
Je pense que la concurrence est familière à tout le monde.Cet article vous présente principalement les informations pertinentes sur l'utilisation d'async et d'enterproxy pour contrôler le nombre de concurrence.L'article le présente en détail à travers un exemple de code, ce qui est d'une certaine importance pour l'étude de chacun. ou travailler. La valeur d'apprentissage de référence, les amis qui en ont besoin, veuillez étudier ensemble ci-dessous.
Parlons de concurrence et de parallélisme
La concurrence, dans le système d'exploitation, signifie que plusieurs programmes sont démarrés dans un laps de temps entre l'exécution et à la fin, ces programmes s'exécutent tous sur le même processeur, mais un seul programme s'exécute sur le processeur à tout moment.
La concurrence est quelque chose que nous mentionnons souvent. Qu'il s'agisse d'un serveur Web ou d'une application, la concurrence est partout dans le système d'exploitation, elle fait référence à plusieurs programmes dans un laps de temps entre le démarrage et l'exécution, et ces programmes. tous fonctionnent sur le même processeur et un seul programme s'exécute sur le processeur à tout moment. De nombreux sites Web ont des limites sur le nombre de connexions simultanées, donc lorsque les requêtes sont envoyées trop rapidement, la valeur de retour sera vide ou une erreur sera signalée. De plus, certains sites Web peuvent bloquer votre IP car vous envoyez trop de connexions simultanées et pensez que vous faites des requêtes malveillantes.
Comparé à la concurrence, le parallélisme peut être très inconnu. Le parallélisme fait référence à un groupe de programmes s'exécutant à une vitesse indépendante et asynchrone, qui n'est pas égale au chevauchement dans le temps (se produisant au même moment). Les cœurs peuvent être implémentés en augmentant le nombre de cœurs de processeur. Les programmes (tâches) sont exécutés simultanément. C'est vrai, le parallélisme permet d'effectuer plusieurs tâches simultanément
Utiliser enterproxy pour contrôler le nombre de simultanéités
enterproxy est un outil qui Pu Lingda a le plus contribué à , provoquant un changement dans la pensée de la programmation basée sur les événements, utilisant le mécanisme d'événements pour découpler la logique métier complexe, résolvant les critiques concernant le couplage des fonctions de rappel, transformant l'attente série en attente parallèle et améliorant l'efficacité de l'exécution. dans des scénarios de collaboration multi-asynchrones
Comment utiliser enterproxy pour contrôler le nombre de simultanéités ? Habituellement, si nous n'utilisons pas enterproxy et les compteurs faits maison, nous récupérons trois sources :
Cette imbrication profonde, de manière sérielle
var render = function (template, data) {
_.template(template, data);
};
$.get("template", function (template) {
// something
$.get("data", function (data) {
// something
$.get("l10n", function (l10n) {
// something
render(template, data, l10n);
});
});
});Supprimer cette imbrication profonde dans le passé De manière conventionnelle, nous maintenons un compteur par nous-mêmes
(function(){
var count = 0;
var result = {};
$.get('template',function(data){
result.data1 = data;
count++;
handle();
})
$.get('data',function(data){
result.data2 = data;
count++;
handle();
})
$.get('l10n',function(data){
result.data3 = data;
count++;
handle();
})
function handle(){
if(count === 3){
var html = fuck(result.data1,result.data2,result.data3);
render(html);
}
}
})();Ici, enterproxy peut jouer le rôle de ce compteur. Il vous aide à gérer si ces opérations asynchrones sont terminées, il appellera automatiquement la fonction de traitement que vous fournissez et. transmettre les données capturées en tant que paramètres
var ep = new enterproxy();
ep.all('data_event1','data_event2','data_event3',function(data1,data2,data3){
var html = fuck(data1,data2,data3);
render(html);
})
$.get('http:example1',function(data){
ep.emit('data_event1',data);
})
$.get('http:example2',function(data){
ep.emit('data_event2',data);
})
$.get('http:example3',function(data){
ep.emit('data_event3',data);
})enterproxy fournit également les API requises pour de nombreux autres scénarios. Vous pouvez apprendre cette API enterproxy par vous-même
Utiliser async pour contrôler le. nombre de concurrence
Si nous avons 40 requêtes à envoyer, de nombreux sites Web peuvent échouer car vous envoyez trop de connexions simultanées. Vous faites une requête malveillante et votre IP sera bloquée.
Nous devons donc toujours contrôler le nombre de concurrence, puis explorer lentement ces 40 liens.
Utilisez mapLimit en asynchrone pour contrôler le nombre de simultanéités à 5 et ne capturer que 5 liens à la fois.
async.mapLimit(arr, 5, function (url, callback) {
// something
}, function (error, result) {
console.log("result: ")
console.log(result);
})Nous devons d'abord savoir ce qu'est la simultanéité, pourquoi nous devons limiter le nombre de simultanéités et quelles solutions sont disponibles. Ensuite, vous pouvez accéder à la documentation pour voir comment utiliser l'API. La documentation asynchrone est un excellent moyen d'apprendre ces syntaxes.
Simulez un ensemble de données. Les données renvoyées ici sont fausses et le délai de retour est aléatoire.
var concurreyCount = 0;
var fetchUrl = function(url,callback){
// delay 的值在 2000 以内,是个随机的整数 模拟延时
var delay = parseInt((Math.random()* 10000000) % 2000,10);
concurreyCount++;
console.log('现在并发数是 ' , concurreyCount , ' 正在抓取的是' , url , ' 耗时' + delay + '毫秒');
setTimeout(function(){
concurreyCount--;
callback(null,url + ' html content');
},delay);
}
var urls = [];
for(var i = 0;i<30;i++){
urls.push('http://datasource_' + i)
}Ensuite, nous utilisons async.mapLimit pour explorer simultanément et obtenir les résultats.
async.mapLimit(urls,5,function(url,callback){
fetchUrl(url,callbcak);
},function(err,result){
console.log('result: ');
console.log(result);
})La simulation est extraite de Alsotang
Après avoir exécuté la sortie, les résultats suivants sont obtenus
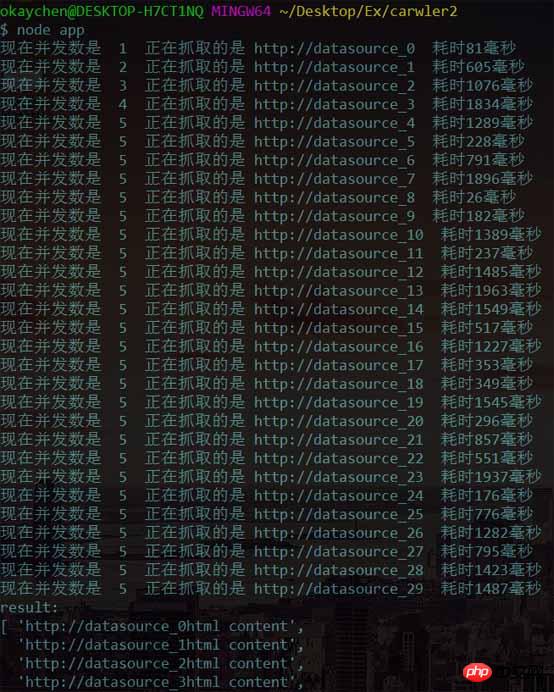
Nous avons constaté que le le nombre de concurrence passe de 1, mais lorsqu'il atteint 5, il cesse d'augmenter. Lorsqu'il y a des tâches, continuez à explorer et le nombre de connexions simultanées est toujours contrôlé à 5.
Complétez le système d'exploration simple du nœud
Parce que la concurrence contrôlée par eventproxy est utilisée dans l'exemple du didacticiel "le nœud inclut l'enseignement mais pas la réunion " Par Alsotang senior Quantity, complétons un simple robot d'exploration de nœuds qui utilise l'asynchrone pour contrôler le nombre de concurrences.
La cible du crawl est la page d'accueil de ce site Web (protection manuelle du visage)
Dans la première étape, nous devons utiliser les modules suivants :
url : utilisé pour l'analyse des url, ici url.resolve() est utilisé pour générer un nom de domaine légal
async : un module pratique qui fournit des fonctions puissantes et un travail JavaScript asynchrone
cheerio : une implémentation de base jQuery rapide et flexible spécialement personnalisée pour le serveur
superagent : une demande client très pratique dans le module Agent nodejs
Installez le module dépendant via npm
La deuxième étape consiste à introduire le module dépendant via require et à déterminer l'URL de l'objet d'exploration :
var url = require("url");
var async = require("async");
var cheerio = require("cheerio");
var superagent = require("superagent");
var baseUrl = 'http://www.chenqaq.com';Étape 3 : utilisez superagent pour demander l'URL cible et utilisez cheerio pour traiter baseUrl afin d'obtenir l'URL du contenu cible, et enregistrez-la dans le tableau arr
superagent.get(baseUrl)
.end(function (err, res) {
if (err) {
return console.error(err);
}
var arr = [];
var $ = cheerio.load(res.text);
// 下面和jQuery操作是一样一样的..
$(".post-list .post-title-link").each(function (idx, element) {
$element = $(element);
var _url = url.resolve(baseUrl, $element.attr("href"));
arr.push(_url);
});
// 验证得到的所有文章链接集合
output(arr);
// 第四步:接下来遍历arr,解析每一个页面需要的信息
})Nous avons besoin une fonction pour vérifier la capture L'objet url obtenu est très simple Nous avons seulement besoin d'une fonction pour parcourir arr et l'imprimer :
function output(arr){
for(var i = 0;i<arr.length;i++){
console.log(arr[i]);
}
}第四步:我们需要遍历得到的URL对象,解析每一个页面需要的信息。
这里就需要用到async控制并发数量,如果你上一步获取了一个庞大的arr数组,有多个url需要请求,如果同时发出多个请求,一些网站就可能会把你的行为当做恶意请求而封掉你的ip
async.mapLimit(arr,3,function(url,callback){
superagent.get(url)
.end(function(err,mes){
if(err){
console.error(err);
console.log('message info ' + JSON.stringify(mes));
}
console.log('「fetch」' + url + ' successful!');
var $ = cheerio.load(mes.text);
var jsonData = {
title:$('.post-card-title').text().trim(),
href: url,
};
callback(null,jsonData);
},function(error,results){
console.log('results ');
console.log(results);
})
})得到上一步保存url地址的数组arr,限制最大并发数量为3,然后用一个回调函数处理 「该回调函数比较特殊,在iteratee方法中一定要调用该回调函数,有三种方式」
callback(null) 调用成功
callback(null,data) 调用成功,并且返回数据data追加到results
callback(data) 调用失败,不会再继续循环,直接到最后的callback
好了,到这里我们的node简易的小爬虫就完成了,来看看效果吧

嗨呀,首页数据好少,但是成功了呢。
参考资料
Node.js 包教不包会 - alsotang
enterproxy
async
async Documentation
上面是我整理给大家的,希望今后会对大家有帮助。
相关文章:
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



