
 base de données
tutoriel mysql
Une brève analyse de l'utilisation de concat et group_concat dans MySQL
base de données
tutoriel mysql
Une brève analyse de l'utilisation de concat et group_concat dans MySQL
Une brève analyse de l'utilisation de concat et group_concat dans MySQL
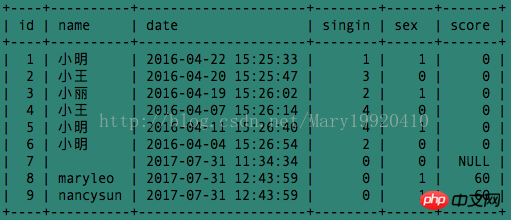
Les exemples utilisés dans cet article sont tous exécutés sous la table de base de données tt2 suivante :
1. Fonction concat()
1. Fonction : Concaténer plusieurs chaînes en une seule chaîne.
2. Syntaxe : concat(str1, str2,...)
Le résultat de retour est la chaîne générée par les paramètres de connexion. Si un paramètre est nul, la valeur de retour est nulle.
3. Exemple :
Exemple 1 : sélectionnez concat (id, nom, score) comme information à partir de tt2 ;

Il y a une ligne au milieu qui est nulle car la valeur de score d'une ligne dans la table tt2 est nulle.
Exemple 2 : Dans le résultat de l'exemple 1, la combinaison des trois champs id, name et score n'a pas de séparateur On peut ajouter une virgule comme séparateur :

Cela semble beaucoup plus agréable à regarder~~
Mais il est beaucoup plus difficile de saisir l'instruction SQL. Vous devez saisir deux fois des virgules pour trois champs. . S'il y a 10 champs, vous devez saisir des virgules neuf fois... C'est si compliqué. Existe-t-il un moyen simple ? ——Alors concat_ws(), qui peut spécifier le séparateur entre les paramètres, est là ! ! !
2. Fonction concat_ws()
1. Fonction : Identique à concat(), concaténer plusieurs chaînes en une chaîne, mais vous pouvez spécifier le séparateur à la fois ~ (concat_ws est concat avec le séparateur)
2 Syntaxe : concat_ws(separator, str1, str2, ...)
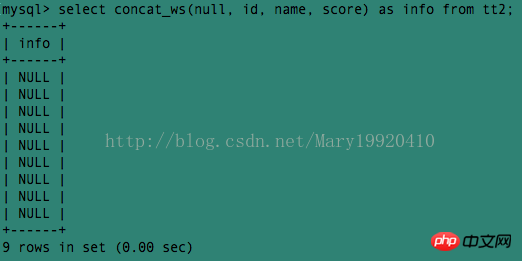
Explication : le paramètre du chapitre un spécifie le délimiteur. Il convient de noter que le séparateur ne peut pas être nul. S'il est nul, le résultat renvoyé sera nul.
3. Exemple :
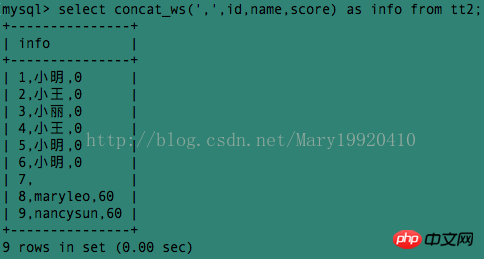
Exemple 3 : Nous utilisons concat_ws() pour spécifier le séparateur sous forme de virgule pour obtenir le même effet que l'exemple 2 :
Exemple 4 : Spécifiez le séparateur comme nul, et tous les résultats deviennent nuls :
3. Fonction group_concat()
Préface : dans une instruction de requête avec group by, le champ spécifié par select est soit inclus après l'instruction group by comme base de regroupement, soit il est inclus dans la fonction d’agrégation. (Pour en savoir plus sur Group By, veuillez cliquer sur : Une brève analyse de l'utilisation de Group By dans SQL).
Exemple 5 :
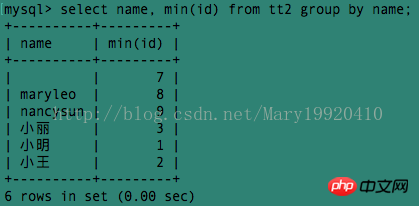
Cet exemple interroge le plus petit identifiant parmi les personnes portant le même nom. Que se passe-t-il si nous voulons interroger toutes les identités des personnes portant le même nom ?
Bien sûr, nous pouvons interroger comme ceci :
Exemple 6 :
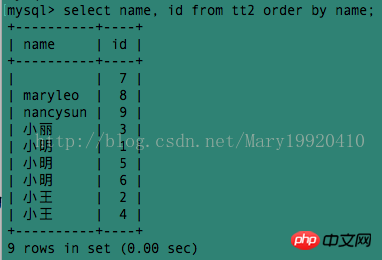
Mais si le même nom apparaît plusieurs fois, cela semble très peu intuitif. Existe-t-il un moyen plus intuitif permettant à chaque nom d'apparaître une seule fois, tout en affichant également les identifiants de toutes les personnes portant le même nom ? ——Utilisez group_concat()
1. Fonction : concatène les valeurs du même groupe généré par group by et renvoie un résultat de chaîne.
2. Syntaxe : group_concat([distinct] Champ à connecter [ordre par tri du champ asc/desc ] [separator 'separator'] )
Explication : Les doublons peuvent être éliminés en utilisant distinct Valeur ; si vous souhaitez trier les valeurs dans le résultat, vous pouvez utiliser la clause order by ; est une valeur de chaîne, qui est par défaut une virgule.
3. Exemple :
Exemple 7 : Utilisez group_concat() et group by pour afficher les numéros d'identification des personnes portant le même nom :

Exemple 8 : Triez les numéros d'identification ci-dessus de grand à petit et utilisez '_' comme séparateur :

Exemple 9 : Le requête ci-dessus Affiche tous les identifiants de chaque groupe regroupés par nom. Ensuite, nous devons interroger l'identifiant et le score de tous les groupes regroupés par nom :

Cet article analyse brièvement l'utilisation de concat et group_concat dans MySQL. Pour plus de contenu connexe, veuillez. faites attention au réseau chinois php.
Recommandations associées :
Introduction à l'outil de gestion graphique MySQL
Explications associées des fonctions de base des procédures stockées MySQL
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1359
1359
 52
52

 Intégration RDS MySQL avec Redshift Zero ETL
Apr 08, 2025 pm 07:06 PM
Intégration RDS MySQL avec Redshift Zero ETL
Apr 08, 2025 pm 07:06 PM
Simplification de l'intégration des données: AmazonrDSMysQL et l'intégration Zero ETL de Redshift, l'intégration des données est au cœur d'une organisation basée sur les données. Les processus traditionnels ETL (extrait, converti, charge) sont complexes et prennent du temps, en particulier lors de l'intégration de bases de données (telles que AmazonrDSMysQL) avec des entrepôts de données (tels que Redshift). Cependant, AWS fournit des solutions d'intégration ETL Zero qui ont complètement changé cette situation, fournissant une solution simplifiée et à temps proche pour la migration des données de RDSMySQL à Redshift. Cet article plongera dans l'intégration RDSMYSQL ZERO ETL avec Redshift, expliquant comment il fonctionne et les avantages qu'il apporte aux ingénieurs de données et aux développeurs.
 L'optimisation des requêtes dans MySQL est essentielle pour améliorer les performances de la base de données, en particulier lorsqu'elle traite avec de grands ensembles de données
Apr 08, 2025 pm 07:12 PM
L'optimisation des requêtes dans MySQL est essentielle pour améliorer les performances de la base de données, en particulier lorsqu'elle traite avec de grands ensembles de données
Apr 08, 2025 pm 07:12 PM
1. Utilisez l'index correct pour accélérer la récupération des données en réduisant la quantité de données numérisées SELECT * FROMMLOYEESEESHWHERELAST_NAME = 'SMITH'; Si vous recherchez plusieurs fois une colonne d'une table, créez un index pour cette colonne. If you or your app needs data from multiple columns according to the criteria, create a composite index 2. Avoid select * only those required columns, if you select all unwanted columns, this will only consume more server memory and cause the server to slow down at high load or frequency times For example, your table contains columns such as created_at and updated_at and timestamps, and then avoid selecting * because they do not require inefficient query se
 La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé primaire MySQL ne peut pas être vide car la clé principale est un attribut de clé qui identifie de manière unique chaque ligne dans la base de données. Si la clé primaire peut être vide, l'enregistrement ne peut pas être identifié de manière unique, ce qui entraînera une confusion des données. Lorsque vous utilisez des colonnes entières ou des UUIdes auto-incrémentales comme clés principales, vous devez considérer des facteurs tels que l'efficacité et l'occupation de l'espace et choisir une solution appropriée.
 MySQL peut-il gérer plusieurs connexions
Apr 08, 2025 pm 03:51 PM
MySQL peut-il gérer plusieurs connexions
Apr 08, 2025 pm 03:51 PM
MySQL peut gérer plusieurs connexions simultanées et utiliser le multi-threading / multi-processus pour attribuer des environnements d'exécution indépendants à chaque demande client pour s'assurer qu'ils ne sont pas dérangés. Cependant, le nombre de connexions simultanées est affectée par les ressources système, la configuration MySQL, les performances de requête, le moteur de stockage et l'environnement réseau. L'optimisation nécessite la prise en compte de nombreux facteurs tels que le niveau de code (rédaction de SQL efficace), le niveau de configuration (ajustement max_connections), niveau matériel (amélioration de la configuration du serveur).
 Impossible de se connecter à MySQL en tant que racine
Apr 08, 2025 pm 04:54 PM
Impossible de se connecter à MySQL en tant que racine
Apr 08, 2025 pm 04:54 PM
Les principales raisons pour lesquelles vous ne pouvez pas vous connecter à MySQL en tant que racines sont des problèmes d'autorisation, des erreurs de fichier de configuration, des problèmes de mot de passe incohérents, des problèmes de fichiers de socket ou une interception de pare-feu. La solution comprend: vérifiez si le paramètre Bind-Address dans le fichier de configuration est configuré correctement. Vérifiez si les autorisations de l'utilisateur racine ont été modifiées ou supprimées et réinitialisées. Vérifiez que le mot de passe est précis, y compris les cas et les caractères spéciaux. Vérifiez les paramètres et les chemins d'autorisation du fichier de socket. Vérifiez que le pare-feu bloque les connexions au serveur MySQL.
 mysql s'il faut changer la table de verrouillage de table
Apr 08, 2025 pm 05:06 PM
mysql s'il faut changer la table de verrouillage de table
Apr 08, 2025 pm 05:06 PM
Lorsque MySQL modifie la structure du tableau, les verrous de métadonnées sont généralement utilisés, ce qui peut entraîner le verrouillage du tableau. Pour réduire l'impact des serrures, les mesures suivantes peuvent être prises: 1. Gardez les tables disponibles avec le DDL en ligne; 2. Effectuer des modifications complexes en lots; 3. Opérez pendant les périodes petites ou hors pointe; 4. Utilisez des outils PT-OSC pour obtenir un contrôle plus fin.
 Puis-je installer mysql sur Windows 7
Apr 08, 2025 pm 03:21 PM
Puis-je installer mysql sur Windows 7
Apr 08, 2025 pm 03:21 PM
Oui, MySQL peut être installé sur Windows 7, et bien que Microsoft ait cessé de prendre en charge Windows 7, MySQL est toujours compatible avec lui. Cependant, les points suivants doivent être notés lors du processus d'installation: téléchargez le programme d'installation MySQL pour Windows. Sélectionnez la version appropriée de MySQL (communauté ou entreprise). Sélectionnez le répertoire d'installation et le jeu de caractères appropriés pendant le processus d'installation. Définissez le mot de passe de l'utilisateur racine et gardez-le correctement. Connectez-vous à la base de données pour les tests. Notez les problèmes de compatibilité et de sécurité sur Windows 7, et il est recommandé de passer à un système d'exploitation pris en charge.
 MySQL peut-il fonctionner sur Android
Apr 08, 2025 pm 05:03 PM
MySQL peut-il fonctionner sur Android
Apr 08, 2025 pm 05:03 PM
MySQL ne peut pas fonctionner directement sur Android, mais il peut être implémenté indirectement en utilisant les méthodes suivantes: à l'aide de la base de données légère SQLite, qui est construite sur le système Android, ne nécessite pas de serveur distinct et a une petite utilisation des ressources, qui est très adaptée aux applications de périphériques mobiles. Connectez-vous à distance au serveur MySQL et connectez-vous à la base de données MySQL sur le serveur distant via le réseau pour la lecture et l'écriture de données, mais il existe des inconvénients tels que des dépendances de réseau solides, des problèmes de sécurité et des coûts de serveur.
