

Quelle technologie est nécessaire pour l'entrepôt de données

Le Data Warehousing est une série de nouvelles technologies d'application développées sur la base de la technologie des systèmes de bases de données en fonction des besoins de développement commercial des systèmes d'information et devenant progressivement indépendantes. Il existe deux technologies principales pour l'entrepôt de données : OLTP et OLAP. Analysons-les ci-dessous :

1. OLTP et OLAP
. Le nom complet d'OLTP est Online Transaction Processing. OLTP utilise principalement des bases de données relationnelles traditionnelles pour le traitement des transactions. L'exigence principale d'OLTP est le traitement efficace et rapide d'enregistrements uniques. Les exigences les plus fondamentales telles que la technologie d'indexation, la sous-base de données et la sous-table visent à résoudre ce problème.
Le nom complet d'OLAP est Online Analytical Processing. OLAP peut traiter et compter une grande quantité de données, contrairement à la base de données OLTP, qui doit prendre en compte l'ajout, la suppression, la modification et le contrôle de la concurrence des données, les données OLAP en général. n'a besoin que de traiter les demandes de requêtes de données. Les importations sont importées par lots, de sorte que la réponse aux demandes peut être considérablement accélérée grâce à des technologies telles que le stockage de colonnes, la compression de colonnes et l'indexation bitmap.
2. Comparaison simple des données OLTP et OLAP
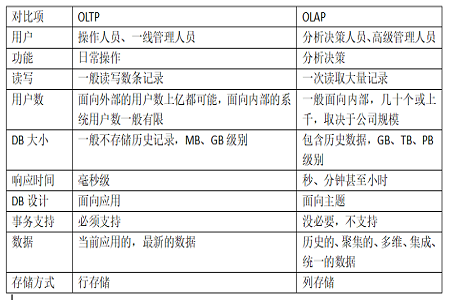
3. 🎜>Les entrepôts de données hors ligne sont généralement construits sur la base de la théorie de la modélisation dimensionnelle. Les entrepôts de données hors ligne sont généralement superposés de manière logique. La segmentation des mots est principalement basée sur les considérations suivantes :
1. des données soigneusement traitées par l'équipe chargée des données, plutôt que des données brutes provenant du système d'entreprise. Le premier avantage est que les utilisateurs utilisent des données soigneusement préparées, standardisées et propres d'un point de vue commercial. Très facile à comprendre et à utiliser. Deuxièmement, si le système métier en amont est modifié ou même reconstruit (comme la structure des tables, les champs, la signification métier, etc.), l'équipe de données sera responsable de gérer tous ces changements et de minimiser l'impact sur les utilisateurs en aval.
2. Performances et maintenabilité : les professionnels font des choses professionnelles. La superposition des données fait que le traitement des données est essentiellement effectué par l'équipe de données, de sorte que la même logique métier n'a pas besoin d'être exécutée à plusieurs reprises, économisant ainsi le stockage et les calculs correspondants. aérien. De plus, la superposition de données rend également la maintenance de l'entrepôt de données claire et pratique. Chaque couche n'est responsable que de ses propres tâches. S'il y a un problème avec le traitement des données sur une certaine couche, il vous suffit de modifier cette couche.
3. Normalisation : Pour une entreprise et une organisation, le calibre des données est très important Lorsque tout le monde parle d'un indicateur, il doit s'appuyer sur un calibre clair et reconnu. standardiser.
4. Couche ODS : Les tables de données du système source de l'entrepôt de données sont généralement stockées intactes. C'est ce qu'on appelle la couche ODS (Operation Data Store). La couche ODS est également souvent appelée zone de préparation (zone de préparation). ), ils sont la source des données traitées par la couche d'entrepôt de données suivante (c'est-à-dire la couche de table de faits et de table de dimensions générée sur la base de la modélisation dimensionnelle de Kimball, et les données de la couche récapitulative traitées sur la base de ces tables de faits et tables de détail). En même temps, la couche ODS stocke également des données historiques incrémentielles ou des données complètes.
5. Couches DWD et DWS : les détails de l'entrepôt de données (DWD) et le résumé de l'entrepôt de données (DWS) font l'objet de l'entrepôt de données. Les données des couches DWD et DWS sont générées par la couche ODS après nettoyage, conversion et chargement ETL, et elles sont généralement construites sur la base de la théorie de modélisation dimensionnelle de Kimball, et les dimensions de chaque sous-thème sont garanties par des dimensions et des bus de données cohérents. cohérence.
6. Couche application (ADS) : La couche application est principalement le data mart (Data Mart, DM) établi par chaque département ou département métier sur la base de DWD et DWS. Le data mart DM est relatif à DWD et. DWS. Pour l'entrepôt de données (DW). De manière générale, les données de la couche application proviennent de la couche DW, mais en principe, l'accès direct à la couche ODS n'est pas autorisé. De plus, par rapport à la couche DW, la couche application ne contient que des données de couche détaillées et récapitulatives qui intéressent les départements ou les parties eux-mêmes.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Partager l'expérience de projet en matière de traitement de données et d'entrepôt de données grâce au développement MySQL
Nov 03, 2023 am 09:39 AM
Partager l'expérience de projet en matière de traitement de données et d'entrepôt de données grâce au développement MySQL
Nov 03, 2023 am 09:39 AM
À l’ère numérique d’aujourd’hui, les données sont généralement considérées comme la base et le capital de la prise de décision des entreprises. Cependant, le processus consistant à traiter de grandes quantités de données et à les transformer en informations fiables d’aide à la décision n’est pas facile. À l’heure actuelle, le traitement et l’entreposage des données commencent à jouer un rôle important. Cet article partagera une expérience de projet dans la mise en œuvre du traitement des données et de l'entrepôt de données via le développement MySQL. 1. Contexte du projet Ce projet est basé sur les besoins de construction de données d'une entreprise commerciale et vise à réaliser l'agrégation, la cohérence, le nettoyage et la fiabilité des données grâce au traitement des données et à l'entrepôt de données. Données pour cette implémentation
 Utilisez le langage Hive in Go pour mettre en œuvre un entrepôt de données efficace
Jun 15, 2023 pm 08:52 PM
Utilisez le langage Hive in Go pour mettre en œuvre un entrepôt de données efficace
Jun 15, 2023 pm 08:52 PM
Ces dernières années, les entrepôts de données sont devenus partie intégrante de la gestion des données d'entreprise. L'utilisation directe de la base de données pour l'analyse des données peut répondre à des besoins de requêtes simples, mais lorsque nous devons effectuer une analyse de données à grande échelle, une seule base de données ne peut plus répondre aux besoins. À l'heure actuelle, nous devons utiliser un entrepôt de données pour traiter des données massives. . Hive est l'un des composants open source les plus populaires dans le domaine des entrepôts de données. Il peut intégrer le moteur informatique distribué Hadoop et les requêtes SQL et prendre en charge le traitement parallèle de données massives. En même temps, en langage Go, utilisez
 Briser les silos de données grâce à un entrepôt de données unifié : CDP basé sur Apache Doris
Mar 20, 2024 pm 01:47 PM
Briser les silos de données grâce à un entrepôt de données unifié : CDP basé sur Apache Doris
Mar 20, 2024 pm 01:47 PM
À mesure que les sources de données des entreprises se diversifient de plus en plus, le problème des silos de données est devenu courant. Lorsque les compagnies d’assurance créent des plates-formes de données clients (CDP), elles sont confrontées au problème des couches informatiques à forte intensité de composants et du stockage des données dispersées causé par les silos de données. Afin de résoudre ces problèmes, ils ont adopté CDP 2.0 basé sur Apache Doris, en utilisant les capacités d'entrepôt de données unifiées de Doris pour briser les silos de données, simplifier les pipelines de traitement des données et améliorer l'efficacité du traitement des données.
 Comment le langage Go prend-il en charge les applications d'entrepôt de données et d'analyse de données sur le cloud ?
May 17, 2023 pm 04:51 PM
Comment le langage Go prend-il en charge les applications d'entrepôt de données et d'analyse de données sur le cloud ?
May 17, 2023 pm 04:51 PM
Ces dernières années, avec le développement continu de la technologie du cloud computing, l'entrepôt de données et l'analyse des données sur le cloud sont devenus un sujet de préoccupation pour de plus en plus d'entreprises. En tant que langage de programmation efficace et facile à apprendre, comment le langage Go prend-il en charge les applications d'entrepôt de données et d'analyse de données sur le cloud ? Application de développement d'entrepôt de données cloud en langage Go Pour développer des applications d'entrepôt de données sur le cloud, le langage Go peut utiliser une variété de cadres et d'outils de développement, et le processus de développement est généralement très simple. Parmi eux, plusieurs outils importants incluent : 1.1GoCloudGoCloud est un
 Quelles sont les caractéristiques exceptionnelles d'un entrepôt de données par rapport à une base de données opérationnelle ?
Jul 19, 2022 pm 04:15 PM
Quelles sont les caractéristiques exceptionnelles d'un entrepôt de données par rapport à une base de données opérationnelle ?
Jul 19, 2022 pm 04:15 PM
Les fonctionnalités exceptionnelles sont la « prise en charge massive des données » et la « technologie de récupération rapide ». L'entrepôt de données est un environnement de données structuré pour les systèmes d'aide à la décision et les sources de données des applications d'analyse en ligne, et la base de données est le cœur de l'ensemble de l'environnement de l'entrepôt de données, où les données sont stockées et fournissent un support pour la récupération de données par rapport aux bases de données manipulatrices ; Il se caractérise par la prise en charge de données massives et une technologie de récupération rapide.
 Intégration de PHP et de l'entrepôt de données
May 16, 2023 pm 11:10 PM
Intégration de PHP et de l'entrepôt de données
May 16, 2023 pm 11:10 PM
Avec le développement rapide d’Internet et du Big Data, de plus en plus d’entreprises commencent à utiliser les entrepôts de données comme infrastructure importante pour soutenir le développement commercial. En tant que langage de programmation populaire, PHP est progressivement devenu le premier choix pour de nombreuses entreprises et organisations. Alors, comment intégrer PHP à un entrepôt de données ? 1. Présentation de l'entrepôt de données L'entrepôt de données fait référence à un système de stockage de données à grande échelle construit avec un thème comme noyau et selon un certain modèle de données et une certaine architecture de données. Son objectif est d'améliorer la vitesse d'accès aux données et l'efficacité des requêtes.
 Comment s'assurer que les projets d'IA et d'analyse n'échouent pas ?
May 08, 2023 pm 06:40 PM
Comment s'assurer que les projets d'IA et d'analyse n'échouent pas ?
May 08, 2023 pm 06:40 PM
2023 est une année marquée par une escalade des crises économiques et des risques climatiques. C'est pourquoi le besoin d'informations basées sur les données pour favoriser l'efficacité, la résilience et d'autres initiatives clés sera une priorité absolue pour les entreprises en 2023. De nombreuses entreprises ont tenté d’adopter des analyses avancées et l’intelligence artificielle pour répondre à ce besoin. Désormais, ils doivent transformer la preuve de concept en retour sur investissement. De nombreuses entreprises font d’énormes progrès en investissant beaucoup de talents et les bons logiciels. Cependant, de nombreux projets d’IA et d’analyse d’entreprises échouent parce qu’elles ne disposent pas des technologies de base appropriées pour prendre en charge les charges de travail d’IA et d’analyse avancée. Certaines entreprises s'appuient sur des systèmes matériels obsolètes, tandis que d'autres sont gênées par les problèmes de coût et de contrôle liés à l'exploitation du cloud public. La plupart des entreprises
 Comment utiliser Java pour développer une application d'entrepôt de données basée sur Hive
Sep 21, 2023 pm 04:48 PM
Comment utiliser Java pour développer une application d'entrepôt de données basée sur Hive
Sep 21, 2023 pm 04:48 PM
Comment utiliser Java pour développer une application d'entrepôt de données basée sur Hive Introduction : À l'ère actuelle du Big Data, l'entrepôt de données est un outil important permettant aux entreprises de stocker et de traiter des données massives. En tant que membre de l'écosystème Hadoop, Hive fournit des solutions d'entrepôt de données. Cet article vise à présenter comment utiliser Java pour développer une application d'entrepôt de données basée sur Hive et à fournir des exemples de code détaillés. 1. Préparation Avant de commencer, nous devons nous assurer des points suivants : installer Hadoop et Hive et nous assurer qu'ils fonctionnent correctement