


1. Utilisation de base des interfaces
L'interface elle-même en golang est aussi un type, elle représente une collection. de méthodes. Tant que n'importe quel type implémente toutes les méthodes déclarées dans l'interface, alors la classe implémente l'interface. Contrairement à d'autres langages, Golang n'a pas besoin de déclarer explicitement qu'un type implémente une interface, mais est vérifié par le compilateur et le runtime.
Déclaration
type 接口名 interface{
方法1
方法2
...
方法n
}
type 接口名 interface {
已声明接口名1
...
已声明接口名n
}
type iface interface{
tab *itab
data unsafe.Pointer
}L'interface elle-même est également un type structurel, mais le compilateur lui impose de nombreuses restrictions :
● Il ne peut pas y avoir de champs
● Vous ne pouvez pas définir vos propres méthodes
● Vous pouvez uniquement déclarer des méthodes, pas les implémenter
● Vous pouvez intégrer d'autres types d'interface
package main
import (
"fmt"
)
// 定义一个接口
type People interface {
ReturnName() string
}
// 定义一个结构体
type Student struct {
Name string
}
// 定义结构体的一个方法。
// 突然发现这个方法同接口People的所有方法(就一个),此时可直接认为结构体Student实现了接口People
func (s Student) ReturnName() string {
return s.Name
}
func main() {
cbs := Student{Name:"小明"}
var a People
// 因为Students实现了接口所以直接赋值没问题
// 如果没实现会报错:cannot use cbs (type Student) as type People in assignment:Student does not implement People (missing ReturnName method)
a = cbs
name := a.ReturnName()
fmt.Println(name) // 输出"小明"
}Si un L'interface ne contient aucune méthode, alors c'est une interface vide (interface vide). Tous les types sont conformes à la définition d'une interface vide, donc n'importe quel type peut être converti en interface vide.
Pour faire simple, la valeur d'une interface est composée de deux parties, à savoir le type et les données. Pour juger si deux interfaces sont égales, cela dépend si leurs deux parties sont égales en plus, seulement quand ; le type et les données sont nuls Représente l'interface comme nulle.
var a interface{}
var b interface{} = (*int)(nil)
fmt.Println(a == nil, b == nil) //true false2. Imbrication d'interfaces
Intégrez d'autres interfaces comme des champs anonymes. L'ensemble de méthodes de type cible doit contenir toutes les méthodes, y compris les méthodes d'interface intégrées, pour réaliser l'interface. L'intégration d'autres types d'interfaces équivaut à importer de manière centralisée leurs méthodes déclarées. Cela nécessite que les méthodes portant le même nom ne puissent pas être intégrées en elles-mêmes ou intégrées de manière cyclique.
type stringer interfaceP{
string() string
}
type tester interface {
stringer
test()
}
type data struct{}
func (*data) test() {}
func (data) string () string {
return ""
}
func main() {
var d data
var t tester = &d
t.test()
println(t.string())
}Les variables d'interface Superset peuvent être implicitement converties en sous-ensembles, mais pas l'inverse.
3. Implémentation de l'interface
La détection d'interface de Golang comporte à la fois des parties statiques et dynamiques.
● Partie statique
Pour le type concret (y compris les types personnalisés) ->, le compilateur génère l'itab correspondant et le place dans la section .rodata d'ELF. plus tard, lorsque , pointez simplement le pointeur directement vers l'adresse de décalage appropriée où .rodata existe. Pour une implémentation spécifique, veuillez consulter les journaux de soumission de Golang CL 20901 et CL 20902.
Pour l'interface-> de type concret (type concret, y compris les types personnalisés), le compilateur extrait les champs pertinents à des fins de comparaison et génère des valeurs
● La partie dynamique
sera traitée au moment de l'exécution, il existe une table de hachage globale qui enregistre l'itab de la conversion type->interface correspondante. Lors de la conversion, vérifiez d'abord la table de hachage s'il y en a une, sinon, vérifiez si les deux types peuvent le faire. être converti. S'il peut être inséré dans la table de hachage, il renverra un succès, s'il ne le peut pas, il renverra un échec. Notez que la table de hachage ici n'est pas la carte en cours, mais la table de hachage la plus primitive utilisant des tableaux, utilisant la méthode d'adresse ouverte pour résoudre les conflits. Principalement l'interface <-> (interface affectée à l'interface, interface convertie en une autre interface) est utilisée pour produire dynamiquement l'itab. La structure de
interface est la suivante :
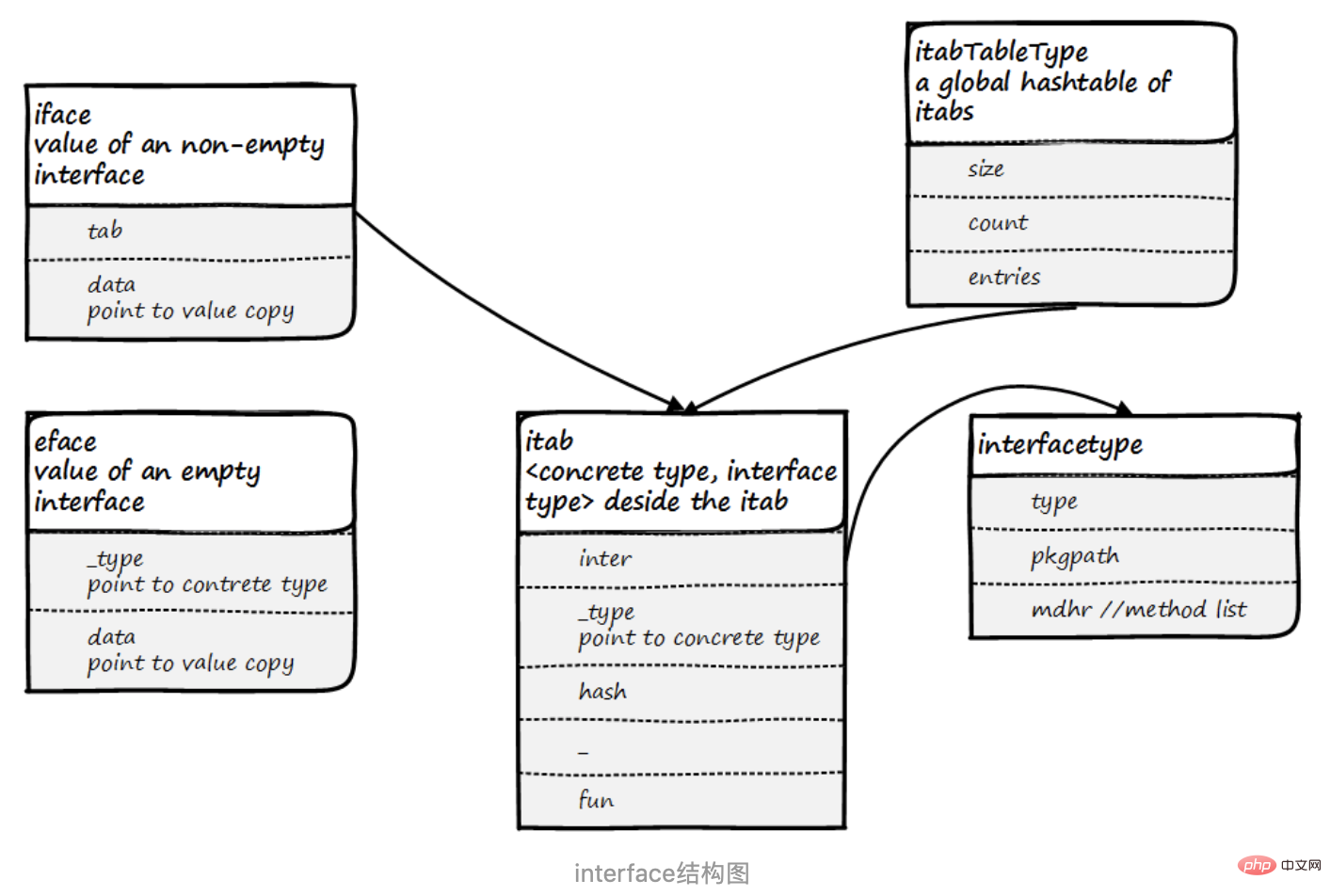
La structure du type d'interface interfacetype
type interfacetype struct {
typ _type
pkgpath name //记录定义接口的包名
mhdr []imethod //一个imethod切片,记录接口中定义的那些函数。
}
// imethod表示接口类型上的方法
type imethod struct {
name nameOff // name of method
typ typeOff // .(*FuncType) underneath
}Les types nameOff et typeOff sont int32 , et ces deux valeurs sont L'éditeur de liens est responsable de l'intégration des décalages par rapport aux métainformations de l'exécutable. Les méta-informations seront chargées dans la structure runtime.moduledata pendant l'exécution.
4. La structure des valeurs d'interface iface et eface
Pour les performances, golang est divisé en deux types d'interfaces, eface et eface est une interface vide, et iface est une interface de méthode.
type iface struct {
tab *itab
data unsafe.Pointer
}
type eface struct {
_type *_type
data unsafe.Pointer
}
type itab struct {
inter *interfacetype //inter接口类型
_type *_type //_type数据类型
hash uint32 //_type.hash的副本。用于类型开关。 hash哈希的方法
_ [4]byte
fun [1]uintptr // 大小可变。 fun [0] == 0表示_type未实现inter。 fun函数地址占位符
}Les données de la structure iface sont utilisées pour stocker les données réelles. Le runtime demandera une nouvelle mémoire, y testera les données, puis les données pointeront vers cette nouvelle mémoire.
La méthode de hachage dans itab est copiée depuis _type.hash ; fun est un tableau uintptr d'une taille de 1. Lorsque fun[0] est 0, cela signifie que _type n'implémente pas l'interface pour le moment. , fun stocke l'adresse de la première méthode d'interface, et les autres méthodes sont stockées une par une. Ici, nous échangeons simplement de l'espace contre du temps. En fait, les méthodes peuvent être trouvées dans le champ _type. ils s'appellent, Il n'y a pas besoin de recherche dynamique.
4.1 Table itab globale
iface.go:
const itabInitSize = 512
// 注意:如果更改这些字段,请在itabAdd的mallocgc调用中更改公式。
type itabTableType struct {
size uintptr // 条目数组的长度。始终为2的幂。
count uintptr // 当前已填写的条目数。
entries [itabInitSize]*itab // really [size] large
}On peut voir que cette itabTable globale est stockée dans un tableau, et size enregistre la taille du tableau, toujours puissance de 2. count enregistre la quantité de tableau qui a été utilisée. entrées est un tableau *itab avec une taille initiale de 512.
5. Conversion de type d'interface
L'attribution d'une valeur spécifique à l'interface appellera les fonctions de la série conv Par exemple, l'interface vide appelle la série convT2E. , non- L'interface vide appelle la série convT2I Pour des raisons de performances, de nombreux cas particuliers tels que convT2I64 et convT2Estring évitent d'appeler typedmemmove.
func convT2E(t *_type, elem unsafe.Pointer) (e eface) {
if raceenabled {
raceReadObjectPC(t, elem, getcallerpc(), funcPC(convT2E))
}
if msanenabled {
msanread(elem, t.size)
}
x := mallocgc(t.size, t, true)
// TODO: 我们分配一个清零的对象只是为了用实际数据覆盖它。
//确定如何避免归零。同样在下面的convT2Eslice,convT2I,convT2Islice中。
typedmemmove(t, x, elem)
e._type = t
e.data = x
return
}
func convT2I(tab *itab, elem unsafe.Pointer) (i iface) {
t := tab._type
if raceenabled {
raceReadObjectPC(t, elem, getcallerpc(), funcPC(convT2I))
}
if msanenabled {
msanread(elem, t.size)
}
x := mallocgc(t.size, t, true)
typedmemmove(t, x, elem)
i.tab = tab
i.data = x
return
}
func convT2I16(tab *itab, val uint16) (i iface) {
t := tab._type
var x unsafe.Pointer
if val == 0 {
x = unsafe.Pointer(&zeroVal[0])
} else {
x = mallocgc(2, t, false)
*(*uint16)(x) = val
}
i.tab = tab
i.data = x
return
}
func convI2I(inter *interfacetype, i iface) (r iface) {
tab := i.tab
if tab == nil {
return
}
if tab.inter == inter {
r.tab = tab
r.data = i.data
return
}
r.tab = getitab(inter, tab._type, false)
r.data = i.data
return
}On peut voir que :
● Le type spécifique est converti en une interface vide, et le champ _type copie directement le type source mallocgc crée une nouvelle mémoire, y copie la valeur ; , et les données pointent vers cette mémoire.
● 具体类型转非空接口,入参tab是编译器生成的填进去的,接口指向同一个入参tab指向的itab;mallocgc一个新内存,把值复制过去,data再指向这块内存。
● 对于接口转接口,itab是调用getitab函数去获取的,而不是编译器传入的。
对于那些特定类型的值,如果是零值,那么不会mallocgc一块新内存,data会指向zeroVal[0]。
5.1 接口转接口
func assertI2I2(inter *interfacetype, i iface) (r iface, b bool) {
tab := i.tab
if tab == nil {
return
}
if tab.inter != inter {
tab = getitab(inter, tab._type, true)
if tab == nil {
return
}
}
r.tab = tab
r.data = i.data
b = true
return
}
func assertE2I(inter *interfacetype, e eface) (r iface) {
t := e._type
if t == nil {
// 显式转换需要非nil接口值。
panic(&TypeAssertionError{nil, nil, &inter.typ, ""})
}
r.tab = getitab(inter, t, false)
r.data = e.data
return
}
func assertE2I2(inter *interfacetype, e eface) (r iface, b bool) {
t := e._type
if t == nil {
return
}
tab := getitab(inter, t, true)
if tab == nil {
return
}
r.tab = tab
r.data = e.data
b = true
return
}我们看到有两种用法:
● 返回值是一个时,不能转换就panic。
● 返回值是两个时,第二个返回值标记能否转换成功
此外,data复制的是指针,不会完整拷贝值。每次都malloc一块内存,那么性能会很差,因此,对于一些类型,golang的编译器做了优化。
5.2 接口转具体类型
接口判断是否转换成具体类型,是编译器生成好的代码去做的。我们看个empty interface转换成具体类型的例子:
var EFace interface{}
var j int
func F4(i int) int{
EFace = I
j = EFace.(int)
return j
}
func main() {
F4(10)
}反汇编:
go build -gcflags '-N -l' -o tmp build.go go tool objdump -s "main.F4" tmp
可以看汇编代码:
MOVQ main.EFace(SB), CX //CX = EFace.typ2 LEAQ type.*+60128(SB), DX //DX = &type.int3 CMPQ DX, CX.
可以看到empty interface转具体类型,是编译器生成好对比代码,比较具体类型和空接口是不是同一个type,而不是调用某个函数在运行时动态对比。
5.3 非空接口类型转换
var tf Tester
var t testStruct
func F4() int{
t := tf.(testStruct)
return t.i
}
func main() {
F4()
}
//反汇编
MOVQ main.tf(SB), CX // CX = tf.tab(.inter.typ)
LEAQ go.itab.main.testStruct,main.Tester(SB), DX // DX = <testStruct,Tester>对应的&itab(.inter.typ)
CMPQ DX, CX //可以看到,非空接口转具体类型,也是编译器生成的代码,比较是不是同一个itab,而不是调用某个函数在运行时动态对比。
6. 获取itab的流程
golang interface的核心逻辑就在这,在get的时候,不仅仅会从itabTalbe中查找,还可能会创建插入,itabTable使用容量超过75%还会扩容。看下代码:
func getitab(inter *interfacetype, typ *_type, canfail bool) *itab {
if len(inter.mhdr) == 0 {
throw("internal error - misuse of itab")
}
// 简单的情况
if typ.tflag&tflagUncommon == 0 {
if canfail {
return nil
}
name := inter.typ.nameOff(inter.mhdr[0].name)
panic(&TypeAssertionError{nil, typ, &inter.typ, name.name()})
}
var m *itab
//首先,查看现有表以查看是否可以找到所需的itab。
//这是迄今为止最常见的情况,因此请不要使用锁。
//使用atomic确保我们看到该线程完成的所有先前写入更新itabTable字段(在itabAdd中使用atomic.Storep)。
t := (*itabTableType)(atomic.Loadp(unsafe.Pointer(&itabTable)))
if m = t.find(inter, typ); m != nil {
goto finish
}
// 未找到。抓住锁,然后重试。
lock(&itabLock)
if m = itabTable.find(inter, typ); m != nil {
unlock(&itabLock)
goto finish
}
// 条目尚不存在。进行新输入并添加。
m = (*itab)(persistentalloc(unsafe.Sizeof(itab{})+uintptr(len(inter.mhdr)-1)*sys.PtrSize, 0, &memstats.other_sys))
m.inter = inter
m._type = typ
m.init()
itabAdd(m)
unlock(&itabLock)
finish:
if m.fun[0] != 0 {
return m
}
if canfail {
return nil
}
//仅当转换时才会发生,使用ok形式已经完成一次,我们得到了一个缓存的否定结果。
//缓存的结果不会记录,缺少接口函数,因此初始化再次获取itab,以获取缺少的函数名称。
panic(&TypeAssertionError{concrete: typ, asserted: &inter.typ, missingMethod: m.init()})
}流程如下:
● 先用t保存全局itabTable的地址,然后使用t.find去查找,这样是为了防止查找过程中,itabTable被替换导致查找错误。
● 如果没找到,那么就会上锁,然后使用itabTable.find去查找,这样是因为在第一步查找的同时,另外一个协程写入,可能导致实际存在却查找不到,这时上锁避免itabTable被替换,然后直接在itaTable中查找。
● 再没找到,说明确实没有,那么就根据接口类型、数据类型,去生成一个新的itab,然后插入到itabTable中,这里可能会导致hash表扩容,如果数据类型并没有实现接口,那么根据调用方式,该报错报错,该panic panic。
这里我们可以看到申请新的itab空间时,内存空间的大小是unsafe.Sizeof(itab{})+uintptr(len(inter.mhdr)-1)*sys.PtrSize,参照前面接受的结构,len(inter.mhdr)就是接口定义的方法数量,因为字段fun是一个大小为1的数组,所以len(inter.mhdr)-1,在fun字段下面其实隐藏了其他方法接口地址。
6.1 在itabTable中查找itab find
func itabHashFunc(inter *interfacetype, typ *_type) uintptr {
// 编译器为我们提供了一些很好的哈希码。
return uintptr(inter.typ.hash ^ typ.hash)
}
// find在t中找到给定的接口/类型对。
// 如果不存在给定的接口/类型对,则返回nil。
func (t *itabTableType) find(inter *interfacetype, typ *_type) *itab {
// 使用二次探测实现。
//探测顺序为h(i)= h0 + i *(i + 1)/ 2 mod 2 ^ k。
//我们保证使用此探测序列击中所有表条目。
mask := t.size - 1
h := itabHashFunc(inter, typ) & mask
for i := uintptr(1); ; i++ {
p := (**itab)(add(unsafe.Pointer(&t.entries), h*sys.PtrSize))
// 在这里使用atomic read,所以如果我们看到m!= nil,我们也会看到m字段的初始化。
// m := *p
m := (*itab)(atomic.Loadp(unsafe.Pointer(p)))
if m == nil {
return nil
}
if m.inter == inter && m._type == typ {
return m
}
h += I
h &= mask
}
}从注释可以看到,golang使用的开放地址探测法,用的是公式h(i) = h0 + i*(i+1)/2 mod 2^k,h0是根据接口类型和数据类型的hash字段算出来的。以前的版本是额外使用一个link字段去连到下一个slot,那样会有额外的存储,性能也会差写,在1.11中我们看到有了改进。
6.2 检查并生成itab init
// init用所有代码指针填充m.fun数组m.inter / m._type对。 如果该类型未实现该接口,将m.fun [0]设置为0,并返回缺少的接口函数的名称。
//可以在同一m上多次调用此函数,即使同时调用也可以。
func (m *itab) init() string {
inter := m.inter
typ := m._type
x := typ.uncommon()
// inter和typ都有按名称排序的方法,
//并且接口名称是唯一的,
//因此可以在锁定步骤中对两者进行迭代;
//循环是O(ni + nt)而不是O(ni * nt)。
ni := len(inter.mhdr)
nt := int(x.mcount)
xmhdr := (*[1 << 16]method)(add(unsafe.Pointer(x), uintptr(x.moff)))[:nt:nt]
j := 0
imethods:
for k := 0; k < ni; k++ {
i := &inter.mhdr[k]
itype := inter.typ.typeOff(i.ityp)
name := inter.typ.nameOff(i.name)
iname := name.name()
ipkg := name.pkgPath()
if ipkg == "" {
ipkg = inter.pkgpath.name()
}
for ; j < nt; j++ {
t := &xmhdr[j]
tname := typ.nameOff(t.name)
if typ.typeOff(t.mtyp) == itype && tname.name() == iname {
pkgPath := tname.pkgPath()
if pkgPath == "" {
pkgPath = typ.nameOff(x.pkgpath).name()
}
if tname.isExported() || pkgPath == ipkg {
if m != nil {
ifn := typ.textOff(t.ifn)
*(*unsafe.Pointer)(add(unsafe.Pointer(&m.fun[0]), uintptr(k)*sys.PtrSize)) = ifn
}
continue imethods
}
}
}
// didn't find method
m.fun[0] = 0
return iname
}
m.hash = typ.hash
return ""
}这个方法会检查interface和type的方法是否匹配,即type有没有实现interface。假如interface有n中方法,type有m中方法,那么匹配的时间复杂度是O(n x m),由于interface、type的方法都按字典序排,所以O(n+m)的时间复杂度可以匹配完。在检测的过程中,匹配上了,依次往fun字段写入type中对应方法的地址。如果有一个方法没有匹配上,那么就设置fun[0]为0,在外层调用会检查fun[0]==0,即type并没有实现interface。
这里我们还可以看到golang中continue的特殊用法,要直接continue到外层的循环中,那么就在那一层的循环上加个标签,然后continue 标签。
6.3 把itab插入到itabTable中 itabAdd
// itabAdd将给定的itab添加到itab哈希表中。
//必须保持itabLock。
func itabAdd(m *itab) {
// 设置了mallocing时,错误可能导致调用此方法,通常是因为这是在恐慌时调用的。
//可靠地崩溃,而不是仅在需要增长时崩溃哈希表。
if getg().m.mallocing != 0 {
throw("malloc deadlock")
}
t := itabTable
if t.count >= 3*(t.size/4) { // 75% 负载系数
// 增长哈希表。
// t2 = new(itabTableType)+一些其他条目我们撒谎并告诉malloc我们想要无指针的内存,因为所有指向的值都不在堆中。
t2 := (*itabTableType)(mallocgc((2+2*t.size)*sys.PtrSize, nil, true))
t2.size = t.size * 2
// 复制条目。
//注意:在复制时,其他线程可能会寻找itab和找不到它。没关系,他们将尝试获取Itab锁,因此请等到复制完成。
if t2.count != t.count {
throw("mismatched count during itab table copy")
}
// 发布新的哈希表。使用原子写入:请参阅getitab中的注释。
atomicstorep(unsafe.Pointer(&itabTable), unsafe.Pointer(t2))
// 采用新表作为我们自己的表。
t = itabTable
// 注意:旧表可以在此处进行GC处理。
}
t.add(m)
}
// add将给定的itab添加到itab表t中。
//必须保持itabLock。
func (t *itabTableType) add(m *itab) {
//请参阅注释中的有关探查序列的注释。
//将新的itab插入探针序列的第一个空位。
mask := t.size - 1
h := itabHashFunc(m.inter, m._type) & mask
for i := uintptr(1); ; i++ {
p := (**itab)(add(unsafe.Pointer(&t.entries), h*sys.PtrSize))
m2 := *p
if m2 == m {
//给定的itab可以在多个模块中使用并且由于全局符号解析的工作方式,
//指向itab的代码可能已经插入了全局“哈希”。
return
}
if m2 == nil {
// 在这里使用原子写,所以如果读者看到m,它也会看到正确初始化的m字段。
// NoWB正常,因为m不在堆内存中。
// *p = m
atomic.StorepNoWB(unsafe.Pointer(p), unsafe.Pointer(m))
t.count++
return
}
h += I
h &= mask
}
}可以看到,当hash表使用达到75%或以上时,就会进行扩容,容量是原来的2倍,申请完空间,就会把老表中的数据插入到新的hash表中。然后使itabTable指向新的表,最后把新的itab插入到新表中。
推荐:go语言教程
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Introduction aux types d'interfaces de disque dur
Introduction aux types d'interfaces de disque dur
 Utilisation du nœud d'arbre
Utilisation du nœud d'arbre
 Comment obtenir des données en HTML
Comment obtenir des données en HTML
 Comment changer pycharm en chinois
Comment changer pycharm en chinois
 Comment acheter du Dogecoin
Comment acheter du Dogecoin
 utilisation de la fonction ubound
utilisation de la fonction ubound
 Que peuvent faire les amis de TikTok ?
Que peuvent faire les amis de TikTok ?
 utilisation de la fonction stripslashes
utilisation de la fonction stripslashes
 utilisation de la fonction de tri de Python
utilisation de la fonction de tri de Python










![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



