

1 Introduction
Ne parlons pas de la fréquence du CPU, de la taille de la mémoire (c'est aussi important que l'index, mais ce n'est pas ce dont parle cet article) , et le temps de recherche du disque dur. En ce qui concerne le réglage de MySQL, vous devez au moins connaître le plan d'exécution d'explication, les journaux SQL lents, les anciennes commandes de profil, la nouvelle vue des performances performance_schema et les tableaux associés des informations sur les transactions en cours et l'utilisation de la mémoire dans information_schema, ainsi que les informations de diagnostic sur l'état innodb du moteur. comme certains indicateurs tps, qps et iops dans metrix. (Recommandations associées : "Tutoriel MySQL")
Ci-dessus sont quelques outils préparés pour le réglage, et la base de données fournira de nombreuses fonctions grandes et petites pour une haute disponibilité, les plus importantes sont : la réplication , réplication de groupe, partition, lien de fichier : c'est-à-dire que les journaux de journaux et les fichiers de données peuvent être placés respectivement sur différents disques durs. Les petits incluent : le calcul des colonnes, le calcul du hachage des colonnes, la fusion d'index, le pushdown d'index, MRR, BKA, Loose Index et d'autres algorithmes, ainsi que les facteurs de remplissage, etc.
Bien sûr, il n'y a pas d'index de vue ni de vue partitionnée distribuée, et la jointure ne prend en charge que l'imbrication. C'est un défaut de MySQL. L'algorithme de jointure du serveur SQL prend en charge trois types, la boucle pendant le hachage, ce qui améliore considérablement la vitesse. de rejoindre. MySQL ne propose pas beaucoup de fonctions pour améliorer les performances. D'autres sont basées sur l'expérience, comme les tables statiques. N'utilisez pas de fonctions dans les sous-requêtes. Essayez de transformer les sous-requêtes en requêtes de jointure. Les colonnes sans chaîne et blob sont toujours meilleures que les autres nombres. Ou la colonne de temps est lente. Join |order by|group ne doit pas générer de table temporaire sur le disque dur. Bien sûr, cela est lié à la mémoire, à la conception de tables étroites et de tables larges, etc. type d'entreprise.
Il existe deux façons de démarrer l'optimisation, l'une au moment de l'exécution, c'est-à-dire l'optimisation sur le serveur en cours d'exécution, et l'autre pendant le processus de développement. Peu importe lequel, performance_schema sera nécessaire.
Explication de deux schémas de performances
La vue des performances se trouve dans chaque base de données SQL Server est une série de tables mémoire commençant par dm_*. Mysql représente les différentes tables de la bibliothèque performance_schema Regardons d'abord les tables d'entrée :
SELECT * FROM setup_timers; -- 计时定义表 select * from setup_actors; -- 那些用户需要收集信息 select * from Setup_objects; -- 那些对象需要收集信息,比如mysql表, select * from setup_consumers; -- 那些仪器的分类需要收集 select * from setup_instruments; -- 收集仪器,每一个功能点都会有仪器的事件,开始和结束,然后开启那个仪器,就会收集那个仪器的数据
Tout d'abord, voyons comment. activer le commutateur performance_schema :
show variables like 'performance_schema' -- 这是一个read only变量
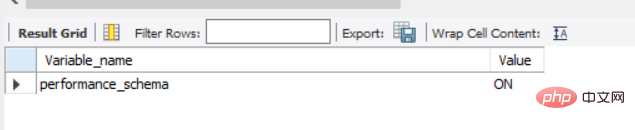
S'il est désactivé, il doit être activé dans le fichier de configuration.
Présentons ensuite ces tableaux d’entrée un par un.
1, table setup_actors
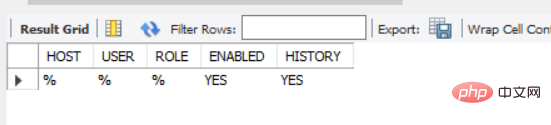
peut être collectée par tous les utilisateurs.
2, Setup_objects
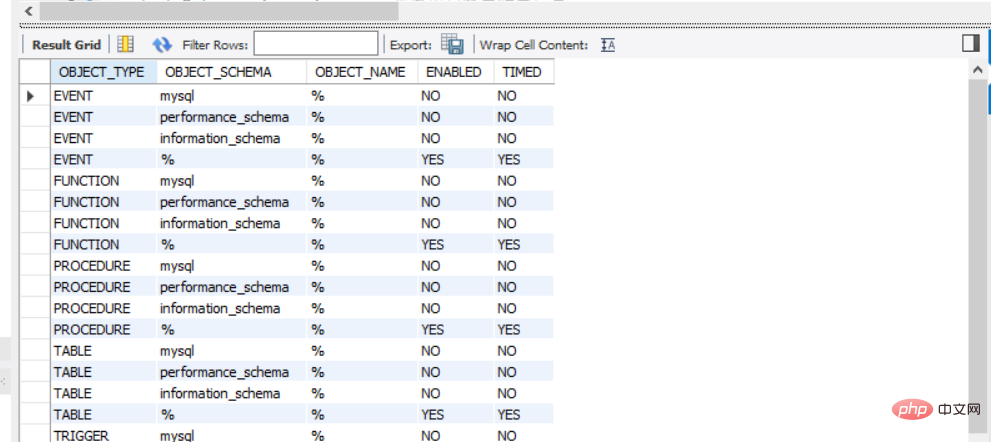
Ces objets peuvent être collectés, qu'il s'agisse de tables ou de déclencheurs, etc. . Quant à la désactivation des deux contrôles de colonnes, les champs activés et temporisés sont définis sur Non, ce qui est le cas pour ces tables.
3 setup_consumers
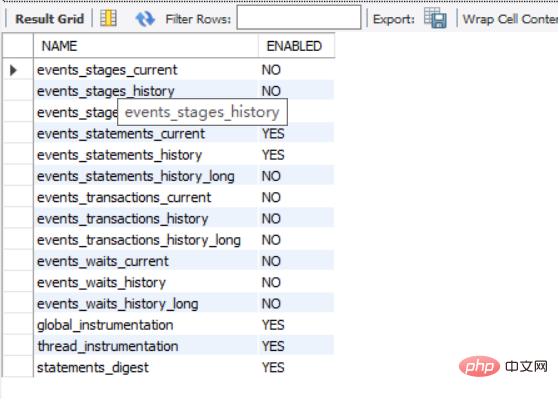
Classification des événements, les étapes sont des étapes, une déclaration dans le serveur Les étapes du processus d'exécution et les résultats sont les mêmes que pour le profil. La méthode de profil n'est pas recommandée car elle sera supprimée ultérieurement. La transaction est la collection d'événements de la transaction, etc.
4 setup_instruments
Il s'agit du principal instrument de surveillance des événements, comme suit :
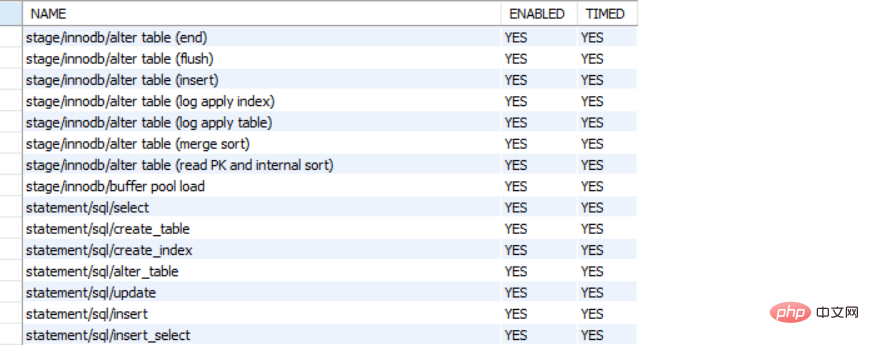
5 Enfin, il y a setup_timers, qui est utilisé avec performance_timers pour définir les types de temps de ces catégories d'instruments, comme suit :
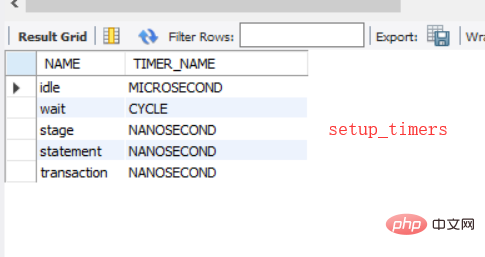
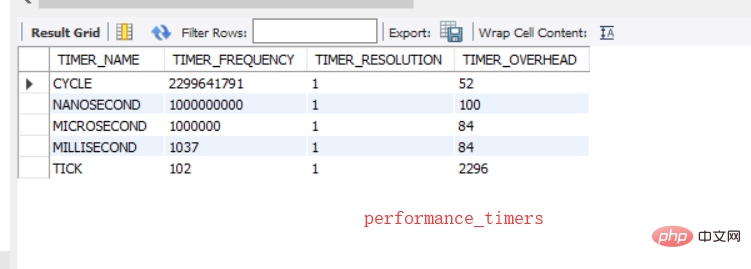
CYCLE : horloge du processeur , TIMER_FREQUENCY est le nombre de secondes, TIMER_RESOLUTION C'est de combien il augmente à chaque fois, et enfin à quelle fréquence il est obtenu.
3 Utilisez performance_schema pour obtenir les données de profil
Ouvrez l'instrument concerné :
Regardons le tableau de classification des instruments ci-dessus Les informations dans setup_consumers et les lignes sur la scène sont toutes NON, nous devons donc les changer en OUI. En même temps, nous devons obtenir les informations dans le tableau de surveillance des déclarations, nous devons donc également le faire. allumer les déclarations :
UPDATE setup_consumers SET ENABLED = 'YES'
WHERE NAME LIKE '%stage%';
UPDATE setup_consumers SET ENABLED = 'YES'
WHERE NAME LIKE '%statements%';Puis allumer l'instrument de scène
UPDATE performance_schema.setup_instruments SET ENABLED = 'YES', TIMED = 'YES'
WHERE NAME LIKE '%stage/%'; -- 开启所有执行步骤的监控
UPDATE performance_schema.setup_instruments SET ENABLED = 'YES', TIMED = 'YES'
WHERE NAME LIKE '%statement/%';L'exécution est basé sur sql
select * from quartz.TestOne
Interrogez l'ID de requête de cette instruction :
SELECT EVENT_ID, TRUNCATE(TIMER_WAIT/1000000000000,6) as Duration, SQL_TEXT
FROM performance_schema.events_statements_history_long WHERE SQL_TEXT like '%quartz%';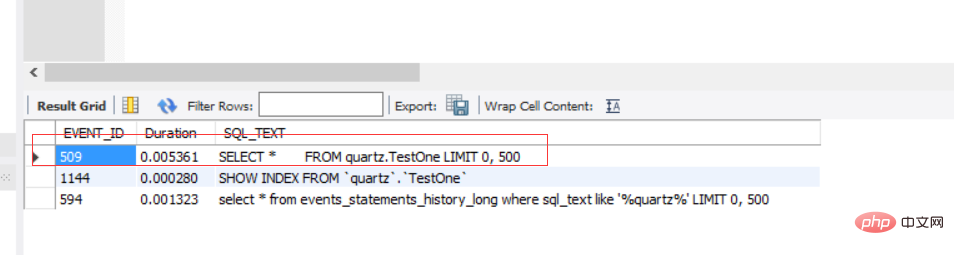
那么id就是509
然后执行性能监控表:
SELECT event_name AS Stage, TRUNCATE(TIMER_WAIT/1000000000000,6) AS Duration
FROM performance_schema.events_stages_history_long WHERE NESTING_EVENT_ID=509 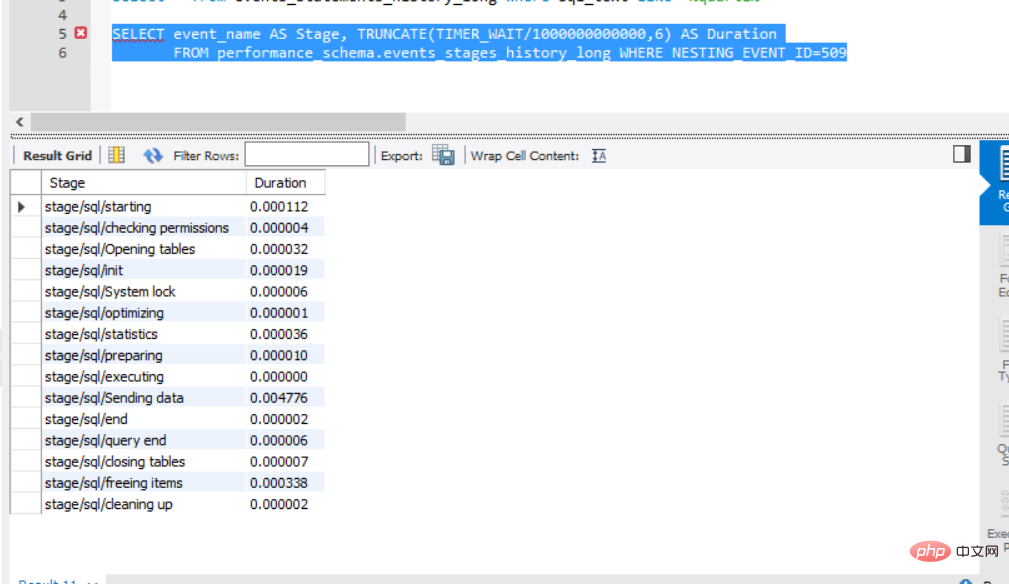
内容和老版本的profile结果一样。
主要看下stage/sql/Sending data这一行,这一行是主要io相关的事件,一般情况下,sql慢了,而这一行数值比较大,那肯定硬盘读数据慢了或者有锁冲突。
那么就是用error log,有死锁,mysql会将死锁信息打入error日志,show engine innodb status只是全局的一些信息,如果要想看详细的再去监控对应的instrument。
而且目前mysql8多支持NOWAIT和skiplocked两个语句,用法还是select.. from 表明 for update/for nowait等,非常灵活的解决了死锁的处理方式,当然你也可以让其事务隔离级别为脏读级别,但是并不能解决更多的业务类型,设置死锁超时也是一个可行的办法。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié









![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



