
 développement back-end
Tutoriel Python
Introduction aux connaissances pertinentes sur la complexité des algorithmes de liste séquentielle en Python
développement back-end
Tutoriel Python
Introduction aux connaissances pertinentes sur la complexité des algorithmes de liste séquentielle en Python
Introduction aux connaissances pertinentes sur la complexité des algorithmes de liste séquentielle en Python

Cet article vous apporte des connaissances sur la complexité des algorithmes de tables séquentielles en Python. Il a une certaine valeur de référence. Les amis dans le besoin peuvent s'y référer.
1. Introduction de la complexité de l'algorithme
Pour les propriétés temporelles et spatiales de l'algorithme, la chose la plus importante est sa ampleur et sa tendance, donc la fonction pour mesurer sa complexité Le facteur constant peut être ignoré.
La notation Big O est généralement la complexité temporelle asymptotique d'un certain algorithme. La complexité des fonctions de complexité asymptotique couramment utilisées est comparée comme suit :
O(1)<O(logn)<O(n)<O(nlogn)<O(n^2)<O(n^3)<O(2^n)<O(n!)<O(n^n)
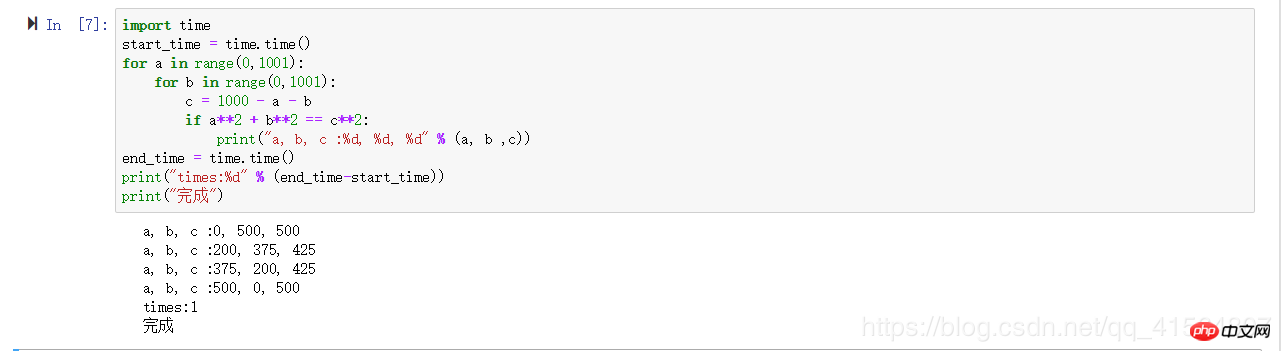
Un exemple d'introduction de la complexité temporelle, veuillez comparer les deux exemples de code pour voir les résultats du calcul
import time
start_time = time.time()
for a in range(0,1001):
for b in range(0,1001):
for c in range(0,1001):
if a+b+c ==1000 and a**2 + b**2 == c**2:
print("a, b, c :%d, %d, %d" % (a, b ,c))
end_time = time.time()
print("times:%d" % (end_time-start_time))
print("完成")

import time
start_time = time.time()
for a in range(0,1001):
for b in range(0,1001):
c = 1000 - a - b
if a**2 + b**2 == c**2:
print("a, b, c :%d, %d, %d" % (a, b ,c))
end_time = time.time()
print("times:%d" % (end_time-start_time))
print("完成")
Comment calculer la complexité temporelle :
# 时间复杂度计算 # 1.基本步骤,基本操作,复杂度是O(1) # 2.顺序结构,按加法计算 # 3.循环,按照乘法 # 4.分支结构采用其中最大值 # 5.计算复杂度,只看最高次项,例如n^2+2的复杂度是O(n^2)
2. Complexité temporelle de la liste séquentielle
Test de complexité temporelle de la liste
# 测试
from timeit import Timer
def test1():
list1 = []
for i in range(10000):
list1.append(i)
def test2():
list2 = []
for i in range(10000):
# list2 += [i] # +=本身有优化,所以不完全等于list = list + [i]
list2 = list2 + [i]
def test3():
list3 = [i for i in range(10000)]
def test4():
list4 = list(range(10000))
def test5():
list5 = []
for i in range(10000):
list5.extend([i])
timer1 = Timer("test1()","from __main__ import test1")
print("append:",timer1.timeit(1000))
timer2 = Timer("test2()","from __main__ import test2")
print("+:",timer2.timeit(1000))
timer3 = Timer("test3()","from __main__ import test3")
print("[i for i in range]:",timer3.timeit(1000))
timer4 = Timer("test4()","from __main__ import test4")
print("list(range):",timer4.timeit(1000))
timer5 = Timer("test5()","from __main__ import test5")
print("extend:",timer5.timeit(1000))
Résultats de sortie

Complexité des méthodes dans la liste :
# 列表方法中复杂度 # index O(1) # append 0(1) # pop O(1) 无参数表示是从尾部向外取数 # pop(i) O(n) 从指定位置取,也就是考虑其最复杂的状况是从头开始取,n为列表的长度 # del O(n) 是一个个删除 # iteration O(n) # contain O(n) 其实就是in,也就是说需要遍历一遍 # get slice[x:y] O(K) 取切片,即K为Y-X # del slice O(n) 删除切片 # set slice O(n) 设置切片 # reverse O(n) 逆置 # concatenate O(k) 将两个列表加到一起,K为第二个列表的长度 # sort O(nlogn) 排序,和排序算法有关 # multiply O(nk) K为列表的长度
Complexité des méthodes dans le dictionnaire (supplémentaire)
# 字典中的复杂度 # copy O(n) # get item O(1) # set item O(1) 设置 # delete item O(1) # contains(in) O(1) 字典不用遍历,所以可以一次找到 # iteration O(n)
3. Structure des données d'une table de séquence
Les informations complètes d'une table de séquence comprennent deux parties, une partie est l'ensemble des éléments de la table et l'autre une partie est d'obtenir un fonctionnement correct. Les informations qui doivent être enregistrées comprennent principalement la capacité de la zone de stockage des éléments et le nombre d'éléments dans la table actuelle.
Combinaison d'en-tête et de zone de données : structure intégrée : informations d'en-tête (capacité d'enregistrement et nombre d'éléments existants) et zone de données pour un stockage continu
Structure séparée : les informations d'en-tête et la zone de données ne sont pas stockées en continu, et certaines informations seront utilisées pour stocker des unités d'adresse pour pointer vers la zone de données réelle
Différences et avantages et inconvénients entre les deux :
# 1.一体式结构:数据必须整体迁移 # 2.分离式结构:在数据动态的过错中有优势
# 申请多大的空间? # 扩充政策: # 1.每次增加相同的空间,线性增长 # 特点:节省空间但操作次数多 # 2.每次扩容加倍,例如每次扩充增加一倍 # 特点:减少执行次数,用空间换效率 # 数据表的操作: # 1.增加元素: # a.尾端加入元素,时间复杂度为O(1) # b.非保序的元素插入:O(1) # c.保序的元素插入:时间度杂度O(n)(保序不改变其原有的顺序) # 2.删除元素: # a.末尾:时间复杂度:O(1) # b.非保序:O(1) # c.保序:O(n) # python中list与tuple采用了顺序表的实现技术 # list可以按照下标索引,时间度杂度O(1),采用的是分离式的存储区,动态顺序表
4. Stratégies d'expansion d'espace variable en python
1. table (ou une petite table), le système alloue une zone de stockage pouvant contenir 8 éléments
2 Lors d'une opération d'insertion (insertion, ajout), si la zone de stockage de l'élément est pleine, remplacez-la par un stockage. superficie quatre fois plus grande
3. Si la table est déjà très grande (le seuil est de 50 000), changez de politique et adoptez une méthode de doublement. Pour éviter trop d'espace libre.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python ont leurs propres avantages et inconvénients, et le choix dépend des besoins du projet et des préférences personnelles. 1.Php convient au développement rapide et à la maintenance des applications Web à grande échelle. 2. Python domine le domaine de la science des données et de l'apprentissage automatique.
 Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python et JavaScript ont leurs propres avantages et inconvénients en termes de communauté, de bibliothèques et de ressources. 1) La communauté Python est amicale et adaptée aux débutants, mais les ressources de développement frontal ne sont pas aussi riches que JavaScript. 2) Python est puissant dans les bibliothèques de science des données et d'apprentissage automatique, tandis que JavaScript est meilleur dans les bibliothèques et les cadres de développement frontaux. 3) Les deux ont des ressources d'apprentissage riches, mais Python convient pour commencer par des documents officiels, tandis que JavaScript est meilleur avec MDNWEBDOCS. Le choix doit être basé sur les besoins du projet et les intérêts personnels.
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Comment choisir la version Pytorch sur Centos
Apr 14, 2025 pm 06:51 PM
Comment choisir la version Pytorch sur Centos
Apr 14, 2025 pm 06:51 PM
Lors de l'installation de Pytorch sur le système CentOS, vous devez sélectionner soigneusement la version appropriée et considérer les facteurs clés suivants: 1. Compatibilité de l'environnement du système: Système d'exploitation: Il est recommandé d'utiliser CentOS7 ou plus. CUDA et CUDNN: La version Pytorch et la version CUDA sont étroitement liées. Par exemple, Pytorch1.9.0 nécessite CUDA11.1, tandis que Pytorch2.0.1 nécessite CUDA11.3. La version CUDNN doit également correspondre à la version CUDA. Avant de sélectionner la version Pytorch, assurez-vous de confirmer que des versions compatibles CUDA et CUDNN ont été installées. Version Python: branche officielle de Pytorch
 Comment exécuter des programmes dans Terminal Vscode
Apr 15, 2025 pm 06:42 PM
Comment exécuter des programmes dans Terminal Vscode
Apr 15, 2025 pm 06:42 PM
Dans VS Code, vous pouvez exécuter le programme dans le terminal via les étapes suivantes: Préparez le code et ouvrez le terminal intégré pour vous assurer que le répertoire de code est cohérent avec le répertoire de travail du terminal. Sélectionnez la commande Run en fonction du langage de programmation (tel que Python de Python your_file_name.py) pour vérifier s'il s'exécute avec succès et résoudre les erreurs. Utilisez le débogueur pour améliorer l'efficacité du débogage.
 Python: automatisation, script et gestion des tâches
Apr 16, 2025 am 12:14 AM
Python: automatisation, script et gestion des tâches
Apr 16, 2025 am 12:14 AM
Python excelle dans l'automatisation, les scripts et la gestion des tâches. 1) Automatisation: La sauvegarde du fichier est réalisée via des bibliothèques standard telles que le système d'exploitation et la fermeture. 2) Écriture de script: utilisez la bibliothèque PSUTIL pour surveiller les ressources système. 3) Gestion des tâches: utilisez la bibliothèque de planification pour planifier les tâches. La facilité d'utilisation de Python et la prise en charge de la bibliothèque riche en font l'outil préféré dans ces domaines.
 L'extension VScode est-elle malveillante?
Apr 15, 2025 pm 07:57 PM
L'extension VScode est-elle malveillante?
Apr 15, 2025 pm 07:57 PM
Les extensions de code vs posent des risques malveillants, tels que la cachette de code malveillant, l'exploitation des vulnérabilités et la masturbation comme des extensions légitimes. Les méthodes pour identifier les extensions malveillantes comprennent: la vérification des éditeurs, la lecture des commentaires, la vérification du code et l'installation avec prudence. Les mesures de sécurité comprennent également: la sensibilisation à la sécurité, les bonnes habitudes, les mises à jour régulières et les logiciels antivirus.
 Comment installer nginx dans Centos
Apr 14, 2025 pm 08:06 PM
Comment installer nginx dans Centos
Apr 14, 2025 pm 08:06 PM
CENTOS L'installation de Nginx nécessite de suivre les étapes suivantes: Installation de dépendances telles que les outils de développement, le devet PCRE et l'OpenSSL. Téléchargez le package de code source Nginx, dézippez-le et compilez-le et installez-le, et spécifiez le chemin d'installation AS / USR / LOCAL / NGINX. Créez des utilisateurs et des groupes d'utilisateurs de Nginx et définissez les autorisations. Modifiez le fichier de configuration nginx.conf et configurez le port d'écoute et le nom de domaine / adresse IP. Démarrez le service Nginx. Les erreurs communes doivent être prêtées à prêter attention, telles que les problèmes de dépendance, les conflits de port et les erreurs de fichiers de configuration. L'optimisation des performances doit être ajustée en fonction de la situation spécifique, comme l'activation du cache et l'ajustement du nombre de processus de travail.
