
 Java
javaDidacticiel
Comment utiliser Java pour implémenter une fonction de recherche de graines p2p
Java
javaDidacticiel
Comment utiliser Java pour implémenter une fonction de recherche de graines p2p
Comment utiliser Java pour implémenter une fonction de recherche de graines p2p

Le contenu de cet article explique comment utiliser Java pour implémenter une fonction de recherche de graines p2p. Il a une certaine valeur de référence. Les amis dans le besoin peuvent s'y référer.
J'avais beaucoup d'intérêt pour le p2p il y a de nombreuses années, mais cela restait en théorie et je n'ai jamais eu l'occasion de le mettre en pratique. J'ai récemment mis en œuvre cette chose. Depuis le début jusqu'à maintenant, je pense qu'il y a certaines choses que je peux partager. Allons droit au but
Concepts de base
Avant de parler de p2p, je veux parler de la façon dont nous téléchargeons des fichiers. Permettez-moi d'énumérer plusieurs façons de télécharger des fichiers
1. Utilisez le protocole http pour télécharger La méthode la plus couramment utilisée est probablement de télécharger des fichiers via un navigateur.
2. Utilisez FTP pour télécharger. Il existe deux modes pour FTP. L'un est le mode port (actif). Dans ce mode, le client ouvrira un port N (> 1023) localement pour établir une connexion FTP. puis envoyez Donnez au serveur FTP le port d'écoute N+1 pour la transmission des données. Lorsqu'il y a un pare-feu ou que le client est NAT, il ne peut pas être téléchargé. Une autre façon est le mode passif. Dans ce mode, en plus du port 21, le serveur FTP ouvrira un autre port supérieur à 1023. C'est-à-dire que le client initiera activement les connexions FTP et les connexions de transmission de données, tant que le serveur FTP est ouvert. Il n’y aura aucun problème avec ce port.
Les deux méthodes ci-dessus peuvent être collectivement appelées architecture cs. Dans cette architecture, les ressources sont concentrées sur le serveur lorsque la quantité de données atteint un certain niveau, des problèmes surviennent. Afin de résoudre ce problème, nous pouvons penser à la décentralisation distribuée, c'est pourquoi p2p signifie peer to peer. Il s'agit d'une architecture peer-to-peer. Chaque nœud est à la fois un client et un serveur.
Architecture p2p
Lorsque les ressources sont stockées sur chaque nœud, on peut penser, lorsque je télécharge une ressource, comment savoir sur quelles machines se trouve ce fichier ?
Dans les premières architectures p2p, il existait un rôle de tracker, chargé de stocker les informations de métadonnées des fichiers. Alors maintenant, le fichier sera enregistré sur chaque homologue et les informations sur le fichier seront obtenues via le tracker.
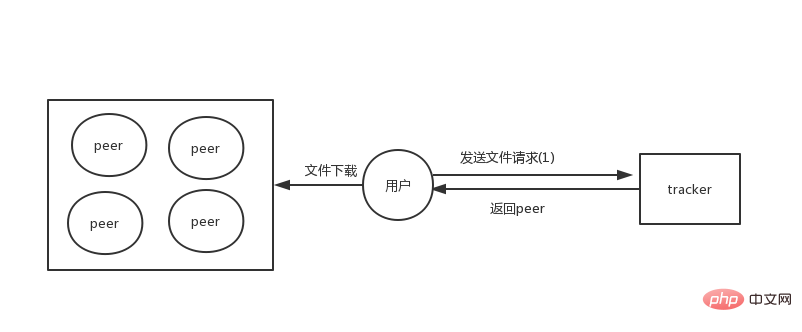
Sous cette architecture, tous nos fichiers sont distribués, mais le tracker sera responsable du stockage des informations de métadonnées de tous les fichiers, le tracker n'a donc besoin d'en stocker qu'une petite quantité de données, par rapport aux fichiers existants, sera relativement facile.
Mais une fois le serveur de tracker bloqué ou le service indisponible, tous les fichiers ne seront pas téléchargés car il n'est pas entièrement distribué. Afin d'être complètement décentralisé, une architecture sans tracker sera développée ultérieurement.
À l'heure actuelle, le tracker n'existe plus et tous les fichiers, y compris les informations de métadonnées des fichiers, sont stockés de manière distribuée. DHTTable de hachage distribuée DHT (Distributed Hash Table), qui est utilisée pour remplacer le tracker. Il existe de nombreux algorithmes pour implémenter dht, tels que l'algorithme Kademlia, etc.
Quelques concepts :
Il y a deux étapes pour mettre en œuvre la recherche de graines. La première étape est un robot d'exploration, qui est utilisé pour explorer les informations de graines sur Internet. La deuxième étape consiste à rejoindre la recherche.
Vous devez avoir les connaissances suivantes : graines, protocole bittorrent dht, bencoded
Quand il s'agit de p2p, nous devons mentionner les graines, qui sont le genre de fichiers qui sont le résultat de .torrent. Tout le monde a peut-être utilisé des torrents pour télécharger des fichiers, et les fichiers téléchargés utilisent le protocole bittorrent. Alors comment récolter des graines sur Internet ?
Les principaux champs inclus dans les graines bt : https://segmentfault.com/a/1190000000681331
Les graines obtenues en dht sont appelées torrent sans tracker. Il n'y a pas d'attribut d'annonce, mais il y en a. attribut nodes à la place. La recommandation officielle est de ne pas ajouter router.bittorrent.com à la graine ou de l'ajouter à la table de routage.
1.
Comment obtenir des graines de DHTSi vous souhaitez obtenir des informations sur les graines, vous devez avoir une compréhension approfondie du protocole DHT décrit par bep_0005. le protocole DHT
Pour plus de détails, vous pouvez cliquer ici http://www.bittorrent.org/beps/bep_0005.htmlComment implémenter une table de routage :
La table de routage couvre tous les ID de nœud, de 0 à 2 élevés à la puissance 160. La table de routage peut être composée de compartiments et chaque compartiment couvre une partie de tous les nœuds.
Au début, il n'y a qu'un seul bucket dans la table de routage, couvrant tous les nodeids. Chaque compartiment ne peut contenir que K nœuds. La valeur K actuelle est de 8. Si le bucket est plein et que tous les nœuds qu'il contient sont bons et que le propre nodeid n'est pas dans ce bucket, alors le bucket d'origine est divisé en deux nouveaux buckets, couvrant 0..2
159 et 2 159..2160. Lorsqu'un compartiment est plein, les nouveaux nœuds sont facilement supprimés. Si un nœud qu'il contient se déconnecte, il sera remplacé. Si un nœud n'a pas reçu de requête ping au cours des 15 dernières minutes, envoyez une requête ping au nœud. Si aucune réponse n'est renvoyée, le nœud sera également remplacé. Chaque bucket doit avoir un attribut de dernière modification pour indiquer l'activité de ce bucket. Ce champ sera mis à jour dans ces situations : 1. Le nœud dans le bucket est pingé et a une réponse 2. Un nœud est ajouté à ce bucket 3. . Le nœud dans le bucket a été remplacé Si le bucket ne met pas à jour ce champ dans les 15 minutes, un identifiant dans la plage du bucket sera sélectionné au hasard pour effectuer l'opération find_node. Le protocole KRPC est utilisé pour transmettre des messages dans le réseau DHT. 1.ping la requête ping est principalement utilisée pour la vérification du rythme cardiaque 2.find_node rechercher Pour un nœud, l'autre partie interrogera les N nœuds les plus proches et les renverra à partir de sa propre table de routage, généralement 8 3.get_peers trouver le propriétaire de l'infohash basé sur le pair infohash, si les pairs renvoyés sont trouvés et qu'aucun nœud n'est trouvé, return nodes 4nounce_peer indique aux autres pairs que. ils ont aussi infohash. Notez que les quatre ci-dessus actualiseront la table de routage Il n'y a aucun nœud dans la table de routage au début, donc vous devez partir du super nœud (par exemple La table de routage que j'ai moi-même implémentée est légèrement différente de celle décrite ci-dessus. UDP est utilisé pour la transmission de données dans le réseau dht, il me suffit donc d'ouvrir un port upd et d'envoyer en continu des requêtes find_node pour établir une table de routage, puis d'obtenir l'infohash du semer via get_peers etnounce_peer. Lorsque nous rejoignons le réseau dht, nous ne pouvons obtenir l'infohash du fichier de départ que via les quatre méthodes présentées ci-dessus, nous devons donc également télécharger la graine via l'infohash pour plus de détails. , veuillez vous référer à bep_009http:/ /www.bittorrent.org/beps/bep_0009.html Nous utilisons principalement bep_009 pour obtenir le champ de nom du torrent. Après avoir obtenu le champ de nom de fichier, nous pouvons créer un index. basé sur le nom et l'infohash pour effectuer la recherche. (Ici, nous construisons principalement des liens magnétiques. Avec les liens magnétiques, vous pouvez accéder à Thunder, Baidu Netdisk, etc. pour télécharger des ressources) La plupart des formats de liens magnétiques : magnet:?xt=urn : btih:infohash La méthode présentée ci-dessus consiste à créer un lien magnétique en obtenant infohash, puis à le télécharger à l'aide d'un logiciel tiers. Bien sûr, vous pouvez également le télécharger vous-même via le protocole BitTorrent. Si vous êtes intéressé, vous pouvez le rechercher vous-même. D'accord, ce qui précède présente simplement quelques étapes de mise en œuvre. De nombreux détails et implémentations spécifiques ne sont pas mentionnés. Dans mes propres mots, j'ai fait référence à certains projets github dht et je l'ai ensuite implémenté moi-même. :https://github.com/mistletoe9527/dht-spiderProtocole KRPC
dht.transmissionbt.com, etc.) pour rechercher et ajouter des nœuds via des requêtes find_node, et les nœuds renvoyés sont utilisés pour find_node.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre parfait en Java. Nous discutons ici de la définition, comment vérifier le nombre parfait en Java ?, des exemples d'implémentation de code.
 Weka en Java
Aug 30, 2024 pm 04:28 PM
Weka en Java
Aug 30, 2024 pm 04:28 PM
Guide de Weka en Java. Nous discutons ici de l'introduction, de la façon d'utiliser Weka Java, du type de plate-forme et des avantages avec des exemples.
 Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre de Smith en Java. Nous discutons ici de la définition, comment vérifier le numéro Smith en Java ? exemple avec implémentation de code.
 Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Dans cet article, nous avons conservé les questions d'entretien Java Spring les plus posées avec leurs réponses détaillées. Pour que vous puissiez réussir l'interview.
 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
 Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Guide de TimeStamp to Date en Java. Ici, nous discutons également de l'introduction et de la façon de convertir l'horodatage en date en Java avec des exemples.
 Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Les capsules sont des figures géométriques tridimensionnelles, composées d'un cylindre et d'un hémisphère aux deux extrémités. Le volume de la capsule peut être calculé en ajoutant le volume du cylindre et le volume de l'hémisphère aux deux extrémités. Ce tutoriel discutera de la façon de calculer le volume d'une capsule donnée en Java en utilisant différentes méthodes. Formule de volume de capsule La formule du volume de la capsule est la suivante: Volume de capsule = volume cylindrique volume de deux hémisphères volume dans, R: Le rayon de l'hémisphère. H: La hauteur du cylindre (à l'exclusion de l'hémisphère). Exemple 1 entrer Rayon = 5 unités Hauteur = 10 unités Sortir Volume = 1570,8 unités cubes expliquer Calculer le volume à l'aide de la formule: Volume = π × r2 × h (4
 Comment exécuter votre première application Spring Boot dans Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
Comment exécuter votre première application Spring Boot dans Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
Spring Boot simplifie la création d'applications Java robustes, évolutives et prêtes à la production, révolutionnant le développement de Java. Son approche "Convention sur la configuration", inhérente à l'écosystème de ressort, minimise la configuration manuelle, allo
