


L'utilisation du mot-clé EXPLAIN peut simuler l'exécution d'instructions de requête SQL par l'optimiseur, afin de savoir comment MySQL traite vos instructions SQL. Analysez les goulots d'étranglement des performances de vos instructions de requête ou de vos structures de table.
➤ Grâce à EXPLAIN, nous pouvons analyser les résultats suivants :
➤ Utilisé comme suit :
EXPLAIN +Instruction SQL
EXPLAIN SELECT * FROM t1
Informations contenues dans le plan d'exécution
Le numéro de séquence de la requête de sélection, y compris un ensemble de nombres, indiquant l'ordre dans lequel la sélection est effectuée. des clauses ou des tables d'opérations sont exécutées dans la requête
résultats id
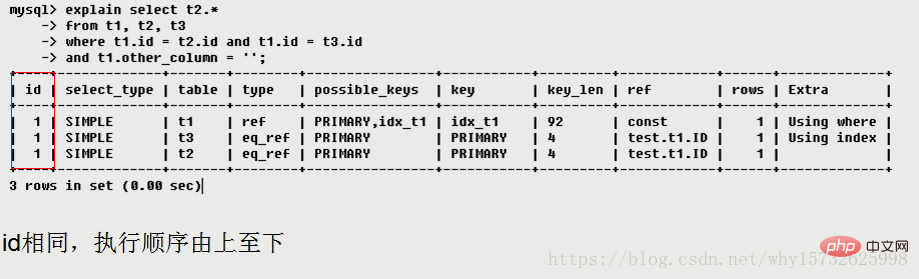
[Résumé] L'ordre de chargement du tableau est tel qu'indiqué dans la colonne du tableau ci-dessus : t1 t3 t2

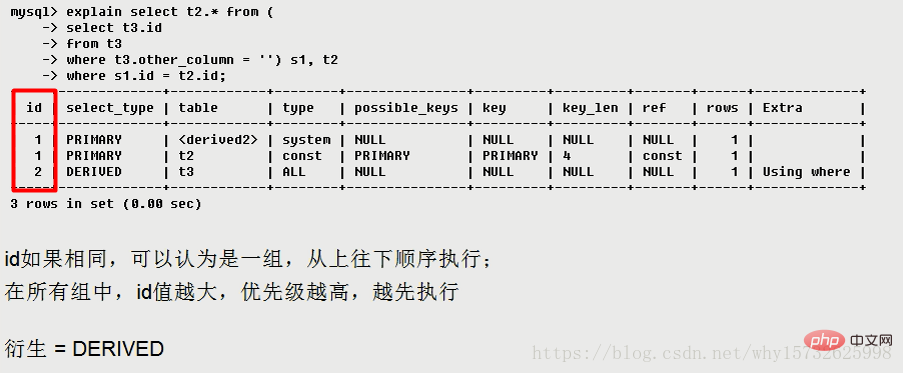 , qui fait référence à la table d'identifiant 2, qui est la table dérivée de la table t3.
, qui fait référence à la table d'identifiant 2, qui est la table dérivée de la table t3. <derived2></derived2>
sont utilisées pour représenter le type de requête respectivement, principalement pour distinguer entre les requêtes complexes ordinaires telles que les requêtes, les requêtes d'union, les sous-requêtes, etc. 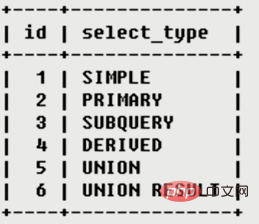
简单的select查询不包含子查询或者UNION
包含任何复杂的 最外层查询则被标记为PRIMARY
在SELECT或WHERE列表中包含了子查询
中子查询被标记为DERIVED结果放在临时表
Type 2.4
Du plus L'ordre du meilleur au pire. est : 
system > const > eq_ref > ref > range > index > all
display Un ou plusieurs index pouvant être appliqués à cette table. Si un index existe sur le champ impliqué dans la requête, l'index sera répertorié . La valeur affichée par key_len est la longueur maximale possible du champ d'index, et non la longueur réelle utilisée. Autrement dit, key_len est calculée en fonction de la définition de la table et non extraite de la table. 使用了用临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于排序order by和分组查询group by。 表示相应的select操作中使用了覆盖索引(Covering Index),避免访问了表的数据行,效率不错。如果同时出现using where,表明索引被用来执行索引键值的查找;如果没有同时出现using where,表明索引用来读取数据而非执行查找动作。 表明使用了where过滤 表明使用了连接缓存,比如说在查询的时候,多表join的次数非常多,那么将配置文件中的缓冲区的join buffer调大一些。 where子句的值 在没有GROUPBY子句的情况下,基于索引优化MIN/MAX操作或者对于MyISAM存储引擎优化COUNT(*)操作,不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化。 优化distinct操作,在找到第一匹配的元组后即停止找同样值的动作 执行顺序5:代表从UNION的临时表中读取行的阶段,table列的表示用第一个和第四个select的结果进行UNION操作。【两个结果union操作】 推荐学习:mysql教程
2,5 clés et clés possibles system La table n'a qu'une seule ligne d'enregistrements (égale à la table système). Il s'agit d'une colonne spéciale de type const. Elle n'apparaît généralement pas. const Effectuez d'abord une sous-requête pour obtenir un résultat de la table temporaire d1. La condition de sous-requête est id = 1, qui est une constante, donc le type est const. un seul enregistrement, donc le type est système.
Effectuez d'abord une sous-requête pour obtenir un résultat de la table temporaire d1. La condition de sous-requête est id = 1, qui est une constante, donc le type est const. un seul enregistrement, donc le type est système.
eq_ref
ref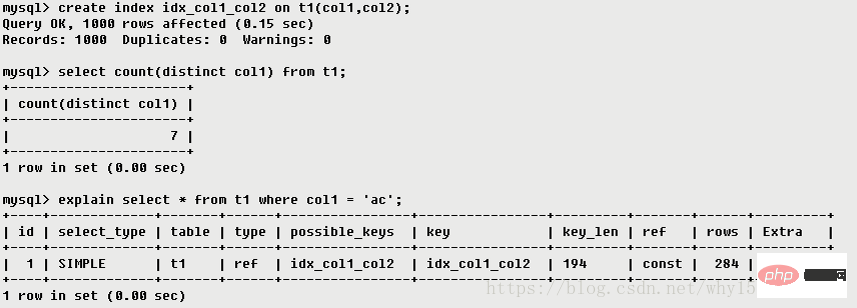
range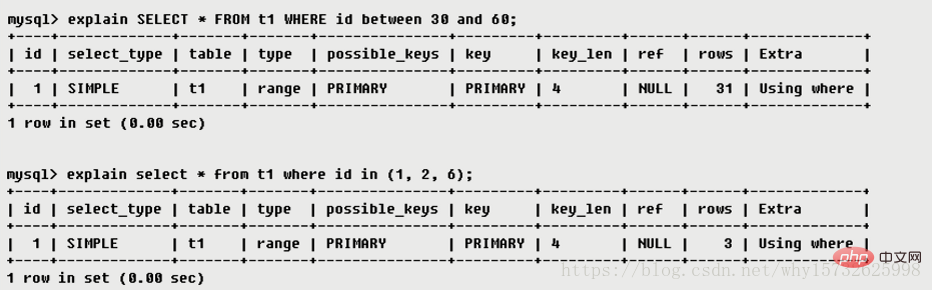
index id est la clé primaire, donc il y a un index de clé primaire
id est la clé primaire, donc il y a un index de clé primaire
all
possible_keys mais ne pourra pas être réellement utilisé par la requête . keyL'index réel utilisé S'il est NULL, aucun index n'est utilisé. (Les raisons possibles incluent l'absence de création d'index ou l'échec de l'index)
2.6 key_len représente le nombre d'octets utilisés dans l'index , qui peut être calculé via cette colonne La longueur de l'index utilisé dans la requête, en 
覆盖索引

不损失精确性的情况下,长度越短越好

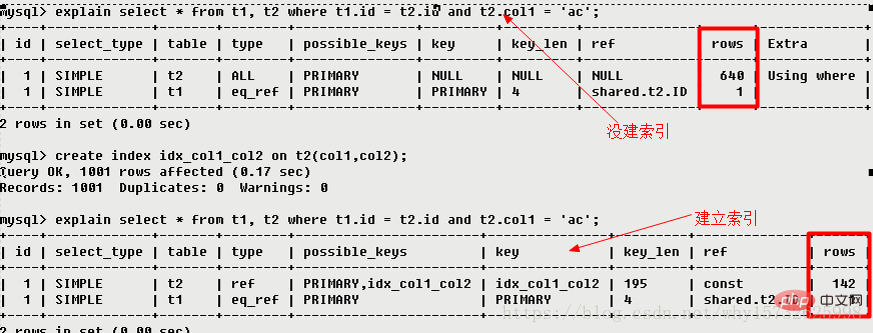
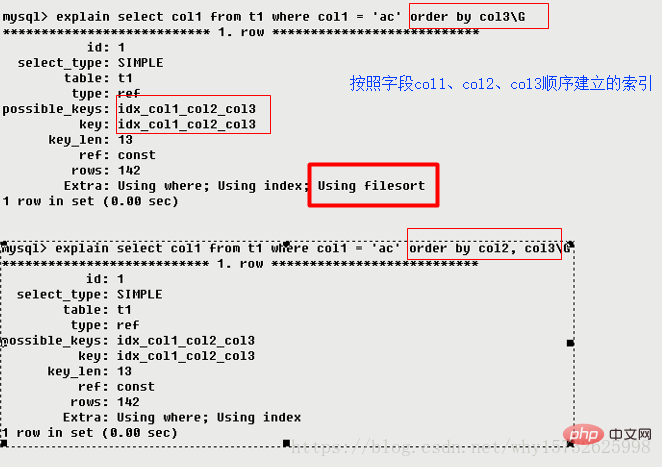
2.9.2 Using temporary(十死无生)
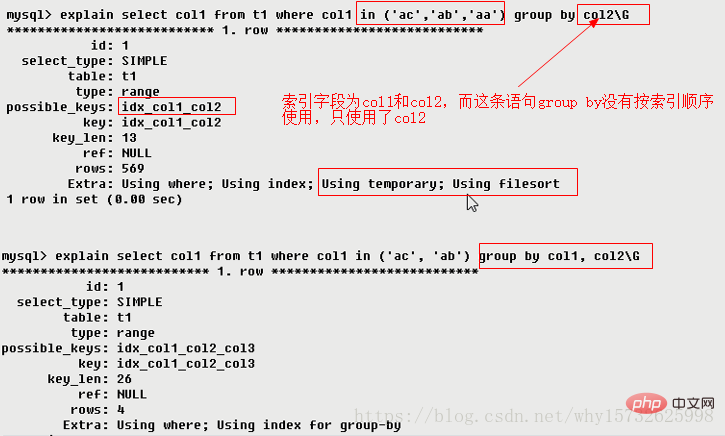
2.9.3 Using index(发财了)


2.9.4 Using where
2.9.5 Using join buffer
2.9.6 impossible where
总是false,不能用来获取任何元组SELECT * FROM t_user WHERE id = '1' and id = '2'
2.9.7 select tables optimized away
2.9.8 distinct
3. 实例分析
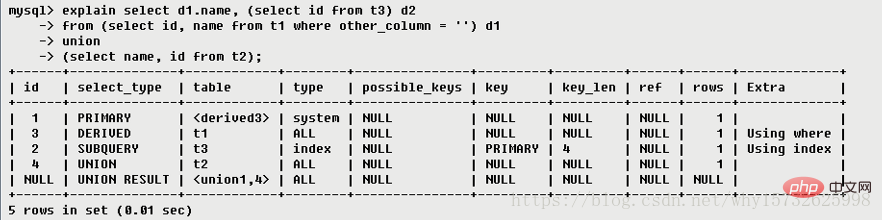
<derived3></derived3>,表示查询结果来自一个衍生表,其中derived3中的3代表该查询衍生自第三个select查询,即id为3的select。【select d1.name …】
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



