

Comment étendre Redis
Jun 11, 2019 am 11:02 AMUn camarade de classe de l'équipe a utilisé Redis comme cache dans son projet et a stocké les données de hotspot dans Redis. Afin d'améliorer les performances, la méthode pipeline est utilisée lors de l'écriture de Redis. Lorsqu'elle est utilisée normalement, les performances et l'utilisation des ressources de Redis peuvent répondre aux exigences du projet. Cependant, lorsque le nombre de visites augmente, le QPS de Redis peut toujours répondre aux exigences. , mais l'utilisation du processeur est élevée. Elle a atteint plus de 90 %, généralement seulement 30 %+. Comme nous le savons tous, Redis est un processus unique et ne peut occuper qu'un seul cœur de processeur. Lorsqu'il est plein, il sera à 100 %. Il ne peut pas utiliser le multicœur de la machine. Lorsque le processeur atteint 100 %, cela provoquera inévitablement un goulot d'étranglement en termes de performances. Comment le résoudre ?

Recommandé : "Tutoriel vidéo Redis"
Option 1 :
La première chose qui vient à l'esprit est d'augmenter le nombre de serveurs Redis, d'effectuer des opérations de hachage sur les clés stockées sur le client, et de les stocker sur différents serveurs Redis. Lors de la lecture, la même opération de hachage est également effectuée pour retrouver la clé. serveur Redis correspondant. Résolvez le problème, mais les inconvénients :
Premièrement, le client doit modifier le code
Deuxièmement, le client doit se souvenir des adresses de tous les serveurs Redis ; >
Cette solution peut être utilisée, mais peut-elle être étendue sans changer le code ?Option 2 :
Créer un cluster La version utilisée par le serveur Redis étant inférieure à 3.0, il ne prend pas en charge les clusters. Vous ne pouvez utiliser qu'un proxy. , j'ai donc pensé au célèbre proxy Redis twemproxy. Les performances de twemproxy sont également excellentes. Bien qu'il s'agisse d'un proxy, son impact sur les performances d'accès est très faible. Même l'auteur de Redis le recommande. twemproxy est facile à utiliser. Un novice peut apprendre à l'utiliser en moins d'une heure, et l'essentiel est qu'il n'est pas nécessaire de modifier le code client. Il prend en charge presque toutes les commandes et opérations de pipeline Redis. Il vous suffit de modifier le code client. L'IP et le PORT Redis configurés dans le fichier de configuration passent de l'IP et du port Redis d'origine à l'IP et au PORT du service twemproxy. Le client n'a pas besoin de prendre en compte le problème de hachage, twemproxy le fera, et le client est comme exploiter un Redis. Le mot "presque" est utilisé ci-dessus car certaines commandes, comme "touches *" ne sont pas supportées Nous avons rapidement déployé twemproxy et les quatre machines Redis qui ont suivi, et appuyé sur Le test trouvé que l'utilisation du processeur des quatre unités Redis suivantes a diminué, mais qu'un nouveau problème est apparu, twemproxy est également un processus unique ! Le goulot d'étranglement des performances revient à twemproxy !Option 3 :
L'accès à Redis est divisé en écriture et lecture, similaire aux producteurs et aux consommateurs. Après une analyse minutieuse, il s'avère qu'il y a moins d'écriture et de lecture. relativement moins de lecture. De plus, cela peut séparer la lecture et l'écriture, l'écriture sur le serveur principal et la lecture à partir de la sauvegarde. La situation rencontrée est que la lecture et l'écriture sont deux services. Pour réaliser la séparation de la lecture et de l'écriture, il suffit de modifier la configuration. informations. Cela peut être fait très simplement, dispersant ainsi la pression sur le Redis principal. La pression d'accès sur Redis s'est améliorée ici, mais ce n'est pas une solution à long terme. Par exemple, lorsque des événements ont lieu et que la quantité de données augmente, il y aura toujours des risques de performances. La méthode finale adoptée est le plan global 2 et 3, comme le montre la figure ci-dessous :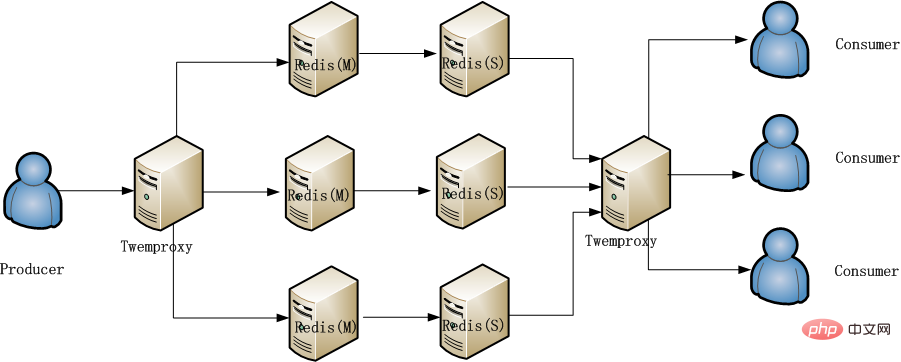
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Article chaud
Outils chauds Tags
Article chaud
Tags d'article chaud

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment mettre en œuvre des stratégies d'invalidation du cache dans Redis?
Mar 17, 2025 pm 06:46 PM
Comment mettre en œuvre des stratégies d'invalidation du cache dans Redis?
Mar 17, 2025 pm 06:46 PM
Comment mettre en œuvre des stratégies d'invalidation du cache dans Redis?
 Existe-t-il un raccourci pour consulter la version redis?
Mar 04, 2025 pm 05:59 PM
Existe-t-il un raccourci pour consulter la version redis?
Mar 04, 2025 pm 05:59 PM
Existe-t-il un raccourci pour consulter la version redis?
 Comment afficher les versions à partir de redis via la ligne de commande
Mar 04, 2025 pm 06:00 PM
Comment afficher les versions à partir de redis via la ligne de commande
Mar 04, 2025 pm 06:00 PM
Comment afficher les versions à partir de redis via la ligne de commande
 Comment est la compatibilité des différentes versions de Redis
Mar 04, 2025 pm 05:57 PM
Comment est la compatibilité des différentes versions de Redis
Mar 04, 2025 pm 05:57 PM
Comment est la compatibilité des différentes versions de Redis
 Comment choisir une clé de fragment dans le cluster redis?
Mar 17, 2025 pm 06:55 PM
Comment choisir une clé de fragment dans le cluster redis?
Mar 17, 2025 pm 06:55 PM
Comment choisir une clé de fragment dans le cluster redis?
 Comment utiliser Redis pour les files d'attente et le traitement des antécédents?
Mar 17, 2025 pm 06:51 PM
Comment utiliser Redis pour les files d'attente et le traitement des antécédents?
Mar 17, 2025 pm 06:51 PM
Comment utiliser Redis pour les files d'attente et le traitement des antécédents?
 Comment surveiller les performances d'un cluster redis?
Mar 17, 2025 pm 06:56 PM
Comment surveiller les performances d'un cluster redis?
Mar 17, 2025 pm 06:56 PM
Comment surveiller les performances d'un cluster redis?
 Comment mettre en œuvre l'authentification et l'autorisation dans Redis?
Mar 17, 2025 pm 06:57 PM
Comment mettre en œuvre l'authentification et l'autorisation dans Redis?
Mar 17, 2025 pm 06:57 PM
Comment mettre en œuvre l'authentification et l'autorisation dans Redis?
