
 développement back-end
Tutoriel C#.Net
Parcours graphique de l'ordre des couches en C++ et impression couche par couche d'arbres binaires construits par des pointeurs intelligents
développement back-end
Tutoriel C#.Net
Parcours graphique de l'ordre des couches en C++ et impression couche par couche d'arbres binaires construits par des pointeurs intelligents
Parcours graphique de l'ordre des couches en C++ et impression couche par couche d'arbres binaires construits par des pointeurs intelligents

L'arbre binaire est une structure de données extrêmement courante, et il existe d'innombrables articles sur la façon de parcourir ses éléments. Cependant, la plupart des articles expliquent le parcours en pré-commande/en milieu de commande/après-commande. Il n'y a pas beaucoup d'articles sur l'impression d'éléments couche par couche. Les explications dans les articles existants sont également relativement obscures et difficiles à lire. Cet article utilisera des images vives et un code clair pour vous aider à comprendre la mise en œuvre du parcours par ordre de niveau. Dans le même temps, nous utilisons des pointeurs intelligents fournis par le C++ moderne pour simplifier la gestion des ressources des structures de données arborescentes.
Tutoriels associés : Tutoriel sur l'arborescence de la structure des données
Alors maintenant, entrons dans le vif du sujet.
Construire un arbre binaire à l'aide de pointeurs intelligents
Ce que nous voulons implémenter ici est un arbre binaire qui simule simplement un arbre de recherche binaire, fournissant une fonction d'insertion qui répond aux exigences d'un arbre de recherche binaire , y compris le parcours dans l'ordre . En même temps, nous utilisons shared_ptr pour gérer les ressources.
Maintenant, nous n'implémentons que deux méthodes : insert et ldr La mise en œuvre des autres méthodes n'est pas l'objet de cet article, mais nous les présenterons une par une dans les articles suivants :
struct BinaryTreeNode: public std::enable_shared_from_this<BinaryTreeNode> {
explicit BinaryTreeNode(const int value = 0)
: value_{value}, left{std::shared_ptr<BinaryTreeNode>{}}, right{std::shared_ptr<BinaryTreeNode>{}}
{}
void insert(const int value)
{
if (value < value_) {
if (left) {
left->insert(value);
} else {
left = std::make_shared<BinaryTreeNode>(value);
}
}
if (value > value_) {
if (right) {
right->insert(value);
} else {
right = std::make_shared<BinaryTreeNode>(value);
}
}
}
// 中序遍历
void ldr()
{
if (left) {
left->ldr();
}
std::cout << value_ << "\n";
if (right) {
right->ldr();
}
}
// 分层打印
void layer_print();
int value_;
// 左右子节点
std::shared_ptr<BinaryTreeNode> left;
std::shared_ptr<BinaryTreeNode> right;
private:
// 层序遍历
std::vector<std::shared_ptr<BinaryTreeNode>> layer_contents();
};, ce n'est généralement pas nécessaire, mais afin de faciliter le fonctionnement lors du parcours par ordre de couche, nous devons construire un pointeur intelligent à partir de enable_shared_from_this, cette étape est donc nécessaire. this insérera les éléments plus petits que la racine dans le sous-arbre de gauche, et les éléments plus grands que la racine seront insérés dans le sous-arbre de droite insert est le parcours dans l'ordre le plus conventionnel. Il est implémenté ici pour afficher tous les éléments de l'arborescence. d'une manière conventionnelle. ldr
pour les créer au lieu de les initialiser en tant qu'objets globaux/locaux, sinon il sera détruit en raison de la destruction de make_shared lors parcours d'ordre de couche. Provoque la destruction de l'objet, provoquant un comportement indéfini. shared_ptr
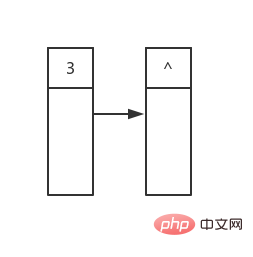
auto root = std::make_shared<BinaryTreeNode>(3); root->insert(1); root->insert(0); root->insert(2); root->insert(5); root->insert(4); root->insert(6); root->insert(7);

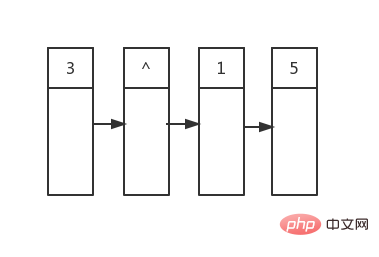
, puis nous imprimons les valeurs de tous ses nœuds enfants, qui sont 3 et 1. , puis les enfants des nœuds enfants gauche et droit, et ainsi de suite. . . . . . 5
. nullptr
std::vector<std::shared_ptr<BinaryTreeNode>>
BinaryTreeNode::layer_contents()
{
std::vector<std::shared_ptr<BinaryTreeNode>> nodes;
// 先添加根节点,根节点自己就会占用一行输出,所以添加了作为行分隔符的nullptr
// 因为需要保存this,所以这是我们需要继承enable_shared_from_this是理由
// 同样是因为这里,当返回的结果容器析构时this的智能指针也会析构
// 如果我们使用了局部变量则this的引用计数从1减至0,导致对象被销毁,而使用了make_shared创建的对象引用计数是从2到1,没有问题
nodes.push_back(shared_from_this());
nodes.push_back(nullptr);
// 我们使用index而不是迭代器,是因为添加元素时很可能发生迭代器失效,处理这一问题将会耗费大量精力,而index则无此烦恼
for (int index = 0; index < nodes.size(); ++index) {
if (!nodes[index]) {
// 子节点打印完成或已经遍历到队列末尾
if (index == nodes.size()-1) {
break;
}
nodes.push_back(nullptr); // 添加分隔符
continue;
}
if (nodes[index]->left) { // 将当前节点的子节点都添加进队列
nodes.push_back(nodes[index]->left);
}
if (nodes[index]->right) {
nodes.push_back(nodes[index]->right);
}
}
return nodes;
}


void BinaryTreeNode::layer_print()
{
auto nodes = layer_contents();
for (auto iter = nodes.begin(); iter != nodes.end(); ++iter) {
// 空指针代表一行结束,这里我们遇到空指针就输出换行符
if (*iter) {
std::cout << (*iter)->value_ << " ";
} else {
std::cout << "\n";
}
}
}如你所见,这个方法足够简单,我们把节点信息保存在额外的容器中是为了方便做进一步的处理,如果只是打印的话大可不必这么麻烦,不过简单通常是有代价的。对于我们的实现来说,分隔符的存在简化了我们对层级之间的区分,然而这样会导致浪费至少log2(n)+1个vector的存储空间,某些情况下可能引起性能问题,而且通过合理得使用计数变量可以避免这些额外的空间浪费。当然具体的实现读者可以自己挑战一下,原理和我们上面介绍的是类似的因此就不在赘述了,也可以参考园内其他的博客文章。
测试
最后让我们看看完整的测试程序,记住要用make_shared创建root实例:
int main()
{
auto root = std::make_shared<BinaryTreeNode>(3);
root->insert(1);
root->insert(0);
root->insert(2);
root->insert(5);
root->insert(4);
root->insert(6);
root->insert(7);
root->ldr();
std::cout << "\n";
root->layer_print();
}输出:
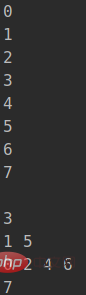
可以看到上半部分是中序遍历的结果,下半部分是层序遍历的输出,而且是逐行打印的,不过我们没有做缩进。所以不太美观。
另外你可能已经发现了,我们没有写任何有关资源释放的代码,没错,这就是智能指针的威力,只要注意资源的创建,剩下的事都可以放心得交给智能指针处理,我们可以把更多的精力集中在算法和功能的实现上。
如有错误和疑问欢迎指出!
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quel est le rôle de char dans les chaînes C
Apr 03, 2025 pm 03:15 PM
Quel est le rôle de char dans les chaînes C
Apr 03, 2025 pm 03:15 PM
En C, le type de char est utilisé dans les chaînes: 1. Stockez un seul caractère; 2. Utilisez un tableau pour représenter une chaîne et se terminer avec un terminateur nul; 3. Faire fonctionner via une fonction de fonctionnement de chaîne; 4. Lisez ou sortant une chaîne du clavier.
 Quatre façons d'implémenter le multithreading dans le langage C
Apr 03, 2025 pm 03:00 PM
Quatre façons d'implémenter le multithreading dans le langage C
Apr 03, 2025 pm 03:00 PM
Le multithreading dans la langue peut considérablement améliorer l'efficacité du programme. Il existe quatre façons principales d'implémenter le multithreading dans le langage C: créer des processus indépendants: créer plusieurs processus en cours d'exécution indépendante, chaque processus a son propre espace mémoire. Pseudo-Multithreading: Créez plusieurs flux d'exécution dans un processus qui partagent le même espace mémoire et exécutent alternativement. Bibliothèque multi-thread: Utilisez des bibliothèques multi-threades telles que PTHEADS pour créer et gérer des threads, en fournissant des fonctions de fonctionnement de thread riches. Coroutine: une implémentation multi-thread légère qui divise les tâches en petites sous-tâches et les exécute tour à tour.
 Comment calculer C-SUBScript 3 Indice 5 C-SUBScript 3 Indice Indice 5 Tutoriel d'algorithme
Apr 03, 2025 pm 10:33 PM
Comment calculer C-SUBScript 3 Indice 5 C-SUBScript 3 Indice Indice 5 Tutoriel d'algorithme
Apr 03, 2025 pm 10:33 PM
Le calcul de C35 est essentiellement des mathématiques combinatoires, représentant le nombre de combinaisons sélectionnées parmi 3 des 5 éléments. La formule de calcul est C53 = 5! / (3! * 2!), Qui peut être directement calculé par des boucles pour améliorer l'efficacité et éviter le débordement. De plus, la compréhension de la nature des combinaisons et la maîtrise des méthodes de calcul efficaces est cruciale pour résoudre de nombreux problèmes dans les domaines des statistiques de probabilité, de la cryptographie, de la conception d'algorithmes, etc.
 Fonction de fonction distincte Distance de distance C Tutoriel d'utilisation
Apr 03, 2025 pm 10:27 PM
Fonction de fonction distincte Distance de distance C Tutoriel d'utilisation
Apr 03, 2025 pm 10:27 PM
STD :: Unique supprime les éléments en double adjacents dans le conteneur et les déplace jusqu'à la fin, renvoyant un itérateur pointant vers le premier élément en double. STD :: Distance calcule la distance entre deux itérateurs, c'est-à-dire le nombre d'éléments auxquels ils pointent. Ces deux fonctions sont utiles pour optimiser le code et améliorer l'efficacité, mais il y a aussi quelques pièges à prêter attention, tels que: std :: unique traite uniquement des éléments en double adjacents. STD :: La distance est moins efficace lorsqu'il s'agit de transacteurs d'accès non aléatoires. En maîtrisant ces fonctionnalités et les meilleures pratiques, vous pouvez utiliser pleinement la puissance de ces deux fonctions.
 Comment appliquer la nomenclature des serpents dans le langage C?
Apr 03, 2025 pm 01:03 PM
Comment appliquer la nomenclature des serpents dans le langage C?
Apr 03, 2025 pm 01:03 PM
Dans le langage C, Snake Nomenclature est une convention de style de codage, qui utilise des soulignements pour connecter plusieurs mots pour former des noms de variables ou des noms de fonction pour améliorer la lisibilité. Bien que cela n'affecte pas la compilation et l'exploitation, la dénomination longue, les problèmes de support IDE et les bagages historiques doivent être pris en compte.
 Utilisation de la libération de la release en C
Apr 04, 2025 am 07:54 AM
Utilisation de la libération de la release en C
Apr 04, 2025 am 07:54 AM
La fonction release_semaphore en C est utilisée pour libérer le sémaphore obtenu afin que d'autres threads ou processus puissent accéder aux ressources partagées. Il augmente le nombre de sémaphore de 1, permettant au fil de blocage de continuer l'exécution.
 C Structure des données du langage: Le rôle clé des structures de données dans l'intelligence artificielle
Apr 04, 2025 am 10:45 AM
C Structure des données du langage: Le rôle clé des structures de données dans l'intelligence artificielle
Apr 04, 2025 am 10:45 AM
C Structure des données du langage: Aperçu du rôle clé de la structure des données dans l'intelligence artificielle dans le domaine de l'intelligence artificielle, les structures de données sont cruciales pour traiter de grandes quantités de données. Les structures de données fournissent un moyen efficace d'organiser et de gérer les données, d'optimiser les algorithmes et d'améliorer l'efficacité du programme. Les structures de données courantes utilisées couramment les structures de données dans le langage C comprennent: les tableaux: un ensemble d'éléments de données stockés consécutivement avec le même type. Structure: un type de données qui organise différents types de données ensemble et leur donne un nom. Liste liée: une structure de données linéaire dans laquelle les éléments de données sont connectés ensemble par des pointeurs. Stack: Structure de données qui suit le dernier principe de premier-out (LIFO). File: Structure de données qui suit le premier principe de première sortie (FIFO). Cas pratique: le tableau adjacent dans la théorie des graphiques est l'intelligence artificielle
 Problèmes avec la version Dev-C
Apr 03, 2025 pm 07:33 PM
Problèmes avec la version Dev-C
Apr 03, 2025 pm 07:33 PM
Dev-C 4.9.9.2 Erreurs et solutions de compilation Lors de la compilation de programmes dans le système Windows 11 à l'aide de Dev-C 4.9.9.2, le volet d'enregistrement du compilateur peut afficher le message d'erreur suivant: GCCC.EXE: InternalError: Aborti (ProgramCollect2) Pleasesubmitafullbugreport.seeforinsstructions. Bien que la "compilation finale soit réussie", le programme réel ne peut pas s'exécuter et un message d'erreur "Archive de code d'origine ne peut pas être compilé" apparaît. C'est généralement parce que le linker recueille
