

Opération multi-table de base de données MySQL
1. Clé étrangère
1. Qu'est-ce qu'une clé étrangère : Une clé étrangère fait référence au référencement d'une ou plusieurs colonnes dans une autre table. La colonne référencée doit avoir une contrainte de clé primaire. ou Contraintes d'unicité. Les clés étrangères sont utilisées pour établir et renforcer la connexion entre les données de deux tables.
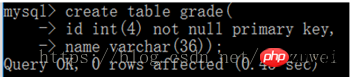
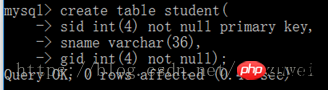
Le gid dans la table Student est l'identifiant de classe de l'élève, qui est l'identifiant de clé primaire dans la note. tableau. Ensuite, gid peut être utilisé comme clé étrangère pour la table student. La table référencée, c'est-à-dire la table grade, est la table maître ; la table qui fait référence à la clé étrangère, c'est-à-dire la table étudiant, est la table esclave, et les deux tables sont dans une relation maître-esclave. La table des étudiants peut utiliser gid pour relier les informations du tableau des notes, établissant ainsi une connexion entre les données des deux tableaux.
Après avoir introduit la clé étrangère, la colonne de clé étrangère ne peut insérer que la valeur qui existe dans la colonne de référence, et la valeur référencée de la colonne de référence ne peut pas être supprimée, ce qui garantit l'intégrité référentielle des données.
2. Ajouter des contraintes de clé étrangère à la table
Si vous souhaitez véritablement connecter les données de deux tables, vous devez ajouter des contraintes de clé étrangère à la table. Le format de syntaxe pour ajouter des contraintes de clé étrangère à une table est le suivant : modifier le nom de la table ajouter une contrainte FK_ID La clé étrangère (nom du champ de clé étrangère) fait référence au nom de la table de clé étrangère (nom du champ de clé primaire)
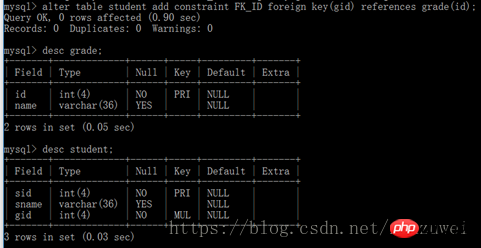
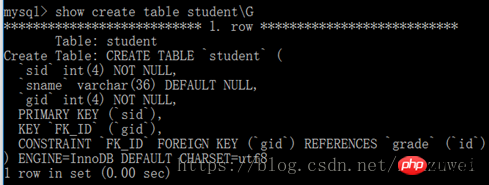
Lors de l'ajout de contraintes de clé étrangère à une table, certaines choses doivent être notées, comme suit :
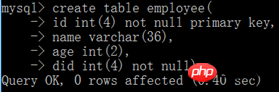
(1) La table à établir une clé étrangère doit être de type InnoDB, pas de table temporaire. Parce que seules les tables de type InnoDB dans MySQL prennent en charge les clés étrangères ;
(2) Lors de la définition des noms de clés étrangères, les guillemets ne peuvent pas être ajoutés, comme la contrainte « FK_ID » ou la contrainte « FK_ID », qui sont toutes deux fausses.
Lorsque les données de la table principale sont supprimées, les données de la table esclave doivent également être supprimées, sinon il y aura beaucoup de données inutiles sans signification. Mysql peut ajouter des clauses delete ou on update lors de la création de clés étrangères pour indiquer à la base de données comment éviter la génération de données inutiles. Le format de syntaxe spécifique est le suivant :
Modifier le nom de la table addconstraint La clé étrangère FK_ID (nom du champ de clé étrangère) fait référence au nom de la table externe (nom du champ de clé primaire
[on delete{cascade) ; | set null | no action | restrict}]
[on update{cascade | set null | no action restrict}]
La description spécifique de chaque paramètre dans l'instruction est celle indiquée dans le tableau suivant :
|
Description de la fonction | ||||||||||
| Cascade | Supprimer les clés contenant et supprimées Tous les enregistrements avec des relations de référence | ||||||||||
| Définir null | Modifiez tous les enregistrements contenant des références aux valeurs clés supprimées et remplacez-les par des valeurs nulles (ne peut pas être utilisé pour les champs marqués comme non nuls) | ||||||||||
| Aucune action | Aucune action | ||||||||||
| Restreindre | Rejeter la table principale pour supprimer ou modifier la colonne associée à la clé étrangère. (Il s'agit du paramètre par défaut et du paramètre le plus sûr lorsque les clauses on delete et on update ne sont pas définies) |
3. Supprimer les contraintes de clé étrangère : modifier le nom de la table, supprimer la clé étrangère nom de la clé étrangère ;

2. Fonctionnement de la table d'association
1. Relation d'association(1) Plusieurs-à-un : Dans leplusieurs-à- une relation de table, les clés étrangères doivent être construites du côté avec plus de et de , sinon cela entraînera une redondance des données.
(2) Plusieurs-à-plusieurs : comme l'horaire des étudiants et l'horaire des cours. Habituellement, afin de réaliser cette relation, une table intermédiaire (appelée table de jointure) doit être définie. Cette table aura deux clés étrangères, référençant respectivement le planning des cours et la table des étudiants. Dans une relation plusieurs-à-plusieurs, il faut noter que les deux clés étrangères reliant la table sont répétables, mais la relation entre les deux clés étrangères ne peut pas être répétée, donc les deux clés étrangères sont les mêmes que celles de la table. Clé primaire syndicale. (3) Un-à-un : Tout d'abord, il faut distinguer la relation maître-esclave. La table esclave nécessite l'existence de la table maître pour avoir du sens. table, la carte d'identité est la table esclave et la clé étrangère est établie dans la table esclave. Il convient de noter que cette relation n'est pas courante dans les bases de données, car les informations ainsi stockées sont généralement placées dans un tableau. Dans le développement réel, la relation d'association un-à-un peut être appliquée dans les aspects suivants. Ø Diviser un tableau avec plusieurs colonnes; Ø Isoler une partie d'un tableau pour des raisons de sécurité Ø Enregistrer les données temporaires et peut être supprimé sans effort Ce tableau supprime le données. 2. Ajout de données
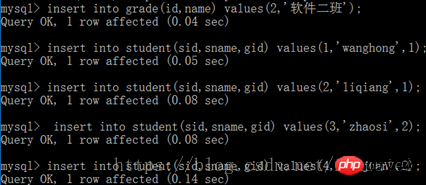
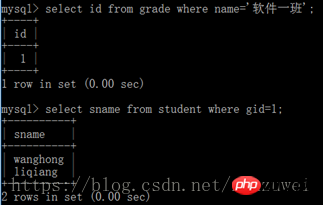
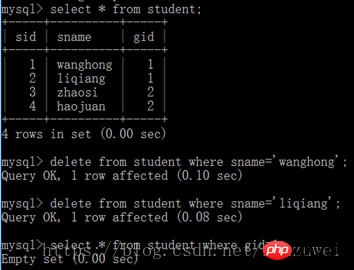



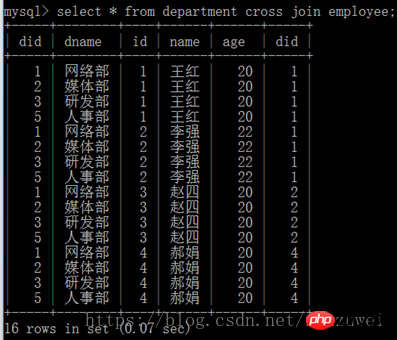
Sélectionnez le champ de requête de la table 1 [interne] rejoignez la table 2 sur la table 1. champ de relation = table 2. champ de relation
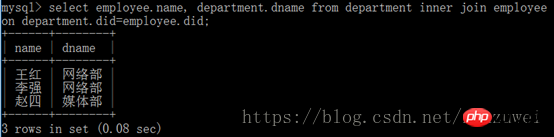
peut également être implémenté en utilisant les instructions conditionnelles Where Même fonctionnalité.
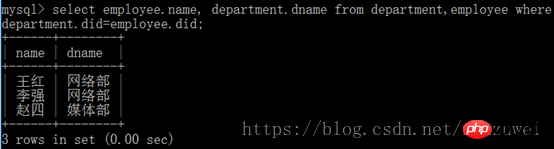
Bien que les résultats de requête de ces deux méthodes soient les mêmes, la jointure interne est une instruction de jointure interne, et où est une instruction de jugement conditionnel Vous pouvez ajouter d'autres conditions directement après. où. L'instruction de jointure interne ne peut pas.
#Si dans une requête de jointure, les deux tables impliquées sont la même table, ce type de requête est appelé requête d'auto-jointure. L'auto-jointure est un type particulier de jointure. Cela signifie que les tables connectées les unes aux autres sont physiquement la même table, mais logiquement divisée en deux tables. Par exemple, si vous souhaitez demander quels employés font partie du département de Wang Hong, vous pouvez le faire. utilisez la requête d'auto-jointure.

3. Jointure externe : Le tableau à gauche du mot-clé est appelé les coordonnées, et le mot à droite est appelé le tableau de droite
Sélectionnez le champ à interroger dans le tableau 1 gauche|droite [externe] jointure Tableau 2
Sur le tableau 1. Champ relationnel = Tableau 2. Champ relationnel où condition
(1) jointure gauche ( jointure gauche) : renvoie la table de gauche Tous les enregistrements et les enregistrements de la table de droite qui remplissent les conditions de jointure.
Si un enregistrement dans le tableau de gauche n'existe pas dans le tableau de droite, il sera affiché comme vide dans le tableau de droite.
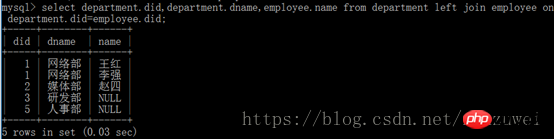
(2) Jointure à droite : renvoie tous les enregistrements de la table de droite et les enregistrements de la table de gauche qui remplissent les conditions de jointure.

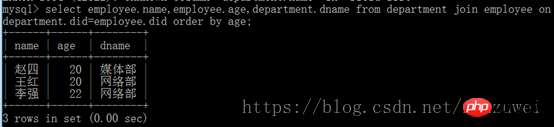
4. Requête de jointure conditionnelle composée
4. Sous-requête : fait référence à une instruction de requête imbriquée dans une autre requête A. dans une instruction de requête. Il peut être imbriqué dans une instruction select, select...into, insert...into et d'autres instructions. Lors de l'exécution d'une instruction de requête, les instructions de la sous-requête seront d'abord exécutées, puis les résultats renvoyés seront utilisés comme conditions de filtre pour la requête externe. Dans la sous-requête, vous pouvez généralement utiliser les opérateurs in, exist, any et all.
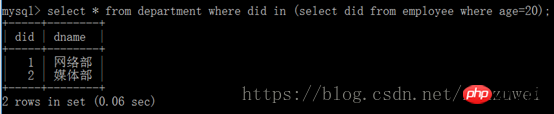
( 1) Sous-requête avec le mot-clé in : l'instruction de requête interne ne renvoie qu'une seule colonne de données et la valeur de cette colonne de données sera utilisée pour l'opération de comparaison par l'instruction de requête externe.
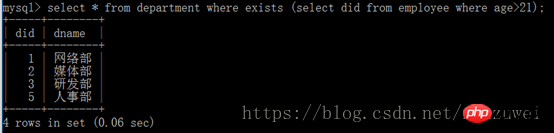
Par exemple : Interrogez le service où existent des employés âgés de 20 ans.
(2) Sous-requête avec le mot-clé exist : Le paramètre après le mot-clé exist peut être n'importe quelle sous-requête. La fonction de cette sous-requête est équivalente à un test. sera généré et seul True ou False sera renvoyé Lorsque la valeur de retour est True, la requête externe sera exécutée.
Dans l'exemple suivant, le résultat renvoyé par la sous-requête est True, donc l'instruction de requête externe sera exécutée, c'est-à-dire que toutes les informations du service sont interrogées. Il convient de noter que le mot-clé exist est plus efficace que le mot-clé in, donc dans le développement réel, en particulier lorsque la quantité de données est importante, il est recommandé d'utiliser le mot-clé exist.
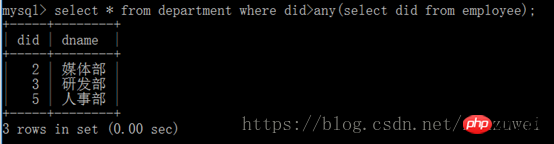
(3) Sous-requête avec n'importe quel mot-clé : any signifie que l'une des conditions est remplie, ce qui permet la création d'une expression pour comparer la liste de valeurs de retour de la sous-requête , Tant qu'une condition de comparaison dans la sous-requête interne est remplie, un résultat est renvoyé comme condition de requête externe.
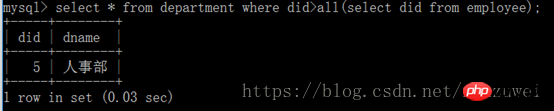
(4) Sous-requête avec all mot-clé : elle est similaire à n'importe quelle autre, sauf que les résultats renvoyés par la sous-requête avec all mot-clé doivent satisfaire toutes les requêtes internes en même temps. .
(5) Sous-requête avec opérateur de comparaison

Cet article explique le fonctionnement multi-table de la base de données MySQL, et plus Pour plus de contenu connexe, veuillez prêter attention au site Web chinois php.
Recommandations associées :
Sélecteur $ - comment encapsuler le DOM dans des objets jquery
Componentisation js native Développer un graphique carrousel simple exemple de code
barre de navigation animée CSS3 3D
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Comment récupérer les données après que SQL supprime les lignes
Apr 09, 2025 pm 12:21 PM
Comment récupérer les données après que SQL supprime les lignes
Apr 09, 2025 pm 12:21 PM
La récupération des lignes supprimées directement de la base de données est généralement impossible à moins qu'il n'y ait un mécanisme de sauvegarde ou de retour en arrière. Point clé: Rollback de la transaction: Exécutez Rollback avant que la transaction ne s'engage à récupérer les données. Sauvegarde: la sauvegarde régulière de la base de données peut être utilisée pour restaurer rapidement les données. Instantané de la base de données: vous pouvez créer une copie en lecture seule de la base de données et restaurer les données après la suppression des données accidentellement. Utilisez la déclaration de suppression avec prudence: vérifiez soigneusement les conditions pour éviter la suppression accidentelle de données. Utilisez la clause WHERE: Spécifiez explicitement les données à supprimer. Utilisez l'environnement de test: testez avant d'effectuer une opération de suppression.
