


Jugez le problème SQL
Lorsque vous jugez s'il y a un problème avec SQL, vous pouvez juger à travers deux apparitions :
, vous pouvez utiliser la commande sar et la commande top pour afficher l'état actuel du système.

Vous pouvez également observer l'état du système grâce à des outils de surveillance tels que Prometheus、Grafana.
Le SQL long est facile à comprendre. Si un SQL est trop long, la lisibilité. sera certainement médiocre et des problèmes surviendront. La fréquence sera certainement plus élevée. Pour déterminer davantage le problème SQL, nous devons commencer par le plan d'exécution, comme indiqué ci-dessous :

Le plan d'exécution nous indique que cette requête a subi une analyse complète de la tableType=ALL, et les lignes sont très grandes (9950400). On peut essentiellement juger qu'il s'agit d'un SQL "savoureux".
Obtention du problème SQL
Différentes bases de données ont différentes méthodes d'acquisition. Ce qui suit est l'outil d'acquisition SQL de requêtes lentes pour les bases de données grand public actuelles
Compétences en écriture SQL
Il existe plusieurs compétences communes en écriture SQL :
• Utilisation raisonnable des index
Avec moins d'index, les requêtes sont plus lentes, trop d'index prennent beaucoup de place lors de l'exécution des ajouts, suppressions et modifications, l'index a besoin ; à maintenir dynamiquement, ce qui affecte les performances
Taux de sélection élevé (moins de valeurs en double) Et il est fréquemment référencé par l'endroit où les index B-tree doivent être établis ; les colonnes de jointure générales doivent être indexées davantage ; efficace avec les index de texte intégral ; l'établissement des index doit trouver un équilibre entre les performances des requêtes et du DML ; lors de la création d'index composites, il convient de prêter attention à la base de la requête dans le cas d'une requête de colonne non principale
• Utilisez UNION ALL au lieu de UNION
.UNION ALL a une efficacité d'exécution supérieure à UNION qui doit être dédupliquée lors de l'exécution ; UNION doit réduire la pondération des données
• Évitez d'écrire * en sélection
Lors de l'exécution de SQL, l'optimiseur doit convertir * en colonnes spécifiques ; chaque requête doit renvoyer à la table et l'écrasement d'index n'est pas autorisé.
• Il est recommandé de créer un index pour les champs JOIN
Généralement, les champs JOIN sont indexés à l'avance
• Évitez le SQL complexe déclarations
Améliorer la lisibilité ; éviter la probabilité de requêtes lentes ; peuvent être converties en plusieurs requêtes courtes et traitées par l'entreprise
• Éviter l'écriture où 1=1
• Évitez l'écriture similaire de order by rand()
RAND() provoquant l'analyse de la colonne de données plusieurs fois
Optimisation SQL Plan d'exécution
Assurez-vous de lire le plan d'exécution avant de terminer l'optimisation SQL. Le plan d'exécution vous indiquera où l'efficacité est faible et où une optimisation est nécessaire. Prenons MYSQL comme exemple pour voir quel est le plan d'exécution. (Le plan d'exécution de chaque base de données est différent, vous devez le comprendre vous-même)

| 字段 | 解释 |
|---|---|
| id | 每个被独立执行的操作标识,标识对象被操作的顺序,id值越大,先被执行,如果相同,执行顺序从上到下 |
| select_type | 查询中每个select 字句的类型 |
| table | 被操作的对象名称,通常是表名,但有其他格式 |
| partitions | 匹配的分区信息(对于非分区表值为NULL) |
| type | 连接操作的类型 |
| possible_keys | 可能用到的索引 |
| key | 优化器实际使用的索引(最重要的列) 从最好到最差的连接类型为const、eq_reg、ref、range、index和ALL。当出现ALL时表示当前SQL出现了“坏味道” |
| key_len | 被优化器选定的索引键长度,单位是字节 |
| ref | 表示本行被操作对象的参照对象,无参照对象为NULL |
| rows | 查询执行所扫描的元组个数(对于innodb,此值为估计值) |
| filtered | 条件表上数据被过滤的元组个数百分比 |
| extra | 执行计划的重要补充信息,当此列出现Using Optimisation des instructions SQL de la base de données MySQLsort , Using temporary 字样时就要小心了,很可能SQL语句需要优化 |
Ensuite, nous utilisons un cas d'optimisation pratique pour illustrer le processus d'optimisation SQL et les techniques d'optimisation.
Cas d'optimisation
Structure des tables
CREATE TABLE `a` ( `id` int(11) NOT NULLAUTO_INCREMENT, `seller_id` bigint(20) DEFAULT NULL, `seller_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL, `gmt_create` varchar(30) DEFAULT NULL, PRIMARY KEY (`id`) ); CREATE TABLE `b` ( `id` int(11) NOT NULLAUTO_INCREMENT, `seller_name` varchar(100) DEFAULT NULL, `user_id` varchar(50) DEFAULT NULL, `user_name` varchar(100) DEFAULT NULL, `sales` bigint(20) DEFAULT NULL, `gmt_create` varchar(30) DEFAULT NULL, PRIMARY KEY (`id`) ); CREATE TABLE `c` ( `id` int(11) NOT NULLAUTO_INCREMENT, `user_id` varchar(50) DEFAULT NULL, `order_id` varchar(100) DEFAULT NULL, `state` bigint(20) DEFAULT NULL, `gmt_create` varchar(30) DEFAULT NULL, PRIMARY KEY (`id`) );
Association à trois tables , interrogez l'état de la commande de l'utilisateur actuel 10 heures avant et après l'heure actuelle, et triez-les par ordre croissant en fonction de l'heure de création de la commande. Le SQL spécifique est le suivant
select a.seller_id, a.seller_name, b.user_name, c.state from a, b, c where a.seller_name = b.seller_name and b.user_id = c.user_id and c.user_id = 17 and a.gmt_create BETWEEN DATE_ADD(NOW(), INTERVAL – 600 MINUTE) AND DATE_ADD(NOW(), INTERVAL 600 MINUTE) order by a.gmt_create
Afficher le volume de données
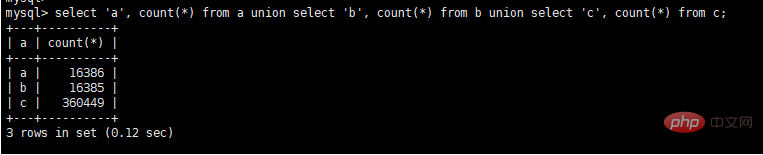
Durée d'exécution d'origine
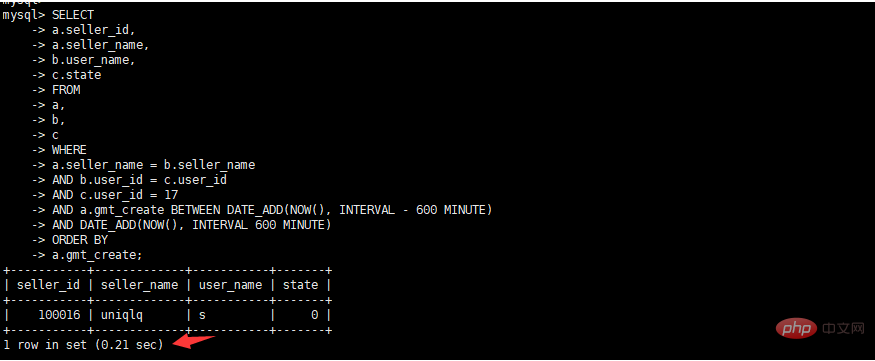
Plan d'exécution original
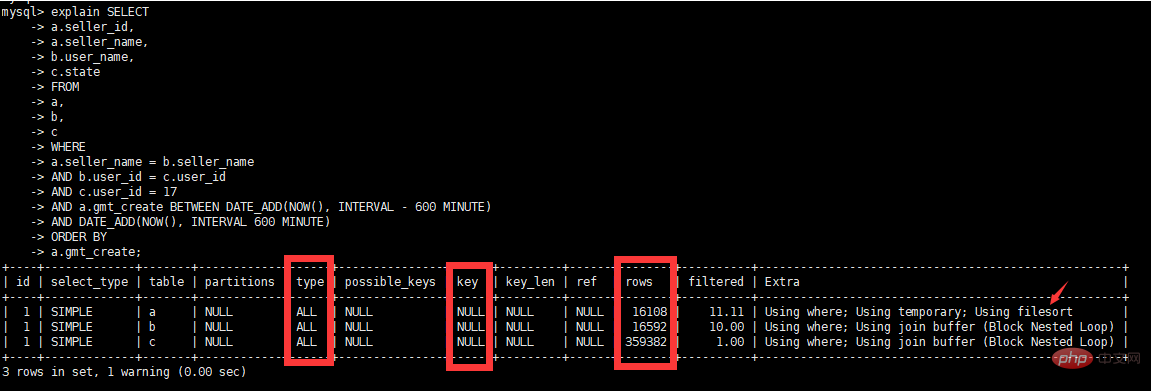
Idées d'optimisation initiales
Le type du champ de condition Where en SQL doit être cohérent avec la structure de la table. La table user_id C'est un type varchar(50) Le type int réel utilisé dans SQL a une conversion implicite et aucun index n'est ajouté. Remplacez les champs user_id des tables b et c par le type int.
Parce que la table b et la table c existent, créez un index sur la table b et la table c user_id
Parce que la table a et la table b exister Association, créer des index sur les seller_name champs des tables a et b
Utiliser des index composites pour éliminer les tables temporaires et le tri
Initial optimisation de SQL
alter table b modify `user_id` int(10) DEFAULT NULL; alter table c modify `user_id` int(10) DEFAULT NULL; alter table c add index `idx_user_id`(`user_id`); alter table b add index `idx_user_id_sell_name`(`user_id`,`seller_name`); alter table a add index `idx_sellname_gmt_sellid`(`gmt_create`,`seller_name`,`seller_id`);
Afficher le temps d'exécution après optimisation
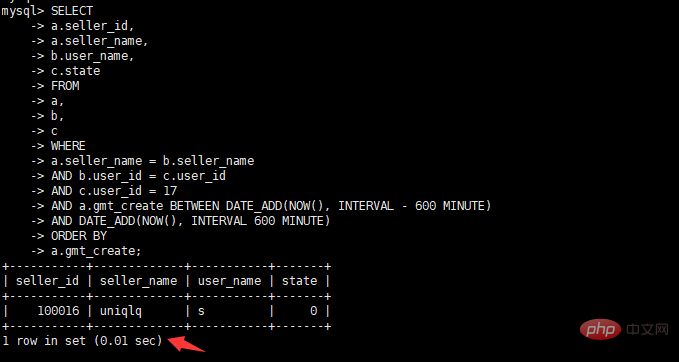
Afficher le temps d'exécution après le plan d'optimisation
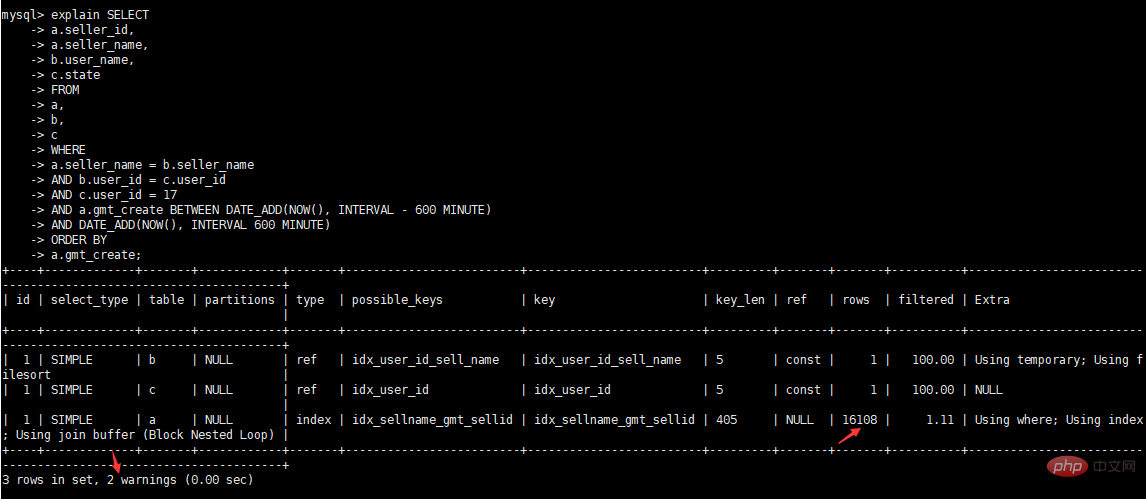
Afficher les informations sur les avertissements
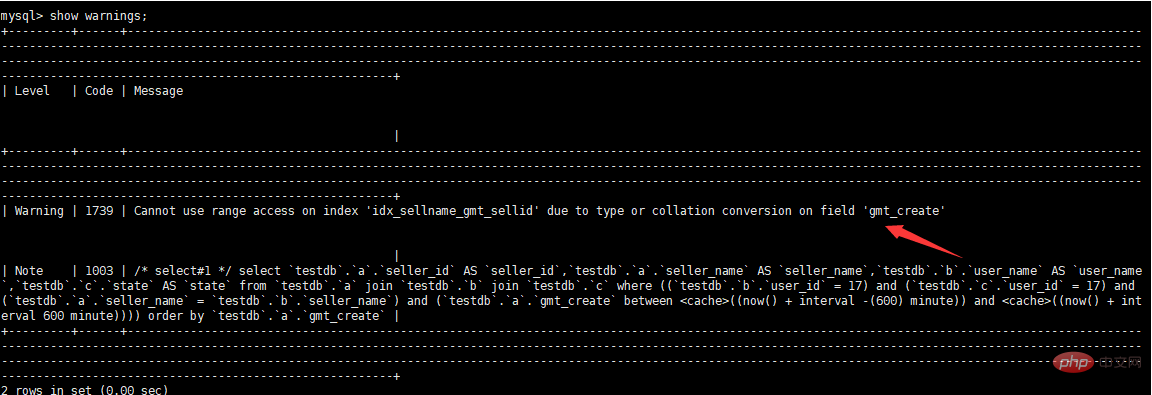
Continuer à optimiser
alter table a modify "gmt_create" datetime DEFAULT NULL
Afficher le temps d'exécution
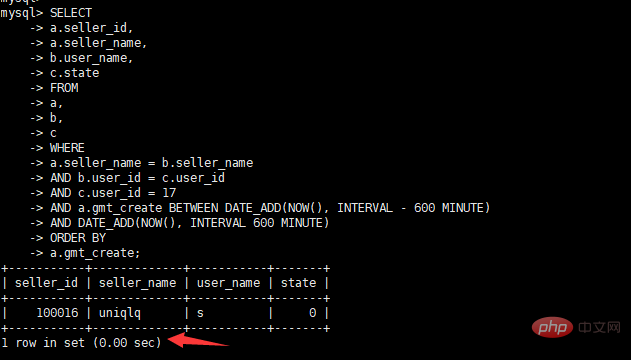
Afficher le plan d'exécution
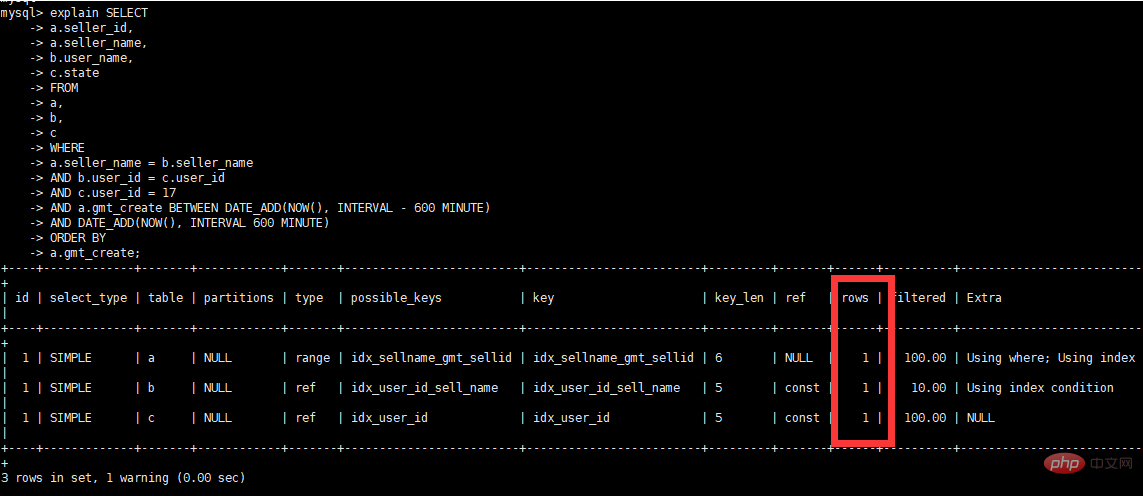
Résumé de l'optimisation
Si l'effet d'optimisation n'est pas évident, répétez la quatrième étape
Recommandez le "tutoriel vidéo mysql"
.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



