

Il existe de grandes différences entre le clustering, la distribution et l'équilibrage de charge en PHP. Dans l'article suivant, je vais vous donner une description détaillée des différences spécifiques entre le clustering, la distribution et l'équilibrage de charge. Sans plus tarder, jetons un coup d'œil.
Les clusters d'ordinateurs sont connectés via un ensemble de logiciels et/ou de matériel informatique faiblement intégrés pour collaborer très étroitement pour terminer le travail informatique. Dans un sens, ils peuvent être considérés comme un ordinateur. Les ordinateurs individuels d'un système en cluster sont généralement appelés nœuds et sont généralement connectés via un réseau local, mais d'autres connexions sont possibles. Les ordinateurs en cluster sont souvent utilisés pour améliorer la vitesse de calcul et/ou la fiabilité d'un seul ordinateur. En général, les ordinateurs en cluster sont beaucoup plus rentables que les ordinateurs isolés, tels que les postes de travail ou les supercalculateurs.
Par exemple, une seule opération lourde est distribuée à plusieurs périphériques nœuds pour un traitement parallèle. Une fois le traitement de chaque périphérique nœud terminé, les résultats sont résumés et renvoyés à l'utilisateur. La capacité de traitement du système est considérablement améliorée. Généralement divisé en plusieurs types :
Cluster haute disponibilité : signifie généralement que lorsqu'un nœud du cluster tombe en panne, les tâches qu'il contient seront automatiquement transférées vers d'autres nœuds normaux. Cela signifie également qu'un nœud du cluster peut être maintenu hors ligne puis remis en ligne. Ce processus n'affecte pas le fonctionnement de l'ensemble du cluster.
Cluster d'équilibrage de charge : lorsqu'un cluster d'équilibrage de charge est en cours d'exécution, il répartit généralement la charge de travail sur un ensemble de serveurs à l'arrière En fin de compte, des performances élevées et une haute disponibilité de l'ensemble du système peuvent être obtenues.
Cluster de calcul haute performance : le cluster de calcul haute performance améliore la puissance de calcul en distribuant les tâches informatiques aux différents nœuds informatiques du cluster, donc principalement utilisé dans le domaine du calcul scientifique.
Cluster : La même entreprise est déployée sur plusieurs serveurs. Distribué : une entreprise est divisée en plusieurs sous-entreprises, ou il s'agit d'entreprises différentes et déployées sur différents serveurs.
En termes simples, la distribution améliore l'efficacité en raccourcissant le temps d'exécution d'une seule tâche, tandis que le clustering améliore l'efficacité en augmentant le nombre de tâches exécutées par unité de temps. Par exemple : prenez Sina.com, s'il y a plus de personnes qui le visitent, il peut créer un cluster, mettre un serveur d'équilibrage à l'avant et plusieurs serveurs à l'arrière pour réaliser la même activité. S'il y a un accès professionnel, le Le serveur de réponse verra quel serveur n'est pas fortement chargé. S'il est lourd, il sera attribué à celui qui terminera la tâche. Si un serveur s'effondre, d'autres serveurs peuvent intervenir. Chaque nœud distribué fournit des services différents. Si un nœud s'effondre, l'entreprise peut échouer.
Avec l'augmentation du volume d'activité, le nombre de visites et le trafic de données dans chaque partie centrale du réseau existant ont a augmenté rapidement. Sa puissance de traitement et son intensité de calcul ont également augmenté en conséquence, ce qui rend impossible pour un seul serveur de le supporter. Dans ce cas, si vous jetez l'équipement existant et effectuez de nombreuses mises à niveau matérielles, cela entraînera un gaspillage des ressources existantes, et si vous faites face à la prochaine augmentation du volume d'affaires, cela entraînera des coûts élevés pour une autre mise à niveau matérielle. Les investissements en termes de coûts, même les équipements les plus performants, ne peuvent pas répondre aux besoins de la croissance actuelle du volume d'affaires.
La technologie d'équilibrage de charge virtualise les ressources d'application de plusieurs serveurs réels sur le backend en un serveur d'applications hautes performances en définissant une adresse IP de serveur virtuel (VIP). Grâce à l'algorithme d'équilibrage de charge, la demande de l'utilisateur est transmise au serveur intranet backend. . Le serveur intranet renvoie la réponse à la demande à l'équilibreur de charge, et l'équilibreur de charge envoie ensuite la réponse à l'utilisateur. Cela masque la structure intranet aux utilisateurs Internet et empêche les utilisateurs d'accéder directement au serveur backend (intranet), ce qui rend la réponse plus difficile. serveur plus sécurisé, ce qui peut empêcher les attaques sur la pile du réseau principal et les services exécutés sur d'autres ports. Et le dispositif d'équilibrage de charge (logiciel ou matériel) vérifiera en permanence l'état de l'application sur le serveur et isolera automatiquement le serveur d'applications non valide, réalisant ainsi une solution d'application simple, évolutive et hautement fiable qui résout le problème. Un seul serveur gère les problèmes d'insuffisance. performances, évolutivité insuffisante et faible fiabilité.
L'expansion du système peut être divisée en expansion verticale (verticale) et expansion horizontale (horizontale). L'expansion verticale consiste à augmenter la puissance de traitement du serveur du point de vue d'une seule machine en augmentant les capacités de traitement matériel, telles que la puissance de traitement du processeur, la capacité de mémoire, le disque, etc., qui ne peuvent pas répondre aux besoins des grands systèmes distribués (sites Web). , un trafic important, une concurrence élevée et des problèmes de données massifs. Par conséquent, il est nécessaire d’adopter une méthode d’expansion horizontale en ajoutant des machines pour répondre aux capacités de traitement des grands services de sites Web. Par exemple, si une machine ne peut pas répondre aux exigences, ajoutez deux machines ou plus pour partager la pression d'accès.
L'une des applications les plus importantes de l'équilibrage de charge consiste à utiliser plusieurs serveurs pour fournir un seul serviceCette solution est parfois appelée batterie de serveurs. Habituellement, l'équilibrage de charge est principalement utilisé dans les sites Web Web, les grands réseaux de discussion Internet Relay, les sites Web de téléchargement de fichiers à fort trafic, les services NNTP (Network News Transfer Protocol) et les services DNS. Désormais, les équilibreurs de charge commencent également à prendre en charge les services de base de données, appelés équilibreurs de charge de base de données.
L'équilibrage de charge du serveur comporte trois fonctionnalités de base : l'algorithme d'équilibrage de charge, le contrôle de santé et la conservation de session. Ces trois fonctionnalités sont les éléments de base pour assurer le fonctionnement normal de l'équilibrage de charge. Certaines autres fonctions approfondissent ces trois fonctions. Ci-dessous, nous présenterons en détail les fonctions et les principes de chaque fonction.
Avant le déploiement du dispositif d'équilibrage de charge, les utilisateurs accèdent directement à l'adresse du serveur (l'adresse du serveur peut être mappée à d'autres adresses sur le pare-feu, mais il s'agit essentiellement d'un accès individuel). Lorsqu'un seul serveur ne peut pas gérer l'accès de plusieurs utilisateurs en raison de performances insuffisantes, il est nécessaire d'envisager l'utilisation de plusieurs serveurs pour fournir les services. La manière d'y parvenir est l'équilibrage de charge. Le principe de mise en œuvre du dispositif d'équilibrage de charge est de mapper les adresses de plusieurs serveurs sur une IP de service externe (nous l'appelons généralement VIP. Pour le mappage de serveur, vous pouvez directement mapper l'IP du serveur à une adresse VIP, ou vous pouvez mapper le serveur IP:Port. Dans VIP:Port. Différentes méthodes de mappage nécessiteront des contrôles de santé correspondants. Lors du mappage du port, le port du serveur et le port VIP peuvent être différents. Ce processus est invisible pour l'utilisateur. a fait l'équilibrage de charge, car ils accèdent toujours à la même adresse IP de destination, puis une fois que l'accès de l'utilisateur atteint le périphérique d'équilibrage de charge, la manière de distribuer l'accès de l'utilisateur au serveur approprié relève du travail du périphérique d'équilibrage de charge. trois caractéristiques majeures mentionnées ci-dessus.
Faisons une analyse détaillée du processus d'accès : 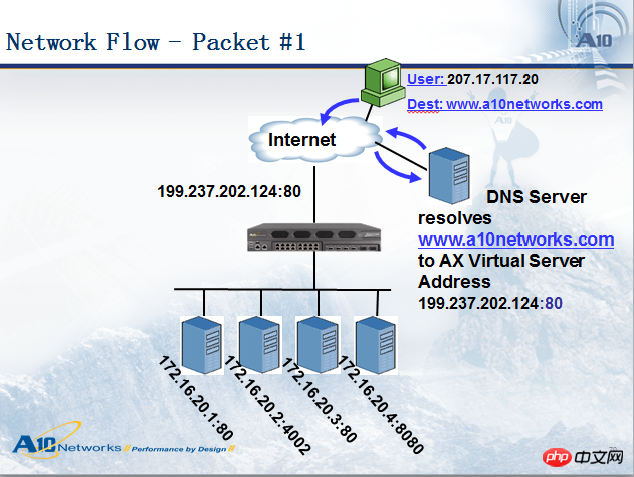
Lorsqu'un utilisateur (IP : 207.17.117.20) accède à un nom de domaine www.a10networks.com, il analysera d'abord le nom de domaine public de ce nom de domaine via une requête DNS. Adresse réseau : 199.237.202.124. Ensuite, l'utilisateur 207.17.117.20 accédera à l'adresse 199.237.202.124, de sorte que le paquet de données arrivera au périphérique d'équilibrage de charge. Ensuite, le périphérique d'équilibrage de charge distribuera le paquet de données. au serveur approprié. Voir la figure ci-dessous : 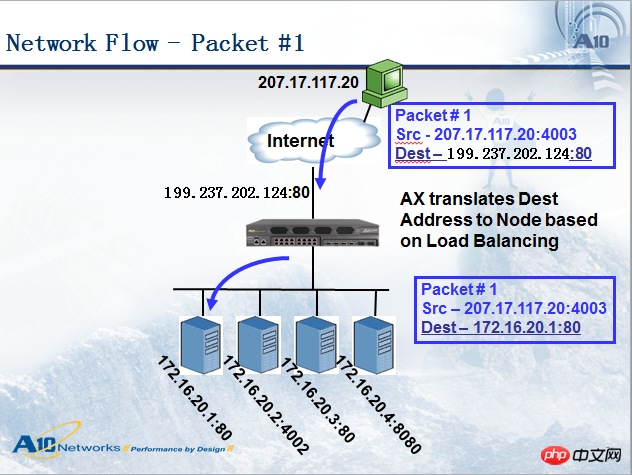
Lorsque le périphérique d'équilibrage de charge envoie le paquet de données au serveur, le paquet de données apporte quelques modifications comme indiqué dans la figure ci-dessus. le paquet de données atteint le dispositif d'équilibrage de charge, l'adresse source est : 207.17 .117.20, l'adresse de destination est : 199.237.202.124. Lorsque le dispositif d'équilibrage de charge transmet le paquet de données au serveur sélectionné, l'adresse source est toujours : 207.17.117.20. , et l'adresse de destination devient 172.16.20.1. Nous appelons cette méthode adresse de destination NAT (DNAT, Destination Address Translation). De manière générale, le DNAT doit être effectué en équilibrage de charge du serveur (il existe un autre mode appelé server direct return-DSR, qui ne fait pas de DNAT, nous en discuterons séparément), et l'adresse source dépend du mode de déploiement. Parfois, c'est aussi le cas. nécessaire de convertir vers d'autres adresses, que nous appelons : adresse source NAT (SNAT). De manière générale, le mode bypass nécessite SNAT, mais pas le mode série. Ce schéma est en mode série, donc l'adresse source Aucun NAT n'a été effectué.
Regardons le paquet de retour du serveur, comme le montre la figure ci-dessous. Il a également subi le processus de conversion d'adresse IP, mais l'adresse source/destination dans le paquet de réponse et le paquet de requête sont exactement inversés. L'adresse source du paquet renvoyé par le serveur est 172.16.20.1, l'adresse de destination est 207.17.117.20. Après avoir atteint le périphérique d'équilibrage de charge, le périphérique d'équilibrage de charge modifie l'adresse source en 199.237.202.124, puis la transmet à l'utilisateur. assurer la cohérence de l’accès. 
De manière générale, les appareils d'équilibrage de charge prennent en charge plusieurs stratégies de distribution d'équilibrage de charge par défaut, telles que :
RoundRobin envoie des requêtes à chaque serveur dans une séquence circulaire. Lorsqu'un des serveurs tombe en panne, AX le retire de la file d'attente circulaire séquentielle et ne participe pas à l'interrogation suivante jusqu'à ce qu'il revienne à la normale.
Ratio : Attribuez une valeur pondérée à chaque serveur sous forme de ratio. En fonction de ce ratio, les requêtes des utilisateurs sont distribuées à chaque serveur. Lorsqu'un des serveurs tombe en panne, AX le sort de la file d'attente du serveur et ne participe pas à la distribution de la prochaine requête utilisateur jusqu'à ce qu'il revienne à la normale.
Priorité : regroupez tous les serveurs, définissez la priorité de chaque groupe et attribuez la priorité aux demandes des utilisateurs. Le groupe de serveurs de plus haut niveau (au sein le même groupe, en utilisant un algorithme d'interrogation ou de ratio prédéfini pour attribuer les demandes des utilisateurs) ; lorsque tous les serveurs ou un nombre spécifié de serveurs du niveau de priorité le plus élevé échouent, AX envoie la demande au groupe de serveurs prioritaire suivant. Cette méthode fournit en fait aux utilisateurs une méthode de sauvegarde à chaud.
LeastConnection : AX enregistrera le nombre actuel de connexions sur chaque serveur ou port de service, et les nouvelles connexions seront transmises au serveur avec le moins de connexions. Lorsqu'un des serveurs tombe en panne, AX le sort de la file d'attente du serveur et ne participe pas à la distribution de la prochaine requête utilisateur jusqu'à ce qu'il revienne à la normale.
Temps de réponse rapide : les nouvelles connexions sont transmises aux serveurs ayant la réponse la plus rapide. Lorsqu'un des serveurs tombe en panne, AX le sort de la file d'attente du serveur et ne participe pas à la distribution de la prochaine requête utilisateur jusqu'à ce qu'il revienne à la normale.
Algorithme de hachage (hachage) : hachez l'adresse source et le port du client et transférez le résultat à chaque serveur lorsque celui-ci est traité. l'un des serveurs tombe en panne, il est retiré de la file d'attente du serveur et ne participe pas à la distribution de la prochaine requête utilisateur jusqu'à ce qu'il revienne à la normale.
Distribution de contenu basée sur des paquets : par exemple, en jugeant l'URL HTTP, si l'URL a une extension .jpg, alors le paquet est transmis au serveur spécifié.
Health Check est utilisé pour vérifier l'état de disponibilité des différents services ouverts par le serveur. Les périphériques d'équilibrage de charge sont généralement configurés avec diverses méthodes de vérification de l'état, telles que Ping, TCP, UDP, HTTP, FTP, DNS, etc. Ping appartient à la troisième couche de vérification de l'état, utilisée pour vérifier la connectivité de l'IP du serveur, tandis que TCP/UDP appartient à la quatrième couche de vérification de l'état, utilisée pour vérifier le UP/DOWN du port de service si vous souhaitez vérifier. plus précisément, vous devez utiliser Pour une vérification de l'état basée sur la couche 7, par exemple, créer une vérification de l'état HTTP, récupérer une page et vérifier si le contenu de la page contient une chaîne spécifiée. Si c'est le cas, le service est UP. S'il ne contient pas ou si la page ne peut pas être récupérée, on considère que le service Web du serveur est indisponible (DOWN). Par exemple, si le périphérique d'équilibrage de charge détecte que le port 80 du serveur 172.16.20.3 est DOWN, le périphérique d'équilibrage de charge ne transmettra pas les connexions ultérieures à ce serveur, mais transmettra les paquets de données à d'autres serveurs en fonction de l'algorithme. Lors de la création d'une vérification de l'état, vous pouvez définir l'intervalle de vérification et le nombre de tentatives. Par exemple, si vous définissez l'intervalle sur 5 secondes et le nombre de tentatives sur 3, le périphérique d'équilibrage de charge lancera une vérification de l'état toutes les 5 secondes. Si la vérification échoue, il essaiera 3 fois, si la vérification échoue trois fois, le service sera marqué comme DOWN, puis le serveur vérifiera toujours le serveur DOWN toutes les 5 secondes. réussit à nouveau à un certain moment, le serveur sera à nouveau marqué pour UP. L'intervalle et le nombre de tentatives de contrôle de santé doivent être définis en fonction de la situation globale. Le principe est que cela n'affectera pas l'activité et n'entraînera pas de charge importante sur l'équipement d'équilibrage de charge.
Comment s'assurer que deux requêtes http d'un utilisateur sont transmises au même serveur, ce qui nécessite que le périphérique d'équilibrage de charge configure la persistance de session.
La persistance de session est utilisée pour maintenir la continuité et la cohérence des sessions. Puisqu'il est difficile de synchroniser les informations d'accès des utilisateurs en temps réel entre les serveurs, il est nécessaire de conserver les sessions d'accès précédentes et ultérieures de l'utilisateur sur un seul serveur pour le traitement. Par exemple, lorsqu'un utilisateur visite un site Web de commerce électronique, le premier serveur gère la connexion de l'utilisateur, mais l'achat de biens par l'utilisateur est géré par le deuxième serveur, puisque le deuxième serveur ne connaît pas les informations de l'utilisateur. Cet achat ne sera donc pas effectué. réussir. Dans ce cas, la maintenance de session est requise et toutes les opérations utilisateur doivent être traitées par le premier serveur pour réussir. Bien entendu, tous les accès ne nécessitent pas de maintenance de session. Par exemple, si le serveur fournit des pages statiques telles que la chaîne d'information du site Web et que chaque serveur a le même contenu, un tel accès ne nécessite pas de maintenance de session.
La plupart des produits d'équilibrage de charge prennent en charge deux types de persistance de session : la persistance de session d'adresse source/destination et la persistance de session de cookie. De plus, le hachage, la persistance d'URL, etc. sont également des méthodes couramment utilisées, mais tous les appareils ne les prennent pas en charge. Différentes rétentions de session doivent être configurées en fonction de différentes applications, sinon cela entraînera un déséquilibre de charge ou même des exceptions d'accès. Nous analysons principalement la maintenance de session de la structure B/S.
Application basée sur la structure B/S :
Pour le contenu d'application avec une structure B/S ordinaire, comme les pages statiques de sites Web, vous n'avez pas besoin de configurer de persistance de session. Cependant, pour un système d'entreprise basé sur une structure B/S, en particulier une plate-forme middleware, la persistance de session doit être configurée. être configuré., Dans des circonstances normales, nous configurons la rétention de session d'adresse source pour répondre aux besoins, mais étant donné que le client peut disposer de l'environnement mentionné ci-dessus qui n'est pas propice à la conservation de session d'adresse source, l'utilisation de la rétention de session Cookie est une meilleure solution. La persistance de la session de cookie enregistrera les informations du serveur sélectionnées par le dispositif d'équilibrage de charge dans un cookie et les enverra au client lorsque le client continue de visiter, l'équilibreur de charge analysera le cookie pour maintenir la session telle qu'elle était auparavant. serveur sélectionné. Les cookies sont divisés en cookies de fichier et cookies de mémoire. Les cookies de fichier sont stockés sur le disque dur de l'ordinateur client. Tant que le fichier cookie n'expire pas, il peut être conservé sur le même serveur, que le navigateur soit fermé à plusieurs reprises ou non. pas. Les cookies de mémoire stockent les informations des cookies en mémoire. La durée de survie du cookie commence à l'ouverture du navigateur et se termine à la fermeture du navigateur. Étant donné que les navigateurs actuels disposent de certains paramètres de sécurité par défaut pour les cookies, certains clients peuvent stipuler que l'utilisation de cookies de fichiers n'est pas autorisée, c'est pourquoi le développement d'applications actuel utilise principalement des cookies de mémoire.
Cependant, les cookies de mémoire ne sont pas omnipotents. Par exemple, le navigateur peut désactiver complètement les cookies pour des raisons de sécurité, de sorte que la conservation de la session des cookies perd son effet. Nous pouvons obtenir la persistance de la session grâce à Session-id, c'est-à-dire utiliser l'ID de session comme paramètre d'URL ou le placer dans un champ caché <input type="hidden">, puis analyser l'ID de session pour la distribution.
Une autre solution consiste à enregistrer les informations de chaque session dans une base de données. Étant donné que cette solution augmentera la charge sur la base de données, cette solution n’est pas efficace pour améliorer les performances. La base de données est mieux utilisée pour stocker les données de session pour des sessions plus longues. Afin d'éviter les points de défaillance uniques dans la base de données et d'améliorer son évolutivité, la base de données est généralement répliquée sur plusieurs serveurs et les requêtes sont distribuées aux serveurs de base de données via un équilibreur de charge.
La persistance de session basée sur l'adresse source/destination n'est pas très simple à utiliser car les clients peuvent se connecter à Internet via DHCP, NAT ou proxy Web, et leurs adresses IP peuvent changer fréquemment, ce qui rend la qualité de service de cette solution non garantie.
NAT (Network Address Translation, Network Address Translation) : lorsque certains hôtes du réseau privé se sont vu attribuer des adresses IP locales (c'est-à-dire des adresses privées utilisées uniquement au sein de ce réseau privé), mais maintenant, lorsque vous souhaitez communiquer avec un hébergeur sur Internet (sans cryptage), vous pouvez utiliser la méthode NAT. Cette méthode nécessite l'installation d'un logiciel NAT sur le routeur connectant le réseau privé à Internet. Un routeur équipé d'un logiciel NAT est appelé routeur NAT et possède au moins une adresse IP globale externe valide. De cette manière, lorsque tous les hôtes utilisant des adresses locales communiquent avec le monde extérieur, leurs adresses locales doivent être converties en adresses IP globales sur le routeur NAT avant de pouvoir se connecter à Internet.
Haute évolutivité
En ajoutant ou en réduisant le nombre de serveurs, vous pouvez mieux faire face aux demandes simultanées élevées.
(Serveur) Health Check
L'équilibreur de charge peut vérifier l'état de santé de la couche d'application du serveur back-end et supprimer les serveurs défaillants du pool de serveurs pour améliorer la fiabilité.
Réutilisation des connexions TCP
La technologie de réutilisation des connexions TCP multiplexe les requêtes HTTP de plusieurs clients sur le front-end en une seule connexion TCP établie entre le back-end et le serveur. Cette technologie peut réduire considérablement la charge de performances du serveur, réduire le retard causé par les nouvelles connexions TCP avec le serveur, minimiser le nombre de demandes de connexion simultanées du client au serveur principal et réduire l'occupation des ressources du serveur.
Généralement, avant d'envoyer une requête HTTP, le client doit effectuer une négociation TCP à trois voies avec le serveur, établir une connexion TCP, puis envoyer la requête HTTP. Le serveur traite la requête HTTP après l'avoir reçue et renvoie le résultat du traitement au client. Ensuite, le client et le serveur s'envoient FIN et ferment la connexion après avoir reçu la confirmation ACK du FIN. De cette manière, une simple requête HTTP nécessite le traitement de plus d’une douzaine de paquets TCP.
Après avoir utilisé la technologie de réutilisation des connexions TCP, une négociation à trois voies est effectuée entre le client (tel que ClientA) et le périphérique d'équilibrage de charge et une requête HTTP est envoyée. Après avoir reçu la demande, le dispositif d'équilibrage de charge détectera s'il existe une longue connexion inactive sur le serveur. Si elle n'existe pas, le serveur établira une nouvelle connexion. Lorsque la réponse à la requête HTTP est terminée, le client négocie avec le périphérique d'équilibrage de charge pour fermer la connexion, et l'équilibrage de charge maintient la connexion avec le serveur. Lorsqu'un autre client (tel que ClientB) doit envoyer une requête HTTP, le périphérique d'équilibrage de charge enverra directement la requête HTTP à la connexion inactive maintenue avec le serveur, évitant ainsi le délai et la consommation des ressources du serveur provoqués par la nouvelle connexion TCP. 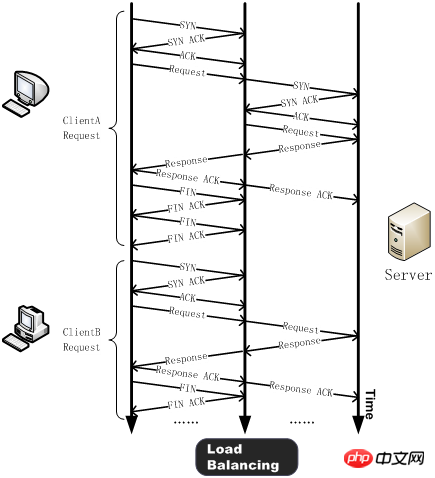
Dans HTTP 1.1, le client peut envoyer plusieurs requêtes HTTP dans une connexion TCP. Cette technologie est appelée HTTP Multiplexing. La différence la plus fondamentale entre celui-ci et le multiplexage de connexion TCP est que le multiplexage de connexion TCP consiste à multiplexer plusieurs requêtes HTTP client vers une connexion TCP côté serveur, tandis que le multiplexage HTTP consiste à multiplexer les requêtes HTTP d'un client via un TCP. La première est une fonctionnalité unique du dispositif d'équilibrage de charge ; tandis que la seconde est une nouvelle fonctionnalité prise en charge par le protocole HTTP 1.1 et est actuellement prise en charge par la plupart des navigateurs.
Cache HTTP
Les équilibreurs de charge peuvent stocker du contenu statique et répondre directement aux utilisateurs lorsqu'ils en font la demande sans avoir à demander de serveurs backend.
Mémoire tampon TCP
La mise en mémoire tampon TCP vise à résoudre le problème du gaspillage des ressources du serveur causé par l'inadéquation entre la vitesse du réseau du serveur back-end et la vitesse du réseau front-end du client. La liaison entre le client et l'équilibreur de charge a une latence élevée et une faible bande passante, tandis que la liaison entre l'équilibreur de charge et le serveur utilise une connexion LAN avec une faible latence et une bande passante élevée. Étant donné que l'équilibreur de charge peut stocker temporairement les données de réponse du serveur back-end sur le client, puis les transmettre aux clients ayant des temps de réponse plus longs et des vitesses de réseau plus lentes, le serveur Web back-end peut libérer les threads correspondants pour gérer d'autres tâches.
Accélération SSL
Dans des circonstances normales, HTTP est transmis en texte clair sur le réseau, qui peut être illégalement écouté, en particulier les informations de mot de passe utilisées pour l'authentification. Afin d'éviter de tels problèmes de sécurité, le protocole SSL (c'est-à-dire : HTTPS) est généralement utilisé pour crypter le protocole HTTP afin d'assurer la sécurité de l'ensemble du processus de transmission. Dans la communication SSL, la technologie de clé asymétrique est d'abord utilisée pour échanger des informations d'authentification, et la clé de session utilisée pour crypter les données entre le serveur et le navigateur est échangée, puis la clé est utilisée pour crypter et déchiffrer les informations pendant le processus de communication.
SSL est une technologie de sécurité qui consomme beaucoup de ressources CPU. Actuellement, la plupart des périphériques d'équilibrage de charge utilisent des puces d'accélération SSL (équilibreurs de charge matériels) pour traiter les informations SSL. Cette méthode offre des performances de traitement SSL supérieures à celles de la méthode de cryptage SSL traditionnelle basée sur le serveur, économisant ainsi une grande quantité de ressources du serveur et permettant au serveur de se concentrer sur le traitement des demandes commerciales. De plus, le traitement SSL centralisé peut également simplifier la gestion des certificats et réduire la charge de travail de gestion quotidienne.
Filtrage de contenu
Certains équilibreurs de charge peuvent modifier les données qui les traversent selon les besoins.
Fonction de prévention des intrusions
Sur la base du pare-feu assurant la sécurité de la couche réseau/couche transport, il assure également la sécurité de la couche application.
Ce qui suit traite de la mise en œuvre de l'équilibrage de charge à différents niveaux :
DNS Load Balancing
DNS est chargé de fournir des services de résolution de noms de domaine. Lors de l'accès à un certain site En fait, vous devez d'abord obtenir l'adresse IP pointée par le nom de domaine via le serveur DNS du nom de domaine du site. Dans ce processus, le serveur DNS termine le mappage du nom de domaine avec le nom de domaine. Adresse IP. De même, ce mappage peut également être un à plusieurs. À ce stade, le serveur DNS agit comme un planificateur d'équilibrage de charge, distribuant les requêtes des utilisateurs à plusieurs serveurs. Utilisez la commande dig pour jeter un œil aux paramètres DNS de « baidu » : 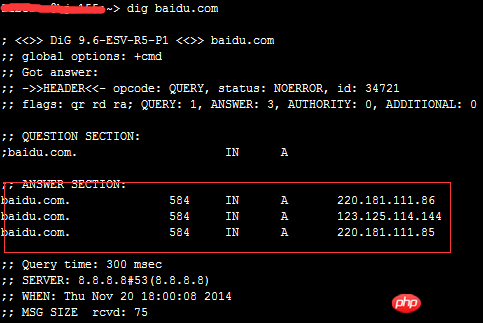
On peut voir que baidu a trois enregistrements A.
Les avantages de cette technologie sont qu'elle est simple à mettre en œuvre, facile à mettre en œuvre, peu coûteuse, adaptée à la plupart des applications TCP/IP, et le serveur DNS peut trouver le serveur le plus proche de l'utilisateur parmi tous les A disponibles. enregistrements . Cependant, ses inconvénients sont également très évidents. Tout d'abord, cette solution ne permet pas d'équilibrer la charge au sens propre du terme. Le serveur DNS répartit uniformément les requêtes HTTP vers les serveurs Web en arrière-plan (ou en fonction de l'emplacement géographique), quelle que soit la charge actuelle. situation de charge de chaque serveur Web ; si la configuration et les capacités de traitement des serveurs Web backend sont différentes, le serveur Web le plus lent deviendra le goulot d'étranglement du système et le serveur doté de fortes capacités de traitement ne pourra pas jouer pleinement son rôle ; n'est pas pris en compte, si un certain serveur Web en arrière-plan tombe en panne, le serveur DNS attribuera toujours des requêtes DNS à ce serveur défaillant, ce qui entraînera l'incapacité de répondre au client. Ce dernier point est fatal. Il peut empêcher un nombre considérable de clients de profiter des services Web et, en raison de la mise en cache DNS, les conséquences dureront longtemps (le cycle général de rafraîchissement du DNS est d'environ 24 heures). Par conséquent, dans les dernières solutions de sites Web de centres de construction étrangers, cette solution est rarement utilisée.
Équilibrage de charge de la couche liaison (couche OSI 2)
Modifiez l'adresse MAC dans la couche liaison de données du protocole de communication pour l'équilibrage de charge.
Lors de la distribution de données, ne modifiez pas l'adresse IP (car l'adresse IP n'est pas encore visible), modifiez uniquement l'adresse MAC cible et configurez toutes les IP virtuelles du serveur back-end pour qu'elles soient cohérentes avec l'adresse IP de l'équilibreur de charge, de sorte que la source du paquet de données ne soit pas modifiée, ni l'adresse de destination à des fins de distribution de données.
L'adresse IP réelle du serveur de traitement est cohérente avec l'adresse IP de destination de la demande de données. Il n'est pas nécessaire de passer par le serveur d'équilibrage de charge pour la traduction de l'adresse. Le paquet de données de réponse peut être renvoyé directement au navigateur de l'utilisateur pour éviter le serveur d'équilibrage de charge. la bande passante de la carte réseau devient un goulot d'étranglement. Également appelé mode de routage direct (mode DR). Comme indiqué ci-dessous : 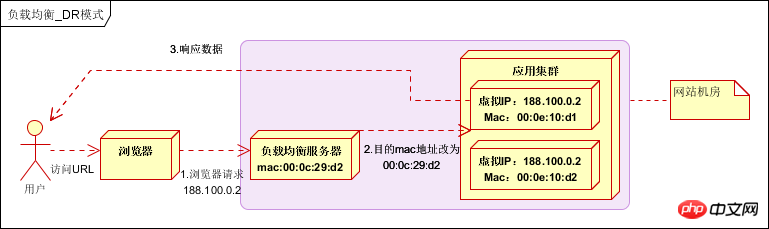
Les performances sont très bonnes, mais la configuration est compliquée et elle est actuellement largement utilisée.
Équilibrage de charge de la couche de transport (couche OSI 4)
La couche de transport est la couche OSI 4, comprenant TCP et UDP. Les équilibreurs de charge de couche de transport populaires sont HAProxy (celui-ci est également utilisé pour l'équilibrage de charge de la couche d'application) et IPVS.
Le serveur interne final sélectionné est déterminé principalement par l'adresse de destination et le port dans le message, ainsi que par la méthode de sélection du serveur définie par le périphérique d'équilibrage de charge.
En prenant le TCP commun comme exemple, lorsque le périphérique d'équilibrage de charge reçoit la première requête SYN du client, il sélectionne un serveur optimal via la méthode ci-dessus et modifie l'adresse IP cible dans le message (changée en IP du serveur backend), transmis directement au serveur. L'établissement de la connexion TCP, c'est-à-dire que la négociation à trois voies est établie directement entre le client et le serveur, et le périphérique d'équilibrage de charge n'agit que comme une action de transfert de type routeur. Dans certaines situations de déploiement, afin de garantir que le paquet de retour du serveur peut être correctement renvoyé au périphérique d'équilibrage de charge, l'adresse source d'origine du paquet peut être modifiée lors du transfert du paquet. 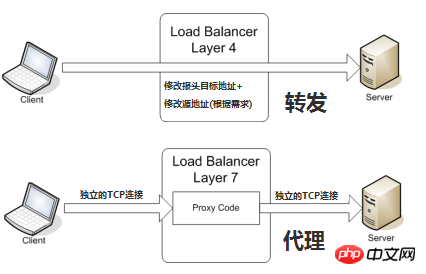
Équilibrage de charge de la couche application (couche OSI 7)
La couche application est la couche OSI 7. Il inclut HTTP, HTTPS et WebSockets. Nginx [Engine X = Engine X] est un équilibreur de charge de couche application très populaire et éprouvé.
L'équilibrage de charge dit à sept couches, également connu sous le nom de « commutation de contenu », est principalement basé sur le contenu de la couche d'application vraiment significatif dans le message, couplé à la méthode de sélection de serveur définie par le dispositif d'équilibrage de charge, pour déterminer la sélection interne finale. Notez que vous pouvez voir l'URL complète de la requête http spécifique à ce moment-là, de sorte que la distribution indiquée dans la figure ci-dessous peut être obtenue : 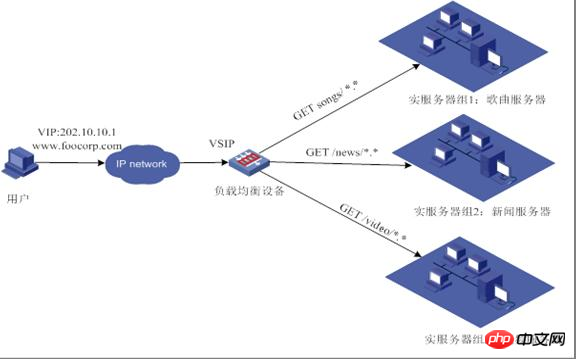
En prenant le TCP commun comme exemple, si le le périphérique d'équilibrage de charge veut être basé sur le contenu réel de la couche d'application, puis sélectionner le serveur, ne peut être vu qu'après que le serveur final et le client ont été mandatés pour établir une connexion (prise de contact à trois), puis le message de contenu réel de la couche d'application Le champ envoyé par le client, combiné à la méthode de sélection du serveur définie par le périphérique d'équilibrage de charge, détermine la sélection finale du serveur interne. Le dispositif d’équilibrage de charge dans ce cas ressemble davantage à un serveur proxy. L'équilibrage de charge, les clients frontaux et les serveurs back-end établiront respectivement des connexions TCP. Par conséquent, du point de vue de ce principe technique, l'équilibrage de charge à sept couches a évidemment des exigences plus élevées en matière d'équipement d'équilibrage de charge, et la capacité à gérer sept couches sera inévitablement inférieure à celle de la méthode de déploiement en mode quatre couches. Alors, pourquoi avons-nous besoin d’un équilibrage de charge de couche 7 ?
L'avantage de l'équilibrage de charge à sept couches est de rendre l'ensemble du réseau plus « intelligent ». Par exemple, la plupart des avantages de l'équilibrage de charge répertoriés ci-dessus sont basés sur l'équilibrage de charge à sept couches. Par exemple, le trafic des utilisateurs visitant un site Web peut transmettre les demandes d'images à un serveur d'images spécifique et utiliser la technologie de mise en cache via l'approche à sept couches ; les demandes de texte peuvent être transmises à un serveur de texte spécifique et la technologie de compression peut être utilisée. Bien sûr, il ne s'agit que d'un petit cas d'application à sept couches. D'un point de vue technique, cette méthode peut modifier la demande du client et la réponse du serveur dans n'importe quel sens, améliorant considérablement la flexibilité du système d'application au niveau de la couche réseau.
Une autre fonctionnalité souvent évoquée est la sécurité. L'attaque SYN Flood la plus courante sur le réseau est que les pirates contrôlent de nombreux clients sources et utilisent de fausses adresses IP pour envoyer des attaques SYN à la même cible. Habituellement, cette attaque enverra un grand nombre de messages SYN et épuisera les ressources associées sur le serveur pour y parvenir. Objectif de déni de service (DoS). Il ressort également des principes techniques qu'en mode quatre couches, ces attaques SYN seront transmises au serveur back-end ; en mode sept couches, ces attaques SYN se termineront naturellement sur le périphérique d'équilibrage de charge et se termineront naturellement sur le serveur principal. n'affecte pas le fonctionnement normal du serveur back-end. De plus, le dispositif d'équilibrage de charge peut définir plusieurs politiques au niveau de sept couches pour filtrer des messages spécifiques, tels que l'injection SQL et d'autres méthodes d'attaque au niveau de l'application, afin d'améliorer encore la sécurité globale du système au niveau de l'application.
L'équilibrage de charge actuel à sept couches se concentre principalement sur le protocole HTTP largement utilisé, son champ d'application concerne donc principalement les systèmes développés sur la base de B/S tels que de nombreux sites Web ou plateformes d'informations internes. L'équilibrage de charge de couche 4 correspond à d'autres applications TCP, telles que les ERP et d'autres systèmes développés sur la base de C/S.
Recommandations associées :
Résumé des points à noter concernant les clusters distribués
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment acheter et vendre du Bitcoin sur okex
Comment acheter et vendre du Bitcoin sur okex
 L'ordinateur ne peut pas copier et coller
L'ordinateur ne peut pas copier et coller
 Introduction aux commandes courantes de postgresql
Introduction aux commandes courantes de postgresql
 Plateforme nationale d'achat et de vente de Bitcoin
Plateforme nationale d'achat et de vente de Bitcoin
 redémarrage de nginx
redémarrage de nginx
 Comment résoudre le problème de l'absence d'accès à Internet lorsque l'ordinateur est connecté au wifi
Comment résoudre le problème de l'absence d'accès à Internet lorsque l'ordinateur est connecté au wifi
 Comment démarrer la surveillance des données Oracle
Comment démarrer la surveillance des données Oracle
 utilisation de l'instruction d'insertion
utilisation de l'instruction d'insertion








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



