
 base de données
tutoriel mysql
Quelles sont les différences entre les moteurs de stockage MySQL ?
base de données
tutoriel mysql
Quelles sont les différences entre les moteurs de stockage MySQL ?
Quelles sont les différences entre les moteurs de stockage MySQL ?

La différence entre les moteurs de stockage dans MySQL : en prenant Innodb et myisam comme exemple, le premier prend en charge les transactions mais pas le second ; le premier met l'accent sur la polyvalence et prend en charge des fonctions plus étendues, tandis que le second se concentre principalement sur les performances ; ne prend pas en charge l'indexation en texte intégral, et cette dernière prend en charge l'indexation en texte intégral, etc.
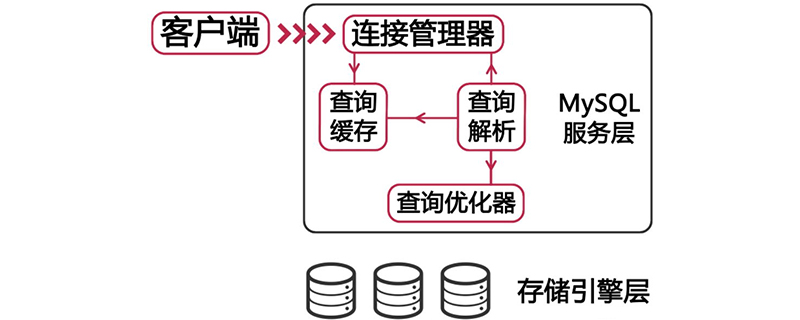
MySQL prend en charge ici plusieurs moteurs de stockage. moteurs. Innodb, myisam
INNODB
Implémentation de l'index INNODB
La même chose que MyISAM est qu'InnoDB utilise également B+Tree Cette structure de données est utilisée pour implémenter l'index B-Tree. La grande différence est que le moteur de stockage InnoDB utilise la méthode de stockage de données « index clusterisé » pour implémenter l'index B-Tree. Ce que l'on appelle « l'agrégation » signifie que les lignes de données et les valeurs clés adjacentes sont stockées ensemble de manière compacte. .Notez qu'InnoDB ne peut que Les enregistrements d'une page feuille (16 Ko) sont agrégés (c'est-à-dire que l'index clusterisé satisfait une certaine plage d'enregistrements), de sorte que les enregistrements contenant des valeurs de clé adjacentes peuvent être éloignés les uns des autres.
Dans InnoDB, la table est appelée table organisée par index. InnoDB construit un B+Tree en fonction de la clé primaire (s'il n'y a pas de clé primaire, un index unique et non vide sera sélectionné à la place. Si Sans un tel index, InnoDB définira implicitement une clé primaire comme un index clusterisé), et les pages feuilles stockent les données d'enregistrement de ligne de la table entière. Les nœuds feuilles de l'index clusterisé peuvent également être appelés pages de données et non-feuilles. les pages peuvent être considérées comme un index clairsemé de pages feuilles.
La figure suivante illustre l'implémentation de l'index clusterisé InnoDB et reflète également la structure d'une table innoDB. On peut voir que dans InnoDB, l'index de clé primaire et les données sont intégrés et non séparés.
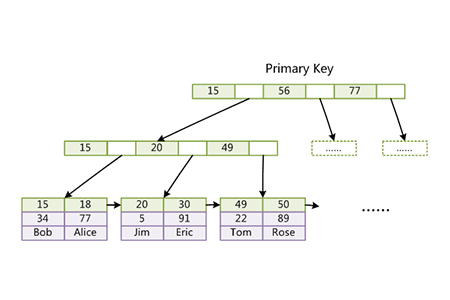
Cette méthode d'implémentation donne à InnoDB des performances ultra-élevées pour la récupération par clé primaire. Vous pouvez choisir délibérément un index clusterisé, tel qu'une table de courrier, et vous pouvez choisir l'ID utilisateur pour agréger les données. De cette façon, il vous suffit de lire un petit nombre de pages de données consécutives à partir du disque pour obtenir tous les courriers d'un. utilisateur avec un certain identifiant, évitant ainsi le besoin d'E/S aléatoires passées à lire des pages dispersées.
InnoDB est une opération d'E/S Innodb utilise MVCC pour lire et écrire afin de prendre en charge une concurrence élevée.
Analyse complète de la table
Lorsque InnoDB effectue une analyse complète de la table, elle n'est pas efficace car InnoDB ne lit pas réellement de manière séquentielle. Dans la plupart des cas, il lit Pick de manière aléatoire. . Lors d'une analyse complète de la table, InnoDB analyse les pages et les lignes dans l'ordre des clés primaires. Cela s'applique à toutes les tables InnoDB, y compris les tables fragmentées. Si la table des pages de clé primaire (la table des pages qui stocke les clés primaires et les lignes) n'est pas fragmentée, une analyse complète de la table est assez rapide car l'ordre de lecture est proche de l'ordre de stockage physique. Mais lorsque la page de clé primaire est fragmentée, l'analyse deviendra très lente
Verrouillage au niveau de la ligne
Fournit le verrouillage des lignes (verrouillage au niveau de la ligne), fourni avec Oracle Lecture non verrouillable de type cohérent dans les SELECT De plus, le verrouillage des lignes de la table InnoDB n'est pas absolu. Si MySQL ne peut pas déterminer la plage à analyser lors de l'exécution d'une instruction SQL, la table InnoDB verrouillera également la table entière. tels que
update table set num=1 where name like “%aaa%”
MYISAM
Implémentation des index MyISAM
Chaque MyISAM est stocké sous forme de trois fichiers sur le disque. Le nom du premier fichier commence par le nom de la table et l'extension indique le type de fichier. Le fichier d'index MyISAM [.MYI (MYIndex)] et le fichier de données [.MYD (MYData)] sont séparés. Le fichier d'index enregistre uniquement le pointeur (emplacement physique) de la page où se trouve l'enregistrement. ces adresses, puis la page est lue. La ligne indexée. Jetons d'abord un coup d'œil au diagramme de structure
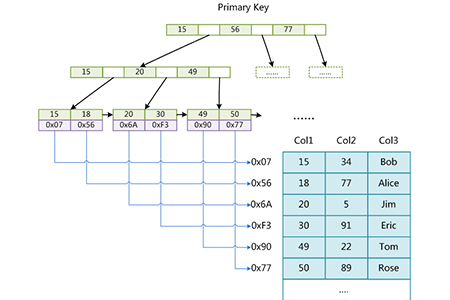
L'image ci-dessus illustre bien que les feuilles de l'arbre enregistrent l'emplacement physique de la rangée correspondante. Grâce à cette valeur, le moteur de stockage peut interroger la table en douceur et obtenir une ligne complète d'enregistrements. Dans le même temps, chaque page feuille enregistre également un pointeur vers la page feuille suivante. Cela facilite la traversée de la plage des nœuds feuilles. Quant à l'index secondaire, il est implémenté dans le moteur de stockage MyISAM de la même manière que la figure ci-dessus. Cela montre également que la méthode d'indexation de MyISAM est "non clusterisée", ce qui contraste avec "l'index clusterisé" d'Innodb
.MyISAM lira l'index en mémoire par défaut et fonctionnera directement en mémoire
Verrouillage au niveau de la table
Résumé : Innodb met l'accent sur la polyvalence et la comparaison des supports pris en charge ; Fonctions étendues Beaucoup, myisam se concentre principalement sur les performances
Différences
1. InnoDB prend en charge les transactions, mais MyISAM ne le fait pas. Pour InnoDB, chaque langage SQL est encapsulé dans une transaction. par défaut et automatiquement soumis. , cela affectera la vitesse, il est donc préférable de placer plusieurs instructions SQL entre start et commit pour former une transaction
2. lié à l'index et doit être Il doit y avoir une clé primaire, et l'indexation via la clé primaire est très efficace. Cependant, l'index auxiliaire nécessite deux requêtes, d'abord pour interroger la clé primaire, puis pour interroger les données via la clé primaire. Par conséquent, la clé primaire ne doit pas être trop grande, car si la clé primaire est trop grande, les autres index le seront également. MyISAM est un index non clusterisé, les fichiers de données sont séparés et l'index enregistre le pointeur du fichier de données. Les index de clé primaire et les index secondaires sont indépendants.
3. InnoDB n'enregistre pas le nombre spécifique de lignes dans la table. Lors de l'exécution de select count(*) from table, une analyse complète de la table est requise. MyISAM utilise une variable pour enregistrer le nombre de lignes dans la table entière. Lors de l'exécution de l'instruction ci-dessus, il vous suffit de lire la variable, ce qui est très rapide
4. , alors que MyISAM prend en charge l'index de texte intégral, MyISAM est plus élevé
;Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 qu'est-ce que mysql innodb
Apr 14, 2023 am 10:19 AM
qu'est-ce que mysql innodb
Apr 14, 2023 am 10:19 AM
InnoDB est l'un des moteurs de base de données de MySQL. C'est désormais le moteur de stockage par défaut de MySQL et l'une des normes pour les versions binaires de MySQL AB adopte un système d'autorisation à double voie, l'une est une autorisation GPL et l'autre est un logiciel propriétaire. autorisation. InnoDB est le moteur préféré pour les bases de données transactionnelles et prend en charge les tables de sécurité des transactions (ACID) ; InnoDB prend en charge les verrous au niveau des lignes, qui peuvent prendre en charge dans la plus grande mesure la concurrence. Les verrous au niveau des lignes sont implémentés par la couche moteur de stockage.
 Comment MySQL voit le format de ligne InnoDB à partir du contenu binaire
Jun 03, 2023 am 09:55 AM
Comment MySQL voit le format de ligne InnoDB à partir du contenu binaire
Jun 03, 2023 am 09:55 AM
InnoDB est un moteur de stockage qui stocke les données dans des tables sur disque, de sorte que nos données existeront toujours même après l'arrêt et le redémarrage. Le processus réel de traitement des données se produit en mémoire, de sorte que les données du disque doivent être chargées dans la mémoire. S'il traite une demande d'écriture ou de modification, le contenu de la mémoire doit également être actualisé sur le disque. Et nous savons que la vitesse de lecture et d'écriture sur le disque est très lente, ce qui est plusieurs ordres de grandeur différents de la lecture et de l'écriture en mémoire. Ainsi, lorsque nous voulons obtenir certains enregistrements de la table, le moteur de stockage InnoDB doit-il lire. les enregistrements du disque un par un ? La méthode adoptée par InnoDB consiste à diviser les données en plusieurs pages et à utiliser les pages comme unité de base d'interaction entre le disque et la mémoire. La taille d'une page dans InnoDB est généralement de 16.
 Comment gérer l'exception mysql innodb
Apr 17, 2023 pm 09:01 PM
Comment gérer l'exception mysql innodb
Apr 17, 2023 pm 09:01 PM
1. Restaurez et réinstallez MySQL Afin d'éviter d'avoir à importer ces données depuis d'autres endroits, effectuez d'abord une sauvegarde du fichier de base de données de la bibliothèque actuelle (/var/lib/mysql/location). Ensuite, j'ai désinstallé le package Perconaserver5.7, réinstallé l'ancien package 5.1.71 d'origine, démarré le service mysql, et il a demandé Unknown/unsupportedtabletype:innodb et n'a pas pu démarrer normalement. 11050912:04:27InnoDB : initialisation du pool de tampons, taille = 384,0 M11050912:04:27InnoDB : terminé
 Comparaison de sélection du moteur de stockage MySQL : évaluation de l'indice de performance InnoDB, MyISAM et mémoire
Jul 26, 2023 am 11:25 AM
Comparaison de sélection du moteur de stockage MySQL : évaluation de l'indice de performance InnoDB, MyISAM et mémoire
Jul 26, 2023 am 11:25 AM
Comparaison de sélection du moteur de stockage MySQL : évaluation de l'indice de performance InnoDB, MyISAM et mémoire Introduction : Dans la base de données MySQL, le choix du moteur de stockage joue un rôle essentiel dans les performances du système et l'intégrité des données. MySQL fournit une variété de moteurs de stockage, les moteurs les plus couramment utilisés incluent InnoDB, MyISAM et Memory. Cet article évaluera les indicateurs de performances de ces trois moteurs de stockage et les comparera à travers des exemples de code. 1. Moteur InnoDB InnoDB est mon
 Comment résoudre la lecture fantôme dans innoDB dans Mysql
May 27, 2023 pm 03:34 PM
Comment résoudre la lecture fantôme dans innoDB dans Mysql
May 27, 2023 pm 03:34 PM
1. Niveau d'isolement des transactions Mysql Ces quatre niveaux d'isolement, lorsqu'il y a plusieurs conflits de concurrence de transactions, certains problèmes de lecture sale, de lecture non répétable et de lecture fantôme peuvent survenir, et innoDB les résout en mode niveau d'isolement de lecture répétable. de la lecture fantôme, 2. Qu'est-ce que la lecture fantôme ? La lecture fantôme signifie que dans la même transaction, les résultats obtenus en interrogeant la même plage deux fois avant et après sont incohérents, comme le montre la figure. Dans la première transaction, nous exécutons une requête de plage. À l'heure actuelle, il n'y a qu'une seule donnée qui remplit les conditions. Dans la deuxième transaction, il insère une ligne de données et la soumet. Ensuite, lorsque la première transaction est à nouveau interrogée, le résultat obtenu est un de plus que le résultat de. la première requête Data, notez que les première et deuxième requêtes de la première transaction sont toutes deux identiques.
 Expliquez les capacités de recherche en texte intégral InNODB.
Apr 02, 2025 pm 06:09 PM
Expliquez les capacités de recherche en texte intégral InNODB.
Apr 02, 2025 pm 06:09 PM
Les capacités de recherche en texte intégral d'InNODB sont très puissantes, ce qui peut considérablement améliorer l'efficacité de la requête de la base de données et la capacité de traiter de grandes quantités de données de texte. 1) INNODB implémente la recherche de texte intégral via l'indexation inversée, prenant en charge les requêtes de recherche de base et avancées. 2) Utilisez la correspondance et contre les mots clés pour rechercher, prendre en charge le mode booléen et la recherche de phrases. 3) Les méthodes d'optimisation incluent l'utilisation de la technologie de segmentation des mots, la reconstruction périodique des index et l'ajustement de la taille du cache pour améliorer les performances et la précision.
 Comment utiliser les moteurs de stockage MyISAM et InnoDB pour optimiser les performances de MySQL
May 11, 2023 pm 06:51 PM
Comment utiliser les moteurs de stockage MyISAM et InnoDB pour optimiser les performances de MySQL
May 11, 2023 pm 06:51 PM
MySQL est un système de gestion de bases de données largement utilisé et différents moteurs de stockage ont des impacts différents sur les performances des bases de données. MyISAM et InnoDB sont les deux moteurs de stockage les plus couramment utilisés dans MySQL. Ils ont des caractéristiques différentes et une mauvaise utilisation peut affecter les performances de la base de données. Cet article explique comment utiliser ces deux moteurs de stockage pour optimiser les performances de MySQL. 1. Moteur de stockage MyISAM MyISAM est le moteur de stockage le plus couramment utilisé pour MySQL. Ses avantages sont une vitesse rapide et un petit espace de stockage. MonISA
 Conseils et stratégies pour améliorer les performances de lecture du moteur de stockage MySQL : analyse comparative de MyISAM et InnoDB
Jul 26, 2023 am 10:01 AM
Conseils et stratégies pour améliorer les performances de lecture du moteur de stockage MySQL : analyse comparative de MyISAM et InnoDB
Jul 26, 2023 am 10:01 AM
Conseils et stratégies pour améliorer les performances de lecture du moteur de stockage MySQL : Analyse comparative de MyISAM et InnoDB Introduction : MySQL est l'un des systèmes de gestion de bases de données relationnelles open source les plus couramment utilisés, principalement utilisé pour stocker et gérer de grandes quantités de données structurées. Dans les applications, les performances de lecture de la base de données sont souvent très importantes, car les opérations de lecture constituent le principal type d'opérations dans la plupart des applications. Cet article se concentrera sur la façon d'améliorer les performances de lecture du moteur de stockage MySQL, en se concentrant sur une analyse comparative de MyISAM et InnoDB, deux moteurs de stockage couramment utilisés.
