
 base de données
Redis
Comment Redis implémente-t-il la file d'attente de retard ? Présentation de la méthode
base de données
Redis
Comment Redis implémente-t-il la file d'attente de retard ? Présentation de la méthode
Comment Redis implémente-t-il la file d'attente de retard ? Présentation de la méthode


La file d'attente de retard, comme son nom l'indique, est une file d'attente de messages avec fonction de retard. Alors, dans quelles circonstances ai-je besoin d’une telle file d’attente ?
1. Contexte
Regardons d'abord le scénario commercial suivant :
- Lorsque la commande a été impayé Comment clôturer une commande dans les délais lorsque le statut est
- Comment vérifier régulièrement si une commande en statut de remboursement a été remboursée avec succès
- Lorsqu'une commande ne reçoit pas de notification d'état de la part du système en aval pendant longtemps, comment Stratégies pour obtenir une synchronisation progressive du statut de la commande
- Lorsque le système informe le système en amont de l'état final du paiement réussi, le système en amont renvoie un échec de notification Comment mettre en œuvre l'asynchrone. notification et envoyez-la à des fréquences divisées : 15s 3m 10m 30m 30m 1h 2h 6h 15h
Solution 1.1
Le plus simple, scannez régulièrement le compteur . Par exemple, si les exigences d'expiration du paiement des commandes sont relativement élevées, le compteur sera scanné toutes les 2 secondes pour vérifier les commandes expirées et clôturer activement les commandes. L'avantage est que c'est simple, L'inconvénient est qu'il analyse la table globalement toutes les minutes, ce qui gaspille des ressources Si le volume de commande des données de la table est sur le point d'expirer est important. , cela entraînera un retard dans la clôture des commandes.
Utilisez RabbitMq ou d'autres modifications de MQ pour implémenter des files d'attente de retard. Les avantages sont qu'il est open source et une solution d'implémentation prête à l'emploi et stable. Les inconvénients sont : MQ est un middleware de messages. . Si la pile technologique de l'équipe est intrinsèquement Si vous avez MQ, ce n'est pas grave. Sinon, c'est un peu coûteux de déployer un ensemble de MQ pour retarder la file d'attente
En utilisant zset et. lister les fonctionnalités de Redis, nous pouvons utiliser Redis pour y parvenir. Une file d'attente de retardRedisDelayQueue
Objectifs de conception.
- Performances en temps réel : les erreurs de deuxième niveau sont autorisées pendant une certaine période de temps
- Haute disponibilité : prend en charge les versions autonomes et en cluster
- Prend en charge la suppression des messages : l'entreprise supprimera les messages spécifiés à tout moment
- Fiabilité des messages : garantie d'être consommée au moins une fois
- Persistance des messages : basée sur les caractéristiques de persistance de Redis lui-même, si les données Redis sont perdues, cela signifie la perte de messages retardés, mais cela peut être utilisé comme sauvegarde principale et garantie de cluster. Cela peut être envisagé pour une optimisation ultérieure afin de conserver les messages dans MangoDB
3 Plan de conception
La conception comprend principalement les points suivants. :
- Utilisez l'intégralité de Redis comme pool de messages et stockez les messages au format KV
- Utilisez ZSET comme file d'attente prioritaire et maintenez la priorité en fonction du score
- Utiliser la structure LIST pour faire progresser la consommation du premier sorti
- ZSET et LIST stockent les adresses de message (correspondant à chaque CLÉ dans le pool de messages)
- Personnalisez l'objet de routage, stockez les noms ZSET et LIST et envoyez messages de point à point de manière point à point, ZSET achemine vers la LISTE correcte
- Utiliser la minuterie pour maintenir le routage
- Mettre en œuvre le délai de message selon les règles TTL
3.1 Schéma de conception
Il est toujours basé sur la conception, l'optimisation et la mise en œuvre du code de la file d'attente de Youzan. Youzan Design 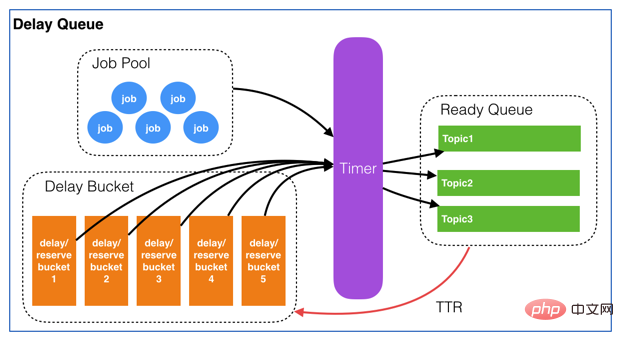
3.2 Structure de données
-
ZING:DELAY_QUEUE:JOB_POOLest une structure Hash_Table, qui stocke des informations sur toutes les files d'attente. Structure KV : K=prefix+projectName field = topic+jobId V=CONENT;VLes données transmises par le client sont renvoyées lorsqu'elles sont consommées -
ZING:DELAY_QUEUE:BUCKETL'ensemble ordonné ZSET de la file d'attente retardée stocke K =ID et l'horodatage d'exécution requis, trié selon l'horodatage -
ZING:DELAY_QUEUE:QUEUEstructure LIST, chaque sujet a une LISTE, et la liste stocke les JOB qui doivent actuellement être consommés
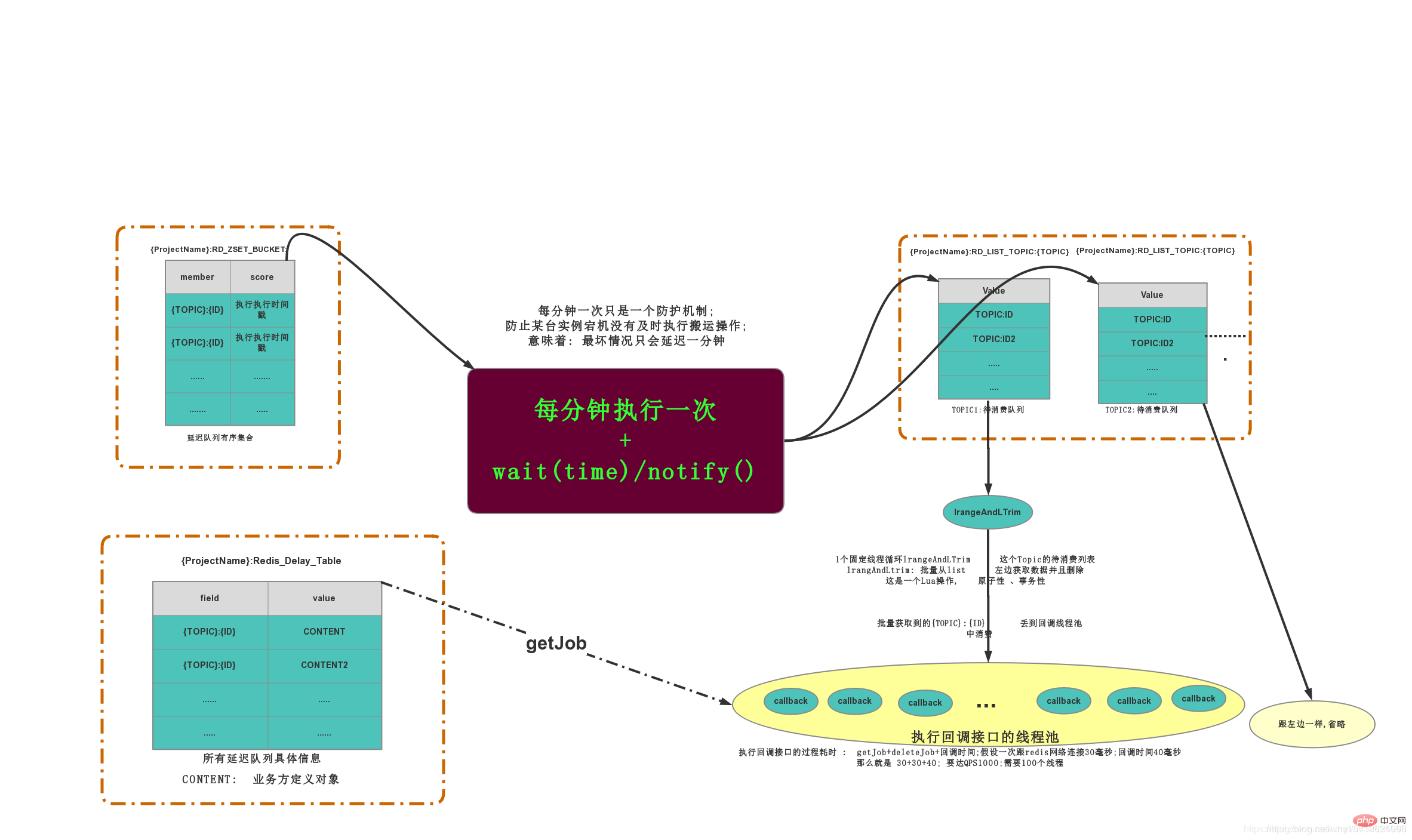
L'Comment Redis implémente-t-il la file dattente de retard ? Présentation de la méthode est à titre de référence uniquement et peut essentiellement décrire l'exécution de l'ensemble du processus. L'Comment Redis implémente-t-il la file dattente de retard ? Présentation de la méthode provient du blog de référence à la fin de l'article
3.3 Vie de la tâche. cycle
- Lorsque vous ajoutez un nouveau JOB, une donnée sera insérée dans
ZING:DELAY_QUEUE:JOB_POOLpour enregistrer le côté commercial et le côté consommateur.ZING:DELAY_QUEUE:BUCKETinsérera également un enregistrement pour enregistrer l'horodatage d'exécution - Le fil de traitement ira à
ZING:DELAY_QUEUE:BUCKETpour trouver quels horodatages d'exécution ont RunTimeMillis plus petit que l'heure actuelle et supprimera tous ces enregistrements en même temps ; temps, il analysera Découvrez quel est le sujet de chaque tâche, puis PUSH ces tâches vers la liste correspondant au SUJETZING:DELAY_QUEUE:QUEUE - Chaque LISTE DE SUJETS aura un fil d'écoute pour obtenir par lots les données à être consommé dans la LISTE, et obtenir Toutes les données reçues sont jetées dans le pool de threads consommateur de ce SUJET
- L'exécution du pool de threads consommateur ira à
ZING:DELAY_QUEUE:JOB_POOLpour trouver la structure de données, la renverra à la structure de rappel, et exécutez la méthode de rappel.
3.4 Points de conception
3.4.1 Concepts de base
- JOB : les tâches qui nécessitent un traitement asynchrone sont les unités de base de la file d'attente de retard
- Sujet : une collection (file d'attente) de tâches du même type. Pour que les consommateurs s'abonnent
3.4.2 Structure du message
Chaque JOB doit contenir les attributs suivants
- jobId : L'identifiant unique du Job. Utilisé pour récupérer et supprimer les informations de tâche spécifiées
- sujet : Type de tâche. Il peut être compris comme un nom commercial spécifique
- délai : le temps pendant lequel le travail doit être retardé. Unité : secondes. (Le serveur le convertira en une heure absolue)
- body : le contenu du Job, permettant aux consommateurs d'effectuer des traitements métier spécifiques, stocké au format json
- retry : le nombre de tentatives échouées
- url : URL de notification
3.5 Détails de conception
3.5.1 Comment à consommer rapidement ZING:DELAY_QUEUE:QUEUE
Le moyen le plus simple de le mettre en œuvre est d'utiliser une minuterie pour l'analyse de deuxième niveau afin de garantir la rapidité d'exécution des messages. , vous pouvez définir une demande pour Redis tous les 1S et déterminer s'il y a des JOB à consommer dans la file d'attente. Mais il y aura un problème. S'il n'y a pas de JOB consommables dans la file d'attente, une analyse fréquente n'aura aucun sens et constituera un gaspillage de ressources. Heureusement, il y a un BLPOP阻塞原语 dans la LISTE, ce sera le cas. être renvoyé immédiatement.S'il n'y a pas de données, elles y seront bloquées jusqu'à ce que les données soient renvoyées. Vous pouvez définir le délai d'expiration du blocage, et NULL sera renvoyé après le délai d'attente ; les méthodes et stratégies d'implémentation spécifiques seront introduites dans le code
3.5.2 Évitez la gestion et la consommation répétées des messages causées par le timing
- Utilisez le verrou distribué de Redis pour contrôler la gestion des messages, évitant ainsi traitement répété des messages. Le problème
- Utiliser des verrous distribués pour assurer la fréquence d'exécution des minuteries
Implémentation du code de base
4.1 Description technique
Pile technologique : SpringBoot, Redisson, Redis, verrouillage distribué, minuterieRemarque : Ce projet n'a pas pris en compte la consommation de plusieurs files d'attente dans le plan de conception et n'a ouvert qu'une seule QUEUE. Celle-ci sera optimisée à l'avenir
4.2 Core Entity
4.2.1 Le travail ajoute des objets/**
* 消息结构
*
* @author 睁眼看世界
* @date 2020年1月15日
*/
@Data
public class Job implements Serializable {
private static final long serialVersionUID = 1L;
/**
* Job的唯一标识。用来检索和删除指定的Job信息
*/
@NotBlank
private String jobId;
/**
* Job类型。可以理解成具体的业务名称
*/
@NotBlank
private String topic;
/**
* Job需要延迟的时间。单位:秒。(服务端会将其转换为绝对时间)
*/
private Long delay;
/**
* Job的内容,供消费者做具体的业务处理,以json格式存储
*/
@NotBlank
private String body;
/**
* 失败重试次数
*/
private int retry = 0;
/**
* 通知URL
*/
@NotBlank
private String url;
}
4.2.2 Le travail supprime des objets /**
* 消息结构
*
* @author 睁眼看世界
* @date 2020年1月15日
*/
@Data
public class JobDie implements Serializable {
private static final long serialVersionUID = 1L;
/**
* Job的唯一标识。用来检索和删除指定的Job信息
*/
@NotBlank
private String jobId;
/**
* Job类型。可以理解成具体的业务名称
*/
@NotBlank
private String topic;
}
4.3 Fil de manipulation/**
* 搬运线程
*
* @author 睁眼看世界
* @date 2020年1月17日
*/
@Slf4j
@Component
public class CarryJobScheduled {
@Autowired
private RedissonClient redissonClient;
/**
* 启动定时开启搬运JOB信息
*/
@Scheduled(cron = "*/1 * * * * *")
public void carryJobToQueue() {
System.out.println("carryJobToQueue --->");
RLock lock = redissonClient.getLock(RedisQueueKey.CARRY_THREAD_LOCK);
try {
boolean lockFlag = lock.tryLock(LOCK_WAIT_TIME, LOCK_RELEASE_TIME, TimeUnit.SECONDS);
if (!lockFlag) {
throw new BusinessException(ErrorMessageEnum.ACQUIRE_LOCK_FAIL);
}
RScoredSortedSet<object> bucketSet = redissonClient.getScoredSortedSet(RD_ZSET_BUCKET_PRE);
long now = System.currentTimeMillis();
Collection<object> jobCollection = bucketSet.valueRange(0, false, now, true);
List<string> jobList = jobCollection.stream().map(String::valueOf).collect(Collectors.toList());
RList<string> readyQueue = redissonClient.getList(RD_LIST_TOPIC_PRE);
readyQueue.addAll(jobList);
bucketSet.removeAllAsync(jobList);
} catch (InterruptedException e) {
log.error("carryJobToQueue error", e);
} finally {
if (lock != null) {
lock.unlock();
}
}
}
}</string></string></object></object>
4.4 Fil de consommation@Slf4j
@Component
public class ReadyQueueContext {
@Autowired
private RedissonClient redissonClient;
@Autowired
private ConsumerService consumerService;
/**
* TOPIC消费线程
*/
@PostConstruct
public void startTopicConsumer() {
TaskManager.doTask(this::runTopicThreads, "开启TOPIC消费线程");
}
/**
* 开启TOPIC消费线程
* 将所有可能出现的异常全部catch住,确保While(true)能够不中断
*/
@SuppressWarnings("InfiniteLoopStatement")
private void runTopicThreads() {
while (true) {
RLock lock = null;
try {
lock = redissonClient.getLock(CONSUMER_TOPIC_LOCK);
} catch (Exception e) {
log.error("runTopicThreads getLock error", e);
}
try {
if (lock == null) {
continue;
}
// 分布式锁时间比Blpop阻塞时间多1S,避免出现释放锁的时候,锁已经超时释放,unlock报错
boolean lockFlag = lock.tryLock(LOCK_WAIT_TIME, LOCK_RELEASE_TIME, TimeUnit.SECONDS);
if (!lockFlag) {
continue;
}
// 1. 获取ReadyQueue中待消费的数据
RBlockingQueue<string> queue = redissonClient.getBlockingQueue(RD_LIST_TOPIC_PRE);
String topicId = queue.poll(60, TimeUnit.SECONDS);
if (StringUtils.isEmpty(topicId)) {
continue;
}
// 2. 获取job元信息内容
RMap<string> jobPoolMap = redissonClient.getMap(JOB_POOL_KEY);
Job job = jobPoolMap.get(topicId);
// 3. 消费
FutureTask<boolean> taskResult = TaskManager.doFutureTask(() -> consumerService.consumerMessage(job.getUrl(), job.getBody()), job.getTopic() + "-->消费JobId-->" + job.getJobId());
if (taskResult.get()) {
// 3.1 消费成功,删除JobPool和DelayBucket的job信息
jobPoolMap.remove(topicId);
} else {
int retrySum = job.getRetry() + 1;
// 3.2 消费失败,则根据策略重新加入Bucket
// 如果重试次数大于5,则将jobPool中的数据删除,持久化到DB
if (retrySum > RetryStrategyEnum.RETRY_FIVE.getRetry()) {
jobPoolMap.remove(topicId);
continue;
}
job.setRetry(retrySum);
long nextTime = job.getDelay() + RetryStrategyEnum.getDelayTime(job.getRetry()) * 1000;
log.info("next retryTime is [{}]", DateUtil.long2Str(nextTime));
RScoredSortedSet<object> delayBucket = redissonClient.getScoredSortedSet(RedisQueueKey.RD_ZSET_BUCKET_PRE);
delayBucket.add(nextTime, topicId);
// 3.3 更新元信息失败次数
jobPoolMap.put(topicId, job);
}
} catch (Exception e) {
log.error("runTopicThreads error", e);
} finally {
if (lock != null) {
try {
lock.unlock();
} catch (Exception e) {
log.error("runTopicThreads unlock error", e);
}
}
}
}
}
}</object></boolean></string></string>
4.5 Ajouter et supprimer JOB/**
* 提供给外部服务的操作接口
*
* @author why
* @date 2020年1月15日
*/
@Slf4j
@Service
public class RedisDelayQueueServiceImpl implements RedisDelayQueueService {
@Autowired
private RedissonClient redissonClient;
/**
* 添加job元信息
*
* @param job 元信息
*/
@Override
public void addJob(Job job) {
RLock lock = redissonClient.getLock(ADD_JOB_LOCK + job.getJobId());
try {
boolean lockFlag = lock.tryLock(LOCK_WAIT_TIME, LOCK_RELEASE_TIME, TimeUnit.SECONDS);
if (!lockFlag) {
throw new BusinessException(ErrorMessageEnum.ACQUIRE_LOCK_FAIL);
}
String topicId = RedisQueueKey.getTopicId(job.getTopic(), job.getJobId());
// 1. 将job添加到 JobPool中
RMap<string> jobPool = redissonClient.getMap(RedisQueueKey.JOB_POOL_KEY);
if (jobPool.get(topicId) != null) {
throw new BusinessException(ErrorMessageEnum.JOB_ALREADY_EXIST);
}
jobPool.put(topicId, job);
// 2. 将job添加到 DelayBucket中
RScoredSortedSet<object> delayBucket = redissonClient.getScoredSortedSet(RedisQueueKey.RD_ZSET_BUCKET_PRE);
delayBucket.add(job.getDelay(), topicId);
} catch (InterruptedException e) {
log.error("addJob error", e);
} finally {
if (lock != null) {
lock.unlock();
}
}
}
/**
* 删除job信息
*
* @param job 元信息
*/
@Override
public void deleteJob(JobDie jobDie) {
RLock lock = redissonClient.getLock(DELETE_JOB_LOCK + jobDie.getJobId());
try {
boolean lockFlag = lock.tryLock(LOCK_WAIT_TIME, LOCK_RELEASE_TIME, TimeUnit.SECONDS);
if (!lockFlag) {
throw new BusinessException(ErrorMessageEnum.ACQUIRE_LOCK_FAIL);
}
String topicId = RedisQueueKey.getTopicId(jobDie.getTopic(), jobDie.getJobId());
RMap<string> jobPool = redissonClient.getMap(RedisQueueKey.JOB_POOL_KEY);
jobPool.remove(topicId);
RScoredSortedSet<object> delayBucket = redissonClient.getScoredSortedSet(RedisQueueKey.RD_ZSET_BUCKET_PRE);
delayBucket.remove(topicId);
} catch (InterruptedException e) {
log.error("addJob error", e);
} finally {
if (lock != null) {
lock.unlock();
}
}
}
}</object></string></object></string>
5. Contenu à optimiser
Actuellement, il n'y a qu'une seule file d'attente. La file d'attente stocke les messages. Lorsqu'un grand nombre de messages devant être consommés s'accumulent, la rapidité des notifications de messages sera affectée. La méthode d'amélioration consiste à ouvrir plusieurs files d'attente, à effectuer le routage des messages, puis à ouvrir plusieurs threads consommateurs pour la consommation afin de fournir un débit- Le message n'est pas conservé, ce qui est risqué. Le message sera conservé dans MangoDB à l'avenir. .
6. Code sourceVeuillez obtenir un code source plus détaillé à l'adresse ci-dessous
- zing-delay-queue (https://gitee.com/whyCodeData/zing-project/tree/master/zing-delay-queue)
RedisDelayQueue实现 redisson-spring-boot-starter (https://gitee.com/whyCodeData/zing-project/tree/master/zing-starter/redisson-spring-boot-starter) RedissonStarter zing-pay (https://gitee. com/ WhyCodeData/zing-pay)项目应用
7. Référence
https://tech.youzan.com /queuing_delay /- https://blog.csdn.net/u010634066/article/details/98864764
- Pour plus de connaissances sur Redis, veuillez prêter attention à :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données Redis: utilisez la commande flushall pour effacer toutes les valeurs de clé. Utilisez la commande flushdb pour effacer la valeur clé de la base de données actuellement sélectionnée. Utilisez SELECT pour commuter les bases de données, puis utilisez FlushDB pour effacer plusieurs bases de données. Utilisez la commande del pour supprimer une clé spécifique. Utilisez l'outil Redis-CLI pour effacer les données.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
L'utilisation des opérations Redis pour verrouiller nécessite l'obtention du verrouillage via la commande setnx, puis en utilisant la commande Expire pour définir le temps d'expiration. Les étapes spécifiques sont les suivantes: (1) Utilisez la commande setnx pour essayer de définir une paire de valeurs de clé; (2) Utilisez la commande Expire pour définir le temps d'expiration du verrou; (3) Utilisez la commande del pour supprimer le verrouillage lorsque le verrouillage n'est plus nécessaire.
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment configurer le temps d'exécution du script LUA dans Centos Redis
Apr 14, 2025 pm 02:12 PM
Comment configurer le temps d'exécution du script LUA dans Centos Redis
Apr 14, 2025 pm 02:12 PM
Sur CentOS Systems, vous pouvez limiter le temps d'exécution des scripts LUA en modifiant les fichiers de configuration Redis ou en utilisant des commandes Redis pour empêcher les scripts malveillants de consommer trop de ressources. Méthode 1: Modifiez le fichier de configuration Redis et localisez le fichier de configuration Redis: le fichier de configuration redis est généralement situé dans /etc/redis/redis.conf. Edit Fichier de configuration: Ouvrez le fichier de configuration à l'aide d'un éditeur de texte (tel que VI ou NANO): Sudovi / etc / redis / redis.conf Définissez le délai d'exécution du script LUA: Ajouter ou modifier les lignes suivantes dans le fichier de configuration pour définir le temps d'exécution maximal du script LUA (unité: millisecondes)
 Comment utiliser la ligne de commande redis
Apr 10, 2025 pm 10:18 PM
Comment utiliser la ligne de commande redis
Apr 10, 2025 pm 10:18 PM
Utilisez l'outil de ligne de commande redis (Redis-CLI) pour gérer et utiliser Redis via les étapes suivantes: Connectez-vous au serveur, spécifiez l'adresse et le port. Envoyez des commandes au serveur à l'aide du nom et des paramètres de commande. Utilisez la commande d'aide pour afficher les informations d'aide pour une commande spécifique. Utilisez la commande QUIT pour quitter l'outil de ligne de commande.
