


Introduction : Redis est une base de données open source de type journal et de valeurs clés écrite en langage ANSI C, respecte le protocole BSD, prend en charge le réseau, peut être basée sur la mémoire et persistante , et fournit une base de données non relationnelle avec des API dans plusieurs langues.
Recommandation spéciale : Questions d'entretien Redis 2020 (dernières)
Les bases de données traditionnelles suivent les règles ACID. Nosql (abréviation de Not Only SQL, nom collectif désignant les systèmes de gestion de bases de données différents des bases de données relationnelles traditionnelles) est généralement distribué et la distribution suit généralement le théorème CAP.
Code source Github : https://github.com/antirez/redis
Site officiel de Redis : https://redis.io/
Recommandé : "Tutoriel redis》
Quels types de données Redis prend-il en charge ?
Chaîne :
Format : définir la valeur de la clé
Le type de chaîne est binaire. Cela signifie que la chaîne redis peut contenir n'importe quelle donnée. Par exemple, des images jpg ou des objets sérialisés.
Le type chaîne est le type de données le plus basique de Redis, et une clé peut stocker jusqu'à 512 Mo.
Hash (Hash)
Format : nom du hmset key1 value1 key2 value2
Le hachage Redis est un ensemble de paires clé-valeur (key=>value).
Redis hash est une table de mappage de champs et de valeurs de type chaîne. Hash est particulièrement adapté au stockage d'objets.
Liste (Liste)
Les listes Redis sont de simples listes de chaînes, triées par ordre d'insertion. Vous pouvez ajouter un élément en tête (à gauche) ou en queue (à droite) de la liste
Format : lpush name value
Ajouter un élément chaîne en tête de liste correspondant à la clé
Format : valeur du nom rpush
Ajouter des éléments de chaîne à la fin de la liste correspondant à la clé
Format : index du nom lrem
Supprimer le nombre d'éléments de la liste correspondant à la clé qui est la même que la valeur Element
Format : llen name
Renvoie la longueur de la clé correspondante à la liste
Set (set)
Format : sad name value
Redis's Set est une collection non ordonnée de type chaîne.
Les collections sont implémentées via des tables de hachage, donc la complexité de l'ajout, de la suppression et de la recherche est O(1).
zset (ensemble trié : ensemble ordonné)
Format : valeur de score du nom zadd
Redis zset, comme set, est également une collection d'éléments de type chaîne, et les doublons sont membre non autorisé.
La différence est que chaque élément est associé à une partition de type double. Redis utilise des scores pour trier les membres de la collection du plus petit au plus grand.
Les membres de zset sont uniques, mais les scores peuvent être répétés.
Qu'est-ce que la persistance Redis ? De quelles méthodes de persistance Redis dispose-t-il ? Quels sont les avantages et les inconvénients ?
La persistance consiste à écrire les données de mémoire sur le disque pour éviter que les données de mémoire ne soient perdues lorsque le service tombe en panne.
Redis propose deux méthodes de persistance : RDB (par défaut) et AOF
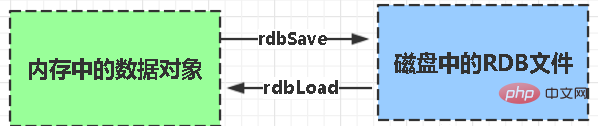
RDB :
rdb est l'abréviation de Redis DataBase
Fonctions de base de la fonction rdbSave (générer un fichier RDB) et rdbLoad (charger la mémoire à partir du fichier) deux fonctions
AOF :
Aof est l'abréviation de Fichier à ajouter uniquement
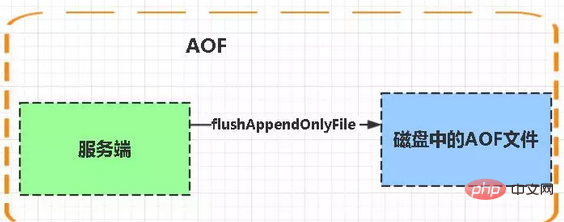
La fonction flushAppendOnlyFile sera appelée chaque fois qu'une tâche ou une fonction du serveur (planifiée) est exécutée. Cette fonction effectue les deux tâches suivantes
aof écrire et sauvegarder : WRITE : Selon les conditions, écrire le cache dans aof_buf dans le fichier AOF SAVE : Selon les conditions, appeler la fonction fsync ou fdatasync pour enregistrer le fichier AOF sur le disque.Structure de stockage :
Le contenu est un stockage de texte de commande au format RESP (Redis Communication Protocol).Comparaison :
1. Les fichiers AOF sont mis à jour plus fréquemment que rdb, utilisez donc aof pour restaurer les données en premier. 2. aof est plus sûr et plus grand que rdb3 rdb a de meilleures performances que aof4 Si les deux sont configurés, AOF sera chargé en premier.
Vous venez de mentionner le protocole de communication Redis (RESP). Pouvez-vous expliquer ce qu'est RESP ? Quelles sont les caractéristiques ? (Vous pouvez voir que de nombreux entretiens sont en fait une série de questions. L'intervieweur attend en fait que vous répondiez à ce point. Si vous répondez à la question, cela ajoutera un autre point à votre évaluation)
RESP Il s'agit d'un protocole de communication précédemment utilisé par le client et le serveur Redis ; Caractéristiques de RESP : implémentation simple, analyse rapide et bonne lisibilité Pour les chaînes simples, le premier octet de la réponse est "+" RéponsePour les erreurs, le premier octet de la réponse est "-" ErreurPour les entiers, le premier octet de la réponse est ":" IntegerPour le vrac Pour les chaînes, le premier octet de la réponse est "$" StringPour les tableaux, le premier octet de la réponse est "*" ArrayQuels sont les modèles architecturaux de Redis ? Parlez de leurs caractéristiques respectives
Version autonome
Caractéristiques : Simple
Problèmes :
1. Capacité de mémoire limitée 2. Puissance de traitement limitée 3. Impossible d'être hautement disponible.
Réplication maître-esclave
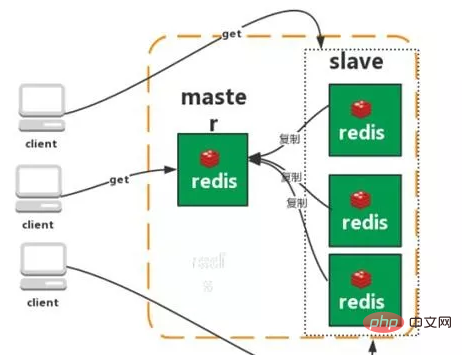
La fonction de réplication de Redis permet aux utilisateurs de répliquer des données basées sur un serveur Redis Créez un nombre illimité de répliques du serveur, le serveur répliqué étant le maître et les répliques de serveur créées via la réplication étant des esclaves. Tant que la connexion réseau entre les serveurs maître et esclave est normale, les serveurs maître et esclave auront les mêmes données, et le serveur maître mettra toujours à jour et synchronisera les données qui lui sont arrivées avec le serveur esclave, garantissant ainsi toujours que les données des serveurs maître et esclave sont les mêmes.
Caractéristiques :
1. Rôle maître/esclave
2. Les données maître/esclave sont les mêmes
3. transfert vers la base de données esclave
Problème :
La haute disponibilité ne peut pas être garantie
Échec de la résolution de la pression de l'écriture principale
Sentinel
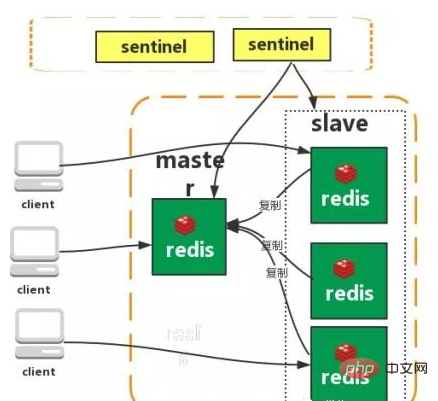
Redis Sentinel est un système distribué qui surveille les serveurs redis maître et esclave et bascule automatiquement lorsque le serveur maître se déconnecte. Trois des fonctionnalités :
Surveillance : Sentinel vérifiera en permanence si votre serveur maître et votre serveur esclave fonctionnent normalement.
Notification : en cas de problème avec un serveur Redis surveillé, Sentinel peut envoyer des notifications à l'administrateur ou à d'autres applications via l'API.
Basculement automatique : lorsqu'un serveur principal ne peut pas fonctionner correctement, Sentinel démarre une opération de basculement automatique.
Caractéristiques :
1. Assurer une haute disponibilité
2. Surveiller chaque nœud
3. Migration automatique des pannes
Inconvénients : Principaux. Depuis le mode, le changement prend du temps pour perdre des données
Ne résout pas la pression de l'écriture principale
Cluster (type proxy) :
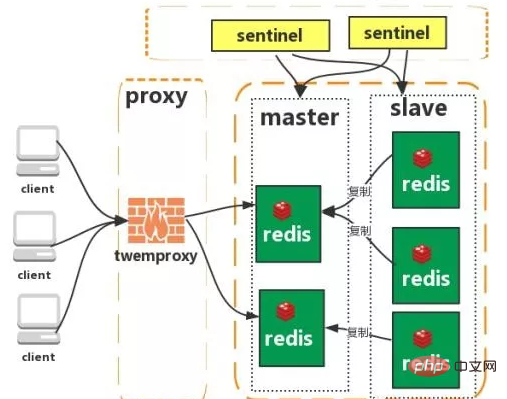
Twemproxy est un serveur proxy open source redis et memcache rapide/léger de Twitter ; Twemproxy est un programme proxy rapide à thread unique qui prend en charge le protocole Memcached ASCII et le protocole redis.
Caractéristiques : 1. Algorithmes de hachage multiples : MD5, CRC16, CRC32, CRC32a, hsieh, murmur, Jenkins
2. Prise en charge de la suppression automatique des nœuds défaillants
3. La logique de partitionnement End-side Sharding est transparente pour l'entreprise, et les méthodes de lecture et d'écriture du côté commercial sont cohérentes avec l'exploitation d'un seul Redis
Inconvénients : un nouveau proxy est ajouté et sa haute disponibilité doit être maintenue .
La logique de basculement doit être mise en œuvre par vous-même. Elle ne peut pas prendre en charge le transfert automatique des défauts et a une faible évolutivité. Une intervention manuelle est nécessaire pour l'expansion et la contraction. >Cluster (type de connexion directe) :
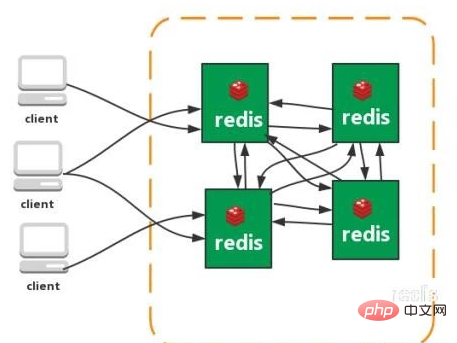 À partir de Redis 3.0, le cluster redis-cluster est pris en charge. structure, chaque nœud enregistre les données et l'ensemble de l'état du cluster, chaque nœud est connecté à tous les autres nœuds.
À partir de Redis 3.0, le cluster redis-cluster est pris en charge. structure, chaque nœud enregistre les données et l'ensemble de l'état du cluster, chaque nœud est connecté à tous les autres nœuds.
Qu'est-ce qu'un algorithme de hachage cohérent ? Qu'est-ce qu'un emplacement de hachage ?
Commandes communes Redis ?
Modèle de clés
* signifie allouer tous les commençant par bitVérifiez si la clé Existe existeDéfinir Définissez la valeur correspondant à la clé sur une valeur de type chaîne. setnxDéfinissez la valeur correspondant à la clé sur une valeur de type chaîne. Si la clé existe déjà, renvoyez 0, nx signifie qu'elle n'existe pas. Supprimer une cléRenvoyer 1 pour la première fois, renvoyer 0 pour la deuxième fois si elle est suppriméeExpire Définir le délai d'expiration (en secondes) Vue TTL Combien de temps reste-t-ilSi un nombre négatif est renvoyé, la clé sera invalide et la clé n'existe pasSetexDéfinissez la valeur correspondant au clé à une valeur de type chaîne, et spécifiez la valeur correspondante de cette période de validité de clé. MsetDéfinissez les valeurs de plusieurs clés à la fois. Renvoyer ok en cas de succès signifie que toutes les valeurs sont définies, et renvoyer 0 en cas d'échec signifie qu'aucune valeur n'est définie. GetsetDéfinissez la valeur de la clé et renvoyez l'ancienne valeur de la clé.Mget
Obtenir les valeurs de plusieurs clés en même temps Si la clé correspondante n'existe pas, nil sera renvoyé en conséquence.
Incr
Ajoute la valeur de key et renvoie la nouvelle valeur. Notez que si incr est une valeur qui n'est pas un int, une erreur sera renvoyée. Si incr est une clé qui n'existe pas, alors définissez la clé sur 1
incrby
est similaire à. incr. Ajoutez la valeur spécifiée et elle sera définie lorsque la clé n'existe pas, et pense que la valeur d'origine est 0
Decr
effectue une opération de soustraction sur la valeur du. key. Si decr n'existe pas, définissez la clé sur -1
Decrby
Identique à decr, moins la valeur spécifiée.
Ajouter
Ajouter une valeur à la valeur de chaîne de la clé spécifiée et renvoyer la longueur de la nouvelle valeur de chaîne.
Strlen
Obtenir la longueur de la valeur de la clé spécifiée.
persister xxx (annuler le délai d'expiration)
Sélectionner la base de données (0-15 base de données)
Sélectionner 0 //Sélectionner la base de données
déplacer l'âge 1// Déplacer l'âge vers 1 bibliothèque
Randomkey renvoie une clé aléatoire
Rename rename
Type renvoie le type de données
08
Avez-vous déjà utilisé le verrouillage distribué Redis ? Comment est-il implémenté ?
Utilisez d'abord setnx pour saisir le verrou. Après l'avoir saisi, utilisez expire pour ajouter un délai d'expiration au verrou afin d'éviter qu'il n'oublie de se libérer.
Que se passe-t-il si le processus plante de manière inattendue ou doit être redémarré pour la maintenance avant d'exécuter expire après setnx ?
L'instruction set a des paramètres très complexes. Elle devrait pouvoir combiner setnx et expirer en une seule instruction en même temps !
09
Avez-vous déjà utilisé Redis comme file d'attente asynchrone ? Comment l'avez-vous utilisé ? Quels sont les inconvénients ?
Généralement, la structure de liste est utilisée comme file d'attente, rpush produit des messages et lpop consomme des messages. Lorsqu'il n'y a aucun message de lpop, dormez un moment et réessayez.
Inconvénients :
Lorsque le consommateur se déconnecte, les messages produits seront perdus, vous devez donc utiliser une file d'attente de messages professionnelle telle que RabbitMQ.
Puis-je le produire une fois et le consommer plusieurs fois ?
En utilisant le mode abonné au sujet pub/sub, une file d'attente de messages 1:N peut être réalisée.
10
Qu'est-ce que la pénétration du cache ? Comment l'éviter ? Qu’est-ce que l’avalanche de cache ? Comment l'éviter ?
Pénétration du cache
Requêtes de cache des systèmes de cache généraux basées sur la clé. Si la valeur correspondante n'existe pas, elle doit être recherchée dans le système back-end (tel que la base de données). Certaines requêtes malveillantes interrogeront délibérément des clés inexistantes. Si le volume de requêtes est important, cela mettra beaucoup de pression sur le système back-end. C’est ce qu’on appelle la pénétration du cache.
Comment l'éviter ?
1 : Le résultat de la requête est également mis en cache lorsqu'il est vide. La durée du cache est raccourcie ou le cache est vidé après l'insertion des données correspondant à la clé.
2 : Filtrer les clés qui ne doivent pas exister. Vous pouvez placer toutes les clés possibles dans un grand Bitmap et filtrer le bitmap lors de l'interrogation.
Avalanche de cache
Lorsque le serveur de cache est redémarré ou qu'un grand nombre de caches échouent au cours d'une certaine période de temps, cela mettra beaucoup de pression sur le système back-end. provoquant le crash du système.
Comment l'éviter ?
1 : Une fois le cache expiré, contrôlez le nombre de threads qui lisent la base de données et écrivent le cache via le verrouillage ou la mise en file d'attente. Par exemple, un seul thread est autorisé à interroger les données et à écrire dans le cache pour une certaine clé, tandis que les autres threads attendent.
2 : Créez un cache de deuxième niveau, A1 est le cache d'origine, A2 est le cache de copie, lorsque A1 échoue, vous pouvez accéder à A2, le délai d'expiration du cache de A1 est défini sur court terme, et A2 est défini sur long terme
3 : Différentes clés, définissez différents délais d'expiration, afin que le temps d'invalidation du cache soit aussi uniforme que possible.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quels sont les 8 types de données de Redis
Quels sont les 8 types de données de Redis
 Tutoriel C#
Tutoriel C#
 Quel protocole est UDP ?
Quel protocole est UDP ?
 Comment utiliser l'instruction insert dans MySQL
Comment utiliser l'instruction insert dans MySQL
 Quels sont les systèmes de correction d'erreurs de noms de domaine ?
Quels sont les systèmes de correction d'erreurs de noms de domaine ?
 saut de ligne forcé de mot
saut de ligne forcé de mot
 utilisation de la fonction setproperty
utilisation de la fonction setproperty
 Le rôle de l'attribut padding en CSS
Le rôle de l'attribut padding en CSS
 Logiciel de système de gestion ERP gratuit
Logiciel de système de gestion ERP gratuit










![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



