
 Java
javaDidacticiel
Résumé et compilation des questions d'entretien Java des grandes entreprises (toutes)
Java
javaDidacticiel
Résumé et compilation des questions d'entretien Java des grandes entreprises (toutes)
Résumé et compilation des questions d'entretien Java des grandes entreprises (toutes)
ThreadLocal (copie des variables de thread)
Synchronized implémente le partage de mémoire et ThreadLocal maintient une variable locale pour chaque thread.
Utilisez l'espace pour le temps, qui est utilisé pour l'isolation des données entre les threads, en fournissant une copie pour chaque thread qui utilise la variable. Chaque thread peut modifier sa propre copie indépendamment sans entrer en conflit avec les copies des autres threads.
La classe ThreadLocal maintient une Map pour stocker une copie des variables de chaque thread. La clé de l'élément dans la Map est l'objet thread, et la valeur est la copie de la variable du thread correspondant.
ThreadLocal joue un rôle énorme dans Spring et apparaît dans des modules tels que la gestion des Beans, la gestion des transactions, la planification des tâches et l'AOP dans la portée de la requête.
La plupart des beans de Spring peuvent être déclarés comme étant à portée Singleton et encapsulés à l'aide de ThreadLocal, de sorte que les beans avec état peuvent fonctionner normalement dans plusieurs threads de manière singleton.
La spécification de la machine virtuelle Java divise les données d'exécution Java en six types.
1. Compteur de programme : Il s'agit d'une structure de données utilisée pour enregistrer l'adresse mémoire du programme en cours d'exécution. Le multithreading de la machine virtuelle Java est obtenu en changeant de thread à tour de rôle et en allouant du temps processeur. Afin de revenir à la position correcte après le changement de thread, chaque thread a besoin d'un compteur de programme indépendant qui ne s'affecte pas les uns les autres. Sujet privé".
2. Pile de machine virtuelle Java : thread privé, identique au cycle de vie du thread, utilisé pour stocker les tables de variables locales, les piles d'opérations et les valeurs de retour des méthodes. La table des variables locales contient les types de données de base et les références d'objet.
3. Pile de méthodes locales : elle est très similaire à la pile de machines virtuelles, mais elle sert les méthodes natives utilisées par la machine virtuelle.
4.Tas Java : une zone mémoire partagée par tous les threads, où presque toutes les instances d'objet allouent de la mémoire.
5. Zone de méthode : une zone partagée par chaque thread, qui stocke les informations de classe chargées par la machine virtuelle, les constantes, les variables statiques et le code compilé.
6. Pool de constantes d'exécution : représente la table des constantes dans chaque fichier de classe au moment de l'exécution. Comprend plusieurs types de constantes : constantes numériques au moment de la compilation, références de méthode ou de champ.
"Pouvez-vous parler de quand, quoi et qu'a fait Java GC ?"
Quand :
1. La nouvelle génération a une zone Eden et deux. Tout d'abord, mettez l'objet dans l'Eden. S'il n'y a pas assez d'espace, placez-le dans l'une des zones survivantes. S'il ne peut toujours pas rentrer, cela déclenchera un GC mineur qui se produira dans la nouvelle génération et placera les objets survivants dans une autre zone survivante, puis effacera. la mémoire d'Eden et de la zone de survivant précédente. Au cours d'un certain processus GC, si l'on trouve des objets qui ne peuvent pas être déposés, ces objets seront placés dans la mémoire d'ancienne génération.
2. Les gros objets et les objets survivants à long terme entrent directement dans la zone des personnes âgées.
3. Chaque fois qu'un GC mineur est exécuté, les objets à promouvoir vers l'ancienne génération doivent être analysés si la taille de ces anciens objets qui sont sur le point d'aller dans l'ancienne zone dépasse la taille restante de l'ancienne zone, puis un Full GC est exécuté pour obtenir le plus d'espace possible dans la zone senior.
À propos de quoi : il ne peut pas être recherché à partir de GC Roots, et il n'y a toujours pas d'objet ressuscité après un nettoyage des marques.
Que faire : Jeune génération : nettoyage de copie ; Ancienne génération : algorithmes de balayage de marquage et de compression de marquage ; Génération permanente : stocke les classes en Java et le chargeur de classe lui-même qui charge les classes.
Quelles sont les racines GC : 1. Objets référencés dans la pile de machines virtuelles 2. Objets référencés par des propriétés statiques dans la zone de méthode, objets référencés par des constantes 3. Références JNI (de manière générale Méthodes natives) dans l'objet de pile de méthodes locale .
Synchronisé et Verrouillage sont tous deux des verrous réentrants. Lorsque le même thread saisit à nouveau le code de synchronisation, il peut utiliser le verrou qu'il a acquis.
Synchronisé est un mécanisme de verrouillage pessimiste et un verrou exclusif. Locks.ReentrantLock ne se verrouille pas à chaque fois mais suppose qu'il n'y a pas de conflit et termine une opération si elle échoue en raison d'un conflit, il réessaye jusqu'à ce qu'il réussisse. Scénarios applicables pour ReentrantLock
Un thread doit être interrompu en attendant le contrôle d'un verrou
Certaines notifications d'attente doivent être traitées séparément , l'application Condition dans ReentrantLock peut contrôler le thread à notifier, et le verrou peut être lié à plusieurs conditions.
a une fonction de verrouillage équitable, chaque fil entrant sera mis en file d'attente pour attendre.
StringBuffer est thread-safe. Chaque fois qu'une chaîne est manipulée, String générera un nouvel objet, mais StringBuffer ne le fera pas ; >fail-fast : le mécanisme est un mécanisme d'erreur dans la collection Java (Collection). Lorsque plusieurs threads opèrent sur le contenu de la même collection, un événement d'échec rapide peut se produire.
Par exemple : lorsqu'un thread A traverse une collection via un itérateur, si le contenu de la collection est modifié par d'autres threads ; alors lorsque le thread A accède à la collection, une exception ConcurrentModificationException sera levée, ce qui entraînera un événement fail-fast.arrive-avant : s'il existe une relation qui se produit avant entre deux opérations, alors le résultat de l'opération précédente sera visible pour l'opération ultérieure.
1. Règles de séquence du programme : chaque opération dans un thread se produit avant toute opération ultérieure dans le thread.
2. Règles de verrouillage du moniteur : le déverrouillage d'un verrouillage du moniteur se produit avant le verrouillage ultérieur du verrouillage du moniteur.
3. Règles des variables volatiles : l'écriture dans un champ volatile se produit avant toute lecture ultérieure de ce champ volatile.
4. Transitivité : si A se produit avant B et que B se produit avant C, alors A se produit avant C.
5. Règles de démarrage du thread : la méthode start() de l'objet Thread se produit avant chaque action de ce thread.
Quatre différences entre Volatile et Synchronisé :
1 Granularité différente, la première cible les variables, la seconde verrouille les objets et les classes
2 blocs de synchronisation, les threads volatiles ne bloquent pas
3 syn garantit trois Caractéristiques majeures, volatile ne garantit pas l'atomicité
4 optimisation du compilateur syn, volatile n'optimise pas volatile a deux caractéristiques :
1 Garantir la visibilité de cette variable sur tous les threads, fait référence à la modification par. un thread Si la valeur de cette variable est modifiée, la nouvelle valeur sera visible par les autres threads, mais elle n'est pas sécurisée pour le multithread.
2. Désactivez l'optimisation de la réorganisation des instructions.
Comment Volatile assure la visibilité de la mémoire :
1 Lors de l'écriture d'une variable volatile, JMM actualisera la variable partagée dans la mémoire locale correspondant au thread dans la mémoire principale. .
2. Lors de la lecture d'une variable volatile, JMM invalidera la mémoire locale correspondant au thread. Le thread lira ensuite la variable partagée depuis la mémoire principale.
Synchronisation : l'achèvement d'une tâche dépend d'une autre tâche. La tâche dépendante ne peut être terminée qu'après avoir attendu la fin de la tâche dépendante.
Asynchrone : il n'est pas nécessaire d'attendre que la tâche dépendante soit terminée, mais seulement d'informer la tâche dépendante du travail à terminer. Tant que la tâche est terminée, elle est terminée et la tâche dépendante sera notifiée. retour s'il est terminé. (La caractéristique de l'asynchrone est la notification). Les appels et les SMS sont des métaphores des opérations synchrones et asynchrones.
Blocage : le processeur s'arrête et attend la fin d'une opération lente avant de terminer d'autres travaux.
Non bloquant : non bloquant signifie que pendant l'exécution lente, le processeur effectue d'autres travaux une fois l'exécution lente terminée, le processeur effectuera les opérations suivantes.
Le non-blocage entraînera une augmentation du changement de thread. Il faut se demander si l'augmentation du temps d'utilisation du processeur peut compenser le coût de commutation du système.
Algorithme sans verrouillage CAS (Compare And Swap) : CAS est une technologie de verrouillage optimiste lorsque plusieurs threads tentent d'utiliser CAS pour mettre à jour la même variable en même temps, un seul des threads peut le faire. mettre à jour la valeur de la variable, et si d'autres threads échouent, le thread ayant échoué ne sera pas suspendu, mais sera informé que la compétition a échoué et pourra réessayer. CAS a 3 opérandes, la valeur mémoire V, l'ancienne valeur attendue A et la nouvelle valeur à modifier B. Si et seulement si la valeur attendue A et la valeur mémoire V sont identiques, modifiez la valeur mémoire V en B, sinon ne faites rien.
Le rôle du pool de threads : Lorsque le programme démarre, plusieurs threads sont créés pour répondre au traitement. Ils sont appelés pools de threads, et les threads à l'intérieur sont appelés threads de travail.
Premier : Réduire. consommation de ressources. Réduisez le coût de création et de destruction des threads en réutilisant les threads créés.
Deuxième : améliorez la vitesse de réponse. Lorsqu'une tâche arrive, elle peut être exécutée immédiatement sans attendre la création du thread.
Troisième : améliorer la gestion des threads.
Pools de threads couramment utilisés : ExecutorService est la classe d'implémentation principale, parmi lesquelles les plus couramment utilisées sont Executors.newSingleThreadPool(), newFixedThreadPool(), newcachedTheadPool(), newScheduledThreadPool().
Mécanisme de fonctionnement du chargeur de classe :
1. Chargement : importez le code binaire Java dans jvm et générez un fichier de classe.
2. Connexion : a) Vérification : Vérifier l'exactitude des données du fichier de classe chargé b) Préparation : Allouer de l'espace de stockage aux variables statiques de la classe c) Analyse : Convertir les références de symboles en références directes
3 : Initialisation : Effectuer un travail d'initialisation sur les variables statiques, les méthodes statiques et les blocs de code statiques de la classe.
Modèle de délégation parentale : lorsque le chargeur de classe reçoit une demande de chargement de classe, il délègue d'abord la demande au chargeur de classe parent pour terminer le chargeur défini par l'utilisateur->Chargeur d'application->Chargeur de classe d'extension->Démarrer la classe chargeur.
Hashage cohérent :
Cache Memcahed :
Structure des données : clé, paire de valeurs
Méthodes d'utilisation : get, put et autres méthodes
Redis structure de données : String—string (type clé-valeur)
Hash—dictionnaire (hashmap) La structure de hachage de Redis vous permet de modifier uniquement une certaine valeur d'attribut, tout comme la mise à jour d'un attribut dans la base de données
List —List implémente la file d'attente de messages
Set : Set utilise l'unicité
Ensemble trié – L'ensemble ordonné peut être trié et la persistance des données peut être obtenue
Analyse approfondie de la boxe et du déballage automatiques Java
Parlez de Java mécanisme de réflexion
Comment écrire une classe immuable ?
Index : B+, B-, index de texte intégral
L'index de MySQL est une structure de données conçue pour permettre à la base de données de trouver des données efficacement.
La structure de données couramment utilisée est B+Tree. Chaque nœud feuille stocke non seulement les informations pertinentes de la clé d'index, mais ajoute également des pointeurs vers les nœuds feuilles adjacents. Cela forme un B+Tree avec des pointeurs d'accès séquentiels. cette optimisation vise à améliorer les performances des différents accès à la plage.
Quand utiliser les index :
apparaît souvent dans les champs après regrouper par, trier par et des mots-clés distincts
apparaît souvent avec d'autres champs Les tables à connecter doivent être indexées sur les champs de connexion
Les champs qui apparaissent souvent dans la clause Where
apparaissent souvent comme Requête sur le champ sélectionné
Spring IOC (Inversion of Control, Dependency Injection)
Spring prend en charge trois méthodes d'injection de dépendances, à savoir l'injection d'attributs (méthode Setter), l'injection de constructeur et l'injection d'interface.
Au Spring, les objets qui composent l'application et qui sont gérés par le conteneur Spring IOC sont appelés beans.
Le conteneur IOC de Spring instancie les beans et établit des dépendances entre les beans via le mécanisme de réflexion.
En termes simples, Bean est un objet initialisé, assemblé et géré par le conteneur Spring IOC.
Le processus d'obtention de l'objet Bean consiste à charger d'abord le fichier de configuration via Resource et à démarrer le conteneur IOC, puis à obtenir l'objet bean via la méthode getBean, puis à appeler sa méthode.
Portée Spring Bean :
Singleton : il n'y a qu'une seule instance Bean partagée dans le conteneur Spring IOC, qui est généralement une portée Singleton.
Prototype : Chaque requête générera une nouvelle instance de Bean.
Requête : Chaque requête http générera une nouvelle instance de Bean.
Les avantages communs des proxys : les classes affaires doivent uniquement se concentrer sur la logique métier elle-même, garantissant la réutilisabilité des classes affaires.
Proxy statique Java :
L'objet proxy et l'objet cible implémentent la même interface. L'objet cible est un attribut de l'objet proxy. Dans l'implémentation d'interface spécifique, l'objet proxy peut ajouter d'autres traitements métier avant et après. appeler la méthode correspondante de la logique de l'objet cible.
Inconvénient : une classe proxy ne peut proxy qu'une seule classe affaires. Si la classe métier ajoute des méthodes, la classe proxy correspondante doit également ajouter des méthodes.
Proxy dynamique Java :
Le proxy dynamique Java consiste à écrire une classe pour implémenter l'interface InvocationHandler et remplacer la méthode Invoke. Dans la méthode Invoke, une logique de traitement améliorée ne peut être écrite que lorsque cette classe proxy publique est en cours d'exécution. il doit être clair sur ce qu'il veut. L'objet proxy peut également implémenter les méthodes de la classe proxy, puis effectuer des améliorations lors de l'implémentation des méthodes de classe.
En fait : Méthodes des objets proxy = traitement amélioré + méthodes des objets proxy
La différence entre JDK et CGLIB générant des classes proxy dynamiques :
Les proxys dynamiques JDK ne peuvent être générés que pour les classes qui implémentent des interfaces Proxy (instancier une classe). À ce stade, l'objet proxy et l'objet cible implémentent la même interface. L'objet cible est un attribut de l'objet proxy. Dans l'implémentation d'interface spécifique, une autre logique de traitement métier peut être ajoutée avant et après l'appel de la méthode correspondante de la cible. object
CGLIB implémente un proxy pour les classes , principalement pour générer une sous-classe de la classe spécifiée (sans instancier une classe) et remplacer les méthodes qu'elle contient.
Scénarios d'application Spring AOP
Tests de performances, contrôle d'accès, gestion des journaux, transactions, etc.
La stratégie par défaut consiste à utiliser la technologie de proxy dynamique JDK si la classe cible implémente l'interface. Si l'objet cible n'implémente pas l'interface, le proxy CGLIB sera utilisé par défaut
Principe de fonctionnement SpringMVC
Les demandes des clients sont soumises à DispatcherServlet
Le contrôleur DispatcherServlet interroge HandlerMapping, le trouve et le distribue au contrôleur spécifié.
Une fois que le contrôleur a appelé le traitement de la logique métier, il renvoie ModelAndView
DispatcherServlet interroge un ou plusieurs analyseurs de vue ViewResoler et trouve la vue spécifiée par ModelAndView
La vue se charge d'afficher les résultats au client
Une requête Http
Résolution de nom de domaine DNS–> poignée de main à trois voies–> ; Après avoir établi une connexion TCP, lancez une requête http –> Le serveur répond à la requête http et le navigateur obtient le code html –> code html (tel que javascript, css, images, etc.) –> Parcourir Le serveur restitue la page et la présente à l'utilisateur
Concevez un système de stockage pour stocker des données massives : Concevez une couche logique appelée "couche intermédiaire". Dans cette couche, les données massives de la base de données sont capturées et placées dans un cache. De la même manière, lorsque de nouvelles données arrivent, elles sont d'abord mises en cache puis trouvent un moyen d'y accéder. conservez-le dans la base de données. C'est une idée simple. L'étape principale est l'équilibrage de charge, qui distribue les requêtes des différents utilisateurs vers différents nœuds de traitement, puis les stocke dans le cache et met régulièrement à jour les données dans la base de données principale. Le processus de lecture et d'écriture utilise un mécanisme similaire au verrouillage optimiste, qui peut continuer la lecture (également lors de l'écriture de données), mais il y aura une marque de version à chaque lecture si la version lue cette fois est inférieure à la version mise en cache. il relira les données. Cette situation est rare et peut être tolérée.
Session et Cookie : Les cookies permettent au serveur de suivre la visite de chaque client, mais ces cookies doivent être renvoyés à chaque visite du client. S'il y a beaucoup de cookies, la quantité de données transmises entre le client et le serveur sera augmentée de manière invisible. .
Session résout très bien ce problème. Chaque fois que le même client interagit avec le serveur, il stocke les données sur le serveur via Session. Il n'a pas besoin de renvoyer toutes les valeurs des cookies à chaque fois, mais renvoie un identifiant, un identifiant unique généré par le serveur pour la première visite de chaque client. Le client n'a qu'à renvoyer cet identifiant. Cet identifiant est généralement un cookie dont le nom est JSESSIONID. De cette manière, le serveur peut utiliser cet ID pour récupérer la valeur KV stockée sur le serveur.
Problèmes d'expiration de session et de cookie, problèmes de sécurité des cookies
Cadre de session distribué
Serveur de configuration, le serveur de gestion de cluster Zookeeper peut gérer uniformément la configuration de tous les serveurs de fichiers
Les sessions partagées sont stockées dans un cache distribué, qui peut être écrit et lu à tout moment, et les performances doivent être très bonnes, comme Memcache et Tair.
Encapsuler une classe qui hérite de HttpSession, stocker la session dans cette classe puis la stocker dans le cache distribué
Car les cookies ne peuvent pas accès inter-domaines, pour réaliser la synchronisation de session, les ID de session doivent être synchronisés et écrits sur différents noms de domaine.
Mode adaptateur : adaptez une interface à une autre interface. InputStreamReader dans Java I/O adapte la classe Reader à InputStream, obtenant ainsi la précision du flux d'octets au flux de caractères.
Mode Décorateur : conservez l'interface d'origine et améliorez les fonctions d'origine.
FileInputStream implémente toutes les interfaces de InputStream. BufferedInputStreams hérite de FileInputStream et est un implémenteur de décorateur spécifique qui enregistre le contenu lu par InputStream en mémoire pour améliorer les performances de lecture.
Méthode de configuration des transactions Spring :
1. Informations Pointcut, utilisées pour localiser les méthodes de classe affaires qui implémentent les aspects de la transaction
2 Attributs de transaction qui contrôlent le comportement de la transaction, ces attributs incluent le niveau d'isolation des transactions et la propagation des transactions. comportement, délai d'attente, règles de restauration.
Spring utilise l'espace de noms de schéma aop/tx et la technologie d'annotation @Transaction pour la configuration déclarative des transactions.
Mybatis
Chaque application Mybatis est centrée sur une instance de l'objet SqlSessionFactory. Tout d’abord, utilisez un flux d’octets pour lire le fichier de configuration via Resource, puis créez une SqlSessionFactory via la méthode SqlSessionFactoryBuilder().build, puis créez une SqlSession pour servir chaque transaction de base de données via la méthode SqlSessionFactory.openSession().
Initialisation Mybatis expérimentée->Créer SqlSession->Exécuter des instructions SQL et renvoyer les résultats dans trois processus
La différence entre Servlet et Filtre :
L'ensemble du processus est le suivant : Le filtre prépare les demandes des utilisateurs, le traitement, puis le La demande est transmise au servlet pour traitement et une réponse est générée, et enfin le filtre post-traite la réponse du serveur.
Le filtre a les utilisations suivantes :
Le filtre peut pré-traiter et post-traiter des demandes et des réponses d'URL spécifiques.
Interceptez le HttpServletRequest du client avant que le HttpServletRequest n'atteigne le servlet.
Vérifiez HttpServletRequest si nécessaire, et vous pouvez également modifier l'en-tête et les données HttpServletRequest.
Interceptez HttpServletResponse avant qu'il n'atteigne le client.
Vérifiez HttpServletResponse si nécessaire, et vous pouvez également modifier l'en-tête et les données HttpServletResponse.
En fait, Filter et Servlet sont très similaires. La seule différence est que Filter ne peut pas générer directement de réponse à l'utilisateur. En fait, le code de la méthode doFilter() dans Filter est le code commun extrait de la méthode service() de plusieurs servlets. Une meilleure réutilisation peut être obtenue en utilisant Filter.
Cycle de vie du Filtre et du Servlet :
1. Le filtre est initialisé au démarrage du serveur web
2 Si un Servlet est configuré avec 1, le Servlet est également initialisé lorsque Tomcat (conteneur de Servlet) démarre.
3. Si le Servlet n'est pas configuré avec 1, le Servlet ne sera pas initialisé au démarrage de Tomcat, mais sera initialisé à l'arrivée de la requête.
4. Chaque fois qu'une demande est faite, la demande sera initialisée. Après avoir répondu à la demande, la demande sera détruite.
5. Une fois le servlet initialisé, il ne sera pas déconnecté à la fin de la requête.
6. Lorsque Tomcat est fermé, Servlet et Filter sont déconnectés à leur tour.
La différence entre HashMap et HashTable.
1. HashMap n'est pas thread-safe et HashTable est thread-safe.
2. Les clés et les valeurs de HashMap autorisent les valeurs nulles, mais pas HashTable.
3. En raison de problèmes de sécurité des threads, HashMap est plus efficace que HashTable.
Le mécanisme d'implémentation de HashMap :
Maintenir un tableau dans lequel chaque élément est une liste chaînée et chaque nœud de la liste chaînée est une clé Entry[] - structure de données de paire de valeurs.
implémente les caractéristiques de tableau + liste chaînée, recherche rapide, insertion et suppression rapides.
Pour chaque clé, son indice d'index de tableau correspondant est int i = hash(key.hashcode)&(len-1);
-
Chaque nœud nouvellement ajouté est placé en tête de la liste chaînée, puis le nœud nouvellement ajouté pointe vers la tête de la liste chaînée d'origine
La différence entre HashMap et TreeMap
Conflit HashMap
La différence entre HashMap, ConcurrentHashMap et LinkedHashMap
ConcurrentHashMap utilise la technologie de segmentation de verrouillage pour garantir la sécurité des threads : divisez d'abord les données en segments pour le stockage, puis attribuez un verrou à chaque segment de données lorsqu'un thread occupe le verrou. accéder aux données d'un segment, les données des autres segments sont également accessibles par d'autres threads
ConcurrentHashMap est thread-safe dans chaque segment (segment)
LinkedHashMap maintient une double liste chaînée et les données qu'elle contient peuvent être lues dans l'ordre dans lequel elles sont écrites
Scénarios d'application ConcurrentHashMap
1 : Scénarios d'application de ConcurrentHashMap It Il y a une forte concurrence, mais cela ne garantit pas la sécurité des threads. Synchronized HashMap et HashMap verrouillent l'intégralité du conteneur. Après le verrouillage, ConcurrentHashMap n'a pas besoin de verrouiller l'intégralité du conteneur, il suffit de verrouiller le segment correspondant, il peut donc être garanti. l'accès synchrone simultané améliore l'efficacité.
2 : Peut être écrit dans plusieurs fils de discussion.
ConcurrentHashMap divise le HashMap en plusieurs Segmenets
1 Lors de l'obtention, aucun verrouillage n'est effectué. Localisez d'abord le segment, puis recherchez le nœud principal pour l'opération de lecture. La valeur est une variable volatile, elle est donc garantie de lire la dernière valeur en cas de condition de concurrence critique. Si la valeur lue est nulle, elle peut être modifiée, alors la fonction ReadValueUnderLock est appelée et le verrou est appliqué pour garantir que. les données lues sont correctes.
2. Il sera verrouillé lors de la mise et sera ajouté à la tête de la chaîne de hachage.
3. Il sera également verrouillé lors de la suppression. Puisque next est un type final et ne peut pas être modifié, tous les nœuds avant le nœud supprimé doivent être copiés.
4.ConcurrentHashMap permet d'effectuer plusieurs opérations de modification simultanément. La clé réside dans l'utilisation de la technologie de séparation des verrous. Il utilise plusieurs verrous pour contrôler les modifications apportées aux différents segments de la table de hachage.
Le scénario d'application de ConcurrentHashMap est une concurrence élevée, mais il ne garantit pas la sécurité des threads. Les HashMap et HashTable synchronisés verrouillent l'intégralité du conteneur. Après le verrouillage, ConcurrentHashMap n'a pas besoin de verrouiller l'intégralité du conteneur, seulement le verrou. Le segment correspondant est suffisant, il peut donc garantir un accès synchrone simultané élevé et améliorer l'efficacité.
ConcurrentHashMap peut garantir que chaque appel est une opération atomique, mais il ne garantit pas que plusieurs appels sont également des opérations atomiques.
La différence entre Vector et ArrayList
ExecutorService service = Executors.... ExecutorService service = new ThreadPoolExecutor() ExecutorService service = new ScheduledThreadPoolExecutor();
Analyse du code source de ThreadPoolExecutor
L'état du pool de threads lui-même :
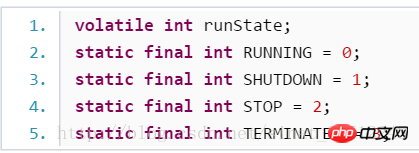
File d'attente des tâches en attente et ensemble de travail :

Le verrou d'état principal du pool de threads :

Le temps de survie et la taille du pool de threads :

1.2 ThreadPoolExecutor Principe de fonctionnement interne
Avec les données définies ci-dessus, regardons comment elles sont implémentées en interne. L'idée entière de Doug Lea est résumée en 5 phrases :
Si la taille actuelle du pool poolSize est inférieure à corePoolSize, créez un nouveau thread pour effectuer la tâche.
Si la taille actuelle du pool poolSize est supérieure à corePoolSize et que la file d'attente n'est pas pleine, entrez dans la file d'attente
Si la taille actuelle du pool size poolSize est supérieur à corePoolSize et s'il est inférieur à maximumPoolSize et que la file d'attente est pleine, un nouveau thread sera créé pour effectuer la tâche.
Si la taille actuelle du pool poolSize est supérieure à corePoolSize et supérieure à maximumPoolSize et que la file d'attente est pleine, la politique de rejet est appelée pour traiter la tâche.
Chaque thread du pool de threads ne se fermera pas immédiatement après l'exécution de la tâche, il vérifiera s'il y a des tâches de thread dans la file d'attente qui doivent être exécutées. attend dans keepAliveTime S'il n'y a pas de nouvelles tâches, le thread se fermera.
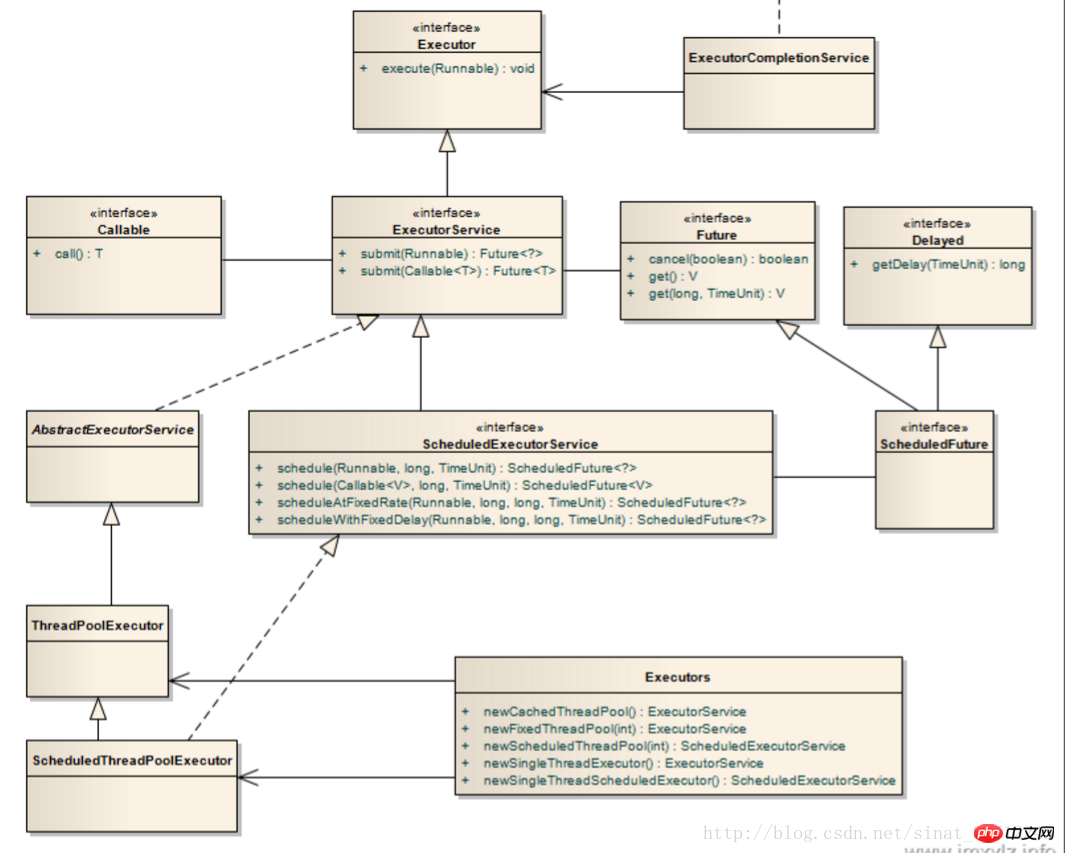
Structure du paquet exécuteur
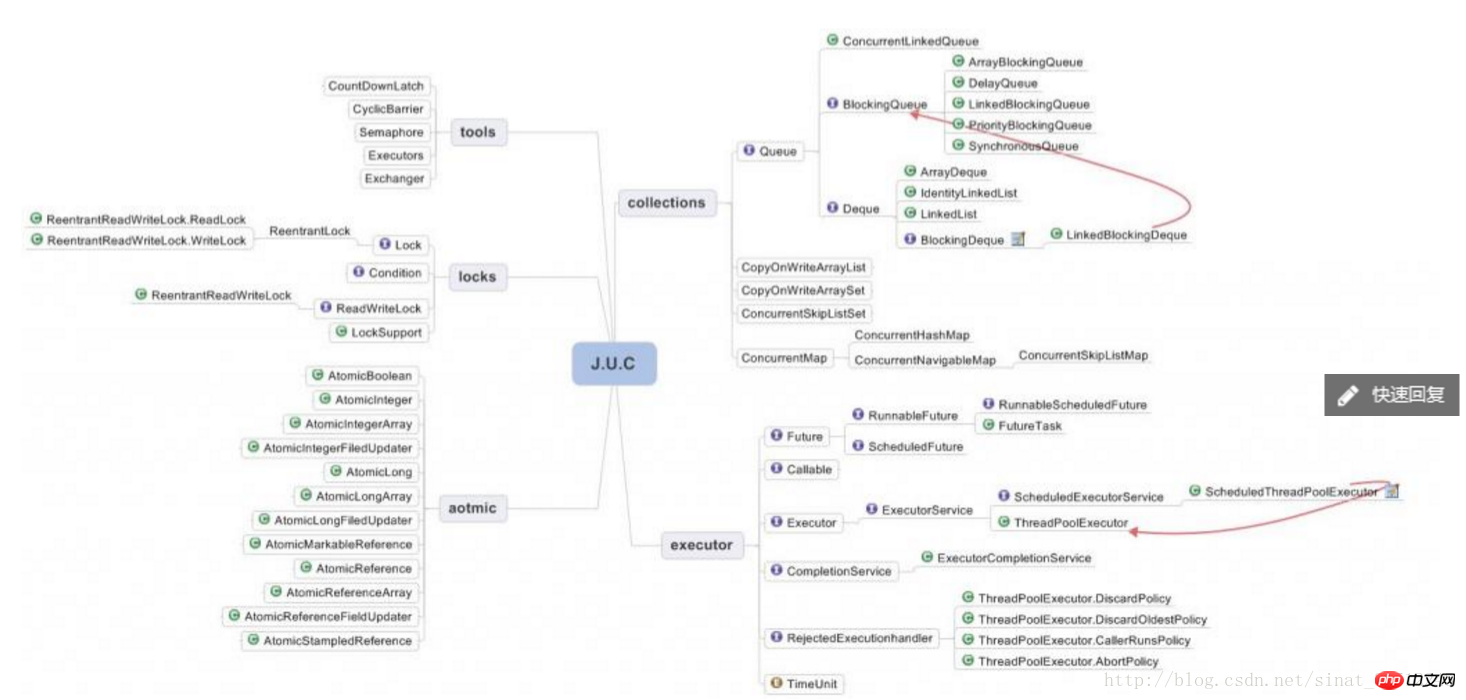
CopyOnWriteArrayList : Verrouillez lors de l'écriture. Lors de l'ajout d'un élément, copiez le conteneur d'origine, copiez-le dans un nouveau conteneur, puis écrivez dans le nouveau conteneur. Après l'écriture, pointez la référence du conteneur d'origine vers le nouveau conteneur et lisez les données. de l'ancien conteneur, une lecture simultanée peut être effectuée, mais il s'agit d'une stratégie de faible cohérence.
Scénarios d'utilisation : CopyOnWriteArrayList convient à une utilisation dans des scénarios où les opérations de lecture sont bien supérieures aux opérations d'écriture, telles que la mise en cache.
Commandes Linux courantes : cd, cp, mv, rm, ps (processus), tar, cat (afficher le contenu), chmod, vim, find, ls
Conditions nécessaires au blocage
Exclusion mutuelle d'au moins une ressource dans un état non partagé
Possédé et en attente
Non- préemption
Attente de boucle
Pour résoudre l'impasse, la première est la prévention des impasses, qui consiste à empêcher les quatre conditions ci-dessus d'être vraies en même temps. La seconde consiste à allouer les ressources de manière raisonnable.
La troisième consiste à utiliser l'algorithme du banquier. Si la quantité restante de ressources demandées par le processus peut être satisfaite par le système d'exploitation, alors allouez-les.
Méthode de communication inter-processus
Pipe (pipe) : Pipe est une méthode de communication semi-duplex Les données ne peuvent circuler que dans une seule direction, et elles ne peuvent circuler que dans une seule direction. dans une direction. Utilisé entre des processus liés. L'affinité de processus fait généralement référence à la relation de processus parent-enfant.
Tube nommé : Le canal nommé est également une méthode de communication semi-duplex, mais il permet la communication entre des processus non liés.
Sémaphore (sémophore) : Un sémaphore est un compteur qui peut être utilisé pour contrôler l'accès aux ressources partagées par plusieurs processus. Il est souvent utilisé comme mécanisme de verrouillage pour empêcher d'autres processus d'accéder à une ressource partagée lorsqu'un processus accède à la ressource. Par conséquent, il est principalement utilisé comme moyen de synchronisation entre les processus et entre différents threads au sein d’un même processus.
File d'attente de messages : La file d'attente de messages est une liste chaînée de messages, stockés dans le noyau et identifiés par l'identifiant de la file d'attente de messages. Les files d'attente de messages pallient aux inconvénients liés à la réduction du nombre d'informations de transmission de signal, aux canaux qui ne peuvent transporter que des flux d'octets non formatés et à des tailles de tampon limitées.
Signal ( sinal ) : Le signal est une méthode de communication relativement complexe utilisée pour informer le processus récepteur qu'un événement s'est produit.
Mémoire partagée (mémoire partagée) : La mémoire partagée consiste à mapper une section de mémoire accessible par d'autres processus. Cette mémoire partagée est créée par un processus, mais accessible par. plusieurs processus. La mémoire partagée est la méthode IPC la plus rapide et est spécifiquement conçue pour remédier aux inefficacités des autres méthodes de communication inter-processus. Il est souvent utilisé conjointement avec d'autres mécanismes de communication, tels que les sémaphores, pour réaliser la synchronisation et la communication entre les processus.
Socket : Socket est également un mécanisme de communication inter-processus. Contrairement à d'autres mécanismes de communication, il peut être utilisé pour la communication de processus entre différentes machines.
La différence et la connexion entre les processus et les threads
L'algorithme de planification des processus du système d'exploitation
Explication détaillée de la structure de stockage hiérarchique du système informatique
Une transaction de base de données fait référence à une seule séquence d'opérations effectuée par une unité logique de travail.

Résumé de l'optimisation de la base de données MySQL
Méthodes courantes pour l'optimisation MYSQL
Moteur de stockage MySQL - la différence entre MyISAM et InnoDB
À propos Base de données SQL Le paradigme du cache de premier niveau d'Hibernate est fourni par Session, il n'existe donc que dans le cycle de vie de Session lorsque le programme appelle save(), update(), saveOrUpdate() et d'autres méthodes. et appelle des requêtes Lors de la liste d'interface, du filtrage, de l'itération, si l'objet correspondant n'existe pas encore dans le cache de session, Hibernate ajoutera l'objet au cache de premier niveau, et le cache disparaîtra à la fermeture de la session.
Le cache de premier niveau d'Hibernate est intégré à la session et ne peut être désinstallé ou configuré de quelque manière que ce soit. Le cache de premier niveau est implémenté à l'aide de la méthode Map clé-valeur. Lors de la mise en cache des objets d'entité, l'objet principal. L'ID de clé est la clé de la carte et l'objet d'entité est la valeur correspondante.
Cache de deuxième niveau Hibernate : placez tous les objets de données obtenus dans le cache de deuxième niveau en fonction de leur ID. La stratégie de cache de deuxième niveau d'Hibernate est une stratégie de cache pour les requêtes d'identification. Lorsque des données sont supprimées, mises à jour ou ajoutées, le cache est mis à jour en même temps.
La différence entre les processus et les threads :
Processus : chaque processus a un code et un espace de données indépendants (contexte du processus). La commutation entre les processus entraînera une surcharge importante. Un processus contient 1 à n threads. .
Threads : les threads du même type partagent du code et de l'espace de données. Chaque thread dispose d'une pile d'exécution et d'un compteur de programme (PC) indépendants, et la surcharge de changement de thread est faible.
Les threads et les processus sont divisés en cinq étapes : création, préparation, exécution, blocage et terminaison.
Multi-processus signifie que le système d'exploitation peut exécuter plusieurs tâches (programmes) en même temps.
Le multi-threading fait référence à l'exécution de plusieurs flux de séquences dans le même programme.
Afin d'implémenter le multi-threading en Java, il existe trois façons. L'une consiste à continuer la classe Thread, l'autre consiste à implémenter l'interface Runable et la troisième consiste à implémenter l'interface Callable.
Switch peut-il utiliser une chaîne comme paramètre ?
a. Avant Java 7, switch ne pouvait prendre en charge que byte, short, char, int ou leurs classes d'encapsulation et types Enum correspondants. Dans Java 7, la prise en charge des chaînes a été ajoutée.
Quelles sont les méthodes publiques d'Object ?
a. La méthode equals teste si deux objets sont égaux
b. La méthode clone copie l'objet
c La méthode getClass renvoie l'objet Class lié à l'objet actuel. object
d. Les méthodes notify, notifyall et wait sont toutes utilisées pour synchroniser les threads d'un objet donné
Les quatre types de références Java, fortes et faibles, et les scénarios dans lesquels elles se trouvent utilisé
a. Utilisez des références logicielles et des références faibles pour résoudre le problème du MOO : utilisez un HashMap pour enregistrer la relation de mappage entre le chemin de l'image et la référence logicielle associée à l'objet image correspondant. Lorsque la mémoire est insuffisante, la JVM le fera. recycle automatiquement ces objets image mis en cache occupés, évitant ainsi efficacement le problème du MOO.
b. Implémentez la mise en cache des objets Java via des méthodes de récupération d'objets accessibles par logiciel : par exemple, si nous créons une classe Employé, si nous devons interroger les informations d'un employé à chaque fois. Même s’il a été interrogé il y a quelques secondes seulement, il doit reconstruire une instance, ce qui prend beaucoup de temps. Nous pouvons combiner des références logicielles et HashMap. Tout d'abord, enregistrez la référence : référencez une instance de l'objet Employee sous la forme d'une référence logicielle et enregistrez la référence au HashMap. La clé est l'identifiant de l'employé et la valeur est la référence logicielle de. cet objet., en revanche, consiste à supprimer la référence et à voir s'il existe une référence logicielle à l'instance Employee dans le cache. Si c'est le cas, récupérez-la à partir de la référence logicielle. S'il n'y a pas de référence logicielle ou si l'instance obtenue à partir de la référence logicielle est nulle, reconstruisez une instance et enregistrez la référence logicielle dans l'instance nouvellement créée.
c. Référence forte : Si un objet a une référence forte, il ne sera pas recyclé par le garbage collector. Même si l'espace mémoire actuel est insuffisant, la JVM ne le récupérera pas, mais générera une erreur OutOfMemoryError, provoquant la fin anormale du programme. Si vous souhaitez rompre l'association entre une référence forte et un objet, vous pouvez attribuer explicitement la référence à null, afin que la JVM recycle l'objet au moment approprié.
d. Référence logicielle : lors de l'utilisation d'une référence logicielle, s'il y a suffisamment d'espace mémoire, la référence logicielle peut continuer à être utilisée sans être recyclée par le garbage collector. Ce n'est que lorsque la mémoire est insuffisante que la référence logicielle sera utilisée. Recyclé par le éboueur.
e. Référence faible : les objets avec des références faibles ont un cycle de vie plus court. Parce que lorsque la JVM effectue un garbage collection, une fois qu'un objet de référence faible est trouvé, la référence faible sera recyclée, que l'espace mémoire actuel soit suffisant ou non. Cependant, comme le garbage collector est un thread de faible priorité, il peut ne pas être en mesure de trouver rapidement les objets de référence faibles.
f. Référence virtuelle : comme son nom l'indique, il s'agit uniquement de nom. Si un objet ne contient qu'une référence virtuelle, cela équivaut à ne pas avoir de référence et peut être recyclé par le ramasse-miettes à tout moment. .
Quelle est la différence entre Hashcode et égal ?
a. Il est également utilisé pour identifier si deux objets sont égaux. Il existe deux types de collections Java : list et set ne permettent pas une implémentation répétée des éléments. vous utilisez égal à À titre de comparaison, s'il y a 1 000 éléments et que vous créez un nouvel élément, vous devez appeler égal 1 000 fois pour les comparer un par un pour voir s'il s'agit du même objet, ce qui réduira considérablement l'efficacité. Le hashcode renvoie en fait l'adresse de stockage de l'objet. S'il n'y a aucun élément à cette position, l'élément est stocké directement au-dessus de lui. Si un élément existe déjà à cette position, la méthode égale est appelée à ce moment pour comparer avec le nouveau. S'ils sont identiques, ils ne seront pas enregistrés et hachés à une autre adresse.
La signification et la différence entre Override et Overload
a. La surcharge, comme son nom l'indique, est le rechargement. Il peut exprimer le polymorphisme de la classe. peut avoir le même nom de fonction mais les noms des paramètres, les valeurs de retour et les types ne peuvent pas être les mêmes ; en d'autres termes, les paramètres, les types et les valeurs de retour peuvent être modifiés mais le nom de la fonction reste inchangé.
b. Cela signifie ride (réécriture). Lorsque la sous-classe hérite de la classe parent, la sous-classe peut définir une méthode avec le même nom et les mêmes paramètres que sa classe parent, lorsque la sous-classe appelle cette fonction, elle sera automatiquement appelée. Méthodes des sous-classes, tandis que les classes parents sont équivalentes à être remplacées (remplacées).
Pour plus de détails, vous pouvez consulter l'analyse d'exemples de la différence entre la surcharge et la réécriture (écrasement) en C++
La différence entre les classes abstraites et les interfaces
Une classe peut. n'hérite que d'une seule classe, mais plusieurs interfaces peuvent être implémentées
b. Il peut y avoir des constructeurs dans les classes abstraites, mais il ne peut pas y avoir de constructeurs dans les interfaces
c. doivent être abstraits, vous pouvez choisir d'implémenter certaines méthodes de base dans des classes abstraites. L'interface nécessite que toutes les méthodes soient abstraites
d. Les classes abstraites peuvent contenir des méthodes statiques, mais les interfaces ne peuvent pas
e. Les classes abstraites peuvent avoir des variables membres ordinaires et les interfaces ne peuvent pas être
Principes et caractéristiques de plusieurs façons d'analyser XML : DOM, SAX, PULLa.DOM : consommation de mémoire : lisez d'abord tous les documents XML en mémoire, puis utilisez l'API DOM pour accéder à l'arborescence et obtenir des données. C'est très simple à écrire, mais cela consomme beaucoup de mémoire. Si les données sont trop volumineuses et que le téléphone n'est pas assez puissant, le téléphone peut planter b.SAX : efficacité d'analyse élevée, faible utilisation de la mémoire, piloté par les événements : plus simplement, il analyse le document de manière séquentielle. numérisation Notifiez la fonction de traitement des événements lorsque vous atteignez le début et la fin du document (document), le début et la fin de l'élément (élément), la fin du document (document), etc., et la fonction de traitement des événements prendra les correspondances actions, puis continuez la même analyse jusqu'à la fin du document.c.PULL : Semblable à SAX, il est également piloté par les événements. Nous pouvons appeler sa méthode next() pour obtenir le prochain événement d'analyse (c'est-à-dire le document de début, le document de fin, la balise de début, la balise de fin). à un certain moment Lorsqu'il y a un élément, vous pouvez appeler la méthode getAttributte() de XmlPullParser pour obtenir la valeur de l'attribut, ou vous pouvez appeler son nextText() pour obtenir la valeur de ce nœud.
La différence entre wait() et sleep()
sleep vient de la classe Thread, et wait vient de la classe Object
Pendant le processus d'appel de sleep( ), le thread ne sera pas libéré du verrouillage d'objet. Le thread qui appelle la méthode wait libérera le verrouillage de l'objet
Le sommeil n'abandonne pas les ressources système après la mise en veille. Wait abandonne les ressources système et d'autres threads peuvent occuper le processeur
veille (millisecondes) doit spécifier une heure de sommeil, une heure Il se réveillera automatiquement à son arrivée
La différence entre le tas et la pile en JAVA, parlons du mécanisme de mémoire de Java
a. et les références d'objet sont toutes allouées sur la pile
b. La mémoire tas est utilisée pour stocker les objets et les tableaux créés par les nouvelles
c. pour les variables de classe dans le tas lors de son chargement, l'adresse mémoire dans le tas est stockée dans la pile
d Variables d'instance : lorsque vous utilisez le mot-clé java new, le système alloue de l'espace aux variables dans le tas. qui n'est pas nécessairement continue, mais est allouée à des variables basées sur une mémoire dispersée. L'adresse de la mémoire du tas est convertie en une longue chaîne de nombres via un algorithme de hachage pour représenter « l'emplacement physique » de cette variable dans le tas. Le cycle de vie de l'instance. variable – lorsque la référence à la variable d'instance est perdue, elle sera GC (garbage collector) Inclus dans la "liste" recyclable, mais la mémoire dans le tas n'est pas libérée immédiatement
e Variables locales : déclarées. dans une certaine méthode ou un certain segment de code (comme une boucle for), exécuté dans sa Lorsque la mémoire est allouée sur la pile, lorsque la variable locale sort de portée, la mémoire est immédiatement libérée
Le principe de mise en œuvre du polymorphisme JAVA
a. De manière abstraite, le polymorphisme signifie que les mêmes messages peuvent se comporter de différentes manières selon à qui ils sont envoyés. (L'envoi d'un message est un appel de fonction)
b. Le principe d'implémentation est la liaison dynamique. La méthode appelée par le programme est liée dynamiquement pendant l'exécution. Le traçage du code source permet de constater que la JVM trouve le paramètre approprié. par voie de transformation automatique.
Recommandations associées :
Résumé des questions et réponses des entretiens de la collection Java
Analyse de l'ordre de chargement des classes en Java (couramment utilisé dans questions d'entretien)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1359
1359
 52
52

 Cinq questions et réponses courantes en matière d'entretien en langage Go
Jun 01, 2023 pm 08:10 PM
Cinq questions et réponses courantes en matière d'entretien en langage Go
Jun 01, 2023 pm 08:10 PM
En tant que langage de programmation devenu très populaire ces dernières années, le langage Go est devenu un point chaud pour les entretiens dans de nombreuses entreprises. Pour les débutants du langage Go, comment répondre aux questions pertinentes lors du processus d’entretien est une question qui mérite d’être explorée. Voici cinq questions et réponses courantes d’entretien en langage Go pour référence pour les débutants. Veuillez présenter comment fonctionne le mécanisme de récupération de place du langage Go ? Le mécanisme de récupération de place du langage Go est basé sur l'algorithme de balayage de marque et l'algorithme de marquage à trois couleurs. Lorsque l'espace mémoire du programme Go n'est pas suffisant, le garbage collector Go
 Résumé des questions d'entretien React front-end en 2023 (Collection)
Aug 04, 2020 pm 05:33 PM
Résumé des questions d'entretien React front-end en 2023 (Collection)
Aug 04, 2020 pm 05:33 PM
En tant que site Web d'apprentissage de la programmation bien connu, le site Web chinois php a compilé pour vous des questions d'entretien React afin d'aider les développeurs front-end à préparer et à éliminer les obstacles aux entretiens React.
 Une collection complète de questions et réponses d'entretien Web front-end sélectionnées en 2023 (Collection)
Apr 08, 2021 am 10:11 AM
Une collection complète de questions et réponses d'entretien Web front-end sélectionnées en 2023 (Collection)
Apr 08, 2021 am 10:11 AM
Cet article résume certaines questions d'entretien Web frontales sélectionnées qui méritent d'être collectées (avec réponses). Il a une certaine valeur de référence. Les amis dans le besoin peuvent s'y référer. J'espère qu'il sera utile à tout le monde.
 50 questions d'entretien angulaires que vous devez maîtriser (Collection)
Jul 23, 2021 am 10:12 AM
50 questions d'entretien angulaires que vous devez maîtriser (Collection)
Jul 23, 2021 am 10:12 AM
Cet article partagera avec vous 50 questions d'entretien Angular qu'il faut maîtriser. Ces 50 questions d'entretien seront analysées en trois parties : débutant, intermédiaire et avancé, et vous aideront à bien les comprendre !
 Terminal Alibaba : 1 million de demandes de connexion par jour, 8 Go de mémoire, comment définir les paramètres JVM ?
Aug 15, 2023 pm 04:31 PM
Terminal Alibaba : 1 million de demandes de connexion par jour, 8 Go de mémoire, comment définir les paramètres JVM ?
Aug 15, 2023 pm 04:31 PM
La semaine dernière, un camarade de classe s'est vu poser cette question lors d'un entretien technique avec Alibaba Cloud : en supposant une plate-forme avec 1 million de demandes de connexion par jour et un nœud de service avec 8 Go de mémoire, comment définir les paramètres JVM ? Si vous pensez que la réponse n’est pas idéale, venez me demander un avis.
 Intervieweur : Que savez-vous de la haute simultanéité ? Moi : euh...
Jul 26, 2023 pm 04:07 PM
Intervieweur : Que savez-vous de la haute simultanéité ? Moi : euh...
Jul 26, 2023 pm 04:07 PM
La haute concurrence est une expérience que presque tous les programmeurs souhaitent vivre. La raison est simple : à mesure que le trafic augmente, nous rencontrerons divers problèmes techniques, tels qu'un délai de réponse de l'interface, une charge CPU accrue, des GC fréquents, des blocages, un stockage de données volumineux, etc.
 Partage des questions d'entretien à haute fréquence Vue en 2023 (avec analyse des réponses)
Aug 01, 2022 pm 08:08 PM
Partage des questions d'entretien à haute fréquence Vue en 2023 (avec analyse des réponses)
Aug 01, 2022 pm 08:08 PM
Cet article résume pour vous quelques questions d'entretien à haute fréquence sélectionnées en 2023 (avec réponses) qui valent la peine d'être collectées. Il a une certaine valeur de référence. Les amis dans le besoin peuvent s'y référer. J'espère qu'il sera utile à tout le monde.
 Jetez un œil à ces questions d'entretien préliminaires pour vous aider à maîtriser les points de connaissances à haute fréquence (4)
Feb 20, 2023 pm 07:19 PM
Jetez un œil à ces questions d'entretien préliminaires pour vous aider à maîtriser les points de connaissances à haute fréquence (4)
Feb 20, 2023 pm 07:19 PM
10 questions par jour. Après 100 jours, vous maîtriserez tous les points de connaissances à haute fréquence des entretiens front-end. ! ! , en lisant l'article, j'espère que vous ne regardez pas directement les réponses, mais demandez-vous d'abord si vous le savez, et si oui, quelle est votre réponse ? Pensez-y et comparez-la avec la réponse. Serait-ce mieux ? Bien sûr, si vous avez une meilleure réponse que la mienne, veuillez laisser un message dans la zone de commentaire et discuter ensemble de la beauté de la technologie.
