

Qu'est-ce que l'exploration de données ?

Le Data Mining est le processus d'extraction d'informations inconnues mais potentiellement utiles cachées dans de grandes quantités de données. L'objectif de l'exploration de données est de construire un modèle de prise de décision pour prédire les comportements futurs sur la base des données d'actions passées.
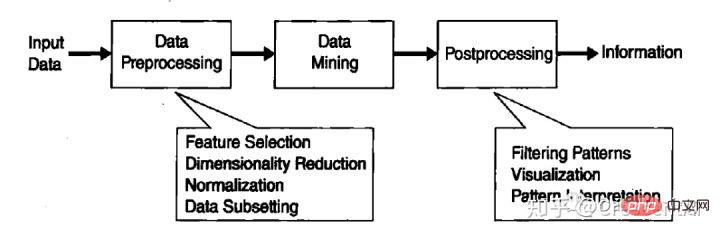
L'exploration de données fait référence au processus de recherche d'informations cachées dans de grandes quantités de données grâce à des algorithmes.
L'exploration de données est généralement liée à l'informatique et atteint les objectifs ci-dessus grâce à de nombreuses méthodes telles que les statistiques, le traitement analytique en ligne, la récupération de renseignements, l'apprentissage automatique, les systèmes experts (s'appuyant sur des règles empiriques passées) et la reconnaissance de formes.
L'exploration de données est un élément indispensable de la découverte de connaissances dans une base de données (KDD), et KDD est l'ensemble du processus de conversion des données brutes en informations utiles. Ce processus comprend une série d'étapes de conversion allant du prétraitement des données au processus. post-traitement des résultats du data mining.
L'origine de l'exploration de données
Des chercheurs de différentes disciplines se sont réunis et ont commencé à développer des outils capables de gérer différents types de données. Des outils plus efficaces et évolutifs. Ces travaux s’appuient sur les méthodologies et algorithmes précédemment utilisés par les chercheurs, et culminent dans le domaine du data mining.
En particulier, l'exploration de données utilise des idées issues des domaines suivants : (1) échantillonnage, estimation et test d'hypothèses à partir de statistiques ; (2) modélisation d'algorithmes de recherche de l'intelligence artificielle, de la reconnaissance de formes et de l'apprentissage automatique. Technologie et théorie de l'apprentissage.
L'exploration de données a également rapidement adopté des idées issues d'autres domaines, notamment l'optimisation, le calcul évolutif, la théorie de l'information, le traitement du signal, la visualisation et la récupération d'informations.
Certains autres domaines jouent également un rôle de soutien important. Les systèmes de bases de données fournissent une prise en charge efficace du stockage, de l'indexation et du traitement des requêtes. Les technologies dérivées du calcul (parallèle) haute performance jouent souvent un rôle important dans le traitement d’ensembles de données massifs. Les technologies distribuées peuvent également faciliter le traitement de quantités massives de données et sont encore plus critiques lorsque les données ne peuvent pas être traitées de manière centralisée.

KDD (Découverte de connaissances à partir d'une base de données)
-
Nettoyage des données
Éliminer le bruit et données incohérentes ;
-
Intégration des données
Plusieurs sources de données peuvent être combinées ensemble
-
Sélection des données
Extraire les données liées aux tâches d'analyse de la base de données;
-
Transformation des données
Transformer et unifier les données en données adaptées à l'exploration via des opérations de synthèse ou d'agrégation Formulaire
- Exploration de donnéesÉtapes de base pour extraire des modèles de données à l'aide de méthodes intelligentes ;
- Évaluation des modèlesIdentifier des modèles vraiment intéressants représentant des connaissances basées sur un certain degré d'intérêt ;
- Représentation des connaissancesUtiliser la technologie de visualisation et de représentation des connaissances pour fournir aux utilisateurs des connaissances extraites .

Méthodologie d'exploration de données
- Compréhension commerciale Comprendre les objectifs et les exigences du projet d'un point de vue commercial, puis transformer cette compréhension en enjeux opérationnels pour l'exploration de données grâce à une analyse théorique, et formuler des plans préliminaires pour atteindre les objectifs
- Données ; compréhension La phase de compréhension des données commence par la collecte de données brutes, puis se familiarise avec les données, identifie les problèmes de qualité des données, explore une compréhension préliminaire des données et découvre des sous-ensembles intéressants à formuler Explorer l'hypothèse d'information
- Préparation des données (préparation des données) La phase de préparation des données fait référence à l'activité de construction des informations nécessaires à l'exploration de données à partir des données non traitées dans les données brutes d'origine. . Les tâches de préparation des données peuvent être effectuées plusieurs fois sans aucun ordre prescrit. L'objectif principal de ces tâches est d'obtenir les informations requises du système source conformément aux exigences de l'analyse dimensionnelle, qui nécessite un prétraitement des données tel que la conversion, le nettoyage, la construction et l'intégration des données ;
- Modélisation A ce stade, il s'agit principalement de sélectionner et d'appliquer diverses techniques de modélisation. Dans le même temps, leurs paramètres sont ajustés pour atteindre des valeurs optimales. Il existe généralement plusieurs techniques de modélisation pour le même type de problème d’exploration de données. Certaines technologies ont des exigences particulières en matière de forme de données et doivent souvent revenir à l'étape de préparation des données
- Évaluation du modèle (évaluation) Avant le déploiement et la publication du modèle ; Il est nécessaire de commencer par Au niveau technique, nous jugeons l'effet du modèle et examinons chaque étape de la construction du modèle, ainsi que la praticabilité du modèle dans des scénarios commerciaux réels basés sur les objectifs commerciaux. L'objectif principal de cette étape est de déterminer s'il existe des problèmes commerciaux importants qui n'ont pas été pleinement pris en compte
- Déploiement du modèle (déploiement) Une fois le modèle terminé ; terminé, il sera déterminé par l'utilisateur modèle (client). En fonction de l'historique actuel et de l'état d'avancement des objectifs, le package répond aux besoins d'utilisation du système d'entreprise.
Tâches d'exploration de données
Généralement, les tâches d'exploration de données sont divisées dans les deux catégories suivantes.
Tâche de prédiction. Le but de ces tâches est de prédire la valeur d'un attribut spécifique en fonction de la valeur d'autres attributs. Les attributs prédits sont généralement appelés variables cibles ou variables dépendantes, et les attributs utilisés pour la prédiction sont appelés variables explicatives ou variables indépendantes.
-
Décrivez la tâche . L'objectif est de dériver des modèles (corrélations, tendances, clusters, trajectoires et anomalies) qui résument les connexions sous-jacentes dans les données. Les tâches d'exploration de données descriptives sont souvent de nature exploratoire et nécessitent souvent des techniques de post-traitement pour vérifier et interpréter les résultats.

Modélisation prédictive (modélisation prédictive) Implante la construction d'un modèle pour une variable cible d'une manière qui décrit la fonction de la variable.
Il existe deux types de tâches de modélisation prédictive : la classification, utilisée pour prédire les variables cibles discrètes ; la régression, utilisée pour prédire les variables cibles continues.
Par exemple, prédire si un internaute achètera un livre dans une librairie en ligne est une tâche de classification car la variable cible est binaire, tandis que prédire le prix futur d'une action est une tâche de régression car le prix a une évolution continue. -attributs valorisés.
Le but des deux tâches est de former un modèle pour minimiser l'erreur entre la valeur prédite et la valeur réelle de la variable cible. La modélisation prédictive peut être utilisée pour déterminer les réponses des clients aux promotions de produits, prédire les perturbations des écosystèmes terrestres ou déterminer si un patient souffre d'une maladie sur la base des résultats de tests.
L'analyse d'association est utilisée pour découvrir des modèles qui décrivent des caractéristiques fortement corrélées dans les données.
Les modèles découverts sont souvent exprimés sous la forme de règles d'implication ou de sous-ensembles de fonctionnalités. L’espace de recherche étant de taille exponentielle, l’objectif de l’analyse de corrélation est d’extraire les modèles les plus intéressants de manière efficace. Les applications de l'analyse d'association comprennent la recherche de génomes ayant des fonctions connexes, l'identification des pages Web que les utilisateurs visitent ensemble et la compréhension des liens entre les différents éléments du système climatique terrestre.
L'analyse de cluster vise à trouver des groupes d'observations étroitement liés tels que les observations appartenant à un même cluster soient plus distinctes les unes des autres que les observations appartenant à des clusters différents aussi similaires que possible. Le clustering peut être utilisé pour regrouper des clients associés, identifier les zones océaniques qui affectent de manière significative le climat de la Terre, compresser les données, etc.
Détection des anomalies La tâche de est d'identifier les observations dont les caractéristiques sont significativement différentes des autres données.
Ces observations sont appelées anomalies ou valeurs aberrantes. L’objectif des algorithmes de détection d’anomalies est de découvrir de véritables anomalies et d’éviter de qualifier par erreur des objets normaux d’anomalies. En d’autres termes, un bon détecteur d’anomalies doit avoir un taux de détection élevé et un faible taux de fausses alarmes.
Les applications de la détection des anomalies incluent la détection de fraudes, de cyberattaques, de schémas inhabituels de maladies, de perturbations des écosystèmes, etc.
Pour plus de connaissances connexes, veuillez visiter : Site Web PHP chinois !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment utiliser le langage Go pour le data mining ?
Jun 10, 2023 am 08:39 AM
Comment utiliser le langage Go pour le data mining ?
Jun 10, 2023 am 08:39 AM
Avec l'essor du Big Data et de l'exploration de données, de plus en plus de langages de programmation ont commencé à prendre en charge les fonctions d'exploration de données. En tant que langage de programmation rapide, sûr et efficace, le langage Go peut également être utilisé pour l'exploration de données. Alors, comment utiliser le langage Go pour le data mining ? Voici quelques étapes et techniques importantes. Acquisition de données Tout d'abord, vous devez obtenir les données. Cela peut être réalisé par divers moyens, tels que l'exploration d'informations sur des pages Web, l'utilisation d'API pour obtenir des données, la lecture de données à partir de bases de données, etc. Le langage Go est livré avec un HTTP riche
 Analyse de données avec MySql : comment gérer l'exploration de données et les statistiques
Jun 16, 2023 am 11:43 AM
Analyse de données avec MySql : comment gérer l'exploration de données et les statistiques
Jun 16, 2023 am 11:43 AM
MySql est un système de gestion de bases de données relationnelles populaire largement utilisé dans le stockage et la gestion de données d'entreprise et personnelles. En plus de stocker et d'interroger des données, MySql fournit également des fonctions telles que l'analyse des données, l'exploration de données et les statistiques qui peuvent aider les utilisateurs à mieux comprendre et utiliser les données. Les données constituent un atout précieux dans toute entreprise ou organisation, et leur analyse peut aider les entreprises à prendre les bonnes décisions commerciales. MySql peut effectuer l'analyse et l'exploration de données de plusieurs manières. Voici quelques techniques et outils pratiques : Utilisation.
 Quelle est la différence entre l'exploration de données et l'analyse de données ?
Dec 07, 2020 pm 03:16 PM
Quelle est la différence entre l'exploration de données et l'analyse de données ?
Dec 07, 2020 pm 03:16 PM
Différences : 1. Les conclusions tirées par « l'analyse des données » sont les résultats des activités intellectuelles humaines, tandis que les conclusions tirées par « l'exploration de données » sont les règles de connaissances découvertes par la machine à partir de l'ensemble d'apprentissage [ou ensemble d'entraînement, ensemble d'échantillons] ; 2. L'« analyse » des données ne peut pas établir de modèles mathématiques et nécessite une modélisation manuelle, tandis que le « data mining » complète directement la modélisation mathématique.
 Conseils de prévision de séries chronologiques en Python
Jun 10, 2023 am 08:10 AM
Conseils de prévision de séries chronologiques en Python
Jun 10, 2023 am 08:10 AM
Avec l’avènement de l’ère des données, de plus en plus de données sont collectées et utilisées à des fins d’analyse et de prédiction. Les données de séries chronologiques sont un type de données courant qui contient une série de données basées sur le temps. Les méthodes utilisées pour prévoir ce type de données sont appelées techniques de prévision de séries chronologiques. Python est un langage de programmation très populaire avec une forte prise en charge de la science des données et de l'apprentissage automatique, c'est donc également un outil très approprié pour la prévision de séries chronologiques. Cet article présentera certaines techniques de prévision de séries chronologiques couramment utilisées en Python et fournira quelques applications pratiques.
 Partage de la technologie des outils du moteur Volcano : utilisez l'IA pour terminer l'exploration de données et l'écriture SQL avec un seuil zéro
May 18, 2023 pm 08:19 PM
Partage de la technologie des outils du moteur Volcano : utilisez l'IA pour terminer l'exploration de données et l'écriture SQL avec un seuil zéro
May 18, 2023 pm 08:19 PM
Lors de l'utilisation des outils de BI, les questions souvent rencontrées sont : "Comment pouvons-nous produire et traiter des données sans SQL ? Pouvons-nous faire de l'analyse minière sans connaître les algorithmes ?" Lorsqu'une équipe d'algorithmes professionnelle effectue de l'exploration de données, l'analyse et la visualisation des données seront également présentées. phénomène relativement fragmenté. Réaliser les travaux de modélisation d’algorithmes et d’analyse de données de manière rationalisée est également un bon moyen d’améliorer l’efficacité. Dans le même temps, pour les équipes professionnelles d'entrepôt de données, le contenu des données sur le même thème est confronté au problème de « construction répétée, utilisation et gestion relativement dispersées » : existe-t-il un moyen de produire des ensembles de données avec le même thème et un contenu différent en même temps ? temps dans une tâche ? L’ensemble de données produit peut-il être utilisé comme entrée pour participer à nouveau à la construction des données ? 1. La capacité de modélisation visuelle de DataWind est fournie avec la plateforme BI Da lancée par Volcano Engine
 La pratique d'application de Redis dans l'intelligence artificielle et l'exploration de données
Jun 20, 2023 pm 07:10 PM
La pratique d'application de Redis dans l'intelligence artificielle et l'exploration de données
Jun 20, 2023 pm 07:10 PM
Avec l’essor de l’intelligence artificielle et de la technologie du Big Data, de plus en plus d’entreprises s’intéressent à la manière de stocker et de traiter efficacement les données. En tant que base de données à mémoire distribuée hautes performances, Redis attire de plus en plus l'attention dans les domaines de l'intelligence artificielle et de l'exploration de données. Cet article donnera une brève introduction aux caractéristiques de Redis et à sa pratique dans les applications d'intelligence artificielle et d'exploration de données. Redis est une base de données NoSQL open source, hautes performances et évolutive. Il prend en charge une variété de structures de données et fournit une mise en cache, des files d'attente de messages, des compteurs, etc.
 Comment effectuer une classification automatique de texte et une exploration de données en PHP ?
May 22, 2023 pm 02:31 PM
Comment effectuer une classification automatique de texte et une exploration de données en PHP ?
May 22, 2023 pm 02:31 PM
PHP est un excellent langage de script côté serveur largement utilisé dans des domaines tels que le développement de sites Web et le traitement de données. Avec le développement rapide d’Internet et la quantité croissante de données, la manière d’effectuer efficacement une classification automatique des textes et une exploration des données est devenue une question importante. Cet article présentera les méthodes et techniques de classification automatique de texte et d'exploration de données en PHP. 1. Qu'est-ce que la classification automatique de textes et l'exploration de données ? La classification automatique du texte fait référence au processus de classification automatique du texte en fonction de son contenu, qui est généralement mis en œuvre à l'aide d'algorithmes d'apprentissage automatique. L'exploration de données fait référence à
 Explication détaillée de l'algorithme Apriori en Python
Jun 10, 2023 am 08:03 AM
Explication détaillée de l'algorithme Apriori en Python
Jun 10, 2023 am 08:03 AM
L'algorithme Apriori est une méthode courante d'exploration de règles d'association dans le domaine de l'exploration de données et est largement utilisé dans la business intelligence, le marketing et d'autres domaines. En tant que langage de programmation général, Python fournit également plusieurs bibliothèques tierces pour implémenter l'algorithme Apriori. Cet article présentera en détail le principe, l'implémentation et l'application de l'algorithme Apriori en Python. 1. Principe de l'algorithme Apriori Avant d'introduire le principe de l'algorithme Apriori, apprenons d'abord les deux concepts suivants dans l'exploration de règles d'association : les ensembles d'éléments fréquents et le support.