
 développement back-end
Tutoriel Python
Apprenez à utiliser Python pour capturer des vidéos avec des réponses spécifiées sur Zhihu
développement back-end
Tutoriel Python
Apprenez à utiliser Python pour capturer des vidéos avec des réponses spécifiées sur Zhihu
Apprenez à utiliser Python pour capturer des vidéos avec des réponses spécifiées sur Zhihu


Avant-propos
Maintenant, Zhihu permet de télécharger des vidéos, mais je ne peux pas télécharger de vidéos, je suis tellement en colère. . J'ai fait des recherches en désespoir de cause. Au bout d'un moment, j'ai tapé le code pour faciliter le téléchargement et l'enregistrement de la vidéo.
Ensuite, pourquoi les chats n'ont-ils pas du tout peur des serpents ? Répondez à titre d'exemple et partagez l'intégralité du processus de téléchargement.
Recommandations d'apprentissage associées : Tutoriel vidéo Python
Déboguer
Ouvrir F12 , recherchez le curseur, comme indiqué ci-dessous :
puis déplacez le curseur sur la vidéo. Comme indiqué ci-dessous :
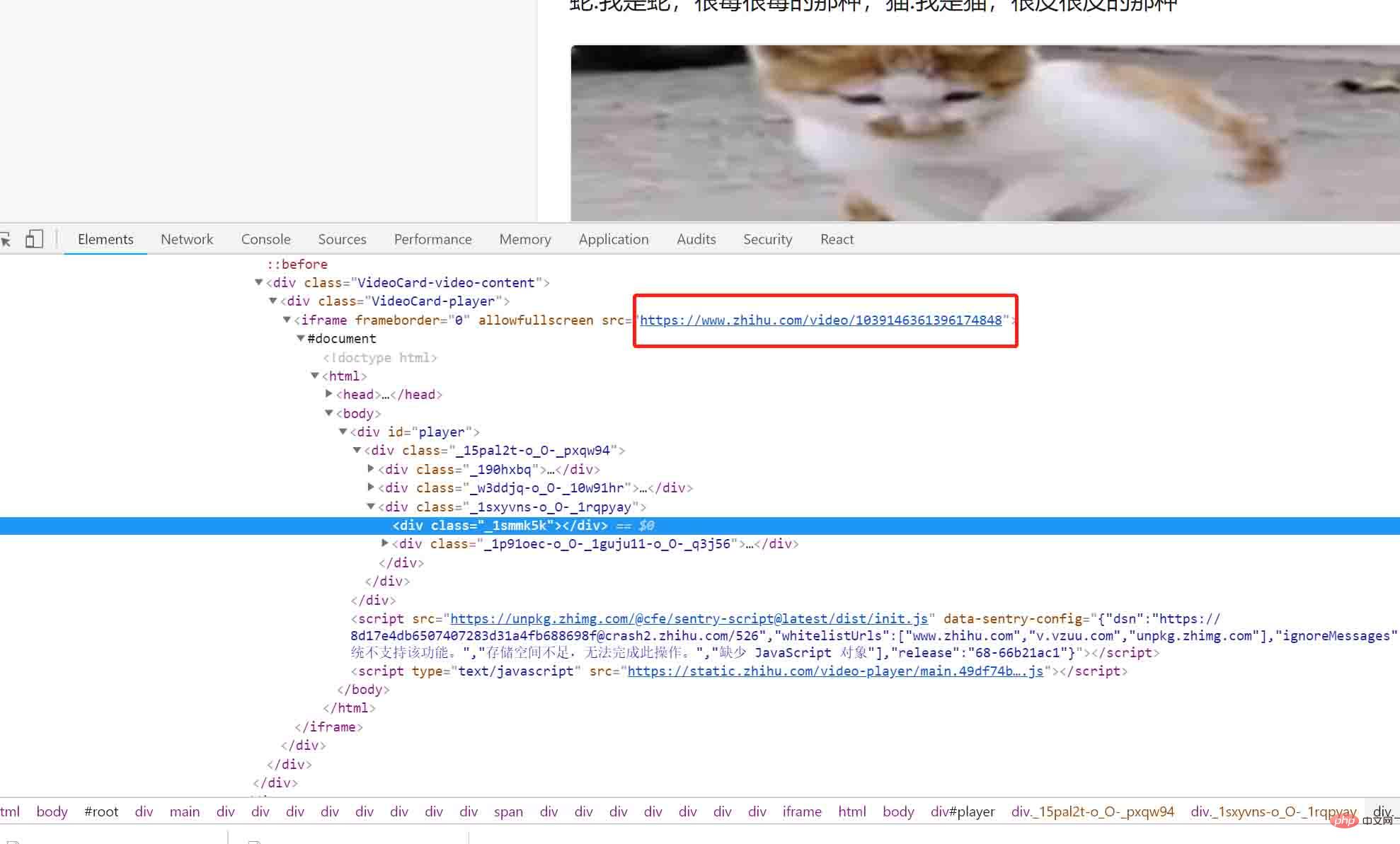
Hé, qu'est-ce que c'est ? Un lien mystérieux est apparu dans le champ de vision : https://www.zhihu.com/video/xxxxx, copions ce lien dans le navigateur, puis ouvrons :
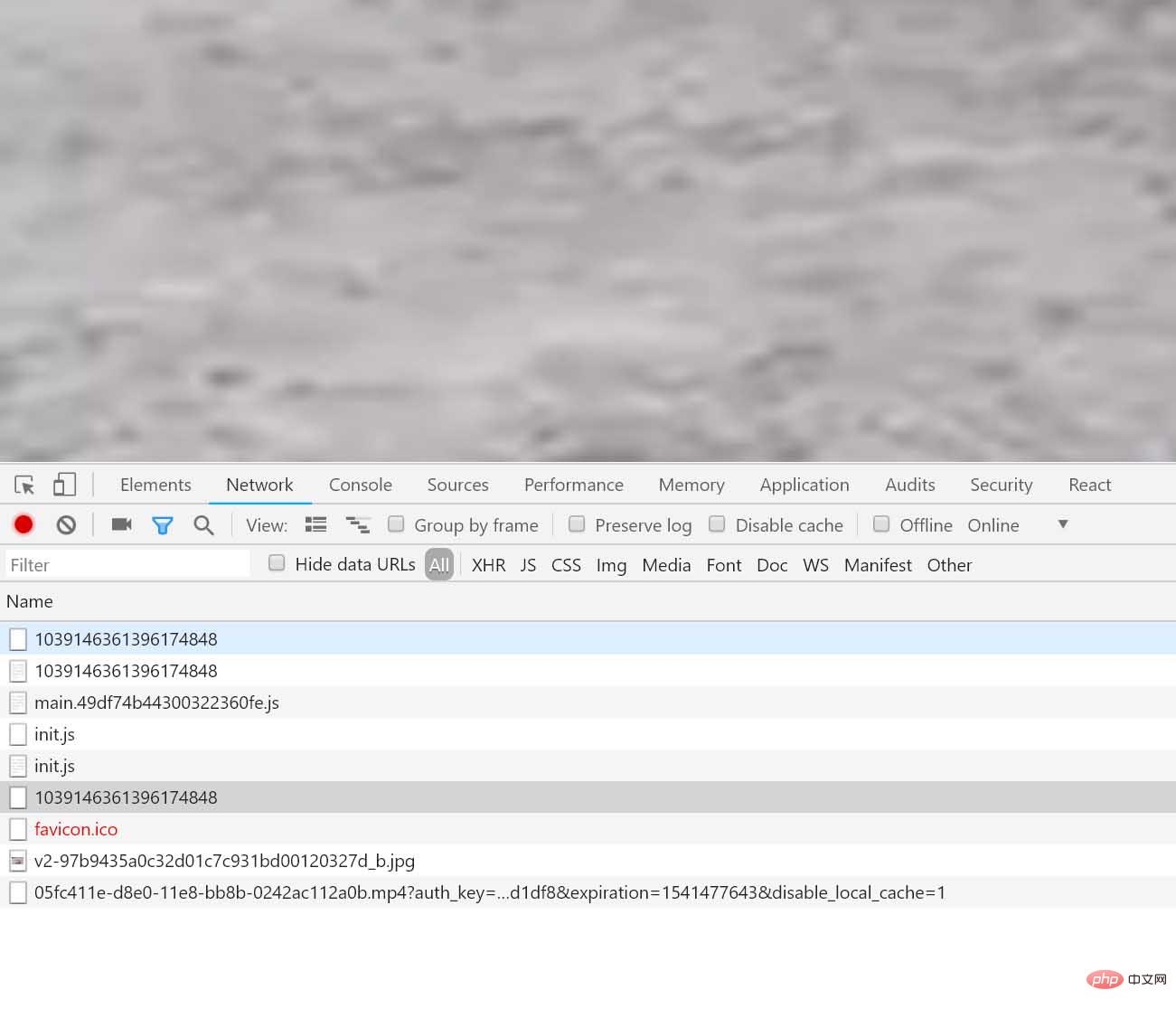
Il semble que ce soit la vidéo que nous recherchons, ne vous inquiétez pas, jetons un coup d'œil à la demande de la page Web, et vous trouverez ensuite une demande très intéressante (voici le focus) :
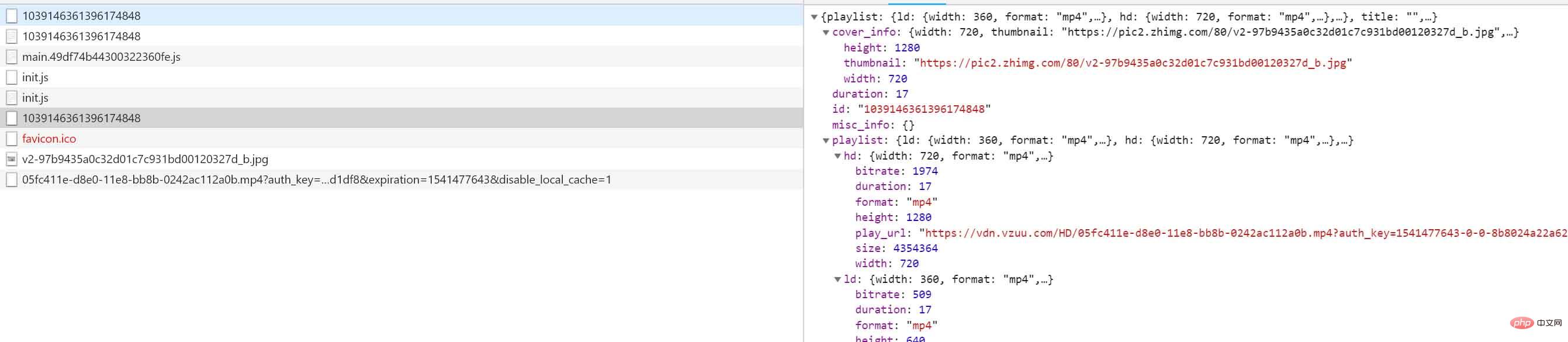
Jetons un coup d'œil aux données nous-mêmes :
{
"playlist": {
"ld": {
"width": 360,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/LD/05fc411e-d8e0-11e8-bb8b-0242ac112a0b.mp4?auth_key=1541477643-0-0-987c2c504d14ab1165ce2ed47759d927&expiration=1541477643&disable_local_cache=1",
"duration": 17,
"size": 1123111,
"bitrate": 509,
"height": 640
},
"hd": {
"width": 720,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/HD/05fc411e-d8e0-11e8-bb8b-0242ac112a0b.mp4?auth_key=1541477643-0-0-8b8024a22a62f097ca31b8b06b7233a1&expiration=1541477643&disable_local_cache=1",
"duration": 17,
"size": 4354364,
"bitrate": 1974,
"height": 1280
},
"sd": {
"width": 480,
"format": "mp4",
"play_url": "https://vdn.vzuu.com/SD/05fc411e-d8e0-11e8-bb8b-0242ac112a0b.mp4?auth_key=1541477643-0-0-5948c2562d817218c9a9fc41abad1df8&expiration=1541477643&disable_local_cache=1",
"duration": 17,
"size": 1920976,
"bitrate": 871,
"height": 848
}
},
"title": "",
"duration": 17,
"cover_info": {
"width": 720,
"thumbnail": "https://pic2.zhimg.com/80/v2-97b9435a0c32d01c7c931bd00120327d_b.jpg",
"height": 1280
},
"type": "video",
"id": "1039146361396174848",
"misc_info": {}
}C'est vrai, la vidéo que nous voulons télécharger se trouve dedans, où ld signifie définition commune, sd signifie pour définition standard, et hd signifie haute définition. Mettez le correspondant Ouvrez à nouveau le lien dans le navigateur, puis cliquez avec le bouton droit et enregistrez pour télécharger la vidéo.
Code
Une fois que vous savez à quoi ressemble l'ensemble du processus, le prochain processus de codage est simple. Je n'expliquerai pas trop ici, allez simplement au. code :
# -*- encoding: utf-8 -*-
import re
import requests
import uuid
import datetime
class DownloadVideo:
__slots__ = [
'url', 'video_name', 'url_format', 'download_url', 'video_number',
'video_api', 'clarity_list', 'clarity'
]
def __init__(self, url, clarity='ld', video_name=None):
self.url = url
self.video_name = video_name
self.url_format = "https://www.zhihu.com/question/\d+/answer/\d+"
self.clarity = clarity
self.clarity_list = ['ld', 'sd', 'hd']
self.video_api = 'https://lens.zhihu.com/api/videos'
def check_url_format(self):
pattern = re.compile(self.url_format)
matches = re.match(pattern, self.url)
if matches is None:
raise ValueError(
"链接格式应符合:https://www.zhihu.com/question/{number}/answer/{number}"
)
return True
def get_video_number(self):
try:
headers = {
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
response = requests.get(self.url, headers=headers)
response.encoding = 'utf-8'
html = response.text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
if video_ids:
video_id_list = list(set([video_id for video_id in video_ids]))
self.video_number = video_id_list[0]
return self
raise ValueError("获取视频编号异常:{}".format(self.url))
except Exception as e:
raise Exception(e)
def get_video_url_by_number(self):
url = "{}/{}".format(self.video_api, self.video_number)
headers = {}
headers['Referer'] = 'https://v.vzuu.com/video/{}'.format(
self.video_number)
headers['Origin'] = 'https://v.vzuu.com'
headers[
'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
headers['Content-Type'] = 'application/json'
try:
response = requests.get(url, headers=headers)
response_dict = response.json()
if self.clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
else:
for clarity in self.clarity_list:
if clarity in response_dict['playlist']:
self.download_url = response_dict['playlist'][
self.clarity]['play_url']
break
return self
except Exception as e:
raise Exception(e)
def get_video_by_video_url(self):
response = requests.get(self.download_url)
datetime_str = datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
if self.video_name is not None:
video_name = "{}-{}.mp4".format(self.video_name, datetime_str)
else:
video_name = "{}-{}.mp4".format(str(uuid.uuid1()), datetime_str)
path = "{}".format(video_name)
with open(path, 'wb') as f:
f.write(response.content)
def download_video(self):
if self.clarity not in self.clarity_list:
raise ValueError("清晰度参数异常,仅支持:ld(普清),sd(标清),hd(高清)")
if self.check_url_format():
return self.get_video_number().get_video_url_by_number().get_video_by_video_url()
if __name__ == '__main__':
a = DownloadVideo('https://www.zhihu.com/question/53031925/answer/524158069')
print(a.download_video())Conclusion
Le code a encore de la place pour l'optimisation. Je viens de télécharger la première vidéo de la réponse. En théorie, il devrait y avoir une réponse qui peut. avoir plus d'une vidéo. Si vous avez encore des questions ou des suggestions, vous pouvez communiquer avec nous.
Recommandations d'apprentissage associées : Tutoriel vidéo Python
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment utiliser les journaux Debian Apache pour améliorer les performances du site Web
Apr 12, 2025 pm 11:36 PM
Comment utiliser les journaux Debian Apache pour améliorer les performances du site Web
Apr 12, 2025 pm 11:36 PM
Cet article expliquera comment améliorer les performances du site Web en analysant les journaux Apache dans le système Debian. 1. Bases de l'analyse du journal APACH LOG enregistre les informations détaillées de toutes les demandes HTTP, y compris l'adresse IP, l'horodatage, l'URL de la demande, la méthode HTTP et le code de réponse. Dans Debian Systems, ces journaux sont généralement situés dans les répertoires /var/log/apache2/access.log et /var/log/apache2/error.log. Comprendre la structure du journal est la première étape d'une analyse efficace. 2.
 Python: jeux, GUIS, et plus
Apr 13, 2025 am 12:14 AM
Python: jeux, GUIS, et plus
Apr 13, 2025 am 12:14 AM
Python excelle dans les jeux et le développement de l'interface graphique. 1) Le développement de jeux utilise Pygame, fournissant des fonctions de dessin, audio et d'autres fonctions, qui conviennent à la création de jeux 2D. 2) Le développement de l'interface graphique peut choisir Tkinter ou Pyqt. Tkinter est simple et facile à utiliser, PYQT a des fonctions riches et convient au développement professionnel.
 PHP et Python: comparaison de deux langages de programmation populaires
Apr 14, 2025 am 12:13 AM
PHP et Python: comparaison de deux langages de programmation populaires
Apr 14, 2025 am 12:13 AM
PHP et Python ont chacun leurs propres avantages et choisissent en fonction des exigences du projet. 1.Php convient au développement Web, en particulier pour le développement rapide et la maintenance des sites Web. 2. Python convient à la science des données, à l'apprentissage automatique et à l'intelligence artificielle, avec syntaxe concise et adaptée aux débutants.
 Le rôle de Debian Sniffer dans la détection des attaques DDOS
Apr 12, 2025 pm 10:42 PM
Le rôle de Debian Sniffer dans la détection des attaques DDOS
Apr 12, 2025 pm 10:42 PM
Cet article traite de la méthode de détection d'attaque DDOS. Bien qu'aucun cas d'application directe de "Debiansniffer" n'ait été trouvé, les méthodes suivantes ne peuvent être utilisées pour la détection des attaques DDOS: technologie de détection d'attaque DDOS efficace: détection basée sur l'analyse du trafic: identification des attaques DDOS en surveillant des modèles anormaux de trafic réseau, tels que la croissance soudaine du trafic, une surtension dans des connexions sur des ports spécifiques, etc. Par exemple, les scripts Python combinés avec les bibliothèques Pyshark et Colorama peuvent surveiller le trafic réseau en temps réel et émettre des alertes. Détection basée sur l'analyse statistique: en analysant les caractéristiques statistiques du trafic réseau, telles que les données
 Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
La fonction ReadDir dans le système Debian est un appel système utilisé pour lire le contenu des répertoires et est souvent utilisé dans la programmation C. Cet article expliquera comment intégrer ReadDir avec d'autres outils pour améliorer sa fonctionnalité. Méthode 1: combinant d'abord le programme de langue C et le pipeline, écrivez un programme C pour appeler la fonction readdir et sortir le résultat: # include # include # include # includeIntmain (intargc, char * argv []) {dir * dir; structDirent * entrée; if (argc! = 2) {
 Certificat NGINX SSL Mise à jour du tutoriel Debian
Apr 13, 2025 am 07:21 AM
Certificat NGINX SSL Mise à jour du tutoriel Debian
Apr 13, 2025 am 07:21 AM
Cet article vous guidera sur la façon de mettre à jour votre certificat NGINXSSL sur votre système Debian. Étape 1: Installez d'abord CERTBOT, assurez-vous que votre système a des packages CERTBOT et Python3-CERTBOT-NGINX installés. Si ce n'est pas installé, veuillez exécuter la commande suivante: Sudoapt-getUpDaSuDoapt-GetInstallCertBotpyThon3-Certerbot-Nginx Étape 2: Obtenez et configurez le certificat Utilisez la commande Certbot pour obtenir le certificat LETSCRYPT et configure
 Python et temps: tirer le meilleur parti de votre temps d'étude
Apr 14, 2025 am 12:02 AM
Python et temps: tirer le meilleur parti de votre temps d'étude
Apr 14, 2025 am 12:02 AM
Pour maximiser l'efficacité de l'apprentissage de Python dans un temps limité, vous pouvez utiliser les modules DateTime, Time et Schedule de Python. 1. Le module DateTime est utilisé pour enregistrer et planifier le temps d'apprentissage. 2. Le module de temps aide à définir l'étude et le temps de repos. 3. Le module de planification organise automatiquement des tâches d'apprentissage hebdomadaires.
 Comment configurer le serveur HTTPS dans Debian OpenSSL
Apr 13, 2025 am 11:03 AM
Comment configurer le serveur HTTPS dans Debian OpenSSL
Apr 13, 2025 am 11:03 AM
La configuration d'un serveur HTTPS sur un système Debian implique plusieurs étapes, notamment l'installation du logiciel nécessaire, la génération d'un certificat SSL et la configuration d'un serveur Web (tel qu'Apache ou Nginx) pour utiliser un certificat SSL. Voici un guide de base, en supposant que vous utilisez un serveur Apacheweb. 1. Installez d'abord le logiciel nécessaire, assurez-vous que votre système est à jour et installez Apache et OpenSSL: SudoaptupDaSuDoaptupgradeSudoaptinsta
