

Dans l'article précédent "Utiliser Python pour implémenter des outils de test hautes performances (1) " nous avons optimisé les performances en changeant l'analyseur python, mais c'est encore loin des besoins réels. Cet article présente le code optimisé pour les tests automatisés.
Plan 2 : Optimiser le code
Les travailleurs veulent être bons au début. Pour optimiser le code, vous devez d'abord trouver le goulot d'étranglement du code. Le moyen le plus simple est d'ajouter un journal ou de l'imprimer. Il doit être supprimé une fois le débogage terminé, ce qui est plus gênant. Python fournit également de nombreux outils de profil : profile, cProfile, hotshot, pystats, mais les résultats fournis par ces outils ne sont pas très lisibles pour voir d'un seul coup d'œil quelle fonction ou ligne prend le plus de temps. python line_profiler fournit une telle fonction. Vous pouvez voir intuitivement quelle ligne prend le plus de temps. On peut dire qu'elle est "rapide, précise et impitoyable". Adresse de téléchargement : http://pythonhosted.org/line_profiler/<.> Après avoir installé line_profiler Enfin, il y aura un kernprof.py dans le répertoire C:Python27Libsite-packages Ajoutez @profile sur les fonctions qui peuvent avoir des goulots d'étranglement, comme dans l'exemple suivant :
Exécuter. ce fichier : kernprof.py -l -v D:projectmpsrcprotocolslibdiametermt.py, obtenez les résultats suivants. À partir de cette image, vous pouvez voir intuitivement que la méthode setAVPS prend 96,6 % du temps. Ensuite, localisez cette fonction et ajoutez à nouveau le modificateur @proflie (le profil peut être ajouté à plusieurs fonctions à la fois. Vous pouvez voir plus loin le rapport setAVPS). du temps pris par chaque ligne de code dans la fonction.@profile def create_msg2(self,H,msg): li = msg.keys() msg_type=li[0] ULR_avps=[] ULR=HDRItem() ULR.cmd=self.dia.dictCOMMANDname2code(self.dia.MSG_TERM[msg_type]) if msg_type[-1]=='A': msg=msg[msg_type] self.dia.setAVPs_by_dic(msg_type,msg,ULR_avps) ULR.appId=H.appId ULR.EndToEnd=H.EndToEnd ULR.HopByHop=H.HopByHop msg=self.dia.createRes(ULR,ULR_avps) else: self.dia.setAVPs(msg_type,msg,ULR_avps) ULR.appId=self.dia.APPID self.dia.initializeHops(ULR) msg=self.dia.createReq(ULR,ULR_avps) return msg
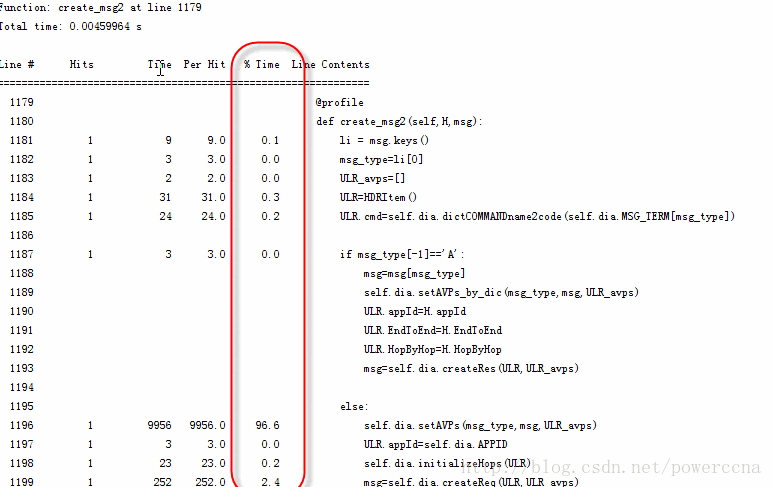
Grâce à une analyse étape par étape, nous pouvons voir que dans la bibliothèque de protocoles open source, dans la méthode setAVPS, l'attribut de recherche d'avp est recherché à partir de une boucle de 3 000, chaque AVP doit être cyclée 3 000 fois, il y a au moins 10 avps dans un message de diamètre, et chaque fois que l'encodage d'une avp doit être cyclé 30 000 fois. Notre solution initiale consistait à supprimer de nombreux avps qui n'étaient pas utilisés dans nos tests de performances (il n'y a aucun moyen, les ressources de développement de tests sont limitées, et souvent il n'y a pas de bonne conception, il faut d'abord créer quelque chose qui répond aux besoins.), mais ce n'est que amélioré A environ 150, on est encore loin de la demande. Nous avons donc changé AVP en mode dictionnaire, afin de pouvoir trouver rapidement les attributs d'AVP en fonction de son nom.
En plus de l'optimisation du code, le nombre de threads avp d'encodage a également été augmenté. Les chapitres suivants parleront de l'impact du multi-threading et du multi-processus sur les performances. à suivre. . . .
[Cours recommandé :
Cours vidéo PythonCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!


















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



