

En savoir plus sur la copie zéro sous Linux et Java


E/S traditionnelle Linux
Bonjour à tous, je suis une donnée située sur un disque Linux. Maintenant, pour m'envoyer du disque vers la carte réseau, je dois suivre les étapes suivantes :
Opération de lecture
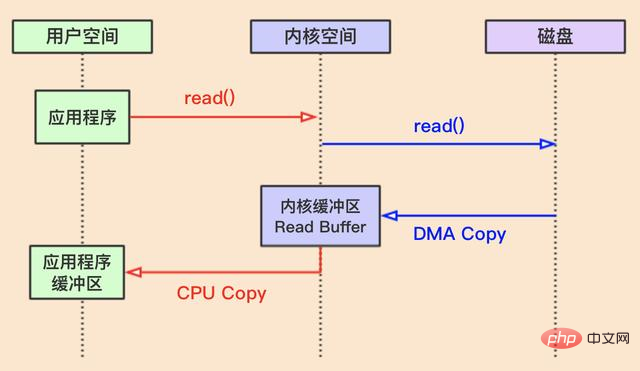
Comme indiqué ci-dessus : la mémoire du système d’exploitation est divisée en espace noyau et espace utilisateur. Premièrement, les applications situées dans l'espace utilisateur lancent des opérations de lecture de données, telles que JVM lançant des read() appels système. A ce moment, le système d'exploitation effectuera un changement de contexte : passer de l'espace utilisateur à l'espace noyau.
Ensuite, l'espace du noyau informe le disque et le noyau me copie du disque vers le tampon du noyau. Ce processus est effectué par un élément matériel appelé "DMA (Direct Memory Access)", il ne nécessite donc pas la participation du CPU.
Ensuite, le noyau me copie du tampon du noyau vers le tampon de l'application, ce qui nécessite la participation du CPU.
Enfin, un changement de contexte est effectué et le contexte revient à l'espace utilisateur.
L'ensemble du processus d'opération de lecture nécessite deux changements de contexte et deux copies .
Recommandations d'apprentissage associées : Tutoriel vidéo Java
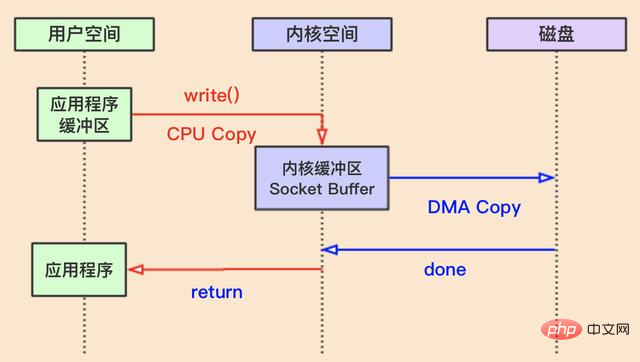
Opération d'écriture
Opération d'écriture C'est similaire à l'opération de lecture, mais dans le sens opposé. Elle nécessite toujours deux changements de contexte et deux copies de données. Je peux être écrit sur le disque ou sur la carte réseau.
Mappage de la mémoire
Comme vous pouvez le voir dans le processus ci-dessus, si vous souhaitez m'envoyer du disque vers le réseau carte, vous avez besoin d'un total de 4 changements de contexte et de 4 opérations de copie. J'ai été copié entre l'espace noyau et l'espace utilisateur par le système d'exploitation, mais en fait je n'ai rien fait pendant cette période, rien n'a changé, c'était juste une copie, donc ce modèle IO était un gaspillage de ressources du système d'exploitation, et j'étais copié tant de fois, épuisé physiquement et mentalement. De plus, les ressources du système d'exploitation sont très précieuses~
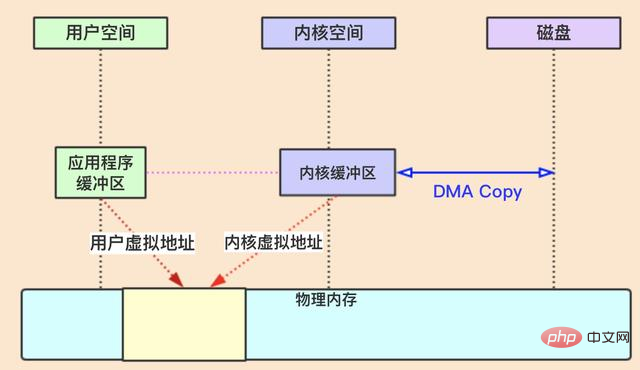
De nos jours, les systèmes d'exploitation grand public utilisent la mémoire virtuelle. Pour faire simple, utilisez adresse virtuelle au lieu de l'adresse physique Cela permet à plusieurs mémoires virtuelles de vouloir uniquement la même adresse physique, et l'espace mémoire virtuelle peut être beaucoup plus grand que l'espace mémoire physique.
Si le système d'exploitation pouvait mapper le tampon d'application dans l'espace utilisateur et le tampon du noyau dans l'espace noyau sur la même adresse physique, cela n'éliminerait-il pas de nombreux processus de copie ? Comme indiqué ci-dessous :
Linux zéro copie
Ainsi, afin de résoudre ce problème, les développeurs Linux intelligents ont écrit de nouveaux appels système. sont faits pour cela. Il existe deux manières principales :
- mmap + write
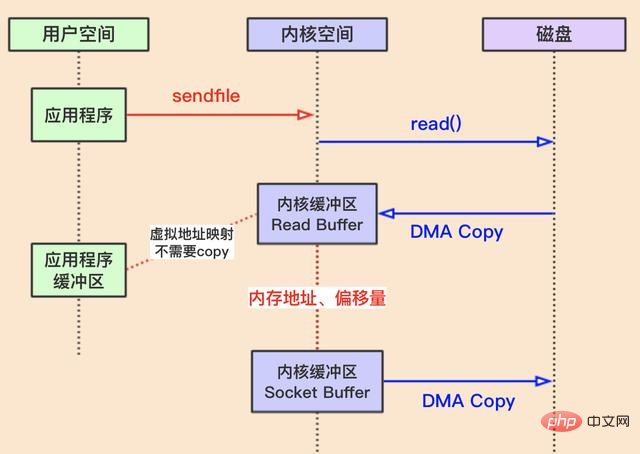
- sendfile
mmap + write
mmap()L'appel système utilisera d'abord la copie DMA pour lire du disque vers le tampon du noyau, puis utilisera le mappage de mémoire pour faire en sorte que les adresses mémoire du tampon utilisateur et du tampon de lecture du noyau aient la même adresse mémoire. disons, le CPU n'a pas besoin de me copier du tampon de lecture du noyau vers le tampon utilisateur !
Lors de l'utilisation de l'appel système write(), le CPU écrit directement depuis le tampon du noyau (équivalent au tampon utilisateur) vers le tampon du noyau qui doit être envoyé, comme envoi réseau Tampon (tampon de socket) , puis transmettez-le au pilote de la carte réseau (ou au disque) via DMA pour préparer l'envoi.
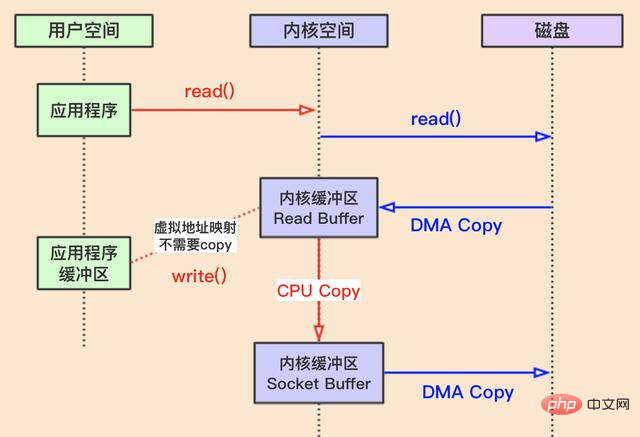
La lecture et l'écriture de données à l'aide de mmap + write nécessitent un total de deux appels système, 4 commutateurs de contexte, 2 copies DMA et 1 copie CPU.
sendfile
sendfile est également un appel système. Il combine essentiellement les fonctions des deux appels système ci-dessus en un seul appel. L'avantage est que le système d'exploitation n'a besoin que de deux commutateurs de contexte, ce qui réduit la surcharge de deux commutateurs de contexte.
En savoir plus sur la copie zéro sous Linux et Java
Le noyau Linux 2.4 optimise sendfile et fournit l'opération de collecte. Cette opération peut supprimer la dernière copie CPU dans l'image ci-dessus. , à la place, l'adresse mémoire et l'enregistrement de décalage des données dans le tampon de noyau précédent (comme le tampon de lecture dans le cas de la figure) sont envoyés au tampon du noyau cible (comme le tampon de socket dans le cas de la figure) , de sorte que dans le DMA final Au stade de la copie, vous pouvez utiliser ce pointeur pour copier directement les données.
Java NIO utilise la copie zéro
La copie zéro de Linux peut en effet économiser certaines ressources du système d'exploitation. Par conséquent, NIO de Java fournit certaines classes pour prendre en charge la copie zéro :
- DirectByteBuffer
- FileChannel
Dans le précédent "Java NIO - Buffer" Cet article en gros introduit DirectByteBuffer. Il existe deux implémentations principales de ByteBuffer, l'une est DirectByteBuffer et l'autre est HeapByteBuffer.
Parmi eux, DirectByteBuffer alloue de la mémoire directement à l'extérieur du tas, et la couche inférieure appelle directement l'appel système NIO du système d'exploitation via JNI, les performances seront donc relativement élevées. Le HeapByteBuffer est une mémoire dans le tas et les données doivent être copiées une fois de plus, les performances sont donc relativement faibles.
FileChannel est une classe fournie par Java NIO pour copier des fichiers. Elle peut copier des fichiers sur le disque ou le réseau, etc.
mapLa méthode utilise en fait la méthode de mappage de mémoire dans le système d'exploitation pour mapper la mémoire du tampon noyau et la mémoire du tampon utilisateur en une adresse. La méthode
transferTo transfère directement le contenu actuel du canal vers un autre canal, ce qui signifie que cette méthode n'a pas le problème de lire et d'écrire du tampon noyau vers le tampon utilisateur. La couche inférieure est l'appel système sendfile. transferFromLa méthode est la même.
Exemple de code :
File file = new File("test.txt");RandomAccessFile raf = new RandomAccessFile(file, "rw");FileChannel fileChannel = raf.getChannel();SocketChannel socketChannel = SocketChannel.open(new InetSocketAddress("", 8080));// 直接使用了transferTo()进行通道间的数据传输fileChannel.transferTo(0, fileChannel.size(), socketChannel);Auteur : Cercle technologique de Public account_xy
Lien : www.imooc.com/article/289550
Source : MOOC.com
Le contenu ci-dessus provient de MOOC.com
Une autre compréhension du zéro copie
Zéro copie provient de l'opération De une perspective système. Parce qu'aucune donnée n'est dupliquée entre les tampons du noyau (seul le tampon du noyau possède une copie des données).
La copie zéro apporte non seulement moins de copie de données, mais apporte également d'autres avantages en termes de performances, tels que moins de changements de contexte, moins de pseudo-partage du cache CPU et aucun calcul de somme de contrôle CPU.
La différence entre mmap et sendFile
mmap convient à la lecture et à l'écriture de petites quantités de données, et sendFile convient aux transferts de fichiers volumineux.
mmap nécessite 4 changements de contexte et 3 copies de données ; sendFile nécessite 3 changements de contexte et au moins 2 copies de données.
sendFile peut utiliser DMA pour réduire la copie du processeur, mais mmap ne le peut pas (il doit être copié du noyau vers le tampon Socket).
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Différence entre Centos et Ubuntu
Apr 14, 2025 pm 09:09 PM
Différence entre Centos et Ubuntu
Apr 14, 2025 pm 09:09 PM
Les principales différences entre Centos et Ubuntu sont: l'origine (Centos provient de Red Hat, pour les entreprises; Ubuntu provient de Debian, pour les particuliers), la gestion des packages (Centos utilise Yum, se concentrant sur la stabilité; Ubuntu utilise APT, pour une fréquence de mise à jour élevée), le cycle de support (CentOS fournit 10 ans de soutien, Ubuntu fournit un large soutien de LT tutoriels et documents), utilisations (Centos est biaisé vers les serveurs, Ubuntu convient aux serveurs et aux ordinateurs de bureau), d'autres différences incluent la simplicité de l'installation (Centos est mince)
 Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Étapes d'installation de CentOS: Téléchargez l'image ISO et Burn Bootable Media; démarrer et sélectionner la source d'installation; sélectionnez la langue et la disposition du clavier; configurer le réseau; partitionner le disque dur; définir l'horloge système; créer l'utilisateur racine; sélectionnez le progiciel; démarrer l'installation; Redémarrez et démarrez à partir du disque dur une fois l'installation terminée.
 Centos arrête la maintenance 2024
Apr 14, 2025 pm 08:39 PM
Centos arrête la maintenance 2024
Apr 14, 2025 pm 08:39 PM
Centos sera fermé en 2024 parce que sa distribution en amont, Rhel 8, a été fermée. Cette fermeture affectera le système CentOS 8, l'empêchant de continuer à recevoir des mises à jour. Les utilisateurs doivent planifier la migration et les options recommandées incluent CentOS Stream, Almalinux et Rocky Linux pour garder le système en sécurité et stable.
 Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
La politique de sauvegarde et de récupération de GitLab dans le système CentOS afin d'assurer la sécurité et la récupérabilité des données, Gitlab on CentOS fournit une variété de méthodes de sauvegarde. Cet article introduira plusieurs méthodes de sauvegarde courantes, paramètres de configuration et processus de récupération en détail pour vous aider à établir une stratégie complète de sauvegarde et de récupération de GitLab. 1. MANUEL BACKUP Utilisez le Gitlab-RakegitLab: Backup: Créer la commande pour exécuter la sauvegarde manuelle. Cette commande sauvegarde des informations clés telles que le référentiel Gitlab, la base de données, les utilisateurs, les groupes d'utilisateurs, les clés et les autorisations. Le fichier de sauvegarde par défaut est stocké dans le répertoire / var / opt / gitlab / backups. Vous pouvez modifier / etc / gitlab
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Comment monter un disque dur dans les centos
Apr 14, 2025 pm 08:15 PM
Comment monter un disque dur dans les centos
Apr 14, 2025 pm 08:15 PM
Le support de disque dur CentOS est divisé en étapes suivantes: Déterminez le nom du périphérique du disque dur (/ dev / sdx); créer un point de montage (il est recommandé d'utiliser / mnt / newdisk); Exécutez la commande Mount (mont / dev / sdx1 / mnt / newdisk); modifier le fichier / etc / fstab pour ajouter une configuration de montage permanent; Utilisez la commande umount pour désinstaller l'appareil pour vous assurer qu'aucun processus n'utilise l'appareil.
 Le choix de Centos après l'arrêt de l'entretien
Apr 14, 2025 pm 08:51 PM
Le choix de Centos après l'arrêt de l'entretien
Apr 14, 2025 pm 08:51 PM
CentOS a été interrompu, les alternatives comprennent: 1. Rocky Linux (meilleure compatibilité); 2. Almalinux (compatible avec CentOS); 3. Serveur Ubuntu (configuration requise); 4. Red Hat Enterprise Linux (version commerciale, licence payante); 5. Oracle Linux (compatible avec Centos et Rhel). Lors de la migration, les considérations sont: la compatibilité, la disponibilité, le soutien, le coût et le soutien communautaire.
 Comment utiliser Docker Desktop
Apr 15, 2025 am 11:45 AM
Comment utiliser Docker Desktop
Apr 15, 2025 am 11:45 AM
Comment utiliser Docker Desktop? Docker Desktop est un outil pour exécuter des conteneurs Docker sur les machines locales. Les étapes à utiliser incluent: 1. Installer Docker Desktop; 2. Démarrer Docker Desktop; 3. Créer une image Docker (à l'aide de DockerFile); 4. Build Docker Image (en utilisant Docker Build); 5. Exécuter Docker Container (à l'aide de Docker Run).
