

Explication détaillée de la persistance RDB dans Redis

Par rapport à d'autres produits de mise en cache tels que Memcache, Redis présente un avantage évident dans la mesure où Redis prend non seulement en charge les données de type clé-valeur simples, mais fournit également list, set et zset , stockage de structures de données telles que le hachage. Nous avons consacré deux articles à présenter en détail ces types de données riches. Ensuite, nous présenterons un autre avantage majeur de Redis : la persistance. (Recommandation : tutoriel vidéo Redis)
Étant donné que Redis est une base de données en mémoire, la base de données dite en mémoire consiste à stocker le contenu de la base de données en mémoire, ce qui est lié à MySQL, Oracle, etc. traditionnels. Par rapport aux bases de données traditionnelles qui enregistrent directement le contenu sur le disque dur, l'efficacité de lecture et d'écriture d'une base de données en mémoire est beaucoup plus rapide que celle d'une base de données traditionnelle (l'efficacité de lecture et d'écriture de la mémoire est bien supérieure à l'efficacité de lecture et d'écriture du disque dur). Cependant, le sauvegarder en mémoire présente également un inconvénient. Une fois l'alimentation coupée ou la machine en panne, toutes les données de la base de données mémoire seront perdues.
Afin de résoudre cette lacune, Redis fournit la fonction de persistance des données de mémoire sur le disque dur et d'utilisation de fichiers persistants pour restaurer les données de la base de données. Redis prend en charge deux formes de persistance, l'une est la capture instantanée RDB (instantané) et l'autre est AOF (append-only-file). Ce blog présente d'abord les instantanés RDB.
1. Introduction à RDB
RDB est une méthode utilisée par Redis pour la persistance. Il s'agit d'un instantané de l'ensemble de données actuellement en mémoire. . Écrivez sur le disque, c'est-à-dire un instantané (toutes les données de paire clé-valeur dans la base de données). Lors de la récupération, le fichier d'instantané est lu directement dans la mémoire.
Retour en haut
2. Méthode de déclenchement
RDB dispose de deux méthodes de déclenchement, à savoir le déclenchement automatique et le déclenchement manuel.
①, Déclenchez automatiquement
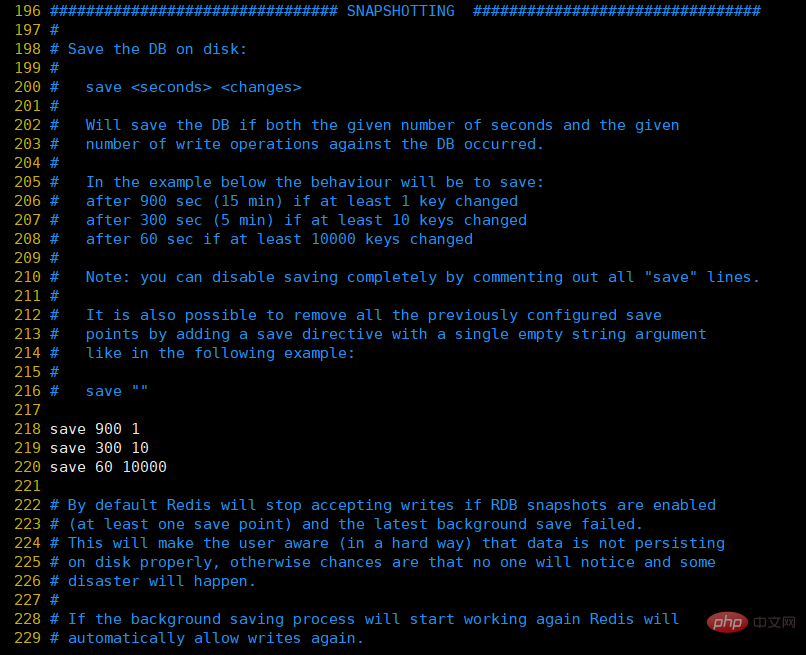
Sous SNAPSHOTTING dans le fichier de configuration redis.conf
①, enregistrez : Ceci est utilisé pour configurer le déclencheur la condition de persistance RDB de Redis, c'est-à-dire quand enregistrer les données en mémoire sur le disque dur. Par exemple "enregistrer m n". Indique que lorsque l'ensemble de données a été modifié n fois en m secondes, bgsave est automatiquement déclenché (cette commande sera présentée ci-dessous, ainsi que la commande pour déclencher manuellement la persistance RDB)
La configuration par défaut est la suivante :
save 900 1:表示900 秒内如果至少有 1 个 key 的值变化,则保存 save 300 10:表示300 秒内如果至少有 10 个 key 的值变化,则保存 save 60 10000:表示60 秒内如果至少有 10000 个 key 的值变化,则保存
Bien sûr, si vous utilisez simplement la fonction de mise en cache de Redis et n'avez pas besoin de persistance, vous pouvez commenter toutes les lignes de sauvegarde pour désactiver la fonction de sauvegarde. Vous pouvez utiliser directement une chaîne vide pour réaliser la désactivation : save ""
②, stop-writes-on-bgsave-error : La valeur par défaut est yes. Lorsque RDB est activé et que la dernière sauvegarde des données en arrière-plan échoue, si Redis cesse de recevoir des données. Cela permettrait à l'utilisateur de se rendre compte que les données n'ont pas été correctement conservées sur le disque, sinon personne ne remarquerait qu'un sinistre s'est produit. Si Redis redémarre, il peut recommencer à recevoir des données
③, rdbcompression ; la valeur par défaut est yes. Pour les instantanés stockés sur disque, vous pouvez définir s'il convient de les compresser pour le stockage. Si tel est le cas, Redis utilisera l'algorithme LZF pour la compression. Si vous ne souhaitez pas consommer de CPU pour la compression, vous pouvez désactiver cette fonctionnalité, mais les instantanés stockés sur le disque seront plus volumineux.
④, rdbchecksum : La valeur par défaut est oui. Après avoir stocké l'instantané, nous pouvons également laisser Redis utiliser l'algorithme CRC64 pour la vérification des données, mais cela augmentera la consommation de performances d'environ 10 %. Si vous souhaitez obtenir une amélioration maximale des performances, vous pouvez désactiver cette fonction.
⑤, dbfilename : définissez le nom de fichier de l'instantané, la valeur par défaut est dump.rdb
⑥, dir : définissez le chemin de stockage du fichier d'instantané, cet élément de configuration doit être un répertoire , pas un nom de fichier . La valeur par défaut est de l'enregistrer dans le même répertoire que le fichier de configuration actuel.
C'est-à-dire que grâce à la méthode de sauvegarde configurée dans le fichier de configuration, lorsque l'opération réelle répond au formulaire de configuration, la persistance RDB sera effectuée et l'instantané de mémoire actuel sera enregistré dans le répertoire configuré par dir . Le nom du fichier est déterminé par le nom de fichier configuré.
②. Déclenchement manuel
Il existe deux commandes pour déclencher manuellement Redis pour la persistance RDB :
1 save
Cette commande bloquera le Redis actuel. Serveur, lors de l'exécution de la commande save, Redis ne peut pas traiter d'autres commandes tant que le processus RDB n'est pas terminé.
Évidemment, cette commande provoquera un blocage à long terme pour les instances avec une mémoire relativement volumineuse, ce qui est une faille fatale. Afin de résoudre ce problème, Redis propose une deuxième méthode.
2. bgsave
Lors de l'exécution de cette commande, Redis effectuera des opérations d'instantané de manière asynchrone en arrière-plan, et l'instantané peut également répondre aux demandes des clients. L'opération spécifique est que le processus Redis effectue une opération fork pour créer un processus enfant. Le processus de persistance RDB est responsable du processus enfant et se termine automatiquement une fois terminé. Le blocage ne se produit que dans la phase de fourche et est généralement de très courte durée.
Fondamentalement, toutes les opérations RDB dans Redis utilisent la commande bgsave.
ps : L'exécution de la commande flushall générera également le fichier dump.rdb, mais il est vide et dénué de sens
Restaurer les données
将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可,redis就会自动加载文件数据至内存了。Redis 服务器在载入 RDB 文件期间,会一直处于阻塞状态,直到载入工作完成为止。
获取 redis 的安装目录可以使用 config get dir 命令

4、停止 RDB 持久化
有些情况下,我们只想利用Redis的缓存功能,并不像使用 Redis 的持久化功能,那么这时候我们最好停掉 RDB 持久化。可以通过上面讲的在配置文件 redis.conf 中,可以注释掉所有的 save 行来停用保存功能或者直接一个空字符串来实现停用:save ""
也可以通过命令:
redis-cli config set save " "
回到顶部
5、RDB 的优势和劣势
①、优势
1.RDB是一个非常紧凑(compact)的文件,它保存了redis 在某个时间点上的数据集。这种文件非常适合用于进行备份和灾难恢复。
2.生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作。
3.RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
②、劣势
1、RDB方式数据没办法做到实时持久化/秒级持久化。因为bgsave每次运行都要执行fork操作创建子进程,属于重量级操作(内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑),频繁执行成本过高(影响性能)
2、RDB文件使用特定二进制格式保存,Redis版本演进过程中有多个格式的RDB版本,存在老版本Redis服务无法兼容新版RDB格式的问题(版本不兼容)
3、在一定间隔时间做一次备份,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改(数据有丢失)
回到顶部
6、RDB 自动保存的原理
Redis有个服务器状态结构:
struct redisService{
//1、记录保存save条件的数组
struct saveparam *saveparams;
//2、修改计数器
long long dirty;
//3、上一次执行保存的时间
time_t lastsave;
}①、首先看记录保存save条件的数组 saveparam,里面每个元素都是一个 saveparams 结构:
struct saveparam{
//秒数
time_t seconds;
//修改数
int changes;
};前面我们在 redis.conf 配置文件中进行了关于save 的配置:
save 900 1:表示900 秒内如果至少有 1 个 key 的值变化,则保存 save 300 10:表示300 秒内如果至少有 10 个 key 的值变化,则保存 save 60 10000:表示60 秒内如果至少有 10000 个 key 的值变化,则保存
那么服务器状态中的saveparam 数组将会是如下的样子:
②、dirty 计数器和lastsave 属性
dirty 计数器记录距离上一次成功执行 save 命令或者 bgsave 命令之后,Redis服务器进行了多少次修改(包括写入、删除、更新等操作)。
lastsave 属性是一个时间戳,记录上一次成功执行 save 命令或者 bgsave 命令的时间。
通过这两个命令,当服务器成功执行一次修改操作,那么dirty 计数器就会加 1,而lastsave 属性记录上一次执行save或bgsave的时间,Redis 服务器还有一个周期性操作函数 severCron ,默认每隔 100 毫秒就会执行一次,该函数会遍历并检查 saveparams 数组中的所有保存条件,只要有一个条件被满足,那么就会执行 bgsave 命令。
执行完成之后,dirty 计数器更新为 0 ,lastsave 也更新为执行命令的完成时间。
更多redis知识请关注redis数据库教程栏目。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1205
24
52
1205
24

 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données Redis: utilisez la commande flushall pour effacer toutes les valeurs de clé. Utilisez la commande flushdb pour effacer la valeur clé de la base de données actuellement sélectionnée. Utilisez SELECT pour commuter les bases de données, puis utilisez FlushDB pour effacer plusieurs bases de données. Utilisez la commande del pour supprimer une clé spécifique. Utilisez l'outil Redis-CLI pour effacer les données.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
L'utilisation des opérations Redis pour verrouiller nécessite l'obtention du verrouillage via la commande setnx, puis en utilisant la commande Expire pour définir le temps d'expiration. Les étapes spécifiques sont les suivantes: (1) Utilisez la commande setnx pour essayer de définir une paire de valeurs de clé; (2) Utilisez la commande Expire pour définir le temps d'expiration du verrou; (3) Utilisez la commande del pour supprimer le verrouillage lorsque le verrouillage n'est plus nécessaire.
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment utiliser la ligne de commande redis
Apr 10, 2025 pm 10:18 PM
Comment utiliser la ligne de commande redis
Apr 10, 2025 pm 10:18 PM
Utilisez l'outil de ligne de commande redis (Redis-CLI) pour gérer et utiliser Redis via les étapes suivantes: Connectez-vous au serveur, spécifiez l'adresse et le port. Envoyez des commandes au serveur à l'aide du nom et des paramètres de commande. Utilisez la commande d'aide pour afficher les informations d'aide pour une commande spécifique. Utilisez la commande QUIT pour quitter l'outil de ligne de commande.
 Comment résoudre la perte de données avec Redis
Apr 10, 2025 pm 08:24 PM
Comment résoudre la perte de données avec Redis
Apr 10, 2025 pm 08:24 PM
Les causes de la perte de données redis incluent les défaillances de mémoire, les pannes de courant, les erreurs humaines et les défaillances matérielles. Les solutions sont: 1. Stockez les données sur le disque avec RDB ou AOF Persistance; 2. Copiez sur plusieurs serveurs pour une haute disponibilité; 3. Ha avec Redis Sentinel ou Redis Cluster; 4. Créez des instantanés pour sauvegarder les données; 5. Mettre en œuvre les meilleures pratiques telles que la persistance, la réplication, les instantanés, la surveillance et les mesures de sécurité.
