
 base de données
tutoriel mysql
Qu'est-ce que la réplication maître-esclave MySQL ? Comment configurer la mise en œuvre ?
base de données
tutoriel mysql
Qu'est-ce que la réplication maître-esclave MySQL ? Comment configurer la mise en œuvre ?
Qu'est-ce que la réplication maître-esclave MySQL ? Comment configurer la mise en œuvre ?

Le contenu de cet article est de vous présenter qu'est-ce que la réplication maître-esclave MySql ? Comment configurer la mise en œuvre ? Il a une certaine valeur de référence. Les amis dans le besoin peuvent s'y référer. J'espère qu'il vous sera utile.
1. Qu'est-ce que la réplication maître-esclave MySQL
La réplication maître-esclave MySQL est l'une de ses fonctions les plus importantes. La réplication maître-esclave signifie qu'un serveur agit en tant que serveur de base de données maître et qu'un ou plusieurs autres serveurs agissent en tant que serveurs de base de données esclaves. Les données du serveur maître sont automatiquement copiées sur les serveurs esclaves. Pour la réplication multiniveau, le serveur de base de données peut agir en tant que maître ou esclave. La base de la réplication maître-esclave MySQL est que le serveur maître enregistre les journaux binaires des modifications de la base de données et que le serveur esclave effectue automatiquement les mises à jour via les journaux binaires du serveur maître.
2. Types de réplication maître-esclave Mysq
1. Réplication basée sur les instructions :
L'instruction exécutée sur le serveur maître est à nouveau exécutée sur le serveur esclave, et dans MySQL - Pris en charge après la version 3.23.
Problèmes existants : l'heure peut ne pas être complètement synchronisée, provoquant des écarts, et l'utilisateur exécutant l'instruction peut également être un utilisateur différent.
2. Réplication basée sur les lignes :
Copiez le contenu adapté directement sur le serveur principal, sans vous soucier de l'instruction qui a provoqué le changement de contenu. Dans MySQL-5.0. Sera introduit dans une version ultérieure. .
Problèmes existants : par exemple, il y a 10 000 utilisateurs dans une table de salaires, et nous ajoutons le salaire de chaque utilisateur de 1 000, puis la réplication basée sur les lignes copiera le contenu de 10 000 lignes, ce qui entraînera une surcharge relativement importante, tandis que la réplication basée sur les instructions ne nécessite qu'une seule instruction.
3. Réplication de type mixte :
MySQL utilise la réplication basée sur les instructions par défaut lorsque la réplication basée sur les instructions pose des problèmes, la réplication basée sur les lignes sera utilisée et MySQL choisira automatiquement .
Dans l'architecture de réplication maître-esclave MySQL, les opérations de lecture peuvent être effectuées sur tous les serveurs, tandis que les opérations d'écriture ne peuvent être effectuées que sur le serveur maître. Bien que l'architecture de réplication maître-esclave offre une extension pour les opérations de lecture, s'il y a plus d'opérations d'écriture (plusieurs serveurs esclaves doivent synchroniser les données du serveur maître), le serveur maître deviendra inévitablement un goulot d'étranglement en termes de performances dans la réplication du serveur maître unique. modèle.
3. Le principe de fonctionnement de la réplication maître-esclave Mysql
1 : Les instructions exécutées sur le serveur maître sont. exécuté sur le serveur esclave Exécutez-le à nouveau. Il est pris en charge dans MySQL-3.23 et les versions ultérieures.
Problèmes existants : l'heure peut ne pas être complètement synchronisée, provoquant des écarts, et l'utilisateur qui exécute l'instruction peut également être un utilisateur différent.2, réplication basée sur les lignes : copiez directement le contenu adapté sur le serveur principal, sans vous soucier de l'instruction qui a provoqué le changement, introduite après MySQL-5.0. version.
Problèmes existants : par exemple, il y a 10 000 utilisateurs dans une table de salaires, et nous ajoutons le salaire de chaque utilisateur de 1 000, puis la réplication basée sur les lignes copiera le contenu de 10 000 lignes, ce qui entraînera une surcharge relativement importante, tandis que la réplication basée sur les instructions ne nécessite qu'une seule instruction.3, réplication de type mixte : MySQL utilise la réplication basée sur les instructions par défaut, et la réplication basée sur les lignes sera utilisée lorsque la réplication basée sur les instructions pose des problèmes, MySQL le sélectionnera automatiquement.
Dans l'architecture de réplication maître-esclave MySQL, les opérations de lecture peuvent être effectuées sur tous les serveurs, tandis que les opérations d'écriture ne peuvent être effectuées que sur le serveur maître. Bien que l'architecture de réplication maître-esclave offre une extension pour les opérations de lecture, s'il y a plus d'opérations d'écriture (plusieurs serveurs esclaves doivent synchroniser les données du serveur maître), le serveur maître deviendra inévitablement un goulot d'étranglement en termes de performances dans la réplication du serveur maître unique. modèle. Trois principes de fonctionnement de la réplication maître-esclave MySQL Comme indiqué ci-dessous :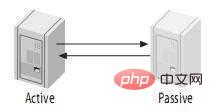
Tout d'abord, un processus fera du processus de copie des journaux bin-log et d'analyse des journaux et de leur exécution propre un processus en série. Les performances sont soumises à certaines limitations, et le délai de réplication asynchrone sera également relativement long. .
De plus, une fois que le côté esclave a obtenu le journal bin du côté maître, il doit analyser le contenu du journal, puis l'exécuter lui-même. Au cours de ce processus, un grand nombre de modifications peuvent avoir eu lieu du côté du maître et un grand nombre de nouveaux journaux ont pu être ajoutés. Si une erreur irréparable se produit dans le stockage du Master à ce stade, toutes les modifications apportées à ce stade ne seront jamais récupérées. Si la pression sur l'esclave est relativement élevée, ce processus peut prendre plus de temps.
Afin d'améliorer les performances de réplication et de résoudre les risques existants, les versions ultérieures de MySQL transféreront l'action de réplication côté esclave vers deux processus. La personne qui a proposé ce plan d'amélioration est « Jeremy Zawodny », ingénieur chez Yahoo! Cela résout non seulement le problème de performances, mais réduit également le temps de retard asynchrone et réduit également la quantité de perte de données possible.
Bien sûr, même après le passage au traitement actuel à deux threads, il existe toujours la possibilité d'un retard des données esclaves et d'une perte de données. Après tout, cette réplication est asynchrone. Ces problèmes existeront tant que les modifications de données ne se feront pas en une seule transaction. Si vous souhaitez éviter complètement ces problèmes, vous ne pouvez utiliser le cluster MySQL que pour les résoudre. Cependant, le cluster de MySQL est une solution pour les bases de données en mémoire. Toutes les données doivent être chargées en mémoire, ce qui nécessite une très grande mémoire et n'est pas très pratique pour les applications générales.
Une autre chose à mentionner est les filtres de réplication de MySQL. Les filtres de réplication vous permettent de copier uniquement une partie des données sur le serveur. Il existe deux types de filtrage de réplication : filtrage des événements dans le journal binaire sur le maître ; filtrage des événements dans le journal de relais sur l'esclave. Comme suit :
Configurer le fichier my.cnf du maître (configuration des clés)/etc/my.cnf
log-bin=mysql-bin server-id = 1 binlog-do-db=icinga binlog-do-db=DB2 //如果备份多个数据库,重复设置这个选项即可 binlog-do-db=DB3 //需要同步的数据库,如果没有本行,即表示同步所有的数据库 binlog-ignore-db=mysql //被忽略的数据库 配置Slave的my.cnf文件(关键性的配置)/etc/my.cnf log-bin=mysql-bin server-id=2 master-host=10.1.68.110 master-user=backup master-password=1234qwer master-port=3306 replicate-do-db=icinga replicate-do-db=DB2 replicate-do-db=DB3 //需要同步的数据库,如果没有本行,即表示同步所有的数据库 replicate-ignore-db=mysql //被忽略的数据库
Les internautes ont dit répliquer-faire Il peut Il y aura quelques problèmes lors de l'utilisation de -db (http://blog.knowsky.com/19696...), mais je ne l'ai pas testé moi-même. Je suppose que le paramètre binlog-do-db est utilisé sur le serveur principal pour filtrer les bases de données dont la copie n'est pas autorisée dans le fichier de configuration en filtrant le journal binaire, c'est-à-dire en n'écrivant pas de journaux d'opérations qui n'autorisent pas la copie des données. être copié dans le journal binaire ; et replicate-do -db est utilisé depuis le serveur pour filtrer les bases de données ou les tables dont la copie n'est pas autorisée en filtrant le journal de relais, c'est-à-dire lors de l'exécution des actions dans le journal de relais, celles aucune action de modification non autorisée ne sera effectuée. Dans ce cas, dans le cas de plusieurs serveurs de base de données esclaves : certains serveurs esclaves copient non seulement les données du serveur maître, mais agissent également comme serveur maître pour copier les données vers d'autres serveurs esclaves, alors binlog-do- devrait pouvoir exister dans son fichier de configuration en même temps. Les deux paramètres db et replicate-do-db sont corrects. Tout est ma propre prédiction. L'utilisation spécifique de binlog-do-db et replicate-do-db doit encore être explorée un peu dans le développement réel.
On dit sur Internet qu'il est préférable de ne pas ignorer certaines bases de données ou tables lors de la réplication sur le serveur maître, car une fois que le serveur maître l'ignore, il n'écrira plus dans le binaire fichier, mais sur le serveur esclave Bien que certaines bases de données soient ignorées, les informations d'opération sur le serveur maître seront toujours copiées dans le journal de relais sur le serveur esclave, mais elles ne seront pas exécutées sur le serveur esclave. Je pense que cela signifie qu'il est recommandé de configurer répliquée-do-db sur le serveur esclave au lieu de binlog-do-db sur le serveur maître.
De plus, qu'il s'agisse d'une liste noire (binlog-ignore-db, répliquer-ignore-db) ou d'une liste blanche (binlog-do-db, répliquer-do-db), il vous suffit d'en écrire une . Si vous les utilisez en même temps Alors seule la liste blanche prend effet.
4. Le processus de réplication maître-esclave MySQL
Il existe deux situations de réplication maître-esclave MySQL : la réplication synchrone et la réplication asynchrone La plupart de l'architecture de réplication actuelle est asynchrone. réplication.
Le processus de base de réplication est le suivant :
Le processus IO sur l'esclave se connecte au maître et demande le fichier journal spécifié à l'emplacement spécifié. (ou depuis le début) journal).
Une fois que le maître a reçu la demande du processus IO de l'esclave, le processus IO responsable de la réplication lira les informations du journal après la position spécifiée dans le journal en fonction des informations de la demande et les renverra. au processus IO de l'esclave. En plus des informations contenues dans le journal, les informations renvoyées incluent également le nom du fichier bin-log et l'emplacement du bin-log dans lequel les informations renvoyées ont été envoyées au maître.
Une fois que le processus IO de l'esclave a reçu les informations, il ajoutera à son tour le contenu du journal reçu à la fin du fichier journal de relais du côté de l'esclave et lira le bin- log côté maître. Le nom du fichier et l'emplacement du journal sont enregistrés dans le fichier master-info, de sorte que la prochaine fois qu'il sera lu, le maître pourra être clairement informé "à partir de quel emplacement dans un certain bin-log dois-je devez démarrer le prochain contenu du journal, veuillez me l'envoyer."
Une fois que le processus SQL de l'esclave a détecté le contenu nouvellement ajouté dans le journal de relais, il analysera immédiatement le contenu du journal de relais et deviendra le contenu exécutable lorsqu'il sera réellement exécuté sur du côté Maître et s’exécute sur lui-même.
五、Mysql主从复制的具体配置
复制通常用来创建主节点的副本,通过添加冗余节点来保证高可用性,当然复制也可以用于其他用途,例如在从节点上进行数据读、分析等等。在横向扩展的业务中,复制很容易实施,主要表现在在利用主节点进行写操作,多个从节点进行读操作,MySQL复制的异步性是指:事物首先在主节点上提交,然后复制给从节点并在从节点上应用,这样意味着在同一个时间点主从上的数据可能不一致。异步复制的好处在于它比同步复制要快,如果对数据的一致性要求很高,还是采用同步复制较好。
最简单的复制模式就是一主一从的复制模式了,这样一个简单的架构只需要三个步骤即可完成:
(1)建立一个主节点,开启binlog,设置服务器id;
(2)建立一个从节点,设置服务器id;
(3)将从节点连接到主节点上。
下面我们开始操作,以MySQL 5.5为例,操作系统Ubuntu12.10,Master 10.1.6.159 Slave 10.1.6.191。
apt-get install mysql-server
Master机器
Master上面开启binlog日志,并且设置一个唯一的服务器id,在局域网内这个id必须唯一。二进制的binlog日志记录master上的所有数据库改变,这个日志会被复制到从节点上,并且在从节点上回放。修改my.cnf文件,在mysqld模块下修改如下内容:
[mysqld] server-id = 1 log_bin = /var/log/mysql/mysql-bin.log
log_bin设置二进制日志所产生文件的基本名称,二进制日志由一系列文件组成,log_bin的值是可选项,如果没有为log_bin设置值,则默认值是:主机名-bin。如果随便修改主机名,则binlog日志的名称也会被改变的。server-id是用来唯一标识一个服务器的,每个服务器的server-id都不一样。这样slave连接到master后,会请求master将所有的binlog传递给它,然后将这些binlog在slave上回放。为了防止权限混乱,一般都是建立一个单独用于复制的账户。
binlog是复制过程的关键,它记录了数据库的所有改变,通常即将执行完毕的语句会在binlog日志的末尾写入一条记录,binlog只记录改变数据库的语句,对于不改变数据库的语句则不进行记录。这种情况叫做基于语句的复制,前面提到过还有一种情况是基于行的复制,两种模式各有各的优缺点。
Slave机器
slave机器和master一样,需要一个唯一的server-id。
[mysqld] server-id = 2
连接Slave到Master
在Master和Slave都配置好后,只需要把slave只想master即可
change master to master_host='10.1.6.159',master_port=3306,master_user='rep', master_password='123456'; start slave;
接下来在master上做一些针对改变数据库的操作,来观察slave的变化情况。在修改完my.cnf配置重启数据库后,就开始记录binlog了。可以在/var/log/mysql目录下看到一个mysql-bin.000001文件,而且还有一个mysql-bin.index文件,这个mysql-bin.index文件是什么?这个文件保存了所有的binlog文件列表,但是我们在配置文件中并没有设置改值,这个可以通过log_bin_index进行设置,如果没有设置改值,则默认值和log_bin一样。在master上执行show binlog events命令,可以看到第一个binlog文件的内容。
注意:上面的sql语句是从头开始复制第一个binlog,如果想从某个位置开始复制binlog,就需要在change master to时指定要开始的binlog文件名和语句在文件中的起点位置,参数如下:master_log_file和master_log_pos。
mysql> show binlog events\G *************************** 1. row *************************** Log_name: mysql-bin.000001 Pos: 4 Event_type: Format_desc Server_id: 1 End_log_pos: 107 Info: Server ver: 5.5.28-0ubuntu0.12.10.2-log, Binlog ver: 4 *************************** 2. row *************************** Log_name: mysql-bin.000001 Pos: 107 Event_type: Query Server_id: 1 End_log_pos: 181 Info: create user rep *************************** 3. row *************************** Log_name: mysql-bin.000001 Pos: 181 Event_type: Query Server_id: 1 End_log_pos: 316 Info: grant replication slave on *.* to rep identified by '123456' 3 rows in set (0.00 sec)
Log_name 是二进制日志文件的名称,一个事件不能横跨两个文件
Pos 这是该事件在文件中的开始位置
Event_type 事件的类型,事件类型是给slave传递信息的基本方法,每个新的binlog都已Format_desc类型开始,以Rotate类型结束
Server_id 创建该事件的服务器id
End_log_pos 该事件的结束位置,也是下一个事件的开始位置,因此事件范围为Pos~End_log_pos-1
Info 事件信息的可读文本,不同的事件有不同的信息
示例
在master的test库中创建一个rep表,并插入一条记录。
create table rep(name var);
insert into rep values ("guol");
flush logs;flush logs命令强制轮转日志,生成一个新的二进制日志,可以通过show binlog events in 'xxx'来查看该二进制日志。可以通过show master status查看当前正在写入的binlog文件。这样就会在slave上执行相应的改变操作。
上面就是最简单的主从复制模式,不过有时候随着时间的推进,binlog会变得非常庞大,如果新增加一台slave,从头开始复制master的binlog文件是非常耗时的,所以我们可以从一个指定的位置开始复制binlog日志,可以通过其他方法把以前的binlog文件进行快速复制,例如copy物理文件。在change master to中有两个参数可以实现该功能,master_log_file和master_log_pos,通过这两个参数指定binlog文件及其位置。我们可以从master上复制也可以从slave上复制,假如我们是从master上复制,具体操作过程如下:
(1)为了防止在操作过程中数据更新,导致数据不一致,所以需要先刷新数据并锁定数据库:flush tables with read lock。
(2)检查当前的binlog文件及其位置:show master status。
mysql> show master status\G *************************** 1. row *************************** File: mysql-bin.000003 Position: 107 Binlog_Do_DB: Binlog_Ignore_DB: 1 row in set (0.00 sec)
(3)通过mysqldump命令创建数据库的逻辑备分:mysqldump --all-databases -hlocalhost -p >back.sql。
(4)有了master的逻辑备份后,对数据库进行解锁:unlock tables。
(5)把back.sql复制到新的slave上,执行:mysql -hlocalhost -p 把master的逻辑备份插入slave的数据库中。
(6)现在可以把新的slave连接到master上了,只需要在change master to中多设置两个参数master_log_file='mysql-bin.000003'和master_log_pos='107'即可,然后启动slave:start slave,这样slave就可以接着107的位置进行复制了。
change master to master_host='10.1.6.159',master_port=3306,master_user='rep', master_password='123456',master_log_file='mysql-bin.000003',master_log_pos='107'; start slave;
有时候master并不能让你锁住表进行复制,因为可能跑一些不间断的服务,如果这时master已经有了一个slave,我们则可以通过这个slave进行再次扩展一个新的slave。原理同在master上进行复制差不多,关键在于找到binlog的位置,你在复制的同时可能该slave也在和master进行同步,操作如下:
(1)为了防止数据变动,还是需要停止slave的同步:stop slave。
(2)然后刷新表,并用mysqldump逻辑备份数据库。
(3)使用show slave status查看slave的相关信息,记录下两个字段的值Relay_Master_Log_File和Exec_Master_Log_Pos,这个用来确定从后面哪里开始复制。
(4)对slave解锁,把备份的逻辑数据库导入新的slave的数据库中,然后设置change master to,这一步和复制master一样。
六、深入了解Mysql主从配置
1、一主多从
由一个master和一个slave组成复制系统是最简单的情况。Slave之间并不相互通信,只能与master进行通信。在实际应用场景中,MySQL复制90%以上都是一个Master复制到一个或者多个Slave的架构模式,主要用于读压力比较大的应用的数据库端廉价扩展解决方案。
在上图中,是我们开始时提到的一主多从的情况,这时主库既要负责写又要负责为几个从库提供二进制日志。这种情况将二进制日志只给某一从,这一从再开启二进制日志并将自己的二进制日志再发给其它从,或者是干脆这个从不记录只负责将二进制日志转发给其它从,这样架构起来性能可能要好得多,而且数据之间的延时应该也稍微要好一些。PS:这些前面都写过了,又复制了一遍。
2、主主复制
上图中,Master-Master复制的两台服务器,既是master,又是另一台服务器的slave。这样,任何一方所做的变更,都会通过复制应用到另外一方的数据库中。在这种复制架构中,各自上运行的不是同一db,比如左边的是db1,右边的是db2,db1的从在右边反之db2的从在左边,两者互为主从,再辅助一些监控的服务还可以实现一定程度上的高可以用。
3、主动—被动模式的Master-Master(Master-Master in Active-Passive Mode)
上图中,这是由master-master结构变化而来的,它避免了M-M的缺点,实际上,这是一种具有容错和高可用性的系统。它的不同点在于其中只有一个节点在提供读写服务,另外一个节点时刻准备着,当主节点一旦故障马上接替服务。比如通过corosync+pacemaker+drbd+MySQL就可以提供这样一组高可用服务,主备模式下再跟着slave服务器,也可以实现读写分离。
4、带从服务器的Master-Master结构(Master-Master with Slaves)

L'avantage de cette structure est qu'elle assure la redondance. Avec une structure de réplication géographiquement distribuée, il n'y a pas de problème de défaillance d'un seul nœud et des requêtes de lecture intensives peuvent également être adressées à l'esclave.
5. MySQL-5.5 prend en charge la réplication semi-synchrone
La réplication MySQL antérieure ne pouvait être implémentée que sur la base d'une implémentation asynchrone. À partir de MySQL-5.5, la réplication semi-automatique est prise en charge. Dans la réplication asynchrone précédente, la base de données principale ne contrôlait pas la progression de la base de données de secours après l'exécution de certaines transactions. Si la base de données de secours est à la traîne et que, malheureusement, la base de données principale tombe en panne (par exemple en cas de temps d'arrêt) à ce moment-là, les données de la base de données de secours seront incomplètes. En bref, lorsque la base de données principale tombe en panne, nous ne pouvons pas utiliser la base de données de secours pour continuer à fournir des services cohérents avec les données. La réplication semi-synchrone (réplication semi-synchrone) garantit dans une certaine mesure que la transaction soumise a été transmise à au moins une base de données de secours. En semi-synchrone, il est uniquement garanti que la transaction a été transmise à la base de données de secours, mais cela ne garantit pas qu'elle a été terminée sur la base de données de secours.
De plus, il existe une autre situation qui peut entraîner une incohérence entre les données primaires et secondaires. Dans une session, une fois qu'une transaction est soumise sur la base de données principale, elle attendra que la transaction soit transférée vers au moins une base de données de secours. Si la base de données principale tombe en panne pendant ce processus d'attente, la base de données de secours et la base de données principale peuvent être incohérentes. , ce qui est très mortel. Si les réseaux actif et de secours échouent ou si la base de données de secours est en panne, la base de données principale attendra 10 secondes (la valeur par défaut de rpl_semi_sync_master_timeout) après la soumission de la transaction avant de continuer. À ce moment-là, la bibliothèque principale reviendra à son état asynchrone d'origine.
Une fois MySQL chargé et activé le plug-in Semi-sync, chaque transaction doit attendre que la base de données de secours reçoive le journal avant de le renvoyer au client. Si vous effectuez une petite transaction et que le délai entre les deux hôtes est faible, la semi-synchronisation peut atteindre zéro perte de données avec peu de perte de performances.
Ce qui précède représente l’intégralité du contenu de cet article, j’espère qu’il sera utile à l’étude de chacun. Pour un contenu plus passionnant, vous pouvez prêter attention aux colonnes de didacticiels pertinentes du site Web PHP chinois ! ! !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: la facilité de gestion des données pour les débutants
Apr 09, 2025 am 12:07 AM
MySQL: la facilité de gestion des données pour les débutants
Apr 09, 2025 am 12:07 AM
MySQL convient aux débutants car il est simple à installer, puissant et facile à gérer les données. 1. Installation et configuration simples, adaptées à une variété de systèmes d'exploitation. 2. Prise en charge des opérations de base telles que la création de bases de données et de tables, d'insertion, d'interrogation, de mise à jour et de suppression de données. 3. Fournir des fonctions avancées telles que les opérations de jointure et les sous-questionnaires. 4. Les performances peuvent être améliorées par l'indexation, l'optimisation des requêtes et le partitionnement de la table. 5. Prise en charge des mesures de sauvegarde, de récupération et de sécurité pour garantir la sécurité et la cohérence des données.
 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Créez une base de données à l'aide de NAVICAT Premium: Connectez-vous au serveur de base de données et entrez les paramètres de connexion. Cliquez avec le bouton droit sur le serveur et sélectionnez Créer une base de données. Entrez le nom de la nouvelle base de données et le jeu de caractères spécifié et la collation. Connectez-vous à la nouvelle base de données et créez le tableau dans le navigateur d'objet. Cliquez avec le bouton droit sur le tableau et sélectionnez Insérer des données pour insérer les données.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Vous pouvez créer une nouvelle connexion MySQL dans NAVICAT en suivant les étapes: ouvrez l'application et sélectionnez une nouvelle connexion (CTRL N). Sélectionnez "MySQL" comme type de connexion. Entrez l'adresse Hostname / IP, le port, le nom d'utilisateur et le mot de passe. (Facultatif) Configurer les options avancées. Enregistrez la connexion et entrez le nom de la connexion.
 Comment récupérer les données après que SQL supprime les lignes
Apr 09, 2025 pm 12:21 PM
Comment récupérer les données après que SQL supprime les lignes
Apr 09, 2025 pm 12:21 PM
La récupération des lignes supprimées directement de la base de données est généralement impossible à moins qu'il n'y ait un mécanisme de sauvegarde ou de retour en arrière. Point clé: Rollback de la transaction: Exécutez Rollback avant que la transaction ne s'engage à récupérer les données. Sauvegarde: la sauvegarde régulière de la base de données peut être utilisée pour restaurer rapidement les données. Instantané de la base de données: vous pouvez créer une copie en lecture seule de la base de données et restaurer les données après la suppression des données accidentellement. Utilisez la déclaration de suppression avec prudence: vérifiez soigneusement les conditions pour éviter la suppression accidentelle de données. Utilisez la clause WHERE: Spécifiez explicitement les données à supprimer. Utilisez l'environnement de test: testez avant d'effectuer une opération de suppression.
 Comment exécuter SQL dans Navicat
Apr 08, 2025 pm 11:42 PM
Comment exécuter SQL dans Navicat
Apr 08, 2025 pm 11:42 PM
Étapes pour effectuer SQL dans NAVICAT: Connectez-vous à la base de données. Créez une fenêtre d'éditeur SQL. Écrivez des requêtes ou des scripts SQL. Cliquez sur le bouton Exécuter pour exécuter une requête ou un script. Affichez les résultats (si la requête est exécutée).
