

Photoshop利用图层样式绘制电影中逼真的3D机器人EVA

本文小编姜维大家带来如何使用Photoshop绘制电影中的3D机器人EVA,教程有些复杂,喜欢的朋友可以一起来学习
实现目标的方法有很多种,但掌握原理什么的最重要了。因为只要掌握了原理,我们甚至就可以画出更为复杂的效果。
最终效果
EVA的故事与模型设定:
1、EVA的基本形状是一个蛋形的,也就是一个椭圆围绕其长直径旋转一周得到的立体圆形。
2、EVA变形(容我这么形容)之后,分成4部分,头部,身体,和两手臂。
3、根据原著,EVA的材质可以设定为白色陶瓷。
绘制过程:
1、拆解。
2、头部绘制:
新建1024 * 1024,分辨率为72的画布,如下图。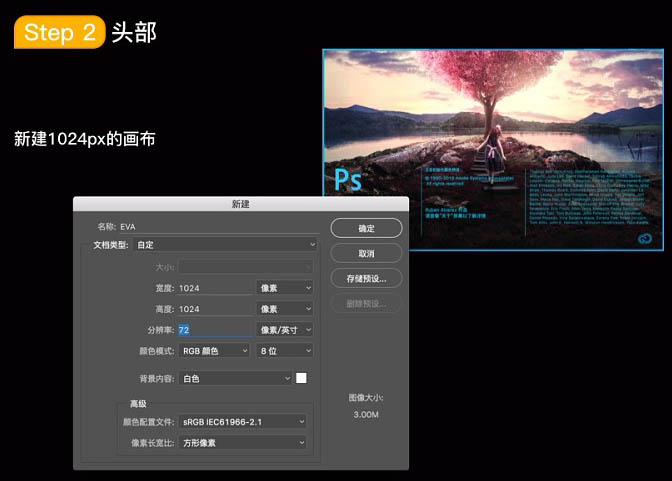
通过调节椭圆形状得到头部轮廓,通过调节内发光与渐变叠加得到头部基础。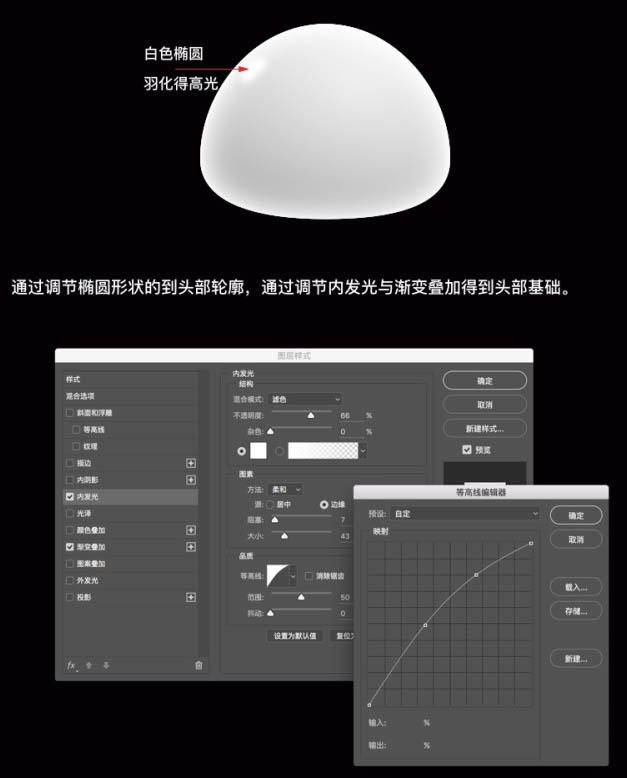
通过调节锚点让椭圆变形,并羽化,得到高光。
同理,通过高光,反射光,以及布尔运算,调节锚点等得到脸部底色及眼睛。
面罩上的黑白条纹可用定义图案功能实现,具体过程如下:

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1359
1359
 52
52

 Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Écrit ci-dessus et compréhension personnelle de l'auteur Le Gaussiansplatting tridimensionnel (3DGS) est une technologie transformatrice qui a émergé dans les domaines des champs de rayonnement explicites et de l'infographie ces dernières années. Cette méthode innovante se caractérise par l’utilisation de millions de gaussiennes 3D, ce qui est très différent de la méthode du champ de rayonnement neuronal (NeRF), qui utilise principalement un modèle implicite basé sur les coordonnées pour mapper les coordonnées spatiales aux valeurs des pixels. Avec sa représentation explicite de scènes et ses algorithmes de rendu différenciables, 3DGS garantit non seulement des capacités de rendu en temps réel, mais introduit également un niveau de contrôle et d'édition de scène sans précédent. Cela positionne 3DGS comme un révolutionnaire potentiel pour la reconstruction et la représentation 3D de nouvelle génération. À cette fin, nous fournissons pour la première fois un aperçu systématique des derniers développements et préoccupations dans le domaine du 3DGS.
 CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : À l'heure actuelle, dans l'ensemble du système de conduite autonome, le module de perception joue un rôle essentiel. Le véhicule autonome roulant sur la route ne peut obtenir des résultats de perception précis que via le module de perception en aval. dans le système de conduite autonome, prend des jugements et des décisions comportementales opportuns et corrects. Actuellement, les voitures dotées de fonctions de conduite autonome sont généralement équipées d'une variété de capteurs d'informations de données, notamment des capteurs de caméra à vision panoramique, des capteurs lidar et des capteurs radar à ondes millimétriques pour collecter des informations selon différentes modalités afin d'accomplir des tâches de perception précises. L'algorithme de perception BEV basé sur la vision pure est privilégié par l'industrie en raison de son faible coût matériel et de sa facilité de déploiement, et ses résultats peuvent être facilement appliqués à diverses tâches en aval.
 Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
0. Écrit à l'avant&& Compréhension personnelle que les systèmes de conduite autonome s'appuient sur des technologies avancées de perception, de prise de décision et de contrôle, en utilisant divers capteurs (tels que caméras, lidar, radar, etc.) pour percevoir l'environnement et en utilisant des algorithmes et des modèles pour une analyse et une prise de décision en temps réel. Cela permet aux véhicules de reconnaître les panneaux de signalisation, de détecter et de suivre d'autres véhicules, de prédire le comportement des piétons, etc., permettant ainsi de fonctionner en toute sécurité et de s'adapter à des environnements de circulation complexes. Cette technologie attire actuellement une grande attention et est considérée comme un domaine de développement important pour l'avenir des transports. . un. Mais ce qui rend la conduite autonome difficile, c'est de trouver comment faire comprendre à la voiture ce qui se passe autour d'elle. Cela nécessite que l'algorithme de détection d'objets tridimensionnels du système de conduite autonome puisse percevoir et décrire avec précision les objets dans l'environnement, y compris leur emplacement,
 L'Ameca deuxième génération est là ! Il peut communiquer couramment avec le public, ses expressions faciales sont plus réalistes et il peut parler des dizaines de langues.
Mar 04, 2024 am 09:10 AM
L'Ameca deuxième génération est là ! Il peut communiquer couramment avec le public, ses expressions faciales sont plus réalistes et il peut parler des dizaines de langues.
Mar 04, 2024 am 09:10 AM
Le robot humanoïde Ameca est passé à la deuxième génération ! Récemment, lors de la Conférence mondiale sur les communications mobiles MWC2024, le robot le plus avancé au monde, Ameca, est à nouveau apparu. Autour du site, Ameca a attiré un grand nombre de spectateurs. Avec la bénédiction de GPT-4, Ameca peut répondre à divers problèmes en temps réel. "Allons danser." Lorsqu'on lui a demandé si elle avait des émotions, Ameca a répondu avec une série d'expressions faciales très réalistes. Il y a quelques jours à peine, EngineeredArts, la société britannique de robotique derrière Ameca, vient de présenter les derniers résultats de développement de l'équipe. Dans la vidéo, le robot Ameca a des capacités visuelles et peut voir et décrire toute la pièce et des objets spécifiques. Le plus étonnant, c'est qu'elle peut aussi
 Comment l'IA peut-elle rendre les robots plus autonomes et adaptables ?
Jun 03, 2024 pm 07:18 PM
Comment l'IA peut-elle rendre les robots plus autonomes et adaptables ?
Jun 03, 2024 pm 07:18 PM
Dans le domaine de la technologie de l’automatisation industrielle, il existe deux points chauds récents qu’il est difficile d’ignorer : l’intelligence artificielle (IA) et Nvidia. Ne changez pas le sens du contenu original, affinez le contenu, réécrivez le contenu, ne continuez pas : « Non seulement cela, les deux sont étroitement liés, car Nvidia ne se limite pas à son unité de traitement graphique d'origine (GPU ), il étend son GPU. La technologie s'étend au domaine des jumeaux numériques et est étroitement liée aux technologies émergentes d'IA "Récemment, NVIDIA a conclu une coopération avec de nombreuses entreprises industrielles, notamment des sociétés d'automatisation industrielle de premier plan telles qu'Aveva, Rockwell Automation, Siemens. et Schneider Electric, ainsi que Teradyne Robotics et ses sociétés MiR et Universal Robots. Récemment, Nvidiahascoll
 Le premier robot capable d'accomplir de manière autonome des tâches humaines apparaît, avec cinq doigts flexibles et rapides, et de grands modèles prennent en charge l'entraînement dans l'espace virtuel
Mar 11, 2024 pm 12:10 PM
Le premier robot capable d'accomplir de manière autonome des tâches humaines apparaît, avec cinq doigts flexibles et rapides, et de grands modèles prennent en charge l'entraînement dans l'espace virtuel
Mar 11, 2024 pm 12:10 PM
Cette semaine, FigureAI, une entreprise de robotique investie par OpenAI, Microsoft, Bezos et Nvidia, a annoncé avoir reçu près de 700 millions de dollars de financement et prévoit de développer un robot humanoïde capable de marcher de manière autonome au cours de la prochaine année. Et l’Optimus Prime de Tesla a reçu à plusieurs reprises de bonnes nouvelles. Personne ne doute que cette année sera celle de l’explosion des robots humanoïdes. SanctuaryAI, une entreprise canadienne de robotique, a récemment lancé un nouveau robot humanoïde, Phoenix. Les responsables affirment qu’il peut accomplir de nombreuses tâches de manière autonome, à la même vitesse que les humains. Pheonix, le premier robot au monde capable d'accomplir des tâches de manière autonome à la vitesse d'un humain, peut saisir, déplacer et placer avec élégance chaque objet sur ses côtés gauche et droit. Il peut identifier des objets de manière autonome
 Après 2 mois, le robot humanoïde Walker S peut plier les vêtements
Apr 03, 2024 am 08:01 AM
Après 2 mois, le robot humanoïde Walker S peut plier les vêtements
Apr 03, 2024 am 08:01 AM
Rédacteur en chef du Machine Power Report : Wu Xin La version domestique de l'équipe robot humanoïde + grand modèle a accompli pour la première fois la tâche d'exploitation de matériaux flexibles complexes tels que le pliage de vêtements. Avec le dévoilement de Figure01, qui intègre le grand modèle multimodal d'OpenAI, les progrès connexes des pairs nationaux ont attiré l'attention. Hier encore, UBTECH, le « stock numéro un de robots humanoïdes » en Chine, a publié la première démo du robot humanoïde WalkerS, profondément intégré au grand modèle de Baidu Wenxin, présentant de nouvelles fonctionnalités intéressantes. Maintenant, WalkerS, bénéficiant des capacités de grands modèles de Baidu Wenxin, ressemble à ceci. Comme la figure 01, WalkerS ne se déplace pas, mais se tient derrière un bureau pour accomplir une série de tâches. Il peut suivre les commandes humaines et plier les vêtements
 Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Lien du projet écrit devant : https://nianticlabs.github.io/mickey/ Étant donné deux images, la pose de la caméra entre elles peut être estimée en établissant la correspondance entre les images. En règle générale, ces correspondances sont 2D à 2D et nos poses estimées sont à échelle indéterminée. Certaines applications, telles que la réalité augmentée instantanée, à tout moment et en tout lieu, nécessitent une estimation de pose des métriques d'échelle, elles s'appuient donc sur des estimateurs de profondeur externes pour récupérer l'échelle. Cet article propose MicKey, un processus de correspondance de points clés capable de prédire les correspondances métriques dans l'espace d'une caméra 3D. En apprenant la correspondance des coordonnées 3D entre les images, nous sommes en mesure de déduire des métriques relatives.
