
 interface Web
Questions et réponses frontales
Questions d'entretien Android intermédiaires et avancées (avec réponses)
interface Web
Questions et réponses frontales
Questions d'entretien Android intermédiaires et avancées (avec réponses)
Questions d'entretien Android intermédiaires et avancées (avec réponses)

Recommandé : "Collection de questions d'entretien Android 2020 [Collection]"
1, java dans == et equals et hashCode
classes, c'est-à-dire s'il s'agit du même objet, sans remplacer égal, comparez l'adresse mémoire. L'implémentation originale est également ==, comme String, etc., qui remplace la méthode égale
hashCode est également une méthode de l'objet. classe. Renvoie un entier discret. Utilisé dans les opérations de collecte pour améliorer la vitesse des requêtes. (HashMap, HashSet, etc. comparez s'ils sont identiques)
2, la différence entre int et entier
type de base intclasse d'encapsulation int d'objet entier
3, String , StringBuffer, StringBuilderDifférence
Chaîne : caractère Les constantes de chaîne ne conviennent pas aux situations où la valeur doit être modifiée fréquemment. Chaque modification équivaut à générer un nouvel objetStringBuffer : variable de chaîne (thread-safe)
StringBuilder : variable de chaîne (thread non sécurisée) Assurez-vous que seul- opération threadée Disponible, légèrement plus efficace que StringBuffer
4 Qu'est-ce qu'une classe interne ? Le rôle des classes internes
Les classes internes peuvent accéder directement aux propriétés des classes externesLes classes internes en Java sont principalement divisées en
classes internes membres , Classe interne locale (imbriqué dans les méthodes et les portées), Classe interne anonyme (pas de constructeur), Classe interne statique (classe modifiée statiquement, ne peut pas utiliser de non -variables membres statiques et méthodes des classes périphériques, ne dépendent pas des classes périphériques)
5, la différence entre les processus et les threads
Le processus est la plus petite unité d'allocation de ressources CPU, et le thread est la plus petite unité de planification du CPU.Les processus ne peuvent pas partager de ressources, mais les threads partagent l'espace d'adressage et d'autres ressources du processus dans lequel ils se trouvent.
Un processus peut avoir plusieurs threads, et un processus peut démarrer un processus ou un thread.
Un thread ne peut appartenir qu'à un seul processus. Les threads peuvent utiliser directement les ressources du même processus. Les threads dépendent des processus pour leur existence.
6, final, enfin, finaliser
final : modifie les classes, les variables membres et les méthodes membres. Les classes ne peuvent pas être héritées, les variables membres sont immuables et les méthodes membres ne peuvent pas être remplacées.Enfin : utilisé avec try...catch... pour garantir qu'il peut être appelé même si une exception se produit.
finalize : méthode de la classe Cette méthode sera appelée avant que les sous-classes puissent. override finalize() Méthodes pour réaliser le recyclage des ressources
7, Sérialisable et Parcelable La différence
L'interface de sérialisation Java sérialisable génère un grand nombre de variables temporaires pendant le processus de lecture et d'écriture sur le disque dur et effectue un grand nombre de i /o opérations en interne, ce qui est très inefficace.L'interface de sérialisation Android Parcelable est efficace et difficile à lire et à écrire en mémoire (AS a des plug-ins associés pour générer les méthodes requises en un seul clic), et les objets ne peuvent pas être enregistrés sur le disque
8 Les propriétés statiques et les méthodes statiques peuvent-elles être héritées ? Peut-il être réécrit ? Et pourquoi ?
Héritable, non remplaçable, mais cachéSi des méthodes et attributs statiques sont définis dans la sous-classe, alors les méthodes ou attributs statiques de la classe parent sont appelés "cachés" à ce moment. Si vous souhaitez appeler les méthodes et propriétés statiques de la classe parent, faites-le directement via le nom de la classe parent, la méthode ou le nom de la variable.
9, compréhension des classes internes membres, des classes internes statiques, des classes internes locales et des classes internes anonymes, et application dans le projet
ava Les classes internes sont principalement divisées enclasses internes membres , classes internes locales (imbriquées dans des méthodes et des portées), classes internes anonymes (sans constructeur), Classe interne statique (la classe modifiée statiquement ne peut pas utiliser de variables membres et de méthodes non statiques d'une classe externe, et ne dépend pas des classes externes)
La raison la plus intéressante pour utiliser des classes internes est : chaque Chaque la classe interne peut hériter indépendamment d'une implémentation (de l'interface), donc si la classe externe a hérité d'une implémentation (de l'interface), cela n'a aucun effet sur la classe interne.Étant donné que Java ne prend pas en charge l'héritage multiple, il prend en charge l'implémentation de plusieurs interfaces. Mais parfois, certains problèmes sont difficiles à résoudre à l'aide d'interfaces. À l'heure actuelle, nous pouvons utiliser la capacité offerte par les classes internes d'hériter de plusieurs classes concrètes ou abstraites pour résoudre ces problèmes de programmation. On peut dire que les interfaces ne résolvent qu'une partie du problème et que les classes internes rendent la solution de l'héritage multiple plus complète.
10, chaîne est convertie en entier méthode et principe
String →integer Intrger.parseInt(string);Integer→string Integer.toString();11, Dans quelles circonstances les objets seront-ils éliminés par le mécanisme de collecte des ordures ?
1. Toutes les instances n'ont pas d'accès actif au thread. 2. Une instance de référence circulaire à laquelle aucune autre instance n'accède. 3. Il existe différents types de référence en Java. Déterminer si une instance est éligible au garbage collection dépend de son type de référence. Pour déterminer quels types d'objets sont des objets inutiles. Il y a 2 méthodes ici : 1. Utilisez la méthode de comptage de marques : Marquez l'objet dans la mémoire Lorsque l'objet est référencé une fois, le compte est augmenté de 1, et la référence. est libéré. Le compte est décrémenté de un. Lorsque le compte atteint 0, l'objet peut être recyclé. Bien entendu, cela pose également un problème : les objets ayant des références circulaires ne peuvent pas être identifiés et recyclés. Il existe donc une deuxième méthode : 2. Utilisez l'algorithme de recherche racine : Partez d'une racine et recherchez tous les objets accessibles, afin que les objets restants doivent être recyclés
12, la différence entre proxy statique et proxy dynamique, dans quels scénarios sont-ils utilisés ?
Classe proxy statique : Créée par des programmeurs ou générée automatiquement par des outils spécifiques, puis compilée. Avant l'exécution du programme, le fichier .class de la classe proxy existe déjà. Classe proxy dynamique : créée dynamiquement à l'aide du mécanisme de réflexion lorsque le programme est en cours d'exécution.14, Quel est le mécanisme pour implémenter le polymorphisme en Java ?
Réponse : le remplacement et la surcharge des méthodes sont des manifestations différentes du polymorphisme Java Le remplacement fait partie du polymorphisme entre le parent et les sous-classes. Une manifestation La surcharge est une manifestation de polymorphisme dans une classe16, dis-moi ce que tu penses de JavaCompréhension de la réflexion
Le mécanisme de réflexion JAVA est en cours d'exécution. Pour n'importe quelle classe, vous pouvez connaître toutes les propriétés et méthodes de cette classe ; pour n'importe quel objet, vous pouvez appeler n'importe laquelle de ses méthodes et propriétés. À partir de l'objet, par réflexion (classe Class), vous pouvez obtenir les informations complètes de la classe (nom de la classe, type de classe, package, toutes les méthodes de types Method[] dont elle dispose, informations complètes d'une méthode (y compris les modificateurs, la valeur de retour type, Exception, type de paramètre), tous les attributs Field[], informations complètes d'un certain attribut, constructeurs), appelant les attributs ou méthodes de la classe elle-même résumé : Obtenez toutes les informations de la classe, de l'objet et de la méthode pendant l'exécution processus.
17, parlez de votre compréhension des annotations Java
Méta-annotation
Le rôle de la méta-annotation est d'annoter d'autres annotations. Dans Java 5.0, quatre types de méta-annotations standard ont été définis, qui sont utilisés pour fournir des descriptions d'autres types d'annotations.
1.@Cible
2.@Rétention
3.@Documenté
4.@Hérité
18 Comprendre , JavaString
Dans le code source, la chaîne est modifiée avec final, qui est une constante qui ne peut pas être modifiée ni héritée.
19, StringPourquoi devrait-il être conçu pour être immuable ?
1. Exigences pour le pool de chaînes
Le pool de chaînes est une zone de stockage spéciale dans la zone méthode. Lorsqu'une chaîne a été créée et qu'elle se trouve dans le pool, une référence à la chaîne est immédiatement renvoyée à la variable, plutôt que de recréer la chaîne et de renvoyer la référence à la variable. Si les chaînes ne sont pas immuables, la modification de la chaîne dans une référence (par exemple, string2) entraînera des données sales dans une autre référence (par exemple, string1).
2. Autoriser les codes de hachage du cache de chaîne
Les codes de hachage de chaînes sont souvent utilisés en Java, tels que : HashMap. L'immuabilité de String garantit que le code de hachage est toujours le même, il n'a donc pas à se soucier des changements. Cette approche signifie que le code de hachage n'a pas besoin d'être recalculé à chaque fois qu'il est utilisé, ce qui est beaucoup plus efficace.
3. Sécurité
La chaîne est largement utilisée pour les paramètres dans les classes Java, tels que : la connexion réseau (Connexion réseau), l'ouverture de fichiers (ouverture de fichiers), etc. Si String n'est pas immuable, les connexions réseau et les fichiers seront modifiés, ce qui entraînera une série de menaces de sécurité. On pensait que le mode de fonctionnement était connecté à une machine, mais en réalité ce n’était pas le cas. Étant donné que les paramètres en réflexion sont tous des chaînes, cela entraînera également une série de problèmes de sécurité.
20, Objet de la classe égale et hashCode, pourquoi ?
Tout d'abord, la relation entre égaux et hashcode est la suivante : 1 Si deux objets sont identiques (c'est-à-dire comparer avec égaux et renvoyer vrai), alors. leurs valeurs hashCode doivent être les mêmes 2. Si le hashCode de deux objets est le même, ils ne sont pas nécessairement les mêmes (c'est-à-dire que la comparaison avec égal renvoie faux) Étant donné que la méthode du hashcode est implémentée afin d'améliorer l'efficacité du programme, procédez d'abord. Si la comparaison du hashcode est différente, il n'est pas nécessaire de comparer des égaux, ce qui réduit considérablement le nombre de comparaisons d'égaux par rapport au grand nombre de comparaisons. , l'amélioration de l'efficacité est évidente21 La différence entre , Liste, Ensemble, Carte
L'ensemble est le type de collection le plus simple. Les objets de la collection ne sont pas classés d’une manière particulière et il n’y a pas d’objets en double. L'interface Set implémente principalement deux classes d'implémentation : HashSet : La classe HashSet accède aux objets de l'ensemble selon l'algorithme de hachage, et la vitesse d'accès est relativement rapide TreeSet : La classe TreeSet implémente l'interface SortedSet et peut. accéder aux objets de l'ensemble. Les objets sont triés. La caractéristique de List est que ses éléments sont stockés de manière linéaire et que les objets répétés peuvent être stockés dans la collection. ArrayList() : représente un tableau dont la longueur peut être modifiée. Les éléments sont accessibles de manière aléatoire, et l'insertion et la suppression d'éléments dans ArrayList() sont lentes. LinkedList() : utilise la structure de données de liste chaînée dans l'implémentation. L'insertion et la suppression sont rapides, l'accès est lent. Map est une collection qui mappe des objets clés et des objets de valeur. Chaque élément contient une paire d'objets clés et d'objets de valeur. Map n'hérite pas de l'interface Collection. Lors de la récupération d'éléments de la collection Map, tant que l'objet clé est donné, l'objet valeur correspondant sera renvoyé. HashMap : implémentation basée sur une carte de la table de hachage. Le coût d’insertion et d’interrogation des paires clé-valeur est fixe. La capacité et le facteur de charge peuvent être définis par le constructeur pour ajuster les performances du conteneur. LinkedHashMap : similaire à HashMap, mais lors d'une itération, l'ordre dans lequel les "paires clé-valeur" sont obtenues est leur ordre d'insertion, ou l'ordre le moins récemment utilisé (LRU). Seulement légèrement plus lent que HashMap. L'accès itératif est plus rapide car il utilise une liste chaînée pour maintenir l'ordre interne.TreeMap : Implémentation basée sur une structure de données arborescente rouge-noir. Lors de l'affichage des "clés" ou des "paires clé-valeur", elles sont triées (l'ordre est déterminé par Comparabel ou Comparator). La particularité de TreeMap est que les résultats que vous obtenez sont triés. TreeMap est la seule Map avec une méthode subMap(), qui peut renvoyer un sous-arbre.
WeakHashMao : carte clé faible, les objets utilisés dans la carte peuvent également être libérés : ceci est conçu pour résoudre des problèmes particuliers. S'il n'y a aucune référence en dehors de la map pointant vers une "clé", cette "clé" peut être recyclée par le garbage collector.
26 Comparaison de ArrayMap et HashMap
1. Différentes méthodes de stockage
Il existe un objet HashMapEntry
2. Lors de l'ajout de données, le traitement lors du développement est différent. La nouvelle opération est effectuée et l'objet est recréé. ce qui coûte très cher. ArrayMap utilise des données de copie, l'efficacité est donc relativement élevée.
3. ArrayMap fournit la fonction de rétrécissement du tableau. Après avoir été effacé ou supprimé, le tableau sera à nouveau réduit, qu'il y ait de l'espace ou non
4.
29 La différence entre , HashMap et HashTable
1 HashMap n'est pas thread-safe. Il est plus efficace et la méthode n'est pas Synchronize. Elle doit fournir une synchronisation externe. Il existe des méthodes containvalue et containKey. Hashtable est thread-safe et n'autorise pas les clés et valeurs nulles. Elle est légèrement moins efficace et la méthode est Synchronize. Il existe des méthodes contain. Hashtable hérite des classes Dictionary30, HashMap et HashSet Différence
hashMap : HashMap implémente l'interface Map. HashMap stocke les paires clé-valeur. Utilisez la méthode put() pour placer des éléments dans la carte. . Value, HashMap est plus rapide car des clés uniques sont utilisées pour obtenir des objets. HashSet implémente l'interface Set. HashSet stocke uniquement les objets. Utilisez la méthode add() pour placer des éléments dans l'ensemble. HashSet utilise les objets membres pour calculer les valeurs de hashcode. equals La méthode () est utilisée pour déterminer l'égalité des objets si les deux objets sont différents, alors renvoie false. HashSet est plus lent que HashMap.31, HashSet et HashMap Comment déterminer si des éléments sont définis sont dupliqués ?
HashSet ne peut pas ajouter d'éléments en double. Lorsque la méthode add (Object) est appelée, appellera d'abord la méthode hashCode de Object pour déterminer si le hashCode existe déjà. n'existe pas, il sera inséré directement s'il existe déjà, appelez la méthode equals de l'objet Object pour déterminer s'il renvoie vrai. S'il est vrai, l'élément existe déjà. S'il est faux, l'élément est inséré. .33 Les différences entre , ArrayList et LinkedList, ainsi en tant que scénarios d'application
ArrayList est implémenté sur la base de tableaux, et ArrayList n'est pas sécurisé pour les threads. LinkedList est implémenté sur la base d'une double liste chaînée : Scénarios d'utilisation : (1) Si l'application effectue un grand nombre d'opérations d'accès ou de suppression sur des éléments à chaque position de l'index, les objets ArrayList sont de loin supérieurs aux objets LinkedList ; (2) Si l'application parcourt principalement les listes et effectue des opérations d'insertion ou de suppression pendant la boucle, les objets LinkedList sont de loin supérieurs aux objets ArrayList ;34
, La différence entre les tableaux et les listes chaînéesTableau : Il stocke les éléments en continu en mémoire ses avantages : parce que les données sont stockées en continu, Le l'adresse mémoire est continue, elle est donc plus efficace lors de la recherche de données ; son inconvénient : avant de stocker, il faut demander un espace mémoire continu, et la taille de son espace doit être déterminée lors de la compilation. La taille de l'espace ne peut pas être modifiée en fonction de vos besoins pendant le fonctionnement. Lorsque les données sont relativement volumineuses, elles peuvent être hors limites. Lorsque les données sont relativement petites, elles peuvent être gaspillées. Lorsque vous modifiez le nombre de données, l'ajout, l'insertion et la suppression de données sont moins efficaces.
Liste chaînée : il s'agit d'une application dynamique pour l'espace mémoire. Elle n'a pas besoin de demander la taille de la mémoire à l'avance comme un tableau. pour ou supprimer de l'espace mémoire selon les besoins, l'augmentation, la suppression et l'insertion de données sont plus flexibles que les tableaux. Il y a aussi le fait que les données de la liste chaînée peuvent se trouver à n'importe quel endroit de la mémoire, et les données sont associées via l'application (c'est-à-dire via le pointeur de l'élément existant)
35
, démarrage du fil Trois façons ? ava propose trois façons de créer des threads, à savoir hériter de la classe Thread, implémenter l'interface Runable et utiliser le pool de threads
36. Quelle est la différence entre le fil et le processus ?
Les threads sont un sous-ensemble de processus. Un processus peut avoir plusieurs threads, et chaque thread effectue différentes tâches en parallèle. Différents processus utilisent différents espaces mémoire et tous les threads partagent le même espace mémoire. Ne confondez pas cela avec la mémoire de pile. Chaque thread possède sa propre mémoire de pile pour stocker les données locales.
38, run() et start() différences de méthode
Cette question est souvent posée, mais elle permet toujours de distinguer la compréhension de l'intervieweur du modèle de thread Java. La méthode start() est utilisée pour démarrer un thread nouvellement créé, et start() appelle en interne la méthode run(), ce qui a un effet différent de celui de l'appel direct de la méthode run(). Lorsque vous appelez la méthode run(), elle ne sera appelée que dans le thread d'origine. Si aucun nouveau thread n'est démarré, la méthode start() démarrera un nouveau thread.
39. Comment contrôler le nombre de threads d'accès simultanés autorisés par une méthode ?
semaphore.acquire() demande un sémaphore A ce moment, le nombre de sémaphores est de -1 (une fois qu'il n'y a plus de sémaphore utilisable, c'est-à-dire lorsque le nombre de sémaphores devient négatif, demandez à nouveau. bloquera jusqu'à ce que les autres threads libèrent le sémaphore)
semaphore.release() libère un sémaphore, à ce moment le nombre de sémaphores + 1
40, la différence entre les méthodes wait et seelp en Java ;
L'attente et la mise en veille dans les programmes Java provoqueront une certaine forme de pause et peuvent répondre à différents besoins. La méthode wait() est utilisée pour la communication entre les threads. Si la condition d'attente est vraie et que d'autres threads sont réveillés, elle libérera le verrou, tandis que la méthode sleep() libère uniquement les ressources CPU ou arrête le thread en cours pendant une période de 30 minutes. temps, mais ne libère pas le verrou.
41, parlez de la compréhension des attendre/notifiermots clés
Attente du verrou de synchronisation de l'objet. Vous devez obtenir le verrou de synchronisation de l'objet avant d'appeler cette méthode. Sinon, la compilation peut réussir, mais une exception sera reçue à l'exécution : IllegalMonitorStateException.
L'appel de la méthode wait() de n'importe quel objet provoque le blocage du thread, le thread ne peut pas continuer à s'exécuter et le verrou sur l'objet est libéré.
Réveillez le thread en attente du verrouillage de synchronisation de l'objet (n'en réveillez qu'un, s'il y en a plusieurs en attente). Notez que lors de l'appel de cette méthode, vous ne pouvez pas réveiller exactement un thread en état d'attente. Au lieu de cela, la JVM détermine quel thread réveiller, et non par priorité.
L'appel de la méthode notify() de n'importe quel objet entraînera le déblocage d'un thread sélectionné au hasard bloqué en appelant la méthode wait() de l'objet (mais il ne sera exécuté que lorsque le verrou sera obtenu).
42. Qu'est-ce qui cause le blocage des fils de discussion ? Comment fermer le fil de discussion ?
La méthode de blocage signifie que le programme attendra que la méthode se termine sans rien faire d'autre. La méthode accept() de ServerSocket consiste à attendre que le client se connecte. Le blocage signifie ici qu'avant que le résultat de l'appel ne soit renvoyé, le thread actuel sera suspendu et ne reviendra pas tant que le résultat n'est pas obtenu. De plus, il existe des méthodes asynchrones et non bloquantes qui reviennent avant que la tâche ne soit terminée.
L'une consiste à y appeler la méthode stop()
L'autre consiste à définir une marque pour arrêter le fil vous-même (recommandé)
43 , Comment garantir la sécurité des threads ?
1. synchronisé ;
2. attendez, notifiez dans la méthode Object
3.
44. Comment réaliser la synchronisation des threads ?
1. Comment modifier le mot-clé synchronisé. 2. Blocs d'instructions modifiés par le mot-clé synchronisé 3. Utiliser des variables de domaine spéciales (volatiles) pour réaliser la synchronisation des threads
45, opérations inter-thread Liste
List list = Collections.synchronizedList(new ArrayList());
46, parlez de Synchronisé Compréhension des mots-clés, des verrous de classe, des verrous de méthode et des verrous réentrants
Les verrous d'objet et les verrous de classe de Java : les verrous d'objet et les verrous de classe de Java sont dans les verrous Le concept est fondamentalement le même que le verrou intégré, mais les deux verrous sont en fait très différents. Les verrous d'objet sont utilisés pour les méthodes d'instance d'objet, ou sur une instance d'objet, et les verrous de classe sont utilisés pour les méthodes statiques de classe. objet d'une classe. Nous savons qu'il peut y avoir plusieurs instances d'objet d'une classe, mais chaque classe n'a qu'un seul objet de classe, donc les verrous d'objet des différentes instances d'objet n'interfèrent pas les uns avec les autres, mais il n'y a qu'un seul verrou de classe pour chaque classe. Mais une chose qu'il faut noter est qu'en fait, le verrouillage de classe n'est qu'une chose conceptuelle et n'existe pas vraiment. Il est uniquement utilisé pour nous aider à comprendre la différence entre les méthodes d'instance de verrouillage et les méthodes statiques
.49 La différence entre les mots-clés , synchronisés et volatils
1. Volatile indique essentiellement au jvm que la valeur de la variable actuelle dans le registre (mémoire de travail) est incertaine et doit être lue à partir de la mémoire principale ; Le thread actuel peut accéder à cette variable, les autres threads sont bloqués.
2. Volatile ne peut être utilisé qu'au niveau des variables ; synchronisé peut être utilisé aux niveaux des variables, des méthodes et des classes
3. Volatile ne peut obtenir la visibilité des modifications des variables et ne peut pas. garantir le sexe d'atomicité ; pendant la synchronisation, il peut garantir la visibilité et l'atomicité des modifications variables
4.volatile ne provoquera pas de blocage de thread ; la synchronisation peut provoquer un blocage de thread.
5. Les variables marquées volatiles ne seront pas optimisées par le compilateur ; les variables marquées synchronisées peuvent être optimisées par le compilateur
51, ReentrantLock , synchronisé et volatile comparaison
Ava a longtemps réussi à obtenir une exclusion mutuelle uniquement grâce au mot-clé synchronisé, ce qui présente quelques inconvénients. Par exemple, vous ne pouvez pas étendre les méthodes ou bloquer les limites en dehors du verrou, vous ne pouvez pas annuler à mi-chemin lorsque vous essayez d'acquérir le verrou, etc. Java 5 fournit un contrôle plus complexe via l'interface Lock pour résoudre ces problèmes. La classe ReentrantLock implémente Lock, qui a la même concurrence et la même sémantique de mémoire que synchronisée, mais est également extensible.
53 Quatre conditions nécessaires à une impasse ?
Causes de l'impasse
1. Concurrence pour les ressources système
La concurrence pour les ressources système conduit à des ressources système insuffisantes et à une allocation inappropriée des ressources, conduisant à une impasse.
2. L'ordre d'exécution du processus est inapproprié.
Condition d'exclusion mutuelle : une ressource ne peut être utilisée que par un seul processus à la fois, c'est-à-dire qu'une certaine ressource ne peut être occupée que par un seul processus. dans un laps de temps. À ce stade, si d’autres processus demandent la ressource, le processus demandeur ne peut qu’attendre.
Conditions de demande et de rétention : Le processus a conservé au moins une ressource, mais a fait une nouvelle demande de ressource, et la ressource est déjà occupée par d'autres processus. À ce moment, le processus demandeur est bloqué, mais il. n’a pas accès à la ressource qu’il a obtenue. Les ressources restent intactes.
Condition d'inévitabilité : les ressources obtenues par un processus ne peuvent pas être retirées de force par d'autres processus avant d'être complètement utilisées, c'est-à-dire qu'elles ne peuvent être libérées que par le processus qui a obtenu les ressources (il ne peut être libéré que activement).
Conditions d'attente de boucle : plusieurs processus forment une relation de boucle de bout en bout en attente de ressources
Ces quatre conditions sont des conditions nécessaires à une impasse Tant qu'une impasse se produit dans le système, ces conditions doivent être vraies. Tant que l'une des conditions ci-dessus n'est pas remplie, il n'y aura pas de blocage.
Évitement et prévention des blocages :
Idée de base pour éviter les blocages :
Le système vérifie dynamiquement les demandes de ressources émises par le processus pour chaque système qui peut être satisfait, et en fonction du résultat de la vérification, il est nécessaire d'allouer des ressources. Si le système peut se bloquer après l'allocation, il ne sera pas alloué, sinon il sera alloué. Il s'agit d'une stratégie dynamique visant à garantir que le système n'entre pas dans un état de blocage.
Comprendre les causes des blocages, en particulier les quatre conditions nécessaires aux blocages, vous pouvez éviter, prévenir et éliminer les blocages dans la mesure du possible. Par conséquent, en termes de conception du système et de planification des processus, veillez à ce que ces quatre conditions nécessaires ne soient pas remplies et à déterminer un algorithme d'allocation de ressources raisonnable pour éviter que les processus n'occupent en permanence les ressources du système. De plus, il est également nécessaire d’empêcher les processus d’occuper des ressources lorsqu’ils sont en attente. L’allocation des ressources doit donc être correctement planifiée.
La différence entre l'évitement des impasses et la prévention des impasses :
La prévention des impasses consiste à essayer de détruire au moins une des quatre conditions nécessaires à l'impasse, d'empêcher strictement l'apparition d'une impasse et de mourir Éviter les blocages ne limite pas strictement l'existence de conditions nécessaires à une impasse, car même si les conditions nécessaires à une impasse existent, une impasse ne se produit pas nécessairement. Éviter les blocages consiste à faire attention à éviter l'apparition éventuelle d'un blocage pendant le fonctionnement du système.
56. Qu'est-ce qu'un pool de threads et comment l'utiliser ? ?
La création de threads coûte des ressources coûteuses et Si le thread est créé seulement après l'arrivée de la tâche, le temps de réponse deviendra plus long et le nombre de threads pouvant être créés par un processus est limité. Afin d'éviter ces problèmes, plusieurs threads sont créés pour répondre au traitement au démarrage du programme. Ils sont appelés pools de threads et les threads à l'intérieur sont appelés threads de travail. À partir du JDK1.5, l'API Java fournit le framework Executor afin que vous puissiez créer différents pools de threads. Par exemple, un seul pool de threads traite une tâche à la fois ; un nombre fixe de pools de threads ou un pool de threads de cache (un pool de threads évolutif adapté aux programmes comportant de nombreuses tâches de courte durée).
57, Quelle est la différence entre tas et pile en Java ?
Pourquoi cette question est-elle classée comme une question d'entretien multithread et simultanée ? Car la pile est une zone mémoire étroitement liée aux threads. Chaque thread possède sa propre mémoire de pile, qui est utilisée pour stocker les variables locales, les paramètres de méthode et les appels de pile. Les variables stockées dans un thread ne sont pas visibles par les autres threads. Le tas est une zone mémoire commune partagée par tous les threads. Les objets sont tous créés dans le tas. Afin d'améliorer l'efficacité, le thread les mettra en cache depuis le tas vers sa propre pile. Si plusieurs threads utilisent cette variable, cela peut causer des problèmes. Cela nécessite que le thread démarre à partir de la pile principale. Lire la valeur d'une variable depuis la mémoire.
58, il y a trois fils T1, T2, T3, comment s'assurer qu'ils sont exécutés dans l'ordre ?
En multi-threading, il existe de nombreuses façons de laisser les threads s'exécuter dans un ordre spécifique. Vous pouvez utiliser la méthode join() de la classe thread pour démarrer un autre thread dans un thread et dans l'autre. le fil termine le fil et continue l'implémentation. Pour garantir l'ordre des trois threads, vous devez commencer par le dernier (T3 appelle T2, T2 appelle T1), de sorte que T1 termine en premier et T3 en dernier.
Communication inter-thread
Nous savons que le thread est la plus petite unité de planification du processeur. Sous Android, le thread principal ne peut pas effectuer d'opérations fastidieuses et les sous-threads ne peuvent pas mettre à jour l'interface utilisateur. Il existe de nombreuses façons de communiquer entre les threads, telles que la diffusion, Eventbus et le rappel d'interface. Sous Android, les gestionnaires sont principalement utilisés. Le gestionnaire envoie le message contenant le message à la file d'attente de messages en appelant la méthode sendmessage, et l'objet looper appelle en permanence la méthode de boucle pour retirer le message de la file d'attente de messages et le remettre au gestionnaire pour traitement, complétant ainsi la communication inter-thread. .
Pool de threads
Il existe quatre pools de threads courants dans Android, FixedThreadPool, CachedThreadPool, ScheduledThreadPool et SingleThreadExecutor.
Le pool de threads FixeThreadPool est créé via la nouvelle méthode FixeThreadPool des exécuteurs. Sa particularité est que le nombre de threads dans le pool de threads est fixe. Même si les threads sont inactifs, ils ne seront pas recyclés à moins que le pool de threads ne soit fermé. Lorsque tous les threads sont actifs, de nouvelles tâches sont dans la file d'attente en attendant que les threads soient traitées. Notez que FixedThreadPool n'a que des threads principaux et aucun thread non principal.
Le pool de threads CachedThreadPool est créé via le newCachedThreadPool of Executors. Il s'agit d'un pool de threads avec un nombre variable de threads. Il n'a pas de threads principaux, uniquement des threads non principaux. Lorsque tous les threads du pool de threads sont actifs, de nouveaux threads seront créés pour gérer de nouvelles tâches. Sinon, les threads inactifs seront utilisés pour gérer de nouvelles tâches. Les threads du pool de threads disposent d'un mécanisme de délai d'attente. Le mécanisme de délai d'attente est de 60 secondes. Passé ce délai, les threads inactifs seront recyclés. Ce type de pool de threads convient au traitement d’un grand nombre de tâches qui prennent moins de temps. Il convient de mentionner ici que la file d'attente des tâches de CachedThreadPool est fondamentalement vide.
Le pool de threads ScheduledThreadPool est créé via le newScheduledThreadPool des exécuteurs. Ses threads principaux sont fixes, mais le nombre de threads non principaux n'est pas fixe, et lorsque les threads non principaux sont inactifs, ils sont immédiatement recyclés. . Ce type de thread convient à l’exécution de tâches planifiées et de tâches récurrentes à période fixe.
Le pool de threads SingleThreadExecutor est créé via la méthode newSingleThreadExecutor des Executors. Il n'y a qu'un seul thread principal dans ce type de pool de threads et aucun thread non principal. Cela garantit que toutes les tâches peuvent être exécutées dans le même thread. et dans l'ordre, il n'est donc pas nécessaire de prendre en compte les problèmes de synchronisation des threads.
Comment fonctionne AsyncTask
AsyncTask est une classe de tâches asynchrones légère fournie par Android lui-même. Il peut exécuter des tâches en arrière-plan dans le pool de threads, puis transmettre la progression de l'exécution et les résultats finaux au thread principal pour mettre à jour l'interface utilisateur. En fait, AsyncTask encapsule Thread et Handler en interne. Bien qu'AsyncTask soit très pratique pour effectuer des tâches en arrière-plan et mettre à jour l'interface utilisateur sur le thread principal, AsyncTask ne convient pas aux opérations en arrière-plan particulièrement chronophages. Pour les tâches particulièrement chronophages, je recommande personnellement d'utiliser un pool de threads.
AsyncTask fournit 4 méthodes principales :
1. onPreExecute() : Cette méthode est exécutée dans le thread principal et sera appelée avant d'exécuter la tâche asynchrone. Elle est généralement utilisée pour certains travaux de préparation. .
2. doInBackground(String... params) : Cette méthode est exécutée dans le pool de threads. Cette méthode est utilisée pour effectuer des tâches asynchrones. Dans cette méthode, la progression de la tâche peut être mise à jour via la méthode publierProgress. La méthode publierProgress appellera la méthode onProgressUpdate. De plus, le résultat de la tâche est renvoyé à la méthode onPostExecute.
3. onProgressUpdate(Object... values) : Cette méthode est exécutée dans le thread principal et est principalement utilisée lorsque la progression de la tâche est appelée.
4. onPostExecute(Long aLong) : Exécuté dans le thread principal une fois la tâche asynchrone exécutée, cette méthode sera appelée. Les paramètres de cette méthode sont les résultats de retour de l'arrière-plan.
En plus de ces méthodes, il existe également des méthodes moins couramment utilisées, comme onCancelled(), qui sera appelée lorsque la tâche asynchrone est annulée.
D'après le code source, nous pouvons savoir que la méthode executeOnExecutor() est appelée à partir de la méthode d'exécution ci-dessus, c'est-à-dire executeOnExecutor(sDefaultExecutor, params); et sDefaultExecutor est en fait un pool de threads série. La méthode onPreExecute() sera appelée ici. Regardez ensuite ce pool de threads. L'exécution d'AsyncTask est mise en file d'attente en raison du mot-clé synchronisé et le paramètre Params d'AsyncTask est encapsulé dans la classe FutureTask. La classe FutureTask est une classe concurrente, et ici elle agit comme un Runnable. Ensuite, la FutureTask sera transmise à la méthode d'exécution de SerialExecutor pour traitement, et la méthode exécuteur de SerialExecutor ajoutera d'abord la FutureTask à la file d'attente mTasks. S'il n'y a pas de tâche à ce moment, la méthode planningNext() sera appelée. exécuter la tâche suivante. S'il y a une tâche, planningNext(); sera appelé à la fin après l'exécution pour exécuter la tâche suivante. jusqu'à ce que toutes les tâches soient terminées. Il existe une méthode call() dans le constructeur d'AsyncTask, et cette méthode sera exécutée par la méthode run de FutureTask. Donc, finalement, cette méthode d’appel sera exécutée dans le pool de threads. La méthode doInBackground est appelée ici. Examinons de plus près cette méthode call(). mTaskInvoked.set(true); indique que la tâche en cours a été exécutée. Exécutez ensuite la méthode doInBackground et transmettez enfin le résultat via la méthode postResult(result); Dans la méthode postResult(), les messages sont envoyés via sHandler. Dans sHandler, un MESSAGE_POST_RESULT est jugé par le type de message. Dans ce cas, la méthode onPostExecute(result) ou onCancelled(result) est appelée. Un autre type de message est MESSAGE_POST_PROGRESS, qui appelle onProgressUpdate pour mettre à jour la progression.
Binder mécanisme de fonctionnement
Intuitivement, Binder est une classe dans Android, qui implémente l'interface IBinder D'un point de vue IPC De manière générale, Binder. est un moyen de communication entre processus dans Android. Il peut également être compris comme un périphérique physique virtuel et son pilote de périphérique est /dev/binder/. Du point de vue du Framework, Binder est le pont de ServiceManager. Depuis la couche application, Binder est le support de communication entre le client et le serveur.
Commençons par comprendre la signification de chaque méthode de cette classe :
DESCRIPTEUR : Identifiant unique de Binder, généralement utilisé pour représenter le nom actuel de la classe Binder.
asInterface(android.os.IBinder obj) : utilisé pour convertir l'objet Binder du serveur en objet de type interface AIDL requis par le client. Ce processus de conversion est spécifique au processus Si le client et le service If. Si le client est dans le même processus, cette méthode renvoie l'objet stub du serveur lui-même, sinon elle renvoie l'objet Stub.proxy encapsulé par le système.
asBinder() : utilisé pour renvoyer l'objet Binder actuel.
onTransact : Cette méthode s'exécute dans le pool de threads Binder côté serveur Lorsque le client lance une demande de communication inter-processus, la demande distante est encapsulée par la couche inférieure du système et transmise à cette méthode. pour le traitement. Faites attention à cette méthode public boolean onTransact (code int, données android.os.Parcel, réponse android.os.Parcel, indicateurs int). Le serveur peut déterminer la méthode cible demandée par le client via le code, puis récupérer la cible. à partir des données. Les paramètres requis par la méthode, puis exécutez la méthode cible. Lorsque la méthode cible est exécutée, la valeur de retour est écrite en réponse. C'est ainsi que la méthode est exécutée. Si cette méthode renvoie false, le client échouera à la requête, nous pouvons donc effectuer une vérification de sécurité dans cette méthode.
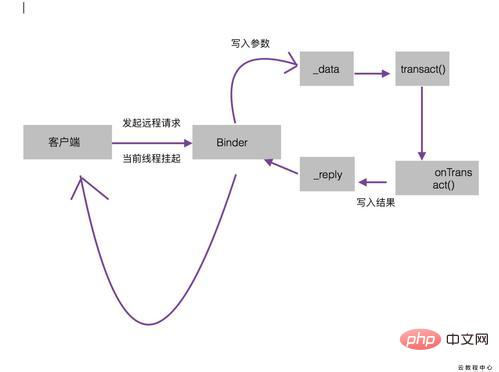
Mécanisme de fonctionnement de Binder mais il y a certains problèmes auxquels il faut prêter attention : 1. Lorsque le client lance une demande, car le thread actuel sera suspendu jusqu'à ce que le serveur renvoie des données. Si cette méthode distante prend beaucoup de temps, alors cette requête distante ne peut pas être lancée dans le thread de l'interface utilisateur, c'est-à-dire le thread principal.
2. Étant donné que la méthode Binder de Service s'exécute dans le pool de threads, la méthode Binder doit être synchronisée, que cela prenne du temps ou non, car elle s'exécute déjà dans un thread.
afficher la distribution des événements et afficher le principe de fonctionnement
Vue personnalisée Android, nous le savons tous que l'implémentation comporte trois parties, onMeasure(), onLayout() et onDraw(). Le processus de dessin de View démarre à partir de la méthode perfromTraversal de viewRoot. Il peut dessiner la vue grâce aux méthodes de mesure, de mise en page et de dessin. Parmi eux, Measure mesure la largeur et la hauteur, layout détermine la position de la vue sur le conteneur parent et draw dessine la vue à l'écran.
Mesure :
Afficher la mesure nécessite MeasureSpc (spécification de mesure), qui représente une valeur entière de 32 bits, les 2 bits élevés représentent SpecMode (mode de mesure) et les bits faibles (30) représentent SpecSize (taille de spécification dans un certain mode de mesure). Un ensemble de SpecMode et SpeSize peut être regroupé dans un MeasureSpec, et inversement, MeasureSpec peut être décompressé pour obtenir les valeurs de SpecMode et SpeSize. Il existe trois types de SpecMode :
unSpecified : le conteneur parent n'a aucune restriction sur la vue, aussi grande ou petite qu'il le souhaite. Ceci est principalement utilisé dans les systèmes généraux.
Exactement : le conteneur parent a détecté la taille exacte requise par la vue. À ce stade, la taille de la vue est la valeur spécifiée par SpecSize, qui correspond à math_parent dans la mise en page ou à la valeur spécifique
At_most : Le conteneur parent spécifie une SpecSize de taille disponible. La taille de la vue ne peut pas être supérieure à cette valeur. Elle correspond au wrao_content dans cette mise en page Pour une vue ordinaire, sa MeasureSpec est composée de. le MeasureSpec du conteneur parent et lui-même. Le layoutParam est déterminé conjointement. Une fois le MeasureSpec déterminé, onMeasure peut déterminer la largeur et la hauteur de la vue. Processus de mesure de la vue : La méthode onMeasure a une méthode setMeasureDimenSion pour définir la valeur de mesure de la largeur et de la hauteur de la vue, et setMeasureDimenSion a une méthode getDefaultSize() comme paramètre. Dans des circonstances normales, nous n'avons besoin de prêter attention qu'aux situations at_most et exactes. La valeur de retour de getDefaultSize est SpecSize dans MeasureSpec, et cette valeur est essentiellement la taille mesurée de la vue. Dans le cas de UnSpecified, il s'agit généralement d'un processus de mesure au sein du système, qui doit prendre en compte des facteurs tels que l'arrière-plan de la vue. Ce dont nous avons parlé plus tôt est le processus de mesure de view et le processus de mesure de viewGroup : Pour viewGroup, en plus de compléter son propre processus de mesure, il doit également parcourir pour appeler la méthode Measure de la sous-classe, chaque élément enfant exécute ce processus de manière récursive. viewGroup est une classe abstraite qui ne fournit pas de méthode onMeasure, mais fournit une méthode MeasureChildren. L'idée de la méthode MeasureChild est de supprimer les layoutParams de l'élément enfant, puis d'obtenir le MeasureSpec de l'élément enfant via getChildMeasureSpec, puis de mesurer l'élément enfant dans la méthode de mesure par électrophorèse. Étant donné que les sous-classes de viewGroup ont des méthodes de présentation différentes, leurs détails de mesure sont différents, donc viewGroup ne peut pas appeler la méthode onMeasure pour des mesures comme view. Remarque : Il n'existe aucun moyen d'obtenir correctement la largeur et la hauteur de la vue pendant le cycle de vie de l'activité. La raison est que la vue n'a pas été mesurée.- Obtenu dans la méthode onWindowFocuschanged ----La signification de la méthode modifiée est que la vue a été initialisée
- Méthode View.post(), qui transmettra le message à la fin de la file d'attente des messages.
- Utilisez le rappel de viewTreeObserver pour terminer.
- Mesurez manuellement via view.measure.
onLayout
Pour une vue ordinaire, vous pouvez utiliser la méthode setFrame pour obtenir la position des quatre sommets de la vue, qui détermine également l'emplacement de la vue dans la position du conteneur parent, puis appelez la méthode onLayout, qui détermine la position de l'élément enfant à partir du conteneur parent.onDraw
Cette méthode dessine la vue à l'écran. Répartissez-vous dans les étapes suivantes :- dessinez le fond,
- dessinez-vous,
- dessinez l'enfant,
- dessinez la décoration.
Optimisation des performances sous Android
En raison des limitations du matériel du téléphone mobile, ni la mémoire ni le processeur ne peuvent avoir une taille aussi grande une mémoire en tant que PC Sur les téléphones Android, une utilisation excessive de la mémoire peut facilement conduire à un MOO, et une utilisation excessive des ressources du processeur peut provoquer le gel du téléphone ou même provoquer un anr. J'optimise principalement à partir des parties suivantes : Optimisation de la mise en page, optimisation des dessins, optimisation des fuites de mémoire, optimisation de la vitesse de réponse, optimisation de la liste, optimisation des bitmaps, optimisation des threads Optimisation de la mise en page : outil de visualisation de hiérarchie, Solution : 1. Supprimez les espaces et niveaux inutiles. 2. Choisissez un groupe de vues avec des performances inférieures, tel que Relativelayout. Si vous pouvez choisir Relativelayout ou LinearLayout, utilisez d'abord LinearLayout, car la fonction Relativelayout est relativement complexe et consommera plus de ressources CPU. 3. Utilisez les balisesOptimisation du dessin
L'optimisation du dessin signifie que la vue évite un grand nombre d'opérations fastidieuses dans la méthode ondraw, car la méthode ondraw peut être appelée fréquemment. 1. Ne créez pas de nouvelles variables locales dans la méthode ondraw. La méthode ondraw est appelée fréquemment, ce qui peut facilement provoquer un GC. 2. N'effectuez pas d'opérations fastidieuses dans la méthode ondraw. Optimisation de la mémoire : fuite de mémoire de référence. Optimisation de la réponse : le thread principal ne peut pas effectuer d'opérations fastidieuses, les événements tactiles prennent 5 secondes, la diffusion prend 10 secondes et le service prend 20 secondes. Optimisation de Listview : 1. Évitez les opérations fastidieuses dans la méthode getview. 2. Afficher la réutilisation et l'utilisation des visualiseurs. 3. Sliding ne convient pas pour activer le chargement asynchrone. 4. Traiter les données par pagination. 5. Les images utilisent un cache de niveau trois. Optimisation Bitmap : 1. Compressez les images dans des proportions égales. 2. Recyclez les images inutilisées dans le temps Optimisation des threads L'idée de l'optimisation des threads est d'utiliser le pool de threads pour gérer et réutiliser les threads afin d'éviter un grand nombre de threads dans le programme peut également contrôler le nombre de threads simultanés pour éviter le blocage des threads dû à la préemption mutuelle des ressources. Autres optimisations 1. Utilisez moins d'énumérations, qui prennent beaucoup de place. 2. Utilisez des structures de données spécifiques à Android, telles que SparseArray au lieu de hashMap. 3. Utilisez les références douces et les références faibles de manière appropriée.Algorithmes de chiffrement (base64, MD5, chiffrement symétrique et chiffrement asymétrique) et scénarios d'utilisation .
Qu'est-ce que le cryptage Rsa ?L'algorithme RSA est l'algorithme de cryptographie à clé publique le plus populaire, utilisant des clés dont la longueur peut varier. RSA est le premier algorithme pouvant être utilisé à la fois pour le cryptage des données et pour les signatures numériques.
Le principe de l'algorithme RSA est le suivant :
1. Sélectionnez aléatoirement deux grands nombres premiers p et q, p n'est pas égal à q, calculez N=pq ; >2. Choisir un nombre supérieur à Si 1 est inférieur à N, l'entier naturel e doit être premier relativement avec (p-1)(q-1).
3. Utilisez la formule pour calculer d : d×e = 1 (mod (p-1)(q-1)).
4. Détruisez p et q.
Les N et e finaux sont la "clé publique", et d est la "clé privée". L'expéditeur utilise N pour crypter les données, et le destinataire ne peut utiliser que d pour décrypter le contenu des données.
La sécurité de RSA repose sur la décomposition de grands nombres. N inférieur à 1024 bits s'est avéré dangereux, et comme l'algorithme RSA effectue des calculs de grands nombres, RSA est plus rapide que DES fois plus lent, c'est le plus grand. faille de RSA, il ne peut donc généralement être utilisé que pour chiffrer une petite quantité de données ou de clés de chiffrement, mais RSA reste un algorithme de haute résistance.
Scénarios d'utilisation : dans le projet, à l'exception de la connexion, du paiement et d'autres interfaces, le cryptage asymétrique rsa est utilisé et le cryptage symétrique aes est utilisé pour d'autres interfaces. Aujourd'hui, nous allons découvrir le cryptage aes.
Qu'est-ce que le cryptage MD5 ?
Le nom anglais complet de MD5 est "Message-Digest Algorithm 5", qui se traduit par "Message Digest Algorithm 5". Il a évolué à partir de MD2, MD3 et MD4. Il s'agit d'un algorithme de cryptage unidirectionnel. méthode de cryptage irréversible.
Quelles sont les caractéristiques du cryptage MD5 ?
Compressibilité : pour les données de n'importe quelle longueur, la longueur de la valeur MD5 calculée est fixe.
Facile à calculer : il est facile de calculer la valeur MD5 à partir des données originales.
Résistance à la modification : si une modification est apportée aux données d'origine, même si seulement 1 octet est modifié, la valeur MD5 résultante sera très différente.
Anti-collision puissant : étant donné les données originales et leur valeur MD5, il est très difficile de trouver des données avec la même valeur MD5 (c'est-à-dire des données falsifiées).
Scénarios d'application MD5 :
Vérification de cohérence
Signature numérique
Authentification d'accès sécurisée
Qu'est-ce que le cryptage aes ?
Advanced Encryption Standard (anglais : Advanced Encryption Standard, abréviation : AES), également connu sous le nom de méthode de cryptage Rijndael en cryptographie, est une norme de cryptage par blocs adoptée par le gouvernement fédéral américain. Cette norme est utilisée pour remplacer le DES original. Elle a été analysée par de nombreuses parties et est largement utilisée dans le monde.
Principe d'implémentation de HashMap :
HashMap est une implémentation asynchrone de l'interface cartographique basée sur des tables de hachage, qui permet d'utiliser des valeurs nullescomme clé et valeur. Il existe deux structures de base dans le langage de programmation Java, l'une est un tableau et l'autre est un pointeur simulé (référence). Toutes les structures de données peuvent être construites à l'aide de ces deux structures de base, et HashMap ne fait pas exception. HashMap est en fait une structure de données de « hachage de liste chaînée ». C'est une combinaison de tableau et de liste chaînée.
La couche inférieure de HashMap est une structure de données et chaque élément du tableau est une liste chaînée.
Conflit :
La méthode Hashcode() est appelée dans HashMap pour calculer la valeur Hashclde, car deux objets différents en Java peuvent avoir le même Hashcode. Cela a conduit à des conflits.
Solution :
Lorsque HashMap est mis, le code source sous-jacent peut être vu Lorsque le programme essaie de mettre un objet clé-valeur dans un HashMap, il renvoie d'abord la valeur en fonction de la valeur. hashCode() de la clé. Déterminez l'emplacement de stockage de l'entrée. Si la valeur de retour de la méthode hashCode() des deux clés d'entrée est la même, alors leurs emplacements de stockage sont les mêmes. Si les deux clés d'entrée renvoient vrai par comparaison égale. , la valeur de l'entrée nouvellement ajoutée sera Écraser la valeur de l'entrée d'origine, mais la clé ne sera pas écrasée. Au contraire, si false est renvoyé, l'entrée nouvellement ajoutée formera une chaîne d'entrée avec l'entrée d'origine dans le. collection, avec le nouveau ajouté en tête et l'ancien en queue
Le principe d'implémentation de HashMap :
Utilisez le hashCode de la clé pour ressasser et calculer l'indice de l'élément de l'objet actuel dans le tableau.- Si des clés avec la même valeur de hachage apparaissent pendant le stockage, il existe deux situations : 1. Si les clés sont identiques, la valeur d'origine sera écrasée. 2. Si les clés sont différentes (un conflit se produit), placez-les dans la liste chaînée.
- Lors de l'obtention, recherchez directement l'indice correspondant à la valeur de hachage, puis déterminez davantage si la clé est la même, afin d'obtenir la valeur correspondante.
- Le cœur de Hashmap est d'utiliser un tableau pour le stockage lorsqu'un conflit de clé se produit, il est stocké dans une liste chaînée.
- ==============================
1. ?
onCreate() -> onStart() -> onResume() -> onPause() -> onDetroy()
2. Cycle de vie du service ?
Il existe deux façons de démarrer le service, l'une consiste à démarrer via startService(), l'autre consiste à démarrer via bindService(). Différentes méthodes de démarrage ont des cycles de vie différents.
Le cycle de vie d'un service démarré via startService() est le suivant : appelez startService() --> onCreate()--> Si vous commencez de cette manière, vous devez faire attention à plusieurs problèmes. Premièrement : lorsque nous sommes appelés via startService, si nous appelons startService() plusieurs fois, la méthode onCreate() ne sera appelée qu'une seule fois, et onStartConmon() le sera. être appelé plusieurs fois. Lorsque nous appelons stopService(), onDestroy() sera appelé pour détruire le service. Deuxièmement : lorsque nous commençons par startService, transmettons la valeur via l'intention et obtenons la valeur dans la méthode onStartConmon(), nous devons d'abord déterminer si l'intention est nulle.
Lier via bindService(). Cette façon de lier le service, méthode de cycle de vie : bindService-->onCreate()-->onBind()-->unBind()- ->onDestroy( ) bingservice L'avantage de démarrer le service de cette manière est qu'il est plus pratique d'exploiter le service dans l'activité. Par exemple, il existe plusieurs méthodes pour rejoindre le service, a, b Si vous souhaitez l'appeler dans l'activité. , vous devez obtenir l'objet ServiceConnection dans l'activité. Obtenez l'objet de classe de la classe interne dans le service via ServiceConnection, puis utilisez cet objet de classe pour appeler les méthodes de la classe. Bien sûr, cette classe doit hériter de l'objet Binder.
3. Processus de démarrage de l'activité (ne répondez pas au cycle de vie)
Il existe deux situations dans le processus de démarrage de l'application La première consiste à cliquer sur l'icône de l'application correspondante depuis le lanceur de bureau, et la seconde consiste à démarrer une nouvelle activité en appelant startActivity dans l'activité.
Lorsque nous créons un nouveau projet, l'activité racine par défaut est MainActivity, et toutes les activités sont enregistrées dans la pile. Lorsque nous démarrons une nouvelle activité, elle sera placée au-dessus de l'activité précédente, et nous le ferons quand. en cliquant sur l'icône de l'application depuis le bureau, puisque le lanceur lui-même est également une application, lorsque nous cliquons sur l'icône, le système appellera startActivitySately(). Dans des circonstances normales, les informations pertinentes sur l'activité que nous démarrons seront enregistrées dans l'intention, tels que l'action, la catégorie, etc. Lorsque nous installons cette application, le système démarrera également un service de gestion PackaManagerService. Ce service de gestion analysera le fichier AndroidManifest.xml pour obtenir des informations pertinentes dans l'application, telles que le service, l'activité, la diffusion, etc., puis obtiendra des informations sur. composants associés. Lorsque nous cliquons sur l'icône de l'application, la méthode startActivitySately() sera appelée, et à l'intérieur de cette méthode, startActivty() sera appelée, et la méthode startActivity() finira par appeler la méthode startActivityForResult(). Et dans la méthode startActivityForResult(). Étant donné que la méthode startActivityForResult() renvoie un résultat, le système donne directement un -1, ce qui signifie qu'aucun résultat ne doit être renvoyé. La méthode startActivityForResult() démarre en fait l'activité via la méthode execStartActivity() dans la classe Instrumentation. La fonction principale de la classe Instrumentation est de surveiller l'interaction entre le programme et le système. Dans cette méthode execStartActivity(), l'objet proxy d'ActivityManagerService sera obtenu et l'activité sera démarrée via cet objet proxy. Une méthode checkStartActivityResult() sera appelée lors du démarrage. Si ce composant n'est pas configuré dans la liste de configuration, une exception sera levée dans cette méthode. Bien sûr, la dernière chose à appeler est Application.scheduleLaunchActivity() pour démarrer l'activité. Dans cette méthode, un objet ActivityClientRecord est obtenu, et cet ActivityClientRecord utilise le gestionnaire pour envoyer des messages. Le système utilisera l'objet ActivityClientRecord pour chaque composant d'activité. en interne. Description, et l'objet ActivityClientRecord stocke un objet LoaderApk, via lequel handleLaunchActivity est appelé pour démarrer le composant d'activité, et la méthode de cycle de vie de la page est appelée dans cette méthode.
4. Méthodes d'enregistrement de diffusion et différences
Extension ici : quand utiliser l'enregistrement dynamique
Diffusion en diffusion, il existe deux méthodes d'enregistrement principales.
Le Le premier est l'enregistrement statique, qui peut également devenir une diffusion résidente. Ce type de diffusion doit être enregistré dans Androidmanifest.xml. La diffusion enregistrée de cette manière n'est pas affectée par le cycle de vie de la page. toujours La réception d'une diffusion est généralement utilisée lorsque vous souhaitez démarrer l'ordinateur automatiquement, etc. Étant donné que la diffusion dans cette méthode d'enregistrement est une diffusion permanente, elle occupera des ressources CPU.
Le deuxième type est l'enregistrement dynamique, et l'enregistrement dynamique est enregistré dans le code. Cette méthode d'enregistrement est également appelée diffusion non-résidente. Elle est affectée par le cycle de vie. Après avoir quitté la page. En recevant la diffusion, nous l'utilisons généralement pour mettre à jour l'interface utilisateur. Cette méthode d'enregistrement a une priorité plus élevée. Enfin, vous devez le dissocier pour éviter les fuites de mémoire
La diffusion est divisée en diffusion ordonnée et diffusion non ordonnée.
5. La différence entre HttpClient et HttpUrlConnection
Extension ici : quelle méthode de requête est utilisée dans Volley (HttpClient avant 2.3, HttpUrlConnection après 2.3)
Tout d'abord, HttpClient et HttpUrlConnection prennent tous deux en charge le protocole Https. Tous deux téléchargent ou téléchargent des données sous forme de flux, ainsi que ipv6, pooling de connexions et autres. fonctions. HttpClient possède de nombreuses API, donc si vous souhaitez l'étendre sans détruire sa compatibilité, il est difficile de l'étendre. Pour cette raison, Google a directement abandonné ce HttpClient dans Android 6.0.
HttpUrlConnection est relativement léger. , possède relativement peu d'API, est facile à développer et peut répondre à la plupart des transmissions de données d'Android. Volley, framework relativement classique, utilisait HttpClient avant la version 2.3, et HttpUrlConnection après la version 2.3.
6. La différence entre la machine virtuelle Java et la machine virtuelle Dalvik
Machine virtuelle Java :
1. La machine virtuelle Java est basée sur la pile. Les machines basées sur une pile doivent utiliser des instructions pour charger et exploiter les données sur la pile, et davantage d'instructions sont nécessaires.
2. La machine virtuelle Java exécute le bytecode Java. (La classe Java sera compilée en un ou plusieurs fichiers bytecode .class)
Machine virtuelle Dalvik :
1 La machine virtuelle Dalvik est basée sur des registres
2 , Dalvik exécute un format de bytecode .dex personnalisé. (Une fois la classe Java compilée dans un fichier .class, un outil dx sera utilisé pour convertir tous les fichiers .class en un fichier .dex, puis la machine virtuelle Dalvik en lira les instructions et les données
3. Pool constant Il a été modifié pour utiliser uniquement des index 32 bits pour simplifier l'interpréteur
4. Une application, une instance de machine virtuelle et un processus (tous les threads d'application Android correspondent à un thread Linux. , tous exécutés dans Dans son propre bac à sable, différentes applications s'exécutent dans différents processus. Chaque application Android Dalvik reçoit un PID Linux indépendant (app_*))
7. Processus maintenu en vie (processus mort-vivant) )
Extension ici : quelle est la priorité du processus
Les méthodes de maintien des processus Android de l'industrie actuelle sont principalement divisées en trois types : noir, blanc et gris. Leur mise en œuvre approximative L'idée est la suivante :
Maintien en vie noir : différents processus d'application utilisent des diffusions pour se réveiller (y compris en utilisant les diffusions fournies par le système pour se réveiller)
Maintien en vie blanc : démarrez le service de premier plan
Grey keep-alive : utilisez les vulnérabilités du système pour démarrer le service de premier plan
Black keep-alive
Le soi-disant black keep-alive consiste à utiliser différents processus d'application pour se réveiller les uns les autres en utilisant des diffusions. Voici trois comparaisons courantes :
Scénario 1 : Utiliser la diffusion générée par le système pour réveiller l'application lorsque vous allumez le téléphone, changez de réseau, prenez des photos ou filmez des vidéos
Scénario 2 : La connexion à un SDK tiers réveillera également l'application correspondante. Le processus d'application, tel que le SDK WeChat, réveillera WeChat et le SDK Alipay réveillera Alipay. À partir de là, le scénario 3 suivant. sera déclenché directement
Scénario 3 : Si Alipay et Taobao sont installés sur votre téléphone, Tmall, UC et d'autres applications basées sur Alibaba, alors après avoir ouvert une application basée sur Alibaba, vous pouvez en réveiller d'autres. Soit dit en passant, les applications basées sur Alibaba (utilisez simplement Alibaba comme exemple, en fait, le système BAT est similaire
Maintenir la vie blanche
La méthode de maintien de la vie blanche est très simple). Il s'agit d'appeler l'API système pour démarrer un processus de service de premier plan. Cela générera une notification dans la barre de notification du système pour informer l'utilisateur qu'une telle application est en cours d'exécution, même si l'application actuelle passe en arrière-plan. montré ci-dessous pour LBE et QQ Music :
Grey keep-alive
Gray keep-alive, ce type de méthode keep-alive est l'application la plus large. Elle utilise les vulnérabilités du système pour démarrer. un processus de service au premier plan. La différence avec la méthode de démarrage ordinaire est qu'il n'apparaît pas de notification dans la barre de notification du système et qu'il semble qu'un processus de service en arrière-plan soit en cours d'exécution. L'avantage est que l'utilisateur ne peut pas détecter que vous êtes en cours d'exécution. exécuter un processus de premier plan (car la notification n'est pas visible), mais la priorité de votre processus est supérieure à celle des processus d'arrière-plan ordinaires. Alors, comment exploiter les vulnérabilités du système ? Les idées et codes généraux d'implémentation sont les suivants :
Idée 1 : API Idée 2 : API >= 18, démarrer deux services front-end avec le même identifiant en même temps, puis arrêter le service démarré plus tard
Les enfants qui connaissent le système Android savent que le système est en fonction de l'expérience et des considérations de performances, le système ne tuera pas le processus lorsque l'application reviendra en arrière-plan, mais le mettra en cache. Plus vous ouvrez d'applications, plus les processus sont mis en cache en arrière-plan. Lorsque la mémoire système est insuffisante, le système commence à déterminer les processus à supprimer en fonction de son propre ensemble de mécanismes de recyclage de processus afin de libérer de la mémoire pour fournir les applications nécessaires. Ce mécanisme de destruction de processus et de récupération de mémoire est appelé Low Memory Killer. Il est basé sur le mécanisme OOM Killer (Out-Of-Memory killer) du noyau Linux.
L'importance du processus est divisée en 5 niveaux :
Processus de premier plan (Processus de premier plan)
Processus visible (Processus visible)
Processus de service ( Processus de service) )
Processus d'arrière-plan
Processus vide
Après avoir compris Low Memory Killer, apprenons-en plus sur oom_adj. Qu'est-ce que oom_adj ? Il s'agit d'une valeur attribuée par le noyau Linux à chaque processus système, représentant la priorité du processus. Le mécanisme de recyclage des processus détermine s'il faut recycler en fonction de cette priorité. Concernant le rôle de oom_adj, il vous suffit de retenir les points suivants :
Plus le oom_adj du processus est grand, plus la priorité du processus est faible et plus il est facile à tuer et à recycler, plus il est petit ; Autrement dit, plus la priorité du processus est élevée. Plus la valeur est élevée, moins il est susceptible d'être tué et recyclé
Le oom_adj du processus d'application ordinaire> = 0, seul le oom_adj du processus système peut be
Certains fabricants de téléphones mobiles ont intégré ces applications bien connues dans leur propre liste blanche, cela garantit que le processus ne meurt pas pour améliorer l'expérience utilisateur (comme WeChat, QQ et Momo sont tous dans Liste blanche de Xiaomi). S'ils sont supprimés de la liste blanche, ils pourront toujours échapper au sort d'être tués comme les applications ordinaires. Afin d'éviter autant que possible d'être tués, il est préférable de faire un travail d'optimisation honnêtement.
Ainsi, la solution fondamentale pour maintenir le processus en vie revient en fin de compte à l'optimisation des performances. L'immortalité du processus est une proposition complètement fausse après tout !
8. Expliquez le contexte
Le contexte est une classe de base abstraite. Lorsqu'il est traduit par contexte, il peut également être compris comme environnement, qui fournit des informations de base sur l'environnement d'exécution de certains programmes. Il existe deux sous-classes sous Context. ContextWrapper est la classe d'encapsulation des fonctions contextuelles et ContextImpl est la classe d'implémentation des fonctions contextuelles. ContextWrapper a trois sous-classes directes, ContextThemeWrapper, Service et Application. Parmi eux, ContextThemeWrapper est une classe d'encapsulation avec un thème, et l'une de ses sous-classes directes est Activity, donc le contexte d'activité, de service et d'application est différent. Seule l'activité nécessite un thème et le service ne nécessite pas de thème. Il existe trois types de contexte, à savoir l'application, l'activité et le service. Bien que ces trois classes jouent des rôles différents, elles appartiennent toutes à un type de Context et leurs fonctions de Context spécifiques sont implémentées par la classe ContextImpl. Par conséquent, dans la plupart des scénarios, Activité, Service et Application, ces trois types de Context sont tous universels. Cependant, il existe plusieurs scénarios spéciaux, tels que le démarrage d'une activité et l'affichage d'une boîte de dialogue. Pour des raisons de sécurité, Android ne permet pas qu'une activité ou un dialogue apparaisse de nulle part. Le démarrage d'une activité doit être basé sur une autre activité, qui est la pile de retour formée par celle-ci. La boîte de dialogue doit apparaître sur une activité (sauf s'il s'agit d'une boîte de dialogue de type alerte système), donc dans ce scénario, nous ne pouvons utiliser que le contexte de type activité, sinon une erreur se produira.
Les objets obtenus par les méthodes getApplicationContext() et getApplication() sont le même objet d'application, mais les types d'objets sont différents.
Nombre de contextes = Nombre d'activités + Nombre de services + 1 (1 est une application)
9. Comprendre la relation entre l'activité, la vue et la fenêtre
Cette question est vraiment déroutant Bonne réponse. Voici donc une métaphore plus appropriée pour décrire leur relation. L'activité est comme un artisan (unité de contrôle), Window est comme une fenêtre (portant le modèle), View est comme une grille de fenêtre (affichant la vue), LayoutInflater est comme des ciseaux et la configuration XML est comme un dessin de grille de fenêtre.
1 : Lorsque Activity est construit, une fenêtre sera initialisée, PhoneWindow pour être précis.
2 : Cette PhoneWindow a un "ViewRoot", et ce "ViewRoot" est une View ou ViewGroup, qui est la vue racine initiale.
3 : "ViewRoot" ajoute les vues une par une via la méthode addView. Par exemple, TextView, Button, etc.
4 : La surveillance des événements de ces Views est effectuée par WindowManagerService pour recevoir des messages et rappeler la fonction Activity. Par exemple, onClickListener, onKeyDown, etc.
10. Quatre LaunchModes et leurs scénarios d'utilisation
Extension ici : la différence entre la pile (First In Last Out) et la file d'attente (First In First Out)
Stack et The différence entre les files d'attente :
1. La file d'attente est première entrée, première sortie, et la pile est première entrée, dernière sortie
2. "Limitations" des opérations d'insertion et de suppression. Une pile est une liste linéaire qui limite les opérations d'insertion et de suppression à une seule extrémité de la liste. Une file d'attente est une liste linéaire qui limite les insertions à une extrémité du tableau et les suppressions à l'autre.
3. La vitesse de parcours des données est différente
mode standard
C'est le mode par défaut Chaque fois que l'activité est activée, une instance d'activité sera créée et placée dans. la pile de tâches. Scénarios d'utilisation : la plupart des activités.
mode singleTop
S'il y a une instance de l'Activity en haut de la pile de tâches, l'instance sera réutilisée (onNewIntent() de l'instance sera appelée), sinon une nouvelle instance sera créée et placée. En poussant vers le haut de la pile, même si une instance de l'activité existe déjà sur la pile, une nouvelle instance sera créée tant qu'elle n'est pas en haut de la pile. Les scénarios d'utilisation incluent des pages de contenu d'actualités ou des applications de lecture.
Mode singleTask
S'il existe déjà une instance de l'Activity dans la pile, l'instance sera réutilisée (onNewIntent() de l'instance sera appelée). Lorsqu'elle est réutilisée, l'instance sera renvoyée en haut de la pile, de sorte que les instances situées au-dessus seront supprimées de la pile. Si l'instance n'existe pas sur la pile, une nouvelle instance sera créée et placée sur la pile. Le scénario d'utilisation est tel que l'interface principale du navigateur. Quel que soit le nombre d'applications à partir desquelles vous démarrez le navigateur, l'interface principale ne sera démarrée qu'une seule fois. Dans d'autres cas, onNewIntent sera utilisé et les autres pages de l'interface principale seront effacées.
Mode singleInstance
Crée une instance de l'activité dans une nouvelle pile et permet à plusieurs applications de partager l'instance d'activité dans la pile. Une fois qu'une instance d'activité de ce mode existe déjà dans une pile, toute application qui active l'activité réutilisera l'instance dans la pile (onNewIntent() de l'instance sera appelée). L'effet est équivalent à plusieurs applications partageant une seule application. Peu importe qui active l'activité, elles entreront dans la même application. Utilisez des scénarios tels que des rappels d'alarme pour séparer les rappels d'alarme des paramètres d'alarme. N'utilisez pas singleInstance pour les pages intermédiaires. Si vous l'utilisez pour des pages intermédiaires, il y aura des problèmes avec les sauts, tels que : A -> B (singleInstance) -> .
11. Afficher le processus de dessin
Contrôles personnalisés :
1. Ce type de contrôle personnalisé ne nécessite pas que nous le dessinions nous-mêmes, mais un nouveau contrôle composé de contrôles natifs. Comme la barre de titre.
2. Hériter du contrôle d'origine. Ce type de contrôle personnalisé peut ajouter certaines méthodes par lui-même en plus des méthodes fournies par le contrôle natif. Comme créer des coins arrondis et des images circulaires.
3. Contrôles entièrement personnalisés : Tout le contenu affiché sur cette vue est dessiné par nous-mêmes. Par exemple, créez une barre de progression en forme d'ondulation de l'eau.
Processus de dessin de la vue : OnMeasure()——>OnLayout()——>OnDraw()
Première étape : OnMeasure() : Mesurez la taille de la vue. La méthode de mesure est appelée de manière récursive depuis la vue parent de niveau supérieur vers la vue enfant, et la méthode de mesure rappelle OnMeasure.
Étape 2 : OnLayout() : Déterminez la position d'affichage et mettez en page la page. Le processus d'appel récursif de la méthode view.layout de la vue parent de niveau supérieur à la vue enfant signifie que la vue parent place la vue enfant dans la position appropriée en fonction de la taille de la mise en page et des paramètres de mise en page obtenus en mesurant la vue enfant dans le étape précédente.
Étape 3 : OnDraw() : Dessinez la vue. ViewRoot crée un objet Canvas puis appelle OnDraw(). Six étapes : ①, dessinez l'arrière-plan de la vue ; ②, enregistrez le calque de canevas (Couche) ; ③, dessinez le contenu de la vue ; ④, dessinez la sous-vue de la vue, sinon, ne l'utilisez pas ; 🎜>⑤, restaurez le calque ⑥, dessinez la barre de défilement.
12. Les événements View et ViewGroup sont divisés en
1. Il n'y a que deux protagonistes dans la distribution des événements Touch : ViewGroup et View. ViewGroup contient trois événements associés : onInterceptTouchEvent, dispatchTouchEvent et onTouchEvent. La vue contient deux événements liés : dispatchTouchEvent et onTouchEvent. Parmi eux, ViewGroup hérite de View.
2. ViewGroup et View forment une structure arborescente, et le nœud racine est un ViwGroup contenu dans l'activité.
3. Les événements tactiles sont composés d'Action_Down, Action_Move et Aciton_UP. Dans un événement tactile complet, il n'y a qu'un seul Down et Up, et il y a plusieurs Moves, qui peuvent être nuls.
4. Lorsqu'Activity reçoit l'événement Touch, il traverse la sous-vue pour distribuer l'événement Down. Le parcours ViewGroup peut être considéré comme récursif. Le but de la distribution est de trouver la vue qui gère réellement cet événement tactile complet. Cette vue renverra true dans le résultat onTouchuEvent.
5. Lorsqu'une sous-vue renvoie vrai, la distribution de l'événement Down sera arrêtée et la sous-vue sera enregistrée dans le ViewGroup. Les événements Move et Up suivants seront gérés directement par la sous-vue. Étant donné que la sous-vue est enregistrée dans ViewGroup, dans la structure de nœuds ViewGroup multicouche, le ViewGroup de niveau supérieur enregistre l'objet ViewGroup là où se trouve la vue qui gère réellement l'événement : par exemple, dans la structure ViewGroup0-ViewGroup1. -TextView, TextView renvoie true, qui sera enregistré dans ViewGroup1, et ViewGroup1 renverra également true et sera enregistré dans ViewGroup0. Lorsque les événements Move et UP arrivent, ils seront d'abord transmis de ViewGroup0 à ViewGroup1, puis de ViewGroup1 à TextView.
6. Lorsque toutes les sous-vues du ViewGroup ne capturent pas l'événement Down, l'événement onTouch du ViewGroup lui-même sera déclenché. La façon de déclencher consiste à appeler la fonction super.dispatchTouchEvent, qui est la méthode dispatchTouchEvent de la classe parent View. Lorsque toutes les sous-vues ne sont pas traitées, la méthode onTouchEvent d'activité est déclenchée.
7. onInterceptTouchEvent a deux fonctions : 1. Intercepter la distribution des événements Down. 2. Arrêtez la transmission des événements Up et Move à la vue cible, afin que le ViewGroup où se trouve la vue cible capture les événements Up et Move.
13. L'état de sauvegarde de l'activité
onSaveInstanceState(Bundle) sera appelé avant que l'activité n'entre dans l'état d'arrière-plan, c'est-à-dire avant la méthode onStop() et après la méthode onPause
;14. Plusieurs animations sous Android
Animation d'image : elle fait référence à la lecture ordonnée de l'image et au temps de lecture de chaque image pour former un effet d'animation, tel que la barre de rythme que vous souhaitez entendre.
Animation d'interpolation : elle fait référence à la transformation de graphiques via une série d'algorithmes en spécifiant l'état initial, l'heure de changement et la méthode de la vue pour former des effets d'animation. Il existe principalement quatre effets : Alpha, Échelle, Traduire, et Rotation . Remarque : L'effet d'animation est uniquement implémenté dans le calque de vue et ne modifie pas réellement les propriétés de la vue, telles que le glissement de la liste et la modification de la transparence de la barre de titre.
Animation d'attribut : elle n'est prise en charge que dans Android 3.0. L'effet d'animation est formé en modifiant continuellement les attributs de la vue et en la redessinant constamment. Par rapport à l'animation de vue, les propriétés de View sont vraiment modifiées. Par exemple, affichez la rotation, le zoom avant et le zoom arrière.
15. Plusieurs méthodes de communication inter-processus dans Android
La communication entre processus Android, telle que l'intention, le fournisseur de contenu, la diffusion et le service, peut toutes communiquer entre les processus.
intention : cette méthode inter-processus n'est pas une forme d'accès à la mémoire. Elle nécessite la transmission d'un URI, comme passer un appel.
contentProvider : ce formulaire utilise le partage de données pour le partage de données.
service : service à distance, aidl
diffusion
16. Compréhension de l'AIDL
Extension ici : Brève description de Binder
AIDL : Chaque processus possède sa propre instance de Dalvik VM, possède sa propre mémoire indépendante, stocke ses propres données dans sa propre mémoire, effectue ses propres opérations et termine sa propre vie dans son propre petit espace. Aidl est comme un pont entre deux processus, permettant aux données d'être transmises entre les deux processus. Il existe de nombreuses options de communication entre processus, telles que BroadcastReceiver, Messenger, etc., mais BroadcastReceiver utilise plus de ressources système. la communication de processus n'est évidemment pas souhaitable ; lorsque Messenger effectue une communication entre processus, la file d'attente des requêtes est exécutée de manière synchrone et ne peut pas être exécutée simultanément.
Une compréhension simple du mécanisme Binde :
Dans le mécanisme Binder du système Android, il est composé des pilotes Client, Service, ServiceManager et Binder, parmi lesquels Client, service et Service Manager s'exécute dans l'espace utilisateur, le pilote Binder s'exécute dans l'espace noyau. Binder est le ciment qui lie ces quatre composants ensemble. Le composant principal est le pilote Binder qui fournit des fonctions de gestion auxiliaires, et le client et le service sont basés sur le pilote Binder et le gestionnaire de services implémentent la communication entre C/S sur l'installation. Parmi eux, le pilote Binder fournit le fichier de périphérique /dev/binder pour interagir avec le contrôle utilisateur
Le client, le service et le gestionnaire de services communiquent avec le pilote Binder via les méthodes correspondantes d'opérations de fichiers ouverts et ioctl. La communication inter-processus entre le client et le service est mise en œuvre indirectement via le pilote Binder. Le Binder Manager est un processus démon qui gère le service et offre au client la possibilité d'interroger l'interface du service.
17. Le principe de Handler
Le thread principal d'Android ne peut pas effectuer d'opérations fastidieuses et le sous-thread ne peut pas mettre à jour l'interface utilisateur. Il existe donc un gestionnaire, son rôle est d'implémenter la communication entre les threads.
Gestionnaire Il y a quatre objets principaux dans l'ensemble du processus, le gestionnaire, Message, MessageQueue et Looper. Lorsque l'application est créée, l'objet gestionnaire sera créé dans le thread principal
Nous enregistrons le message à envoyer au Message. Le gestionnaire envoie le Message au MessageQueue en appelant la méthode sendMessage, et le gestionnaire. L'objet Looper continuera à appeler la méthode loop()
pour supprimer continuellement les messages de MessageQueue et les transmettre au gestionnaire pour traitement. Cela permet la communication entre les threads.
18. Principe du mécanisme Binder
Dans le mécanisme Binder du système Android, il est composé du client, du service, du ServiceManager et du pilote Binder, parmi lesquels le client, le service et le gestionnaire de services s'exécutent. espace utilisateur, le pilote Binder s'exécute dans l'espace du noyau. Binder est le ciment qui lie ces quatre composants ensemble. Le composant principal est le pilote Binder qui fournit des fonctions de gestion auxiliaires, et le client et le service sont basés sur le pilote Binder et le gestionnaire de services implémentent la communication entre C/S sur l'installation. Le pilote Binder fournit le fichier de périphérique /dev/binder pour interagir avec les contrôles utilisateur, le client, le service et le gestionnaire de services communiquent avec le pilote Binder via les méthodes correspondantes d'opérations de fichiers ioctl. La communication inter-processus entre le client et le service est mise en œuvre indirectement via le pilote Binder. Le Binder Manager est un processus démon qui gère le service et offre au client la possibilité d'interroger l'interface du service.
19. Le principe de la réparation à chaud
Nous savons que la machine virtuelle Java - JVM charge le fichier de classe, tandis que la machine virtuelle Android - Dalvik/ART VM charge le fichier dex. de la classe,
et ils ont tous besoin de ClassLoader lors du chargement des classes. ClassLoader a une sous-classe BaseDexClassLoader, et il y a un tableau
sous BaseDexClassLoader - DexPathList, qui est utilisé pour stocker les fichiers dex When. BaseDexClassLoader passe Lors de l'appel de la méthode findClass, elle parcourt en fait le tableau,
trouve le fichier dex correspondant et le renvoie directement s'il est trouvé. La solution pour la réparation à chaud est d'ajouter le nouveau dex à la collection, et il se trouve devant l'ancien dex,
, il sera donc retiré en premier et restitué.
20. Fuites et gestion de la mémoire Android
(1) La différence entre le débordement de mémoire (MOO) et la fuite de mémoire (l'objet ne peut pas être recyclé).
(2) Causes des fuites de mémoire
(3) Outil de détection des fuites de mémoire------>LeakCanary
Dépassement de mémoire hors mémoire : fait référence à Quand le programme demande de la mémoire, il n'y a pas assez d'espace mémoire pour qu'il puisse l'utiliser, et un manque de mémoire apparaît ; par exemple, s'il demande un nombre entier, mais stocke un nombre qui ne peut être enregistré que par un long, c'est une mémoire. débordement. En termes simples, le débordement de mémoire signifie qu'il n'y a pas assez de mémoire.
Fuite de mémoire : une fuite de mémoire signifie qu'une fois que le programme a demandé de la mémoire, il ne peut pas libérer l'espace mémoire alloué. Les dommages causés par une fuite de mémoire peuvent être ignorés, mais les conséquences de l'accumulation de fuites de mémoire sont graves. peu importe la quantité de mémoire, tôt ou tard elle sera occupée Lumière
Causes des fuites de mémoire :
1. Fuite de mémoire causée par le gestionnaire.
Solution : Déclarez Handler comme une classe interne statique, afin qu'il ne contienne pas de référence à la classe externe SecondActivity, et son cycle de vie n'a rien à voir avec la classe externe
If context. est nécessaire dans Handler, vous pouvez référencer des classes externes via des références faibles
2. Fuites de mémoire causées par le mode singleton.
Solution : le contexte est ApplicationContext. Étant donné que le cycle de vie d'ApplicationContext est cohérent avec l'application, cela ne provoquera pas de fuites de mémoire
3. Fuites de mémoire causées par des classes internes non statiques créant de la statique. cas.
Solution : Modifier la classe interne pour qu'elle soit statique pour éviter les fuites de mémoire
4. Fuites de mémoire causées par des classes internes anonymes non statiques.
Solution : définissez la classe interne anonyme sur statique.
5. Fuites de mémoire causées par une utilisation non appariée de l'enregistrement/désenregistrement.
Enregistrez le récepteur de diffusion, EventBus, etc., n'oubliez pas de dissocier.
6. Fuites de mémoire causées par la non-fermeture des objets ressources.
Lorsque ces ressources ne sont pas utilisées, pensez à appeler les méthodes correspondantes telles que close(), destroy(), recycler(), release(), etc. pour les libérer.
7. Fuites de mémoire causées par l'incapacité de nettoyer les objets de collection à temps.
Habituellement, certains objets sont chargés dans une collection lorsqu'ils ne sont pas utilisés, vous devez penser à nettoyer la collection à temps afin que les objets associés ne soient plus référencés.
21. Comment Fragment communique avec Fragment et Activity
1. Appelez directement la méthode dans un autre Fragment dans un Fragment
2. Utilisez le rappel d'interface
. 3. Utilisez la diffusion
4.Fragment appelle directement la méthode publique dans l'activité
22 Adaptation de l'interface utilisateur Android
Pour les polices, utilisez sp, utilisez dp, utilisez plus match_parent, wrap_content. , poids
ressources d'images, la résolution des différentes images peut être remplacée par un pourcentage lorsqu'elles sont placées dans le dossier correspondant.
23. Optimisation de l'application
Optimisation de l'application : (Outil : outil de mise en page de l'analyse de la visionneuse de hiérarchie : l'analyse des tests TraceView prend du temps)
Optimisation du démarrage de l'application
Optimisation de la mise en page
Optimisation de la réponse
Optimisation de la mémoire
Optimisation de l'utilisation de la batterie
Optimisation du réseau
Optimisation du démarrage de l'application (pour démarrage à froid)
Il existe trois façons de démarrer l'application :
Démarrage à froid : l'application n'a pas été démarrée ou le processus d'application a été interrompu et le processus d'application n'existe pas dans le système. L'application en ce moment est un démarrage à froid.
Démarrage à chaud : le démarrage à chaud signifie que le processus de votre application est uniquement en arrière-plan et que le système le fait simplement passer de l'arrière-plan au premier plan et l'affiche à l'utilisateur.
C'est entre le démarrage à froid et le démarrage à chaud. De manière générale, cela se produit dans les deux situations suivantes :
(1) L'utilisateur quitte l'application puis la redémarre. peut-être encore. Il est en cours d'exécution, mais l'activité doit être reconstruite.
(2) Une fois que l'utilisateur a quitté l'application, le système peut tuer l'application pour des raisons de mémoire, et le processus et l'activité doivent être redémarrés. Cependant, l'état de l'instance enregistré du verrou d'arrêt passif peut être redémarré. être restauré dans onCreate .
Optimisation :
OnCreate de l'application (en particulier l'initialisation du SDK tiers) et le rendu de l'activité sur le premier écran n'ont pas besoin d'effectuer des opérations fastidieuses. Si tel est le cas, ils peuvent être placés dans. threads enfants ou IntentServices
Optimisation de la mise en page
Essayez de ne pas effectuer d'imbrication trop complexe. Vous pouvez utiliser
Optimisation de la réponse
Le système Android enverra un signal VSYNC toutes les 16 ms pour redessiner notre interface (Activité).
Raisons du décalage de page :
(1) Mise en page trop complexe.
(2) Opérations complexes sur le fil de l'interface utilisateur
(3) Fréquent là-bas Il y a deux raisons pour les GC fréquents : 1. La gigue de la mémoire, c'est-à-dire qu'un grand nombre d'objets sont créés et libérés immédiatement dans un court laps de temps. 2. La génération d'un grand nombre d'objets en un instant occupera sérieusement la zone mémoire.
Optimisation de la mémoire : reportez-vous à la section Fuite de mémoire et débordement de mémoire
Optimisation de l'utilisation de la batterie (utiliser les outils : Batterystats & bugreport)
(1) Optimiser les requêtes réseau
(2) Lorsque vous utilisez le GPS pour le positionnement, n'oubliez pas de l'éteindre à temps
L'optimisation du réseau (l'impact des connexions réseau sur les utilisateurs : trafic, alimentation, attente des utilisateurs) peut être détectée par l'outil Moniteur réseau à côté de Logcat sous Android Studio
Conception de l'API : la conception de l'API entre l'application et le serveur doit prendre en compte la fréquence des requêtes réseau, l'état des ressources, etc. afin que l'application puisse répondre aux exigences commerciales et à l'interface. afficher avec moins de requêtes.
Compression Gzip : utilisez Gzip pour compresser les requêtes et les réponses, réduisant ainsi la quantité de données transmises, réduisant ainsi la consommation de trafic
Taille de l'image : vous pouvez informer le serveur. de la largeur et de la hauteur requises de l'image lors de l'obtention de l'image, afin que le serveur puisse donner les images d'image appropriées pour éviter le gaspillage
Mise en cache réseau : une mise en cache appropriée peut non seulement rendre notre application plus rapide, mais également. éviter une consommation de trafic inutile.
24. Optimisation de l'image
(1) Opérer sur l'image elle-même. Essayez de ne pas utiliser setImageBitmap, setImageResource, BitmapFactory.decodeResource pour définir une grande image, car une fois le décodage terminé, ces méthodes sont finalement complétées via createBitmap de la couche Java, ce qui nécessite plus de mémoire.
(2) La mise à l'échelle rapport de l'image. Le SDK recommande que la valeur soit une valeur exponentielle de 2. Plus la valeur est grande, plus la valeur sera grande, l'image ne sera pas claire.
(3) N'oubliez pas d'appeler la méthode recycle() des images lorsqu'elles ne sont pas utilisées
25 Interaction entre HybridApp WebView et JS
Android et JS s'appellent mutuellement. via WebView. En fait, oui :
Android appelle le code JS
1. Grâce à loadUrl() de WebView, l'utilisation de cette méthode est plus simple et plus pratique. Cependant, le rendement est relativement faible et il est difficile d’obtenir la valeur de retour.
2. Grâce à évaluerJavascript() de WebView, cette méthode est très efficace, mais elle n'est prise en charge que par les versions supérieures à 4.4 et non par les versions inférieures à 4.4. Il est donc recommandé d’utiliser un mélange des deux.
JS appelle le code Android
1. Le mappage d'objets est effectué via addJavascriptInterface() de WebView. Cette méthode est simple à utiliser et mappe uniquement les objets Android et les objets JS, mais elle présente des failles relativement importantes. .
La raison de la vulnérabilité est la suivante : lorsque JS obtient l'objet Android, il peut appeler toutes les méthodes de l'objet Android, y compris la classe système (classe java.lang.Runtime), exécutant ainsi du code arbitraire.
Solution :
(1) Google stipule dans Android 4.2 que les fonctions appelées soient annotées avec @JavascriptInterface pour éviter les attaques de vulnérabilité.
(2) Utilisez intercept prompt() pour corriger la vulnérabilité avant la version Android 4.2.
2. Interceptez l'URL via le rappel de la méthode ShouldOverrideUrlLoading () de WebViewClient. Les avantages de cette méthode : il n'y a pas de failles dans la méthode 1 ; inconvénients : l'obtention par JS de la valeur de retour de la méthode Android est compliquée. (ios utilise principalement cette méthode)
(1) Android intercepte l'url via la méthode de rappel ShouldOverrideUrlLoading () de WebViewClient
(2) Analyse le protocole de l'url
( 3) Si un protocole préalablement convenu est détecté, appelez la méthode correspondante
3. Interceptez la boîte de dialogue JS alert(), confirm() via la méthode onJsAlert(), onJsConfirm(), onJsPrompt() rappels de WebChromeClient ), message prompt()
Avantages de cette méthode : Il n'y a pas de faille dans la méthode 1 Inconvénients : L'obtention par JS de la valeur de retour de la méthode Android est compliquée ;
26. Principe JAVA GC
L'idée principale de l'algorithme de récupération de place est d'identifier l'espace mémoire disponible de la machine virtuelle, c'est-à-dire les objets dans l'espace du tas. l'objet est référencé, alors appelez-le C'est un objet survivant
Au contraire, si l'objet n'est plus référencé, c'est un objet poubelle, et l'espace qu'il occupe peut être recyclé pour réallocation. Le choix de l'algorithme de garbage collection et l'ajustement raisonnable des paramètres du système de garbage collection affectent directement les performances du système.
27. ANR
Le nom complet de l'ANR est Application Not Responding, qui signifie "Application Not Responding". Lorsque l'opération ne peut pas être traitée par le système dans un délai donné, un ANR. comme celui illustré ci-dessus apparaîtra au niveau du système.
Cause :
(1) Impossible de répondre aux événements de saisie de l'utilisateur (tels que la saisie au clavier, l'écran tactile, etc. ) dans les 5 s.
(2) BroadcastReceiver dans 10 s Impossible de se terminer dans les 20 secondes
(3) Le service ne peut pas se terminer dans les 20 s (faible probabilité)
Solution :
(1) N'effectuez pas d'opérations fastidieuses dans le thread principal, mais doit être implémenté dans un thread enfant. Par exemple, effectuez le moins d'opérations de création possible dans onCreate() et onResume().
(2) Les applications doivent éviter d'effectuer des opérations ou des calculs fastidieux dans BroadcastReceiver.
(3) Évitez de démarrer une activité dans le récepteur d'intention, car cela créerait un nouvel écran et détournerait le focus du programme actuellement exécuté par l'utilisateur.
(4) Le service s'exécute sur le thread principal, les opérations fastidieuses du service doivent donc être placées dans des threads enfants.
28. Modèle de conception
Extension ici : une double vérification doit être écrite.
Mode cas unique : divisé en style méchant et style paresseux
Style méchant :
public class Singleton
{
private static Singleton instance = new Singleton();
public static Singleton getInstance()
{
return instance ;
}
}Style paresseux :
public class Singleton02
{
private static Singleton02 instance;
public static Singleton02 getInstance()
{
if (instance == null)
{
synchronized (Singleton02.class)
{
if (instance == null)
{
instance = new Singleton02();
}
}
}
return instance;
}
}29, RxJava
30. MVP, MVC, MVVM
Extension ici : exemple mvp manuscrit, différence entre mvc et mvc, avantages du mvp
Mode MVP, correspondant au Model--Business Modèles logiques et d'entités, vue - correspond à l'activité, est responsable du dessin de la vue et de l'interaction avec l'utilisateur, Présentateur - est responsable de l'interaction entre la vue et le modèle. Le mode MVP est basé sur le mode MVC, complètement séparé. le modèle et la vue pour que le couplage du projet soit encore plus faible. Dans MVC, l'activité dans le projet correspond au contrôleur C dans MVC, et le traitement logique dans le projet est traité dans ce C. En même temps. Au fil du temps, l'interaction entre View et Model est également dit que toutes les interactions logiques et les interactions utilisateur dans mvc sont placées dans le contrôleur, c'est-à-dire dans l'activité. La vue et le modèle peuvent communiquer directement. Le modèle MVP est plus complètement séparé et a une division du travail plus claire. Le modèle - logique métier et modèle d'entité, vue - est responsable de l'interaction avec les utilisateurs, et le présentateur est responsable de compléter l'interaction entre la vue et le modèle. La plus grande différence entre MVP. et MVC est que dans MVC permet au modèle et à la vue d'interagir, et il est évident dans MVP que l'interaction entre le modèle et la vue est complétée par le présentateur. Un autre point est que l'interaction entre Presenter et View se fait via l'interface
31. Algorithme d'écriture manuscrite (il faut savoir choisir le bullage)
JNI
(1 ) Installez et téléchargez Cygwin, téléchargez Android NDK
(2) Conception de l'interface JNI dans le projet ndk
(3) Utilisez C/C++ pour implémenter des méthodes locales
(4 ) JNI génère le fichier .so de la bibliothèque de liens dynamiques
(5) Copiez la bibliothèque de liens dynamiques dans le projet Java, appelez-la dans le projet Java et exécutez le projet Java
33. RecyclerView et ListView La différence
RecyclerView peut compléter les effets de ListView et GridView, ainsi que l'effet du flux en cascade. Dans le même temps, vous pouvez également définir le sens de défilement de la liste (vertical ou horizontal) ;
La réutilisation des vues dans RecyclerView ne nécessite pas que les développeurs écrivent eux-mêmes le code, le système l'a déjà empaqueté pour vous.
RecyclerView peut effectuer une actualisation partielle.
RecyclerView fournit une API pour implémenter des effets d'animation d'éléments.
En termes de performances :
Si vous devez actualiser fréquemment les données et ajouter des animations, RecyclerView présente un plus grand avantage.
S'il est simplement affiché sous forme de liste, la différence entre les deux n'est pas très grande.
34. Comparaison d'Universal-ImageLoader, Picasso, Fresco et Glide
Fresco est un outil de mise en cache d'images open source lancé par Facebook. Ses principales fonctionnalités incluent : deux caches mémoire plus la formation de cache natif. une mise en cache à trois niveaux,
Avantages :
1. Les images sont stockées dans la mémoire partagée anonyme du système Android, plutôt que dans la mémoire tas de la machine virtuelle. de l'image est également stockée dans la mémoire de tas locale, de sorte que l'application utilise davantage de mémoire, ne provoquera pas de MOO en raison du chargement de l'image et réduit également le décalage d'interface provoqué par les appels fréquents du garbage collector pour recycler Bitmap, ce qui entraîne performances supérieures.
2. Chargement progressif des images JPEG, prenant en charge le chargement des images du flou au clair.
3. L'image peut être affichée dans ImageView à n'importe quel point central, pas seulement au centre de l'image.
4. Le redimensionnement des images JPEG se fait également de manière native, et non dans la mémoire tas de la machine virtuelle, ce qui réduit également le MOO.
5. Très bon support pour l'affichage des images GIF.
Inconvénients :
1. Le framework est volumineux, ce qui affecte la taille de l'Apk
2 Il est fastidieux à utiliser
Universal-ImageLoader : ( On estime que HttpClient est remplacé par Google. Si vous abandonnez, l'auteur renoncera à maintenir ce framework)
Avantages :
Prend en charge le suivi de la progression du téléchargement
2. . Le chargement de l'image peut être suspendu pendant le défilement de la vue via l'interface PauseOnScrollListener.
3. Implémentez plusieurs algorithmes de mise en cache de mémoire par défaut. Ces caches d'images peuvent tous être configurés avec des algorithmes de mise en cache, mais ImageLoader implémente de nombreux algorithmes de mise en cache par défaut, tels que la taille la plus grande en premier, la suppression la moins utilisée et la moins récemment utilisée. , premier entré, premier sorti, le plus long entré, premier sorti, etc.
4. Prise en charge de la définition des règles de nom de fichier de cache local
Avantages Picasso
1. Livré avec une fonction de surveillance statistique. Prend en charge la surveillance de l'utilisation du cache d'images, y compris le taux de réussite du cache, la taille de la mémoire utilisée, le trafic enregistré, etc.
2. Prise en charge du traitement prioritaire. Avant que chaque tâche ne soit planifiée, une tâche avec une priorité plus élevée sera sélectionnée. Par exemple, cela est très approprié lorsque la priorité de la bannière dans la page de l'application est supérieure à celle de l'icône.
3. Prise en charge du délai jusqu'à ce que le calcul de la taille de l'image soit terminé et le chargement
4. Prise en charge du mode vol, le nombre de threads simultanés change en fonction du type de réseau. Lorsque le téléphone passe en mode avion ou que le type de réseau change, le nombre maximum de simultanéité du pool de threads sera automatiquement ajusté. Par exemple, le nombre maximum de simultanéité du wifi est 4, 4g est 3 et 3g est 2. Ici, Picasso détermine le nombre maximum de simultanéités en fonction du type de réseau, et non du nombre de cœurs de processeur.
5. Cache local "Aucun". "Pas" de cache local ne signifie pas qu'il n'y a pas de cache local, mais Picasso lui-même ne l'a pas implémenté et l'a confié à une autre bibliothèque réseau de Square, okhttp, pour l'implémenter. L'avantage est que l'image peut être contrôlée. en demandant Cache-Control et Expired dans l'en-tête de réponse
Avantages de Glide
1 Il peut non seulement mettre en cache des images mais également mettre en cache des fichiers multimédias. cache, il prend en charge Gif, WebP et même Video. , il doit donc être utilisé comme cache multimédia
2. Prise en charge du traitement prioritaire
3. Conformément au cycle de vie de l'activité/du fragment. , Glide prend en charge trimMemory pour maintenir un RequestManager pour chaque contexte. , via FragmentTransaction, il reste cohérent avec le cycle de vie Activity/Fragment, et il existe une implémentation d'interface trimMemory correspondante disponible pour l'appel
4. Prend en charge okhttp et. Volley. Glide obtient les données via UrlConnection par défaut et peut être utilisé avec okhttp ou Volley. En fait, ImageLoader et Picasso prennent également en charge okhttp et Volley 5. Le cache mémoire de Glide a une conception active. cache, ce n'est pas comme l'implémentation générale de get. Utilisez Remove, puis placez ces données mises en cache dans une carte activeResources dont la valeur est une référence logicielle, et comptez le nombre de références une fois l'image chargée, elle sera jugée. Si le nombre de références est vide, l'image la plus petite sera recyclée et Glide mettra en cache l'image la plus petite. Utilisez l'url, view_width, view_height, la résolution de l'écran, etc. comme clés communes pour mettre en cache l'image traitée dans le cache mémoire au lieu de l'original. image pour enregistrer une taille cohérente avec le cycle de vie d'activité/fragment. TrimMemory est pris en charge par défaut pour les images RGB_565 au lieu de ARGB_888, bien que la définition soit pire, l'image est plus petite et peut également être configurée sur ARGB_888
. 6. Glide peut prendre en charge l'expiration de l'URL via la signature ou sans utiliser le cache local
42. Comparaison de Xutils, OKhttp, Volley, Retrofit
Xutils est un framework très complet qui peut effectuer des requêtes réseau, des images chargement, stockage des données et annotation des vues. Il est très pratique d'utiliser ce framework, mais il présente des inconvénients. Il est également très évident que l'utilisation de ce projet rendra le projet très dépendant de ce framework une fois qu'il y aura un problème avec. ce cadre, cela aura un grand impact sur le projet. ,
OKhttp : dans le développement Android, vous pouvez utiliser directement l'API prête à l'emploi pour effectuer des requêtes réseau. Utilisez simplement HttpClient et HttpUrlConnection pour fonctionner. Pour les programmes Java et Android, okhttp encapsule une bibliothèque de requêtes http hautes performances qui prend en charge la synchronisation et l'asynchronisme. De plus, okhttp encapsule également le pool de threads, la conversion des données, l'utilisation des paramètres, la gestion des erreurs, etc. L'API est plus pratique à utiliser. Mais lorsque nous l'utilisons dans le projet, nous devons toujours créer nous-mêmes une couche d'encapsulation, afin qu'elle puisse être utilisée plus facilement.
Volley : Volley est une petite et élégante bibliothèque de requêtes asynchrones officiellement publiée par Google. Le framework est hautement évolutif et prend en charge HttpClient, HttpUrlConnection et même OkHttp, encapsule également ImageLoader. Il n'est même pas nécessaire d'utiliser un framework de chargement d'images. Cependant, cette fonction n'est pas aussi puissante que certains frameworks de chargement d'images spécialisés. Elle peut être utilisée pour des besoins simples, mais des exigences plus complexes nécessitent toujours l'utilisation d'un framework de chargement d'images spécialisé. Volley présente également des défauts, tels que le fait de ne pas prendre en charge la publication de données volumineuses, il n'est donc pas adapté au téléchargement de fichiers. Cependant, l'intention initiale de la conception de Volley elle-même est de répondre à des requêtes réseau fréquentes avec de petits volumes de données.
Retrofit : Retrofit est un framework de requête réseau RESTful basé sur l'encapsulation OkHttp par défaut produit par Square. RESTful est un style de conception d'API actuellement populaire et n'est pas un standard. L'encapsulation de Retrofit peut être considérée comme très puissante. Elle implique un certain nombre de modèles de conception. Les requêtes peuvent être configurées directement via des annotations. Bien que http soit utilisé par défaut, différents convertisseurs Json peuvent être utilisés pour sérialiser les données. En même temps, fournir un support pour RxJava, en utilisant Retrofit + OkHttp + RxJava + Dagger2 On peut dire qu'il s'agit d'un framework relativement tendance à l'heure actuelle, mais il nécessite un seuil relativement élevé.
Volley VS OkHttp
L'avantage de Volley est qu'il est mieux encapsulé, alors qu'en utilisant OkHttp, vous devez avoir suffisamment de capacité pour encapsuler à nouveau. L'avantage d'OkHttp est des performances plus élevées. Parce qu'OkHttp est basé sur NIO et Okio, les performances sont plus rapides que Volley. IO et NIO sont deux concepts en Java. Si je lis des données à partir du disque dur, la première méthode consiste à ce que le programme attende que les données soient lues avant de continuer. C'est la plus simple et est également appelée blocage d'IO. lisez vos données, le programme continue de s'exécuter et vous m'informez une fois les données traitées, puis gérez le rappel. La deuxième méthode est NIO, qui est non bloquante, donc bien sûr NIO a de meilleures performances que IO. Okio est une bibliothèque créée par Square basée sur IO et NIO qui est plus simple et plus efficace dans le traitement des flux de données. Théoriquement, si vous comparez Volley avec OkHttp, vous êtes plus enclin à utiliser Volley, car Volley prend également en charge l'utilisation d'OkHttp en interne, donc l'avantage en termes de performances d'OkHttp a disparu, et Volley lui-même est plus facile à utiliser et a une meilleure évolutivité.
OkHttp VS Retrofit
Il ne fait aucun doute que Retrofit est un package basé sur OkHttp par défaut. Il n'y a pas de comparaison à cet égard, et Retrofit est définitivement préféré.
Volley VS Retrofit
Les deux bibliothèques sont bien encapsulées, mais Retrofit est plus complètement découplé, surtout lorsque Retrofit 2.0 est sorti, Jake a abordé les aspects déraisonnables de la conception 1.0 précédente. Beaucoup de refactorisation. , les responsabilités sont plus subdivisées et Retrofit utilise OkHttp par défaut, ce qui présente un avantage sur Volley en termes de performances. De plus, si votre projet utilise RxJava, vous devez utiliser Retrofit. Par conséquent, par rapport à ces deux bibliothèques, Retrofit présente plus d'avantages. Si vous maîtrisez les deux frameworks, vous devez d'abord utiliser Retrofit. Cependant, le seuil de Retrofit est légèrement supérieur à celui de Volley. Il faut un certain effort pour comprendre ses principes et ses diverses utilisations. Si vous souhaitez bien le comprendre, il est recommandé d'utiliser Volley dans des projets commerciaux.
Java
1. La différence entre sleep et wait dans les threads
(1) Ces deux méthodes proviennent de classes différentes, sleep vient de Thread et wait vient d'Object. ;
(2) La méthode sleep ne libère pas le verrou, mais la méthode wait libère le verrou.
(3) wait, notify, notifyAll ne peut être utilisé que dans les méthodes de contrôle de synchronisation ou les blocs de contrôle de synchronisation, tandis que sleep peut être utilisé n'importe où.
2. Quelle est la différence entre les méthodes start() et run() dans Thread ?
La méthode start() est utilisée pour démarrer un thread nouvellement créé, et start() en interne appelle la méthode run(), ce qui est différent de l'appel direct de la méthode run(). Si la méthode run() est appelée directement,
n'est pas différente de la méthode ordinaire.
3. Comment utiliser les mots-clés final et static.
final :
1. La variable finale est une constante et ne peut se voir attribuer une valeur qu'une seule fois.
2. La méthode finale ne peut pas être remplacée par les sous-classes.
3. Les classes finales ne peuvent pas être héritées.
statique :
1. Variables statiques : il n'y a qu'une seule copie des variables statiques en mémoire (économie de mémoire) La JVM n'alloue qu'une seule fois,
lors du chargement. une classe L'allocation de mémoire des variables statiques est complétée dans le processus et est accessible directement par nom de classe (pratique, bien sûr, elle est également accessible via des objets (mais ce n'est pas recommandé).
2. Bloc de code statique
Le bloc de code statique est automatiquement exécuté lors de l'initialisation lorsque la classe est chargée.
3. Méthode statique
La méthode statique peut être appelée directement via le nom de la classe, et n'importe quelle instance peut également être appelée, de sorte que les mots-clés this et super ne peuvent pas être utilisés dans la méthode statique,
Vous ne pouvez pas accéder directement aux variables d'instance et aux méthodes d'instance de la classe à laquelle vous appartenez (c'est-à-dire aux variables membres et aux méthodes membres sans statique), vous ne pouvez accéder qu'aux variables membres statiques et aux méthodes membres de la classe à laquelle vous appartenez.
4. Différences entre String, StringBuffer et StringBuilder
1. La vitesse d'exécution des trois : StringBuffer > être recréé lors de l'épissage d'un nouvel objet).
2. StringBuffer est thread-safe et StringBuilder n'est pas thread-safe. (Parce que StringBuffer a un tampon)
5. La différence entre la surcharge et la réécriture en Java :
1 Surcharge : Il peut y avoir plusieurs méthodes avec le même nom dans une classe, mais les paramètres. Le type et le nombre sont différents. C'est une surcharge.
2. Réécriture : Si une sous-classe hérite de la classe parent, la sous-classe peut implémenter les méthodes de la classe parent, de sorte que la nouvelle méthode écrase l'ancienne méthode de la classe parent.
6. La différence entre Http et https
Extension ici : le principe de mise en œuvre de https
1 Le protocole https nécessite de demander un certificat à partir de ca. Il y a moins de certificats gratuits, cela nécessite donc un certain coût.
2. http est un protocole de transfert hypertexte et les informations sont transmises en texte brut, tandis que https est un protocole de transmission sécurisé et crypté SSL.
3. http et https utilisent des méthodes de connexion complètement différentes et utilisent des ports différents. Le premier est 80 et le second est 443.
4. La connexion http est très simple et sans état ; le protocole HTTPS est un protocole réseau construit à partir du protocole SSL+HTTP qui peut effectuer une transmission cryptée et une authentification d'identité, et est plus sécurisé que le protocole http.
Principe de mise en œuvre https :
(1) Le client utilise l'URL https pour accéder au serveur web et nécessite qu'une connexion SSL soit établie avec le serveur web.
(2) Après avoir reçu la demande du client, le serveur Web transmettra une copie des informations du certificat du site Web (le certificat contient la clé publique) au client.
(3) Le navigateur du client et le serveur Web commencent à négocier le niveau de sécurité de la connexion SSL, qui est le niveau de cryptage des informations.
(4) Le navigateur du client établit une clé de session en fonction du niveau de sécurité convenu par les deux parties, puis utilise la clé publique du site Web pour crypter la clé de session et la transmet au site Web.
(5) Le serveur Web utilise sa propre clé privée pour déchiffrer la clé de session.
(6) Le serveur Web utilise la clé de session pour crypter la communication avec le client.
7. À quelle couche du modèle TCP/IP se trouve HTTP ? Pourquoi HTTP est-il un protocole de transfert de données fiable ?
Modèle TCP/IP à cinq couches :
De bas en haut : couche physique->couche de liaison de données->couche réseau->couche de transport->couche d'application
Parmi eux, tcp/ip est situé au niveau de la couche réseau dans le modèle, et ICMP (Network Control Message Protocol) est également au niveau de la même couche. http est situé dans la couche application dans le modèle
Étant donné que tcp/ip est un protocole fiable orienté connexion et que http est basé sur le protocole tcp/ip dans la couche transport, http est donc une transmission de données fiable protocole.
8. Caractéristiques des liens HTTP
La caractéristique la plus importante des connexions HTTP est que chaque requête envoyée par le client nécessite que le serveur renvoie une réponse une fois la requête terminée, la connexion est établie. sera activement publié.
Le processus allant de l'établissement d'une connexion à la fermeture de la connexion est appelé « une connexion ».
9. La différence entre TCP et UDP
tcp est orientée connexion Étant donné que la connexion TCP nécessite trois poignées de main, elle peut minimiser le risque et garantir la fiabilité de la connexion.
udp n'est pas orienté connexion. Udp n'a pas besoin d'établir une connexion avec l'objet avant d'établir une connexion. Aucun signal de confirmation n'est envoyé, qu'il soit en envoi ou en réception. UDP n'est donc pas fiable.
Étant donné qu'UDP n'a pas besoin de confirmer la connexion, UDP a moins de surcharge et un taux de transmission plus élevé, le fonctionnement en temps réel est donc meilleur.
10. Étapes permettant à Socket d'établir une connexion réseau
L'établissement d'une connexion Socket nécessite au moins une paire de sockets, dont l'une s'exécute avec le client --ClientSocket, et l'autre avec le client. server--ServiceSocket
1. Surveillance du serveur : le socket côté serveur ne localise pas le socket client spécifique, mais est en état d'attente de connexion, surveillant l'état du réseau en temps réel et attendant le demande de connexion du client.
2. Requête client : fait référence au socket du client faisant une demande de connexion, et la cible à connecter est le socket du serveur. Remarque : Le socket du client doit décrire le socket du serveur auquel il souhaite se connecter.
indique l'adresse et le numéro de port du socket serveur, puis fait une demande de connexion tout comme le socket côté serveur.
3. Confirmation de connexion : lorsque le socket côté serveur surveille la demande de connexion du socket client, il répond à la demande du socket client, établit un nouveau thread et connecte le socket côté serveur au socket client. La description du mot
est envoyée au client Une fois que le client confirme cette description, les deux parties établissent formellement une connexion. Le socket serveur reste à l'état d'écoute et continue de recevoir des demandes de connexion d'autres sockets clients.
11. Prise de contact à trois voies TCP/IP, quatre vagues
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1672
1672
 14
1428
52
1333
25
1277
29
1257
24
14
1428
52
1333
25
1277
29
1257
24

 Un nouveau rapport fournit une évaluation accablante des rumeurs de mise à niveau des appareils photo des Samsung Galaxy S25, Galaxy S25 Plus et Galaxy S25 Ultra
Sep 12, 2024 pm 12:23 PM
Un nouveau rapport fournit une évaluation accablante des rumeurs de mise à niveau des appareils photo des Samsung Galaxy S25, Galaxy S25 Plus et Galaxy S25 Ultra
Sep 12, 2024 pm 12:23 PM
Ces derniers jours, Ice Universe n'a cessé de révéler des détails sur le Galaxy S25 Ultra, qui est largement considéré comme le prochain smartphone phare de Samsung. Entre autres choses, le fuyard a affirmé que Samsung prévoyait d'apporter une seule mise à niveau de l'appareil photo.
 Le Samsung Galaxy S25 Ultra fuit dans les premières images de rendu avec des rumeurs de modifications de conception révélées
Sep 11, 2024 am 06:37 AM
Le Samsung Galaxy S25 Ultra fuit dans les premières images de rendu avec des rumeurs de modifications de conception révélées
Sep 11, 2024 am 06:37 AM
OnLeaks s'est désormais associé à Android Headlines pour offrir un premier aperçu du Galaxy S25 Ultra, quelques jours après une tentative infructueuse de générer plus de 4 000 $ auprès de ses abonnés X (anciennement Twitter). Pour le contexte, les images de rendu intégrées ci-dessous h
 IFA2024 | Le NXTPAPER 14 de TCL n'égalera pas la Galaxy Tab S10 Ultra en termes de performances, mais il lui correspond presque en taille
Sep 07, 2024 am 06:35 AM
IFA2024 | Le NXTPAPER 14 de TCL n'égalera pas la Galaxy Tab S10 Ultra en termes de performances, mais il lui correspond presque en taille
Sep 07, 2024 am 06:35 AM
En plus d'annoncer deux nouveaux smartphones, TCL a également annoncé une nouvelle tablette Android appelée NXTPAPER 14, et sa taille d'écran massive est l'un de ses arguments de vente. Le NXTPAPER 14 est doté de la version 3.0 de la marque emblématique de panneaux LCD mats de TCL.
 Vivo Y300 Pro contient une batterie de 6 500 mAh dans un boîtier mince de 7,69 mm
Sep 07, 2024 am 06:39 AM
Vivo Y300 Pro contient une batterie de 6 500 mAh dans un boîtier mince de 7,69 mm
Sep 07, 2024 am 06:39 AM
Le Vivo Y300 Pro vient d'être entièrement dévoilé et c'est l'un des téléphones Android de milieu de gamme les plus fins avec une grande batterie. Pour être exact, le smartphone ne fait que 7,69 mm d'épaisseur mais dispose d'une batterie de 6 500 mAh. C'est la même capacité que le lancement récent
 Le Samsung Galaxy S24 FE est annoncé pour un lancement moins cher que prévu en quatre couleurs et deux options de mémoire
Sep 12, 2024 pm 09:21 PM
Le Samsung Galaxy S24 FE est annoncé pour un lancement moins cher que prévu en quatre couleurs et deux options de mémoire
Sep 12, 2024 pm 09:21 PM
Samsung n'a pas encore donné d'indications sur la date à laquelle il mettrait à jour sa série de smartphones Fan Edition (FE). Dans l’état actuel des choses, le Galaxy S23 FE reste l’édition la plus récente de la société, ayant été présentée début octobre 2023. Cependant, de nombreux
 Le Motorola Razr 50s se présente comme un nouveau budget pliable possible lors d'une fuite précoce
Sep 07, 2024 am 09:35 AM
Le Motorola Razr 50s se présente comme un nouveau budget pliable possible lors d'une fuite précoce
Sep 07, 2024 am 09:35 AM
Motorola a lancé d'innombrables appareils cette année, même si seuls deux d'entre eux sont pliables. Pour le contexte, alors que la plupart des pays du monde ont reçu la paire sous le nom de Razr 50 et Razr 50 Ultra, Motorola les propose en Amérique du Nord sous le nom de Razr 2024 et Razr 2.
 iQOO Z9 Turbo Plus : les réservations commencent pour le produit phare de la série potentiellement renforcée
Sep 10, 2024 am 06:45 AM
iQOO Z9 Turbo Plus : les réservations commencent pour le produit phare de la série potentiellement renforcée
Sep 10, 2024 am 06:45 AM
La marque sœur de OnePlus, iQOO, a un cycle de produits 2023-4 qui pourrait être presque terminé ; néanmoins, la marque a déclaré qu'elle n'en avait pas encore fini avec sa série Z9. Sa variante Turbo+ finale, et peut-être la plus haut de gamme, vient d'être annoncée comme prévu. T
 Un nouveau rapport fournit une évaluation accablante des rumeurs de mise à niveau des appareils photo des Samsung Galaxy S25, Galaxy S25 Plus et Galaxy S25 Ultra
Sep 12, 2024 pm 12:22 PM
Un nouveau rapport fournit une évaluation accablante des rumeurs de mise à niveau des appareils photo des Samsung Galaxy S25, Galaxy S25 Plus et Galaxy S25 Ultra
Sep 12, 2024 pm 12:22 PM
Ces derniers jours, Ice Universe n'a cessé de révéler des détails sur le Galaxy S25 Ultra, qui est largement considéré comme le prochain smartphone phare de Samsung. Entre autres choses, le fuyard a affirmé que Samsung prévoyait d'apporter une seule mise à niveau de l'appareil photo.
