la reconnaissance de données d’images à grande échelle, la vitesse devient souvent un défi. Afin de résoudre ce problème, cet article présentera comment utiliser le langage Go et Goroutines pour implémenter un système de reconnaissance d'images à haute concurrence. Contexte : Aller à la langue
 Comment faire du traitement et de la reconnaissance d'images en Python
Oct 20, 2023 pm 12:10 PM
Comment faire du traitement et de la reconnaissance d'images en Python
Oct 20, 2023 pm 12:10 PM
Comment effectuer le traitement et la reconnaissance d'images en Python Résumé : La technologie moderne a fait du traitement et de la reconnaissance d'images un outil important dans de nombreux domaines. Python est un langage de programmation facile à apprendre et à utiliser doté de riches bibliothèques de traitement et de reconnaissance d'images. Cet article expliquera comment utiliser Python pour le traitement et la reconnaissance d'images, et fournira des exemples de code spécifiques. Traitement d'image : le traitement d'image est le processus consistant à effectuer diverses opérations et transformations sur des images pour améliorer la qualité de l'image, extraire des informations des images, etc. Bibliothèque PIL en Python (Pi
 Apprenez à utiliser la programmation Python pour réaliser l'amarrage de l'interface de reconnaissance d'image Baidu et réaliser la fonction de reconnaissance d'image.
Aug 25, 2023 pm 03:10 PM
Apprenez à utiliser la programmation Python pour réaliser l'amarrage de l'interface de reconnaissance d'image Baidu et réaliser la fonction de reconnaissance d'image.
Aug 25, 2023 pm 03:10 PM
Apprenez à utiliser la programmation Python pour implémenter l'amarrage de l'interface de reconnaissance d'image de Baidu et réaliser la fonction de reconnaissance d'image. Dans le domaine de la vision par ordinateur, la technologie de reconnaissance d'image est une technologie très importante. Baidu fournit une puissante interface de reconnaissance d'images grâce à laquelle nous pouvons facilement mettre en œuvre la classification, l'étiquetage, la reconnaissance faciale et d'autres fonctions d'images. Cet article vous apprendra comment utiliser le langage de programmation Python pour implémenter des fonctions de reconnaissance d'images en vous connectant à l'interface de reconnaissance d'images de Baidu. Tout d’abord, nous devons créer une application sur Baidu Developer Platform et obtenir
 Comment utiliser les expressions régulières Python pour la reconnaissance d'images
Jun 23, 2023 am 10:36 AM
Comment utiliser les expressions régulières Python pour la reconnaissance d'images
Jun 23, 2023 am 10:36 AM
En informatique, la reconnaissance d’images a toujours été un domaine important. Grâce à la reconnaissance d'image, nous pouvons laisser l'ordinateur reconnaître et analyser le contenu de l'image et le traiter. Python est un langage de programmation très populaire qui peut être utilisé dans de nombreux domaines, notamment la reconnaissance d’images. Cet article explique comment utiliser les expressions régulières Python pour la reconnaissance d'images. Les expressions régulières sont un outil de correspondance de modèles de texte utilisé pour rechercher du texte qui correspond à un modèle spécifique. Python a un module "re" intégré pour les expressions régulières
