

Cet article vous présente une introduction à l'optimisation SQL pour les requêtes de table dans javaweb. Il a une certaine valeur de référence. Les amis dans le besoin peuvent s'y référer. J'espère qu'il vous sera utile.
Contexte
Cette optimisation SQL est destinée aux requêtes de table dans javaweb.
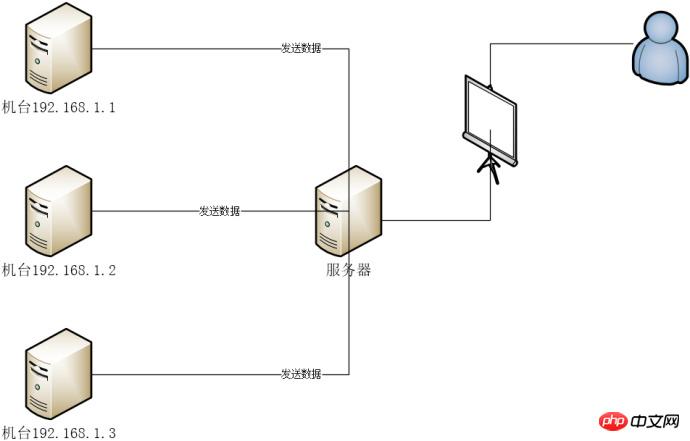
N machines envoient des données commerciales au serveur , le programme serveur stocke les données dans la base de données MySQL. Le programme javaweb du serveur affiche les données sur la page Web pour que les utilisateurs puissent les consulter.
Séparation maître-esclave autonome Windows
A été divisée en tables et bases de données, par année, par année Table des talents
Chaque table contient environ 200 000 données
3 jours de requête de données 70-80s
3-5s
Impossible d'utiliser la pagination SQL, ne peut utiliser Java que pour la pagination.
Si vous configurez Druid, vous pouvez directement afficher le temps d'exécution SQL et la requête uri sur la page Druid Time
utilise System.currentTimeMillis dans le code d'arrière-plan pour calculer le décalage horaire.
Conclusion : L'arrière-plan est lent et la requête SQL est lente
Le l'épissage SQL est trop long, atteignant 3 000 lignes, certains même 8 000 lignes, la plupart d'entre elles sont des opérations d'union toutes, et il y a des requêtes imbriquées inutiles et des champs inutiles interrogés
Utilisez expliquer pour afficher le plan d'exécution, à l'exception du temps, un seul champ dans la condition Where utilise l'index
Remarque : l'optimisation étant terminée, le SQL précédent est introuvable, je ne peux donc utiliser que YY ici.
L'effet n'est pas si évident
L'effet n'est pas si évident évidemment
décomposer l'opération union all, par exemple (une union all sql est aussi très longue)
select aa from bb_2018_10_01 left join ... on .. left join .. on .. where .. union all select aa from bb_2018_10_02 left join ... on .. left join .. on .. where .. union all select aa from bb_2018_10_03 left join ... on .. left join .. on .. where .. union all select aa from bb_2018_10_04 left join ... on .. left join .. on .. where ..
Décomposez le SQL ci-dessus en plusieurs SQL pour l'exécution, et résumez enfin les données, ce qui est environ 20 secondes plus rapide.
select aa from bb_2018_10_01 left join ... on .. left join .. on .. where ..
select aa from bb_2018_10_02 left join ... on .. left join .. on .. where ..
Utiliser Java Fonctionnement de la programmation asynchrone, le SQL décomposé est exécuté de manière asynchrone et les données sont finalement résumées. CountDownLatch et ExecutorService sont utilisés ici. L'exemple de code est le suivant :
// 获取时间段所有天数
List<String> days = MyDateUtils.getDays(requestParams.getStartTime(), requestParams.getEndTime());
// 天数长度
int length = days.size();
// 初始化合并集合,并指定大小,防止数组越界
List<你想要的数据类型> list = Lists.newArrayListWithCapacity(length);
// 初始化线程池
ExecutorService pool = Executors.newFixedThreadPool(length);
// 初始化计数器
CountDownLatch latch = new CountDownLatch(length);
// 查询每天的时间并合并
for (String day : days) {
Map<String, Object> param = Maps.newHashMap();
// param 组装查询条件
pool.submit(new Runnable() {
@Override
public void run() {
try {
// mybatis查询sql
// 将结果汇总
list.addAll(查询结果);
} catch (Exception e) {
logger.error("getTime异常", e);
} finally {
latch.countDown();
}
}
});
}
try {
// 等待所有查询结束
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
// list为汇总集合
// 如果有必要,可以组装下你想要的业务数据,计算什么的,如果没有就没了Le résultat est 20 à 30 s plus rapide
Ce qui suit est un exemple de ma configuration. Ajout de la résolution du saut de nom, 4 à 5 secondes plus rapide. D'autres configurations sont déterminées par vous-même
[client] port=3306 [mysql] no-beep default-character-set=utf8 [mysqld] server-id=2 relay-log-index=slave-relay-bin.index relay-log=slave-relay-bin slave-skip-errors=all #跳过所有错误 skip-name-resolve port=3306 datadir="D:/mysql-slave/data" character-set-server=utf8 default-storage-engine=INNODB sql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION" log-output=FILE general-log=0 general_log_file="WINDOWS-8E8V2OD.log" slow-query-log=1 slow_query_log_file="WINDOWS-8E8V2OD-slow.log" long_query_time=10 # Binary Logging. # log-bin # Error Logging. log-error="WINDOWS-8E8V2OD.err" # 整个数据库最大连接(用户)数 max_connections=1000 # 每个客户端连接最大的错误允许数量 max_connect_errors=100 # 表描述符缓存大小,可减少文件打开/关闭次数 table_open_cache=2000 # 服务所能处理的请求包的最大大小以及服务所能处理的最大的请求大小(当与大的BLOB字段一起工作时相当必要) # 每个连接独立的大小.大小动态增加 max_allowed_packet=64M # 在排序发生时由每个线程分配 sort_buffer_size=8M # 当全联合发生时,在每个线程中分配 join_buffer_size=8M # cache中保留多少线程用于重用 thread_cache_size=128 # 此允许应用程序给予线程系统一个提示在同一时间给予渴望被运行的线程的数量. thread_concurrency=64 # 查询缓存 query_cache_size=128M # 只有小于此设定值的结果才会被缓冲 # 此设置用来保护查询缓冲,防止一个极大的结果集将其他所有的查询结果都覆盖 query_cache_limit=2M # InnoDB使用一个缓冲池来保存索引和原始数据 # 这里你设置越大,你在存取表里面数据时所需要的磁盘I/O越少. # 在一个独立使用的数据库服务器上,你可以设置这个变量到服务器物理内存大小的80% # 不要设置过大,否则,由于物理内存的竞争可能导致操作系统的换页颠簸. innodb_buffer_pool_size=1G # 用来同步IO操作的IO线程的数量 # 此值在Unix下被硬编码为4,但是在Windows磁盘I/O可能在一个大数值下表现的更好. innodb_read_io_threads=16 innodb_write_io_threads=16 # 在InnoDb核心内的允许线程数量. # 最优值依赖于应用程序,硬件以及操作系统的调度方式. # 过高的值可能导致线程的互斥颠簸. innodb_thread_concurrency=9 # 0代表日志只大约每秒写入日志文件并且日志文件刷新到磁盘. # 1 ,InnoDB会在每次提交后刷新(fsync)事务日志到磁盘上 # 2代表日志写入日志文件在每次提交后,但是日志文件只有大约每秒才会刷新到磁盘上 innodb_flush_log_at_trx_commit=2 # 用来缓冲日志数据的缓冲区的大小. innodb_log_buffer_size=16M # 在日志组中每个日志文件的大小. innodb_log_file_size=48M # 在日志组中的文件总数. innodb_log_files_in_group=3 # 在被回滚前,一个InnoDB的事务应该等待一个锁被批准多久. # InnoDB在其拥有的锁表中自动检测事务死锁并且回滚事务. # 如果你使用 LOCK TABLES 指令, 或者在同样事务中使用除了InnoDB以外的其他事务安全的存储引擎 # 那么一个死锁可能发生而InnoDB无法注意到. # 这种情况下这个timeout值对于解决这种问题就非常有帮助. innodb_lock_wait_timeout=30 # 开启定时 event_scheduler=ON
Vite 4-5s
L'effet n'est pas si évident
Pour cet article, je me sens moi-même très surpris. Le SQL d'origine, b est l'index
select aa from bb_2018_10_02 left join ... on .. left join .. on .. where b = 'xxx'
Il devrait y avoir une union all avant, l'union all est exécutée un par un et le résultat récapitulatif final. est obtenu. Modifié en
select aa from bb_2018_10_02 left join ... on .. left join .. on .. inner join
(
select 'xxx1' as b2
union all
select 'xxx2' as b2
union all
select 'xxx3' as b2
union all
select 'xxx3' as b2
) t on b = t.b2Le résultat est 3 à 4 secondes plus rapide
Selon l'opération ci-dessus, requête en 3 jours L'efficacité a atteint environ 8 secondes et ne peut pas être plus rapide. L'utilisation du processeur et de la mémoire de MySQL n'est pas très élevée. Pourquoi la requête est-elle si lente ? Le nombre maximum de données est de 600 000 en 3 jours. Les données sont liées à certaines tables de dictionnaire, ce n'est donc pas comme ça. En continuant à s'appuyer sur les informations fournies sur Internet, une série d'opérations sexy est fondamentalement inutile et il n'y a aucun moyen.
Après avoir analysé l'optimisation SQL, c'est déjà ok je me demande si c'est un problème de lecture et d'écriture du disque. Déployez les programmes optimisés dans différents environnements sur site. L'un a un SSD et l'autre n'a pas de SSD. Il a été constaté que l’efficacité des requêtes était très différente. Après des tests avec un logiciel, il a été constaté que la vitesse de lecture et d'écriture du SSD est de 700 à 800 M/s, et la vitesse de lecture et d'écriture d'un disque dur mécanique ordinaire est de 70 à 80 M/s.
Résultats de l'optimisation : répondre aux attentes.
Conclusion de l'optimisation : l'optimisation SQL n'est pas seulement l'optimisation de SQL lui-même, mais dépend également de ses propres conditions matérielles, de l'impact d'autres applications et de l'optimisation de son propre code.
Ce qui précède représente l'intégralité du contenu de cet article. Pour des informations plus intéressantes sur Java, vous pouvez prêter attention au Tutoriel vidéo Java et au Développement Java. tutoriel sur le site PHP chinois Colonne ! ! !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Outils de téléchargement et d'installation Linux courants
Outils de téléchargement et d'installation Linux courants
 Style de barre de défilement CSS
Style de barre de défilement CSS
 utilisation de l'instruction switch
utilisation de l'instruction switch
 Le rôle de la sonde php
Le rôle de la sonde php
 Comment lire les données de contrôle de macro en javascript
Comment lire les données de contrôle de macro en javascript
 présentation du moteur MySQL
présentation du moteur MySQL
 Comment résoudre le problème selon lequel le code js ne peut pas s'exécuter après le formatage
Comment résoudre le problème selon lequel le code js ne peut pas s'exécuter après le formatage
 Il y a une page vierge supplémentaire dans Word et je ne parviens pas à la supprimer.
Il y a une page vierge supplémentaire dans Word et je ne parviens pas à la supprimer.









![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



