

Opérations Python pour les tableaux Excel
Comment utiliser Python pour créer des tableaux Excel : utilisez d'abord le module openpyxl pour ouvrir un document Excel, spécifiez les informations de cellule des lignes et des colonnes, puis appelez [wb.sheetnames] et [wb.active] pour obtenir les détails du classeur ; Enfin, utilisez la lecture d'index pour obtenir l'objet Cell.

1 tableau python et Excel
Excel est un tableur populaire et puissant dans l'environnement Windows. Le module openpyxl permet aux programmes Python de lire et de modifier des fichiers de feuille de calcul Excel
1) Définition de base du document Excel
- classeur (classeur)
- feuille de calcul (feuille)
- feuille active (feuille active)
- ligne : 1,2,3,4,5,6……..
- colonne : A,B,C,D……..
- Cellule (cellule) : B1, C1
2) Il existe de nombreux modules python pour les opérations sur les tables Excel. Le module openpyxl est sélectionné ici
, mais le module openpyxl doit être installé
pip install openpyxl
Utilisez la commande ci-dessus pour installer le module openpyxl
Il s'agit du tableau sélectionné pour l'opération
1> Ouvrir un document Excel
import openpyxl# 1. 打开一个excel文档, class 'openpyxl.workbook.workbook.Workbook'实例化出来的对象wb = openpyxl.load_workbook('Book.xlsx') print(wb, type(wb))# 获取当前工作薄里所有的工作表,和正在使用的表;print(wb.sheetnames) print(wb.active)

La sortie est un objet
2> la feuille de calcul à utiliser
# 2.选择要操作的工作表,返回工作表对象sheet=wb['Sheet1'] #获取工作表的名称print(sheet.title)

3> Spécifiez les informations de cellule de la ligne et de la colonne spécifiées
# 3. 返回指定行指定列的单元格信息print(sheet.cell(row=1, column=2).value) cell = sheet['B1']print(cell)print(cell.row, cell.column, cell.value)

4> lignes et colonnes de la feuille de calcul
# 4. 获取工作表中行和列的最大值print(sheet.max_column)print(sheet.max_row) sheet.title = '学生信息'print(sheet.title)

5> Accéder à toutes les informations de la cellule
# 5. 访问单元格的所有信息print(sheet.rows) # 返回一个生成器, 包含文件的每一行内容, 可以通过便利访问. # 循环遍历每一行for row in sheet.rows: # 循环遍历每一个单元格for cell in row: # 获取单元格的内容 print(cell.value, end=',') print()

6> 🎜>
Ainsi, le fonctionnement des tableaux Excel peut être résumé en détail comme suit :  1. Importez le module openpyxl.
1. Importez le module openpyxl.
2. Appelez la fonction openpyxl.load_workbook().
3. Obtenez l'objet Workbook.
4. Appelez wb.sheetnames et wb.active pour obtenir les détails du classeur.
5. Obtenez l'objet Feuille de calcul.
6. Utilisez la méthode cell() de l'index ou de la feuille de calcul avec les paramètres de mot-clé de ligne et de colonne.
7. Obtenez l'objet Cell.
8. Lire l'attribut value de l'objet Cell
2 Exemple simple Excel
- Définir une fonction, readwb(wbname, sheetname=None) - Si l'utilisateur le précise sheetname Ouvrez la feuille de calcul spécifiée par l'utilisateur. Si elle n'est pas spécifiée, ouvrez la feuille active
- Triez selon le prix du produit (du petit au grand) et enregistrez-la dans le fichier : Prix du produit : Produit ; quantité
- Toutes les informations et enregistrez-les dans la base de données
#6.保存修改信息wb.save(filename='Boom.xlsx')

Chaque ligne représente une vente distincte. Les colonnes sont le type de produit vendu (A), le prix par livre du produit (B), le nombre de livres vendues (C) et le revenu total de la vente. La colonne TOTAL est configurée comme une formule Excel qui multiplie le coût par livre par le nombre de livres vendues,
et arrondit le résultat au centime le plus proche. Avec cette formule, si la colonne B ou C change, les cellules de la colonne TOTAL seront automatiquement mises à jour
Les prix qui doivent être mis à jour sont les suivants :
Ail 3,07 <🎜. >Citron 1.27
现在假设 Garlic、 Celery 和 Lemons 的价格输入的不正确。这让你面对一项无聊
的任务:遍历这个电子表格中的几千行,更新所有 garlic、celery 和 lemon 行中每磅
的价格。你不能简单地对价格查找替换,因为可能有其他的产品价格一样,你不希
望错误地“更正”。对于几千行数据,手工操作可能要几小时
下载文件 : produceSales.xlsx
原文件打开情况: 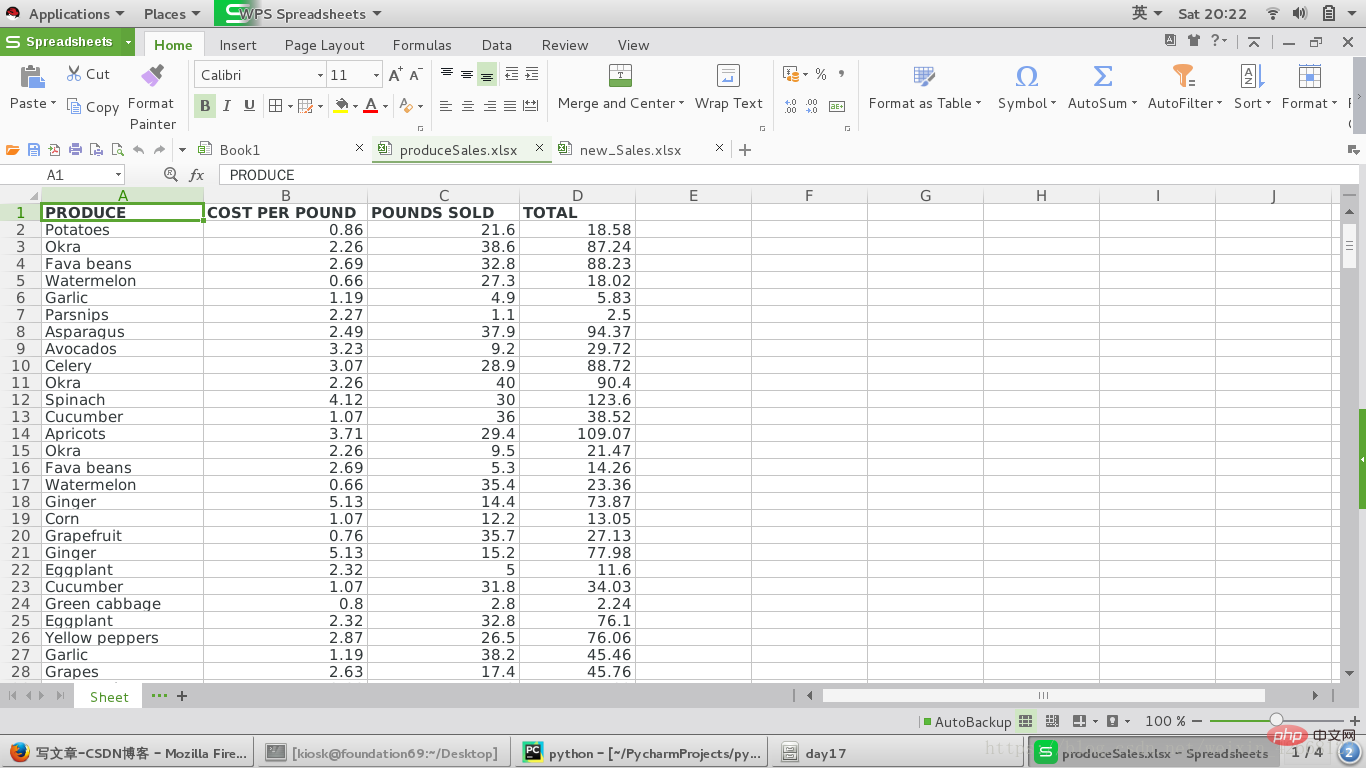
1> 首先需要打开电子表格文件
2> 然后查找每一行内容,检查列 A (即列表的第一个索引)的值是不是 Celery、Garlic 或 Lemon
3> 如果是,更新列 B 中的价格(即列表第二个索引)
4> 最后将该表格保存为一个新的文件
import osimport openpyxldef readwb(wbname, sheetname=None):
# 打开工作薄
wb = openpyxl.load_workbook(wbname)
# 获取要操作的工作表
if not sheetname:
sheet = wb.active else:
sheet = wb[sheetname]
# 获取商品信息保存到列表中
all_info = [] for row in sheet.rows:
child = [cell.value for cell in row]
all_info.append(child)
if child[0] == 'Celery':
child[1] = 1.19
if child[0] == 'Garlic':
child[1] = 3.07
if child[0] == 'Lemon':
child[1] = 1.27
return all_infodef save_to_excel(data, wbname, sheetname='sheet1'):
"""
将信息保存到excel表中;
"""
print("写入Excel[%s]中......." % (wbname))
# 打开excel表, 如果文件不存在, 自己实例化一个WorkBook对象
wb = openpyxl.Workbook()
# 修改当前工作表的名称
sheet = wb.active
# 修改工作表的名称
sheet.title = sheetname
for row, item in enumerate(data): # 0 [' BOOK', 50, 3]
for column, cellValue in enumerate(item): # 0 ' BOOK'
sheet.cell(row=row + 1, column=column + 1, value=cellValue)
# ** 往单元格写入内容
# sheet.cell['B1'].value = "value"
# sheet.cell(row=1, column=2, value="value")
# 保存写入的信息
wb.save(filename=wbname)
print("写入成功!")
data = readwb(wbname='/home/kiosk/Desktop/day17/produceSales.xlsx')
save_to_excel(data, wbname='new_Sales.xlsx', sheetname="商品信息")
表示写入新数据成功 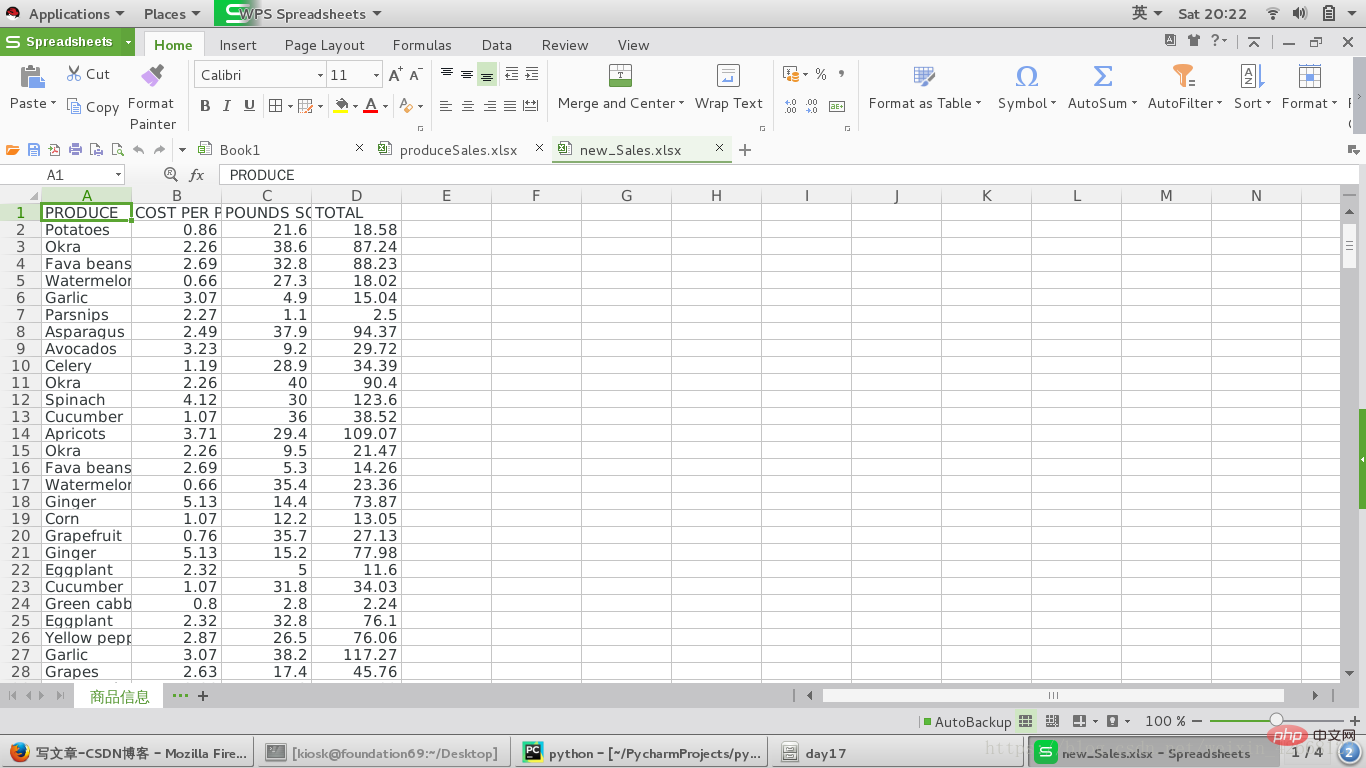
这是更改后的保存的新表格
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python ont leurs propres avantages et inconvénients, et le choix dépend des besoins du projet et des préférences personnelles. 1.Php convient au développement rapide et à la maintenance des applications Web à grande échelle. 2. Python domine le domaine de la science des données et de l'apprentissage automatique.
 Comment entraîner le modèle Pytorch sur Centos
Apr 14, 2025 pm 03:03 PM
Comment entraîner le modèle Pytorch sur Centos
Apr 14, 2025 pm 03:03 PM
Une formation efficace des modèles Pytorch sur les systèmes CentOS nécessite des étapes, et cet article fournira des guides détaillés. 1. Préparation de l'environnement: Installation de Python et de dépendance: le système CentOS préinstalle généralement Python, mais la version peut être plus ancienne. Il est recommandé d'utiliser YUM ou DNF pour installer Python 3 et Mettez PIP: sudoyuMupDatePython3 (ou sudodnfupdatepython3), pip3install-upradepip. CUDA et CUDNN (accélération GPU): Si vous utilisez Nvidiagpu, vous devez installer Cudatool
 Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python et JavaScript ont leurs propres avantages et inconvénients en termes de communauté, de bibliothèques et de ressources. 1) La communauté Python est amicale et adaptée aux débutants, mais les ressources de développement frontal ne sont pas aussi riches que JavaScript. 2) Python est puissant dans les bibliothèques de science des données et d'apprentissage automatique, tandis que JavaScript est meilleur dans les bibliothèques et les cadres de développement frontaux. 3) Les deux ont des ressources d'apprentissage riches, mais Python convient pour commencer par des documents officiels, tandis que JavaScript est meilleur avec MDNWEBDOCS. Le choix doit être basé sur les besoins du projet et les intérêts personnels.
 Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Activer l'accélération du GPU Pytorch sur le système CentOS nécessite l'installation de versions CUDA, CUDNN et GPU de Pytorch. Les étapes suivantes vous guideront tout au long du processus: CUDA et CUDNN Installation détermineront la compatibilité de la version CUDA: utilisez la commande NVIDIA-SMI pour afficher la version CUDA prise en charge par votre carte graphique NVIDIA. Par exemple, votre carte graphique MX450 peut prendre en charge CUDA11.1 ou plus. Téléchargez et installez Cudatoolkit: visitez le site officiel de Nvidiacudatoolkit et téléchargez et installez la version correspondante selon la version CUDA la plus élevée prise en charge par votre carte graphique. Installez la bibliothèque CUDNN:
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Comment choisir la version Pytorch sous Centos
Apr 14, 2025 pm 02:51 PM
Comment choisir la version Pytorch sous Centos
Apr 14, 2025 pm 02:51 PM
Lors de la sélection d'une version Pytorch sous CentOS, les facteurs clés suivants doivent être pris en compte: 1. CUDA Version Compatibilité GPU Prise en charge: si vous avez NVIDIA GPU et que vous souhaitez utiliser l'accélération GPU, vous devez choisir Pytorch qui prend en charge la version CUDA correspondante. Vous pouvez afficher la version CUDA prise en charge en exécutant la commande nvidia-SMI. Version CPU: Si vous n'avez pas de GPU ou que vous ne souhaitez pas utiliser de GPU, vous pouvez choisir une version CPU de Pytorch. 2. Version Python Pytorch
 Comment installer nginx dans Centos
Apr 14, 2025 pm 08:06 PM
Comment installer nginx dans Centos
Apr 14, 2025 pm 08:06 PM
CENTOS L'installation de Nginx nécessite de suivre les étapes suivantes: Installation de dépendances telles que les outils de développement, le devet PCRE et l'OpenSSL. Téléchargez le package de code source Nginx, dézippez-le et compilez-le et installez-le, et spécifiez le chemin d'installation AS / USR / LOCAL / NGINX. Créez des utilisateurs et des groupes d'utilisateurs de Nginx et définissez les autorisations. Modifiez le fichier de configuration nginx.conf et configurez le port d'écoute et le nom de domaine / adresse IP. Démarrez le service Nginx. Les erreurs communes doivent être prêtées à prêter attention, telles que les problèmes de dépendance, les conflits de port et les erreurs de fichiers de configuration. L'optimisation des performances doit être ajustée en fonction de la situation spécifique, comme l'activation du cache et l'ajustement du nombre de processus de travail.
 Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
La formation distribuée par Pytorch sur le système CentOS nécessite les étapes suivantes: Installation de Pytorch: La prémisse est que Python et PIP sont installés dans le système CentOS. Selon votre version CUDA, obtenez la commande d'installation appropriée sur le site officiel de Pytorch. Pour la formation du processeur uniquement, vous pouvez utiliser la commande suivante: pipinstalltorchtorchVisionTorChaudio Si vous avez besoin d'une prise en charge du GPU, assurez-vous que la version correspondante de CUDA et CUDNN est installée et utilise la version Pytorch correspondante pour l'installation. Configuration de l'environnement distribué: la formation distribuée nécessite généralement plusieurs machines ou des GPU multiples uniques. Lieu
