

Introduction à 4 méthodes de conversion HTML en PDF (avec code)

Cet article vous présente 4 méthodes de conversion de HTML en PDF (avec du code). Il a une certaine valeur de référence. Les amis dans le besoin peuvent s'y référer.
Dans cet article, je vais vous montrer comment générer des documents PDF à partir de pages React au style complexe à l'aide de Node.js, Puppeteer, Chrome sans tête et Docker.
Contexte : Il y a quelques mois, un client nous a demandé de développer une fonctionnalité permettant aux utilisateurs d'obtenir le contenu des pages React au format PDF. Cette page est essentiellement un rapport et une visualisation des données d'un cas de patient, avec de nombreux SVG inclus. Il existe également des requêtes spéciales pour manipuler la mise en page et effectuer certains réarrangements des éléments HTML. Il devrait donc y avoir un style différent et du contenu supplémentaire dans le PDF par rapport à la page React d'origine.
Étant donné que cette tâche est beaucoup plus complexe que de la résoudre avec de simples règles CSS, nous explorons d'abord les moyens possibles pour y parvenir. Nous avons trouvé 3 solutions principales. Cet article de blog vous guidera à travers leurs possibilités et leur éventuelle mise en œuvre.
Est-il généré côté client ou côté serveur ?
Les fichiers PDF peuvent être générés à la fois côté client et côté serveur. Mais il est probablement plus logique de laisser le backend s'en charger, puisque vous ne voulez pas utiliser toutes les ressources que le navigateur de l'utilisateur peut fournir.
Même ainsi, je montrerai toujours la solution pour les deux méthodes.
Option 1 : Faire des captures d'écran depuis le DOM
À première vue, cette solution semble être la plus simple, et il s'avère que c'est le cas, mais elle a ses propres limites. Il s'agit d'une méthode facile à utiliser si vous n'avez pas de besoins particuliers, comme sélectionner du texte dans un PDF ou effectuer une recherche sur du texte.
La méthode est simple et directe : créez une capture d'écran de la page et placez-la dans un fichier PDF. Très simple. Nous pouvons utiliser deux packages pour y parvenir :
- Html2canvas, qui génère des captures d'écran basées sur DOM
- jsPdf, une bibliothèque qui génère des PDF
Commencer à coder :
npm install html2canvas jspdf
import html2canvas from 'html2canvas'
import jsPdf from 'jspdf'
function printPDF () {
const domElement = document.getElementById('your-id')
html2canvas(domElement, { onclone: (document) => {
document.getElementById('print-button').style.visibility = 'hidden'
}})
.then((canvas) => {
const img = canvas.toDataURL('image/png')
const pdf = new jsPdf()
pdf.addImage(imgData, 'JPEG', 0, 0, width, height)
pdf.save('your-filename.pdf')
})Ça y est !
Veuillez noter la méthode onclone de html2canvas. C'est très pratique lorsque vous devez manipuler le DOM avant de prendre une capture d'écran (par exemple en masquant le bouton d'impression). J'ai vu de nombreux projets utilisant ce package. Mais malheureusement, ce n’est pas ce que nous voulons car nous devons créer le PDF sur le backend.
Option 2 : Utilisez simplement la bibliothèque PDF
Il existe plusieurs bibliothèques sur NPM, telles que jsPDF (comme mentionné ci-dessus) ou PDFKit. Le problème avec eux est que si je veux utiliser ces bibliothèques, je devrai restructurer la page. Cela nuit définitivement à la maintenabilité car je devrais appliquer toutes les modifications ultérieures au modèle PDF et à la page React.
Veuillez consulter le code ci-dessous. Vous devez créer manuellement le document PDF vous-même. Vous devez parcourir le DOM, trouver chaque élément et le convertir au format PDF, ce qui est un travail fastidieux. Il faut trouver un moyen plus simple.
doc = new PDFDocument
doc.pipe fs.createWriteStream('output.pdf')
doc.font('fonts/PalatinoBold.ttf')
.fontSize(25)
.text('Some text with an embedded font!', 100, 100)
doc.image('path/to/image.png', {
fit: [250, 300],
align: 'center',
valign: 'center'
});
doc.addPage()
.fontSize(25)
.text('Here is some vector graphics...', 100, 100)
doc.end()Cet extrait de code provient de la documentation PDFKit. Mais cela peut toujours être utile si votre objectif est de générer un fichier PDF directement, plutôt que de convertir une page HTML existante (et en constante évolution).
Solution finale 3 : Puppeteer et Headless Chrome basés sur Node.js
Qu'est-ce que Puppeteer ? Sa documentation se lit comme suit :
Puppeteer est une bibliothèque Node qui fournit une API de haut niveau pour contrôler Chrome ou Chromium sur le protocole DevTools. Puppeteer exécute Chrome ou Chromium en mode sans tête par défaut, mais il peut également être configuré pour fonctionner en mode complet (sans tête).
Il s'agit essentiellement d'un navigateur qui peut être exécuté à partir de Node.js. Si vous lisez sa documentation, la première chose mentionnée est que vous pouvez utiliser Puppeteer pour générer des captures d'écran et des PDF de pages. excellent! C'est exactement ce que nous voulons.
Utilisez d'abord npmi i puppeteer pour installer Puppeteer et implémenter nos fonctions.
const puppeteer = require('puppeteer')
async function printPDF() {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
await page.goto('https://blog.risingstack.com', {waitUntil: 'networkidle0'});
const pdf = await page.pdf({ format: 'A4' });
await browser.close();
return pdf
})Il s'agit d'une fonction simple qui accède à une URL et génère un fichier PDF du site.
Tout d'abord, nous lançons le navigateur (la génération de PDF n'est prise en charge qu'en mode sans tête), puis ouvrons une nouvelle page, définissons la fenêtre d'affichage et naviguons jusqu'à l'URL fournie.
La définition de l'option waitUntil:'networkidle0' signifie que Puppeteer considérera la navigation comme terminée lorsqu'il n'y a pas de connexion réseau pendant au moins 500 millisecondes. (Plus d'informations peuvent être obtenues à partir de la documentation de l'API.)
Après cela, nous enregistrons le PDF en tant que variable, fermons le navigateur et revenons au PDF.
Remarque : La méthode page.pdf accepte un objet options et vous pouvez utiliser l'option 'path' pour enregistrer le fichier sur le disque. Si aucun chemin n'est fourni, le PDF ne sera pas enregistré sur le disque mais sera mis en mémoire tampon. (Je discuterai de la façon de gérer cela plus tard.)
Si vous devez vous connecter avant de pouvoir générer un PDF à partir d'une page protégée, vous devrez d'abord accéder à la page de connexion, vérifier le formulaire l'ID ou le nom de l'élément, remplissez-les, puis Soumettez le formulaire :
await page.type('#email', process.env.PDF_USER)
await page.type('#password', process.env.PDF_PASSWORD)
await page.click('#submit')Toujours enregistrer les informations de connexion dans les variables d'environnement, ne les codez jamais en dur !
样式控制
Puppeteer 也有这种样式操作的解决方案。你可以在生成 PDF 之前插入样式标记,Puppeteer 将生成具有已修改样式的文件。
await page.addStyleTag({ content: '.nav { display: none} .navbar { border: 0px} #print-button {display: none}' })将文件发送到客户端并保存
好的,现在你已经在后端生成了一个 PDF 文件。接下来做什么?
如上所述,如果你不把文件保存到磁盘,将会得到一个缓冲区。你只需要把含有适当内容类型的缓冲区发送到前端即可。
printPDF.then(pdf => {
res.set({ 'Content-Type': 'application/pdf', 'Content-Length': pdf.length })
res.send(pdf)现在,你只需在浏览器向服务器发送请求即可得到生成的 PDF。
function getPDF() {
return axios.get(`${API_URL}/your-pdf-endpoint`, {
responseType: 'arraybuffer',
headers: {
'Accept': 'application/pdf'
}
})一旦发送了请求,缓冲区的内容就应该开始下载了。最后一步是将缓冲区数据转换为 PDF 文件。
savePDF = () => {
this.openModal(‘Loading…’) // open modal
return getPDF() // API call
.then((response) => {
const blob = new Blob([response.data], {type: 'application/pdf'})
const link = document.createElement('a')
link.href = window.URL.createObjectURL(blob)
link.download = `your-file-name.pdf`
link.click()
this.closeModal() // close modal
})
.catch(err => /** error handling **/)
}
<button onClick={this.savePDF}>Save as PDF</button>就这样!如果单击“保存”按钮,那么浏览器将会保存 PDF。
在 Docker 中使用 Puppeteer
我认为这是实施中最棘手的部分 —— 所以让我帮你节省几个小时的百度时间。
官方文档指出“在 Docker 中使用 headless Chrome 并使其运行起来可能会非常棘手”。官方文档有疑难解答部分,你可以找到有关用 Docker 安装 puppeteer 的所有必要信息。
如果你在 Alpine 镜像上安装 Puppeteer,请确保在看到页面的这一部分时再向下滚动一点。否则你可能会忽略一个事实:你无法运行最新的 Puppeteer 版本,并且你还需要用一个标记禁用 shm :
const browser = await puppeteer.launch({
headless: true,
args: ['--disable-dev-shm-usage']
});否则,Puppeteer 子进程可能会在正常启动之前耗尽内存。
方案 3 + 1:CSS 打印规则
可能有人认为从开发人员的角度来看,简单地使用 CSS 打印规则很容易。没有 NPM 模块,只有纯 CSS。但是在跨浏览器兼容性方面,它的表现如何呢?
在选择 CSS 打印规则时,你必须在每个浏览器中测试结果,以确保它提供的布局是相同的,并且它不是100%能做到这一点。
例如,在给定元素后面插入一个 break-after 并不是一个多么高深的技术,但是你可能会惊讶的发现要在 Firefox 中使用它需要使用变通方法。
除非你是一位经验丰富的 CSS 大师,在创建可打印页面方面有很多的经验,否则这可能会非常耗时。
如果你可以使打印样式表保持简单,打印规则是很好用的。
让我们来看一个例子吧。
@media print {
.print-button {
display: none;
}
.content p {
break-after: always;
}
}上面的 CSS 隐藏了打印按钮,并在每个 p 之后插入一个分页符,其中包含content 类。有一篇很棒的文章总结了你可以用打印规则做什么,以及它们有什么问题,包括浏览器兼容性。
考虑到所有因素,如果你想从不那么复杂的页面生成 PDF,CSS打印规则非常有效。
总结
让我们快速回顾前面介绍的方案,以便从 HTML 页面生成 PDF 文件:
从 DOM 产生截图:当你需要从页面创建快照时(例如创建缩略图)可能很有用,但是当你需要处理大量数据时就会有些捉襟见肘。
只用 PDF 库:如果你打算从头开始以编程方式创建 PDF 文件,这是一个完美的解决方案。否则,你需要同时维护 HTML 和 PDF 模板,这绝对是一个禁忌。
Puppeteer:尽管在 Docker 上工作相对困难,但它为我们的实现提供了最好的结果,而且编写代码也是最简单的。
CSS打印规则:如果你的用户受过足够的教育,知道如何把页面内容打印到文件,并且你的页面相对简单,那么它可能是最轻松的解决方案。正如你在我们的案例中所看到的,事实并非如此。
本篇文章到这里就已经全部结束了,更多其他精彩内容可以关注PHP中文网的HTML视频教程栏目!
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment fusionner des PDF sur iPhone
Feb 02, 2024 pm 04:05 PM
Comment fusionner des PDF sur iPhone
Feb 02, 2024 pm 04:05 PM
Lorsque vous travaillez avec plusieurs documents ou plusieurs pages du même document, vous souhaiterez peut-être les combiner en un seul fichier à partager avec d'autres. Pour un partage facile, Apple vous permet de fusionner plusieurs fichiers PDF en un seul fichier pour éviter d'envoyer plusieurs fichiers. Dans cet article, nous vous aiderons à connaître toutes les façons de fusionner deux ou plusieurs PDF en un seul fichier PDF sur iPhone. Comment fusionner des fichiers PDF sur iPhone Sur iOS, vous pouvez fusionner des fichiers PDF en un seul de deux manières : en utilisant l'application Fichiers et l'application Raccourcis. Méthode 1 : utiliser l'application Fichiers Le moyen le plus simple de fusionner deux ou plusieurs PDF en un seul fichier consiste à utiliser l'application Fichiers. Ouvrir sur iPhone
 3 façons d'obtenir du texte à partir d'un PDF sur iPhone
Mar 16, 2024 pm 09:20 PM
3 façons d'obtenir du texte à partir d'un PDF sur iPhone
Mar 16, 2024 pm 09:20 PM
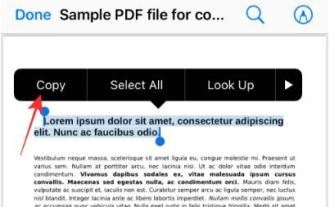
La fonction Live Text d'Apple reconnaît le texte, les notes manuscrites et les chiffres dans les photos ou via l'application Appareil photo et vous permet de coller ces informations sur n'importe quelle autre application. Mais que faire lorsque vous travaillez avec un PDF et que vous souhaitez en extraire du texte ? Dans cet article, nous expliquerons toutes les façons d'extraire du texte à partir de fichiers PDF sur iPhone. Comment obtenir du texte à partir d'un fichier PDF sur iPhone [3 méthodes] Méthode 1 : faire glisser du texte sur un PDF Le moyen le plus simple d'extraire du texte d'un PDF est de le copier, comme sur n'importe quelle autre application contenant du texte. 1. Ouvrez le fichier PDF dont vous souhaitez extraire le texte, puis appuyez longuement n'importe où sur le PDF et commencez à faire glisser la partie du texte que vous souhaitez copier. 2
 Comment vérifier la signature dans un PDF
Feb 18, 2024 pm 05:33 PM
Comment vérifier la signature dans un PDF
Feb 18, 2024 pm 05:33 PM
Nous recevons généralement des fichiers PDF du gouvernement ou d'autres agences, certains avec des signatures numériques. Après avoir vérifié la signature, nous voyons le message SignatureValid et une coche verte. Si la signature n'est pas vérifiée, la validité est inconnue. La vérification des signatures est importante, voyons comment le faire en PDF. Comment vérifier les signatures au format PDF La vérification des signatures au format PDF le rend plus fiable et le document est plus susceptible d'être accepté. Vous pouvez vérifier les signatures dans les documents PDF des manières suivantes. Ouvrez le PDF dans Adobe Reader Cliquez avec le bouton droit sur la signature et sélectionnez Afficher les propriétés de la signature Cliquez sur le bouton Afficher le certificat du signataire Ajoutez la signature à la liste des certificats de confiance à partir de l'onglet Confiance Cliquez sur Vérifier la signature pour terminer la vérification.
 Comment exporter des fichiers Xmind vers des fichiers PDF
Mar 20, 2024 am 10:30 AM
Comment exporter des fichiers Xmind vers des fichiers PDF
Mar 20, 2024 am 10:30 AM
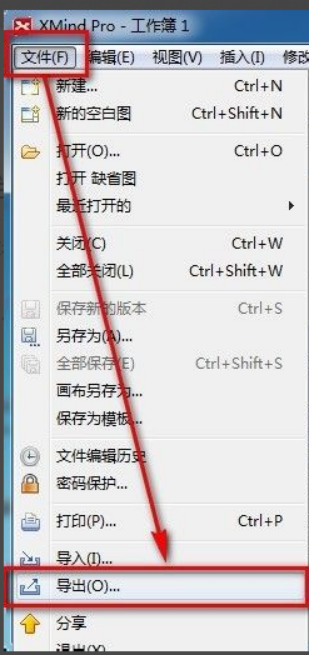
xmind est un logiciel de cartographie mentale très pratique. Il s'agit d'un formulaire cartographique créé à partir de la réflexion et de l'inspiration des gens. Après avoir créé le fichier xmind, nous le convertissons généralement au format de fichier PDF pour faciliter la diffusion et l'utilisation par chacun. vers des fichiers pdf ? Vous trouverez ci-dessous les étapes spécifiques pour votre référence. 1. Tout d’abord, montrons comment exporter la carte mentale vers un document PDF. Sélectionnez le bouton de fonction [Fichier]-[Exporter]. 2. Sélectionnez [Document PDF] dans la nouvelle interface apparue et cliquez sur le bouton [Suivant]. 3. Sélectionnez les paramètres dans l'interface d'exportation : format du papier, orientation, résolution et emplacement de stockage du document. Après avoir terminé les réglages, cliquez sur le bouton [Terminer]. 4. Si vous cliquez sur le bouton [Terminer]
 Résoudre le problème du téléchargement de fichiers PDF en PHP7
Feb 29, 2024 am 11:12 AM
Résoudre le problème du téléchargement de fichiers PDF en PHP7
Feb 29, 2024 am 11:12 AM
Résoudre les problèmes rencontrés lors du téléchargement de fichiers PDF en PHP7 En développement web, nous rencontrons souvent le besoin d'utiliser PHP pour télécharger des fichiers. Le téléchargement de fichiers PDF en particulier peut aider les utilisateurs à obtenir les informations ou les fichiers nécessaires. Cependant, vous rencontrerez parfois des problèmes lors du téléchargement de fichiers PDF en PHP7, tels que des caractères tronqués et des téléchargements incomplets. Cet article détaillera comment résoudre les problèmes que vous pourriez rencontrer lors du téléchargement de fichiers PDF en PHP7 et fournira quelques exemples de code spécifiques. Analyse du problème : en PHP7, en raison de l'encodage des caractères et du H
 Découvrez comment faire pivoter des fichiers PDF à l'aide des touches de raccourci du navigateur Edge
Jan 05, 2024 am 09:17 AM
Découvrez comment faire pivoter des fichiers PDF à l'aide des touches de raccourci du navigateur Edge
Jan 05, 2024 am 09:17 AM
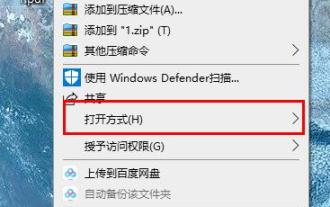
Bien que les fichiers PDF soient très pratiques à utiliser, de nombreux amis aiment toujours utiliser Word pour les modifier et les visualiser, alors comment les convertir ? Jetons un coup d'œil à la méthode de fonctionnement détaillée ci-dessous. Touche de raccourci de rotation PDF du navigateur Edge : A : La touche de raccourci pour la rotation est F9. 1. Cliquez avec le bouton droit sur le fichier PDF et sélectionnez « Ouvrir avec ». 2. Sélectionnez « Microsoft Edge » pour ouvrir le fichier PDF. 3. Après avoir saisi le fichier pdf, une barre des tâches apparaîtra ci-dessous. 4. Cliquez sur le bouton de rotation à côté du signe « + » pour faire pivoter vers la droite.
 Comment définir la méthode d'ouverture par défaut du PDF dans Win11 Tutoriel sur la définition de la méthode d'ouverture par défaut du PDF dans Win11
Feb 29, 2024 pm 09:01 PM
Comment définir la méthode d'ouverture par défaut du PDF dans Win11 Tutoriel sur la définition de la méthode d'ouverture par défaut du PDF dans Win11
Feb 29, 2024 pm 09:01 PM
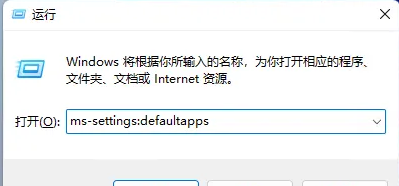
Certains utilisateurs trouvent difficile de choisir une méthode d'ouverture à chaque fois qu'ils ouvrent un fichier PDF. Ils souhaitent définir leur méthode d'ouverture couramment utilisée comme méthode par défaut. Alors, comment définir la méthode d'ouverture PDF par défaut dans Win11 ? L'éditeur ci-dessous vous donnera une introduction détaillée au didacticiel sur la définition de la méthode d'ouverture des PDF par défaut dans win11. Si vous êtes intéressé, venez y jeter un œil. Tutoriel sur la définition de la méthode d'ouverture par défaut du PDF dans win11 1. Touche de raccourci "win+R" pour ouvrir l'exécution, entrez la commande "ms-settings:defaultapps" et appuyez sur Entrée pour ouvrir. 2. Après avoir accédé à la nouvelle interface, saisissez « .pdf » dans le champ de recherche ci-dessus et cliquez sur l'icône de recherche pour effectuer une recherche. 3. Ceci
 PHP et Vue : une combinaison parfaite d'outils de développement front-end
Mar 16, 2024 pm 12:09 PM
PHP et Vue : une combinaison parfaite d'outils de développement front-end
Mar 16, 2024 pm 12:09 PM
PHP et Vue : une combinaison parfaite d'outils de développement front-end À l'ère actuelle de développement rapide d'Internet, le développement front-end est devenu de plus en plus important. Alors que les utilisateurs ont des exigences de plus en plus élevées en matière d’expérience des sites Web et des applications, les développeurs front-end doivent utiliser des outils plus efficaces et plus flexibles pour créer des interfaces réactives et interactives. En tant que deux technologies importantes dans le domaine du développement front-end, PHP et Vue.js peuvent être considérés comme une arme parfaite lorsqu'ils sont associés. Cet article explorera la combinaison de PHP et Vue, ainsi que des exemples de code détaillés pour aider les lecteurs à mieux comprendre et appliquer ces deux éléments.
