

Exploration des critiques musicales NetEase Cloud
# coding=gbk
import requests
import json
c='网易云爬虫实战一'
print(c)
music_url = 'https://music.163.com/#/song?id=28815250'
id = music_url.split('=')[1]
# print(id)
url = 'https://music.163.com/weapi/v1/resource/comments/R_SO_4_%s?csrf_token=7e19029fe28aa3e09cfe87e89d2e4eeb' %(id)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'Referer': 'https://music.163.com/song?id=%s' %(id),
'Origin': 'https://music.163.com',
}
formdata = {
'params': 'AoF/ZXuccqvtaCMCPHecFGVPfrbtDj4JFPJsaZ3tYn9J+r0NcnKPhZdVECDz/jM+1CpA+ByvAO2J9d44B/MG97WhjmxWkfo4Tm++AfyBgK11NnSbKsuQ5bxJR6yE0MyFhU8sPq7wb9DiUPFKs2ulw0GxwU/il1NS/eLrq+bbYikK/cyne90S/yGs6ldxpbcNd1yQTuOL176aBZXTJEcGkfbxY+mLKCwScAcCK1s3STo=',
'encSecKey': '365b4c31a9c7e2ddc002e9c42942281d7e450e5048b57992146633181efe83c1e26acbc8d84b988d746370d788b6ae087547bace402565cca3ad59ccccf7566b07d364aa1d5b2bbe8ccf2bc33e0f03182206e29c66ae4ad6c18cb032d23f1793420ceda05e796401f170dbdb825c20356d27f07870598b2798f8d344807ad6f2',
}
response = requests.post(url, headers = headers, data = formdata)
messages = json.loads(response.text)
data_list=[]
data={}
for message in messages['hotComments']:
data['nickname']=message['user']['nickname']
data['content']=message['content']
data_list.append(data)
data={}
#print(data_list)
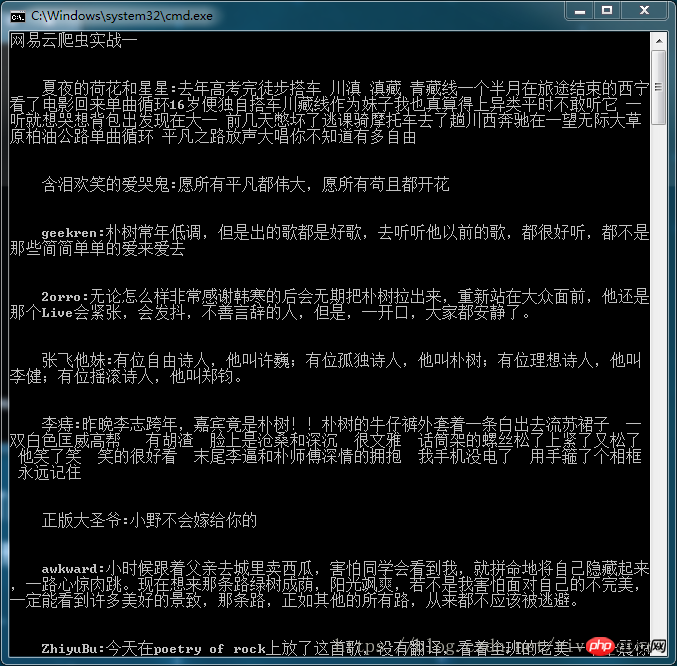
for i in data_list:
c = ' '+i['nickname']+':'+i['content']
print('\n\n'+c.replace('\n',''))
Résumé :
1. # coding=gbk" signifie que vous pouvez saisir des chaînes de texte dans l'éditeur de texte.
2. La fonction split() dans "id = music_url.split('=')[1]" signifie regrouper des éléments, dans cet exemple c'est "https://music.163 .com /#/song?id=”, “28815250”
3. Le texte HTML obtenu par le module de requêtes doit être converti en Python lisible à l'aide du json. Texte de la méthodeloads(), sinon une erreur sera signalée. Cela ne se produit pas dans le notebook Jupyter.
4. La fonction replace() peut supprimer des éléments de la chaîne. Dans cet exemple, le caractère de nouvelle ligne est remplacé par vide.
Le résultat final de l'affichage est le suivant :
Cet article présente le contenu pertinent de la revue musicale NetEase Cloud ramper, veuillez suivre le site Web chinois php.
Recommandations associées :
Classe de pagination PHP+MySQL simple
Deux constructeurs de tableaux arborescents sans récursion
Convertissez le HTML en Excel et réalisez des fonctions d'impression et de téléchargement
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1206
24
52
1206
24

 Récupération de métadonnées à l'aide de l'API du New York Times
Sep 02, 2023 pm 10:13 PM
Récupération de métadonnées à l'aide de l'API du New York Times
Sep 02, 2023 pm 10:13 PM
Introduction La semaine dernière, j'ai écrit une introduction sur le scraping de pages Web pour collecter des métadonnées, et j'ai mentionné qu'il était impossible de scraper le site Web du New York Times. Le paywall du New York Times bloque vos tentatives de collecte de métadonnées de base. Mais il existe un moyen de résoudre ce problème en utilisant l'API du New York Times. Récemment, j'ai commencé à créer un site Web communautaire sur la plateforme Yii, que je publierai dans un prochain tutoriel. Je souhaite pouvoir ajouter facilement des liens pertinents par rapport au contenu du site. Même si les utilisateurs peuvent facilement coller des URL dans des formulaires, fournir des informations sur le titre et la source prend du temps. Ainsi, dans le didacticiel d'aujourd'hui, je vais étendre le code de scraping que j'ai récemment écrit pour tirer parti de l'API du New York Times afin de collecter les titres lors de l'ajout d'un lien vers le New York Times. Rappelez-vous, je suis impliqué
 Comment explorer et traiter les données en appelant l'interface API dans un projet PHP ?
Sep 05, 2023 am 08:41 AM
Comment explorer et traiter les données en appelant l'interface API dans un projet PHP ?
Sep 05, 2023 am 08:41 AM
Comment explorer et traiter les données en appelant l'interface API dans un projet PHP ? 1. Introduction Dans les projets PHP, nous devons souvent explorer les données d'autres sites Web et traiter ces données. De nombreux sites Web fournissent des interfaces API et nous pouvons obtenir des données en appelant ces interfaces. Cet article explique comment utiliser PHP pour appeler l'interface API afin d'explorer et de traiter les données. 2. Obtenez l'URL et les paramètres de l'interface API Avant de commencer, nous devons obtenir l'URL de l'interface API cible et les paramètres requis.
 Résumé de l'expérience de développement Vue : conseils pour optimiser le référencement et l'exploration des moteurs de recherche
Nov 22, 2023 am 10:56 AM
Résumé de l'expérience de développement Vue : conseils pour optimiser le référencement et l'exploration des moteurs de recherche
Nov 22, 2023 am 10:56 AM
Résumé de l'expérience de développement Vue : Conseils pour optimiser le référencement et l'exploration des moteurs de recherche Avec le développement rapide d'Internet, le référencement des sites Web (SearchEngineOptimization, optimisation des moteurs de recherche) est devenu de plus en plus important. Pour les sites Web développés avec Vue, l’optimisation du référencement et de l’exploration des moteurs de recherche est cruciale. Cet article résumera une expérience de développement de Vue et partagera quelques conseils pour optimiser le référencement et l'exploration des moteurs de recherche. Utilisation de la technologie de prérendu Vue
 Comment utiliser Scrapy pour explorer les livres Douban et leurs notes et commentaires ?
Jun 22, 2023 am 10:21 AM
Comment utiliser Scrapy pour explorer les livres Douban et leurs notes et commentaires ?
Jun 22, 2023 am 10:21 AM
Avec le développement d’Internet, les gens ont de plus en plus recours à Internet pour obtenir des informations. Pour les amateurs de livres, Douban Books est devenu une plateforme indispensable. En outre, Douban Books propose également une multitude d'évaluations et de critiques de livres, permettant aux lecteurs de comprendre un livre de manière plus complète. Cependant, obtenir manuellement ces informations revient à chercher une aiguille dans une botte de foin. À l'heure actuelle, nous pouvons utiliser l'outil Scrapy pour explorer les données. Scrapy est un framework de robot d'exploration open source basé sur Python, qui peut nous aider efficacement
 Scrapy en action : exploration des données d'actualités Baidu
Jun 23, 2023 am 08:50 AM
Scrapy en action : exploration des données d'actualités Baidu
Jun 23, 2023 am 08:50 AM
Scrapy en action : exploration des données d'actualité de Baidu Avec le développement d'Internet, le principal moyen par lequel les gens obtiennent des informations est passé des médias traditionnels à Internet, et les gens comptent de plus en plus sur Internet pour obtenir des informations d'actualité. Pour les chercheurs ou les analystes, une grande quantité de données est nécessaire à l’analyse et à la recherche. Par conséquent, cet article explique comment utiliser Scrapy pour explorer les données d'actualités Baidu. Scrapy est un framework d'exploration Python open source qui peut analyser les données de sites Web rapidement et efficacement. Scrapy fournit de puissantes fonctions d'analyse et d'exploration de pages Web
 Comment utiliser la bibliothèque de classes PHP Goutte pour l'exploration Web et l'extraction de données ?
Aug 09, 2023 pm 02:16 PM
Comment utiliser la bibliothèque de classes PHP Goutte pour l'exploration Web et l'extraction de données ?
Aug 09, 2023 pm 02:16 PM
Comment utiliser la bibliothèque de classes PHPGoutte pour l'exploration Web et l'extraction de données ? Présentation : Dans le processus de développement quotidien, nous avons souvent besoin d'obtenir diverses données sur Internet, telles que les classements de films, les prévisions météorologiques, etc. L'exploration du Web est l'une des méthodes courantes pour obtenir ces données. Dans le développement PHP, nous pouvons utiliser la bibliothèque de classes Goutte pour implémenter des fonctions d'exploration Web et d'extraction de données. Cet article explique comment utiliser la bibliothèque de classes PHPGoutte pour explorer des pages Web et extraire des données, ainsi que joindre des exemples de code. Qu'est-ce que la goutte
 Scrapy en action : analyse des données du film Douban et classement de popularité
Jun 22, 2023 pm 01:49 PM
Scrapy en action : analyse des données du film Douban et classement de popularité
Jun 22, 2023 pm 01:49 PM
Scrapy est un framework Python open source permettant de récupérer des données rapidement et efficacement. Dans cet article, nous utiliserons Scrapy pour explorer les données et la popularité des films Douban. Préparation Tout d'abord, nous devons installer Scrapy. Vous pouvez installer Scrapy en tapant la commande suivante sur la ligne de commande : pipinstallscrapy Ensuite, nous créerons un projet Scrapy. Sur la ligne de commande, entrez la commande suivante : scrapystartproject
 Comment utiliser Scrapy pour explorer les chansons de Kugou Music ?
Jun 22, 2023 pm 10:59 PM
Comment utiliser Scrapy pour explorer les chansons de Kugou Music ?
Jun 22, 2023 pm 10:59 PM
Avec le développement d'Internet, la quantité d'informations sur Internet augmente et les utilisateurs doivent explorer les informations de différents sites Web pour effectuer diverses analyses et explorations. Scrapy est un framework d'exploration Python entièrement fonctionnel qui peut analyser automatiquement les données d'un site Web et les afficher sous une forme structurée. Kugou Music est l'une des plateformes de musique en ligne les plus populaires. Ci-dessous, je vais vous présenter comment utiliser Scrapy pour explorer les informations sur les chansons de Kugou Music. 1. Installer ScrapyScrapy est un framework basé sur le langage Python, donc
