

Algorithme de tri : tri par fusion [avec code]

![Algorithme de tri : tri par fusion [avec code]](https://img.php.cn/upload/article/000/000/040/5d5e5940ba074405.jpg)
Qu'est-ce que le tri par fusion ?
En termes simples, le tri par fusion consiste à intégrer deux séquences ordonnées ensemble.
Tutoriel recommandé : Tutoriel vidéo PHP
Comment combiner deux séquences ordonnées les intégrer ensemble ?
Alors on suppose qu'il y a M={m1,m2,m3,....,mx} séquence et N ={n1,n2,n3,...., ny} séquence, ces deux séquences sont déjà des séquences ordonnées. Créez d'abord une séquence vide K = {}, puis comparez m1 et n1, ajoutez m1 < n1, puis mettez m1 dans la séquence K, puis M Le curseur de séquence recule. , c'est-à-dire que m2 et n1 seront comparés la prochaine fois jusqu'à ce que toutes les comparaisons soient terminées et remplies dans la séquence K.
Puisque le tri par fusion intègre des séquences ordonnées, cela ne signifie-t-il pas que les séquences non ordonnées ne peuvent pas être triées ? Cette condition n'est-elle pas trop sévère ?
Le tri par fusion est basé sur la méthode diviser pour régner, c'est-à-dire qu'une séquence complètement désordonnée peut être divisée sans fil pour obtenir une séquence ordonnée. Par exemple : il y a maintenant M={m1. , m2, m3, ...., mx}, la séquence M est une séquence complètement désordonnée, alors la séquence M peut être divisée en plusieurs petites séquences - {m1, m2}, {m3, m4 }....{ mx-1, mx} ; À ce stade, ces séquences sont dans l'ordre, elles peuvent ensuite être triées via l'opération de fusion, donc le tri par fusion peut également trier les séquences non ordonnées, et sa vitesse est juste derrière le tri rapide, qui appartient à Stable. tri.
Comment diviser une séquence ?
Comme mentionné dans la question précédente, le tri par fusion est basé sur diviser pour régner, et diviser pour régner se reflète dans la séquence de division. Par exemple : il y a maintenant M = {m1, m2, m3, ...., mx}, la première division : M1 = {m1, m2, ..., m(x+1)/2}, M2 = {m(x+1 )/2 +1 , m(x+1)/2 +2,...,mx}, après la première division, les séquences M1 et M2 sont obtenues, puis les M1 et M2 sont divisés, et après plusieurs divisions, x/2 est obtenu + x%2 séquences, puis fusionnez-les une par une.
Les étapes spécifiques de cet algorithme :
1. Spécifiez les premiers pointeurs gauche et milieu (la gauche pointe vers le premier élément de la séquence 1 , la droite pointe vers la séquence 2 (le premier élément)
2. Comparez les tailles de gauche et du milieu et placez les petits éléments dans le nouvel espace
3. Répétez l'étape 2 jusqu'à ce que l'un des les séquences ont été parcourues
4. Copiez et collez les éléments restants qui n'ont pas été ajoutés au nouvel espace directement dans le nouvel espace
Les étapes principales de l'algorithme :
1. Utilisez la méthode diviser pour régner (récursion) pour diviser la séquence
2. Comparez les tailles de gauche et de milieu et ajoutez de petits éléments dans le nouveau espace
indique Terminé, collez le code :
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace 排序__归并排序
{
class 归并
{
public static int[] arr = { 6, 202, 301, 100, 38, 8, 1 ,-1,1000};
static void Main(string[] args)
{
Sort(arr, 0, arr.Length -1);
foreach (var item in arr)
{
Console.Write(item + " ");
}
Console.ReadKey();
}
public static void Sort(int []a,int left,int right)
{
if (left >= right) return;
else
{
int mid = (left + right) / 2; //@1
Sort(a, left, mid);
Sort(a, mid + 1, right);
MergeSort(a, left, mid, right);
}
}
public static void MergeSort(int []a,int left,int mid,int right)
{
int[] Arr = new int[right - left + 1];
int l = left, m = mid +1 , k = 0; //@2
while ( m <= right && l <= mid ) //@3
{
if (a[l] > a[m]) Arr[k++] = a[m++];
else Arr[k++] = a[l++];
}
while (m < right +1) //@4
{
Arr[k++] = a[m++];
}
while (l < mid +1 ) Arr[k++] = a[l++]; //@4
for (k = 0, l = left; l < right + 1; k++, l++) a[l] = Arr[k];
}
}
}Interprétation du code :
@1 : La fonction Sort() termine la segmentation de la séquence. Chaque récursion divise la séquence en deux moitiés jusqu'à ce qu'elle soit divisée en deux. ne peut pas être séparé.
@2 : l représente le premier élément de la séquence 1, m représente le premier élément de la séquence 2, k représente le nombre d'éléments existants dans le nouveau tableau Arr
@3 : le premier élément de la séquence 1 Comparez avec le premier élément de la séquence 2, mettez le petit dans Arr et déplacez le curseur de la séquence vers l'arrière jusqu'à ce que les éléments de l'une des séquences soient comparés
@4 : Le processus de comparaison entre la séquence 1 et la séquence 2, il peut sembler que la séquence 1 a toutes été ajoutées à Arr, mais pas la séquence 2, alors les éléments non comparés restants seront copiés directement dans Arr
Résumé :
Le code ci-dessus ne divise pas le tableau au vrai sens du terme. Il effectue simplement une division logique. Il ne remplit pas le tableau divisé dans un nouveau tableau comme les autres codes. Cela aura un léger impact sur la vitesse et la mémoire. Bien que ce soit minime, ce n'est pas si bon après tout. Dans l'opération de fusion, vous devez faire attention aux paramètres qui ne franchissent pas la limite (j'ai longtemps réfléchi à la raison pour laquelle le m au-dessus de @2 devrait être égal à mi +1. au lieu de mid En fait, la raison est très simple Parce que mid appartient à la séquence de gauche, il n'appartient qu'à la séquence de droite à partir de mid+1. Changer m = mid +1 en m = mid n'est pas impossible, mais le. le code suivant doit également être modifié, mais il n'est pas nécessaire de faire une autre comparaison inutile. Ce problème, j'y ai vraiment réfléchi pendant longtemps...), en fait, tant que la relation logique est clarifiée, le code peut être facilement saisi.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Problèmes complexes de conception expérimentale sur le marché biface de Kuaishou
Apr 15, 2023 pm 07:40 PM
Problèmes complexes de conception expérimentale sur le marché biface de Kuaishou
Apr 15, 2023 pm 07:40 PM
1. Contexte du problème 1. Introduction à l'expérience du marché biface Le marché biface, c'est-à-dire une plateforme, comprend deux participants, producteurs et consommateurs, et les deux parties se promeuvent mutuellement. Par exemple, Kuaishou a un producteur vidéo et un consommateur vidéo, et les deux identités peuvent se chevaucher dans une certaine mesure. L'expérimentation bilatérale est une méthode expérimentale qui combine des groupes du côté des producteurs et des consommateurs. Les expériences bilatérales présentent les avantages suivants : (1) L'impact de la nouvelle stratégie sur deux aspects peut être détecté simultanément, tels que les changements dans le DAU du produit et le nombre de personnes téléchargeant des œuvres. Les plateformes bilatérales ont souvent des effets de réseau transversaux. Plus il y a de lecteurs, plus les auteurs seront actifs, et plus les auteurs seront actifs, plus les lecteurs suivront. (2) Le débordement et le transfert d'effet peuvent être détectés. (3) Aidez-nous à mieux comprendre le mécanisme d'action. L'expérience AB elle-même ne peut pas nous dire la relation entre la cause et l'effet, seulement.
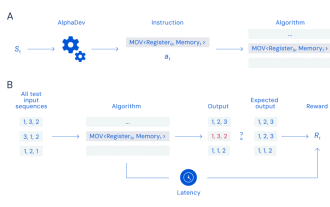 Google utilise l'IA pour briser le sceau de dix ans de l'algorithme de tri. Elle est exécutée des milliards de fois chaque jour, mais les internautes disent que c'est la recherche la plus irréaliste ?
Jun 22, 2023 pm 09:18 PM
Google utilise l'IA pour briser le sceau de dix ans de l'algorithme de tri. Elle est exécutée des milliards de fois chaque jour, mais les internautes disent que c'est la recherche la plus irréaliste ?
Jun 22, 2023 pm 09:18 PM
Tri | Nuka-Cola, Chu Xingjuan Les amis qui ont suivi des cours d'informatique de base doivent avoir personnellement conçu un algorithme de tri, c'est-à-dire utiliser du code pour réorganiser les éléments d'une liste non ordonnée par ordre croissant ou décroissant. C'est un défi intéressant, et il existe de nombreuses façons possibles de le relever. Beaucoup de temps a été investi pour trouver comment accomplir les tâches de tri plus efficacement. En tant qu'opération de base, les algorithmes de tri sont intégrés aux bibliothèques standard de la plupart des langages de programmation. Il existe de nombreuses techniques et algorithmes de tri différents utilisés dans les bases de code du monde entier pour organiser de grandes quantités de données en ligne, mais au moins en ce qui concerne les bibliothèques C++ utilisées avec le compilateur LLVM, le code de tri n'a pas changé depuis plus d'une décennie. . Récemment, l'équipe Google DeepMindAI a développé un
 Comment filtrer et trier les données dans le développement de la technologie Vue
Oct 09, 2023 pm 01:25 PM
Comment filtrer et trier les données dans le développement de la technologie Vue
Oct 09, 2023 pm 01:25 PM
Comment filtrer et trier les données dans le développement de la technologie Vue Dans le développement de la technologie Vue, le filtrage et le tri des données sont des fonctions très courantes et importantes. Grâce au filtrage et au tri des données, nous pouvons rapidement interroger et afficher les informations dont nous avons besoin, améliorant ainsi l'expérience utilisateur. Cet article expliquera comment filtrer et trier les données dans Vue et fournira des exemples de code spécifiques pour aider les lecteurs à mieux comprendre et utiliser ces fonctions. 1. Filtrage des données Le filtrage des données fait référence au filtrage des données qui répondent aux exigences en fonction de conditions spécifiques. Dans Vue, on peut passer comp
 Comment implémenter l'algorithme de tri par sélection en C#
Sep 20, 2023 pm 01:33 PM
Comment implémenter l'algorithme de tri par sélection en C#
Sep 20, 2023 pm 01:33 PM
Comment implémenter l'algorithme de tri par sélection en C# Le tri par sélection (SelectionSort) est un algorithme de tri simple et intuitif. Son idée de base est de sélectionner à chaque fois l'élément le plus petit (ou le plus grand) parmi les éléments à trier et de le placer à la fin de. la séquence triée. Répétez ce processus jusqu'à ce que tous les éléments soient triés. Apprenons-en davantage sur la façon d'implémenter l'algorithme de tri par sélection en C#, ainsi que des exemples de code spécifiques. Création d'une méthode de tri par sélection Tout d'abord, nous devons créer une méthode pour implémenter le tri par sélection. Cette méthode accepte un
 Quels sont les algorithmes de tri des tableaux ?
Jun 02, 2024 pm 10:33 PM
Quels sont les algorithmes de tri des tableaux ?
Jun 02, 2024 pm 10:33 PM
Les algorithmes de tri de tableaux sont utilisés pour organiser les éléments dans un ordre spécifique. Les types courants d'algorithmes incluent : Tri à bulles : échangez les positions en comparant les éléments adjacents. Tri par sélection : recherchez le plus petit élément et remplacez-le par la position actuelle. Tri par insertion : insérez les éléments un par un à la bonne position. Tri rapide : méthode diviser pour mieux régner, sélectionnez l'élément pivot pour diviser le tableau. Tri par fusion : diviser pour mieux régner, tri récursif et fusion de sous-tableaux.
 Swoole Advanced : Comment utiliser le multithreading pour implémenter un algorithme de tri à grande vitesse
Jun 14, 2023 pm 09:16 PM
Swoole Advanced : Comment utiliser le multithreading pour implémenter un algorithme de tri à grande vitesse
Jun 14, 2023 pm 09:16 PM
Swoole est un framework de communication réseau hautes performances basé sur le langage PHP. Il prend en charge la mise en œuvre de plusieurs modes IO asynchrones et de plusieurs protocoles réseau avancés. Sur la base de Swoole, nous pouvons utiliser sa fonction multi-threading pour implémenter des opérations algorithmiques efficaces, telles que des algorithmes de tri à grande vitesse. L'algorithme de tri à grande vitesse (QuickSort) est un algorithme de tri courant. En localisant un élément de référence, les éléments sont divisés en deux sous-séquences. Celles plus petites que l'élément de référence sont placées à gauche et celles supérieures ou égales à la référence. L'élément est placé à droite. Ensuite, les sous-séquences gauche et droite sont placées par récursion.
 Comment utiliser l'algorithme de tri par base en C++
Sep 19, 2023 pm 12:15 PM
Comment utiliser l'algorithme de tri par base en C++
Sep 19, 2023 pm 12:15 PM
Comment utiliser l'algorithme de tri par base en C++ L'algorithme de tri par base est un algorithme de tri non comparatif qui termine le tri en divisant les éléments à trier en un ensemble limité de chiffres. En C++, nous pouvons utiliser l’algorithme de tri par base pour trier un ensemble d’entiers. Ci-dessous, nous verrons en détail comment implémenter l'algorithme de tri par base, avec des exemples de code spécifiques. Idée d'algorithme L'idée de l'algorithme de tri par base est de diviser les éléments à trier en un ensemble limité de bits numériques, puis de trier les éléments sur chaque bit tour à tour. Le tri sur chaque bit est terminé
 Comment implémenter une fonction d'algorithme de tri simple à l'aide de MySQL et Java
Sep 20, 2023 am 09:45 AM
Comment implémenter une fonction d'algorithme de tri simple à l'aide de MySQL et Java
Sep 20, 2023 am 09:45 AM
Comment utiliser MySQL et Java pour implémenter une fonction d'algorithme de tri simple Introduction : Dans le développement de logiciels, les algorithmes de tri sont l'une des fonctions les plus basiques et les plus couramment utilisées. Cet article expliquera comment utiliser MySQL et Java pour implémenter une fonction d'algorithme de tri simple et fournira des exemples de code spécifiques. 1. Présentation des algorithmes de tri Les algorithmes de tri sont des algorithmes qui organisent un ensemble de données selon des règles spécifiques. Les algorithmes de tri couramment utilisés incluent le tri à bulles, le tri par insertion, le tri par sélection, le tri rapide, etc. Cet article utilisera le tri à bulles comme exemple pour l'expliquer et le mettre en œuvre. 2.M
