
 interface Web
js tutoriel
Partage du didacticiel d'exploration du site Web Chrome + Puppeteer + Node.js
interface Web
js tutoriel
Partage du didacticiel d'exploration du site Web Chrome + Puppeteer + Node.js
Partage du didacticiel d'exploration du site Web Chrome + Puppeteer + Node.js


Qu'allons-nous apprendre ?
Dans ce tutoriel, vous apprendrez à automatiser et nettoyer le Web à l'aide de JavaScript. Pour ce faire, nous utiliserons Puppeteer. Puppeteer est une API de bibliothèque Node qui nous permet de contrôler Chrome sans tête. Headless Chrome est un moyen d'exécuter le navigateur Chrome sans réellement exécuter Chrome.
【Recommandation du didacticiel vidéo : Tutoriel nodejs ]
Si rien de tout cela n'a de sens, ce que vous devez vraiment savoir, c'est que nous allons écrire du JavaScript code qui automatise Google Chrome.
Avant de commencer
Avant de commencer, vous devrez avoir Node 8+ installé sur votre ordinateur. Vous pouvez l'installer ici. Assurez-vous de sélectionner la version "actuelle" 8+.
Si vous n'avez jamais utilisé Node auparavant et que vous souhaitez apprendre, consultez : Apprendre Node JS 3 meilleurs cours Node JS en ligne.
Après avoir installé Node, créez un nouveau dossier de projet et installez Puppeteer. Puppeteer est livré avec la dernière version de Chromium qui peut être utilisée avec l'API :
npm install --save puppeteer
Exemple n°1 — Capture d'écran
Après avoir installé Puppeteer, nous commencerons par un exemple simple. Cet exemple est tiré de la documentation de Puppeteer (avec des modifications mineures). Nous expliquerons étape par étape le code pour prendre des captures d'écran des sites Web que vous visitez.
Tout d'abord, créez un fichier nommé test.js et copiez le code suivant :
const puppeteer = require('puppeteer');
async function getPic() {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://google.com');
await page.screenshot({path: 'google.png'});
await browser.close();
}
getPic();Parcourons cet exemple ligne par ligne.
- Ligne 1 : Nous avons besoin des dépendances Puppeteer que nous avons installées plus tôt
-
Lignes 3 à 10 : Voici notre fonction principale
getPic(). Cette fonction contiendra tout notre code d’automatisation. -
Ligne 12 : Sur la ligne 12, on appelle la fonction
getPic().
Il est important de noter que la fonction getPic() est une fonction 异步 et profite de la nouvelle fonctionnalité ES 2017 async/await. Puisque cette fonction est asynchrone, elle renvoie un Promise lorsqu'elle est appelée. Lorsque la fonction Async renvoie enfin une valeur, Promise sera analysé (ou Reject s'il y a une erreur).
Puisque nous utilisons une fonction async, nous pouvons utiliser une expression await, qui mettra en pause l'exécution de la fonction et attendra que Promise soit résolu avant de continuer. Si rien de tout cela n’a de sens maintenant, ce n’est pas grave. Cela deviendra plus clair au fur et à mesure que nous poursuivrons le didacticiel.
Maintenant que nous avons un aperçu de la fonction principale, plongeons dans sa fonctionnalité interne :
- Ligne 4 :
const browser = await puppeteer.launch();
C'est ici que l'on démarre réellement le marionnettiste. Essentiellement, nous lançons une instance de Chrome et la définissons comme étant égale à notre variable browser nouvellement créée. Puisque nous avons utilisé le mot-clé await, la fonction s'arrêtera ici jusqu'à ce que le Promise soit résolu (jusqu'à ce que nous créions avec succès l'instance Chrome ou qu'une erreur se produise).
- Ligne 5 :
const page = await browser.newPage();
Ici, nous créons une nouvelle page dans le navigateur automatique. Nous attendons que la nouvelle page s'ouvre et l'enregistrons dans notre variable page.
- Ligne 6 :
await page.goto('https://google.com');En utilisant le page que nous avons créé dans la dernière ligne de code, nous pouvons maintenant dire au page navigation vers l'URL. Dans cet exemple, accédez à Google. Notre code fera une pause jusqu'à ce que la page soit chargée.
- Ligne 7 :
await page.screenshot({path: 'google.png'});Maintenant, nous disons à Puppeteer de prendre une capture d'écran de l'écran 页面 actuel. La méthode screenshot() prend l'objet .png personnalisé de l'emplacement de sauvegarde de la capture d'écran comme paramètre. Encore une fois, nous avons utilisé le mot-clé await afin que notre code se mette en pause pendant que l'action est effectuée.
- Ligne 9 :
await browser.close();
Enfin, on arrive à la fin de la fonction getPic() et on ferme le browser.
Exécuter l'exemple
Vous pouvez exécuter l'exemple de code ci-dessus en utilisant Node :
node test.js
Voici la capture d'écran résultante :

merveilleux! Pour plus de plaisir (et un débogage plus facile), nous pouvons exécuter le code sans l'exécuter sans tête.
Qu'est-ce que cela signifie ? Essayez-le vous-même et voyez. Remplacez la ligne 4 du code de :
const browser = await puppeteer.launch();
par :
const browser = await puppeteer.launch({headless: false});, puis exécutez-le à nouveau en utilisant Node :
node test.js
Cool, n'est-ce pas ? Vous pouvez réellement voir Google Chrome fonctionner selon votre code lorsque nous l'exécutons avec {headless:false}.
Avant de continuer, nous allons faire une dernière chose avec ce code. Vous vous souvenez que notre capture d'écran était un peu décentrée ? C'est parce que notre page est un peu petite. On peut changer la taille de la page en ajoutant la ligne de code suivante :
await page.setViewport({width: 1000, height: 500})这个屏幕截图更好看点:
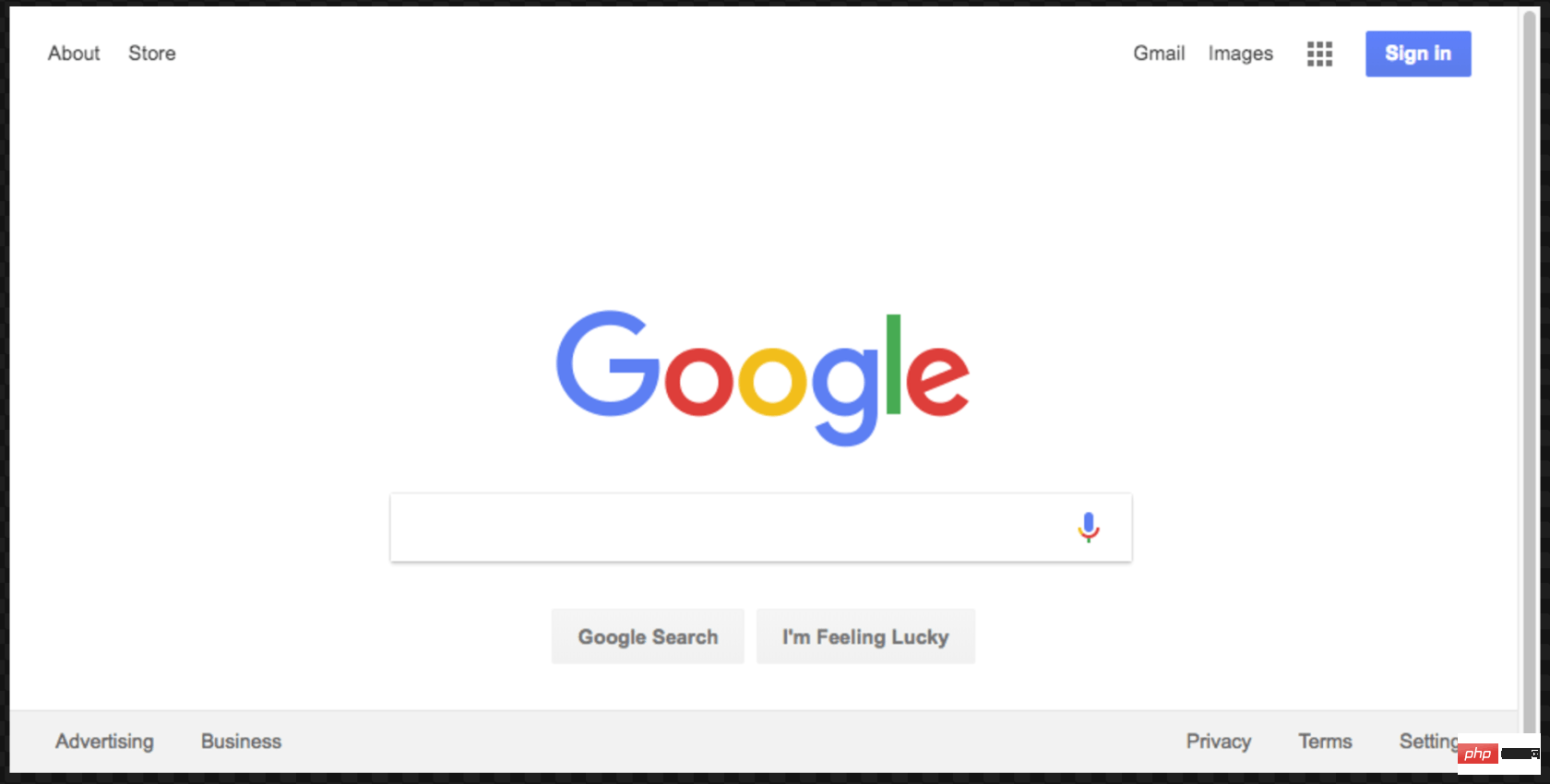
这是本示例的最终代码:
const puppeteer = require('puppeteer');
async function getPic() {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('https://google.com');
await page.setViewport({width: 1000, height: 500})
await page.screenshot({path: 'google.png'});
await browser.close();
}
getPic();示例 #2-让我们抓取一些数据
既然您已经了解了 Headless Chrome 和 Puppeteer 的工作原理,那么让我们看一个更复杂的示例,在该示例中我们事实上可以抓取一些数据。
首先, 在此处查看 Puppeteer 的 API 文档。 如您所见,我们有很多方法可以使用, 不仅可以点击网站,还可以填写表格,输入内容和读取数据。
在本教程中,我们将抓取 Books To Scrape ,这是一家专门设置的假书店,旨在帮助人们练习抓取。
在同一目录中,创建一个名为scrape.js的文件,并插入以下样板代码:
const puppeteer = require('puppeteer');
let scrape = async () => {
// 实际的抓取从这里开始...
// 返回值
};
scrape().then((value) => {
console.log(value); // 成功!
});理想情况下,在看完第一个示例之后,上面的代码对您有意义。如果没有,那没关系!
我们上面所做的需要以前安装的puppeteer依赖关系。然后我们有scraping()函数,我们将在其中填入抓取代码。此函数将返回值。最后,我们调用scraping函数并处理返回值(将其记录到控制台)。
我们可以通过在scrape函数中添加一行代码来测试以上代码。试试看:
let scrape = async () => {
return 'test';
};现在,在控制台中运行node scrape.js。您应该返回test!完美,我们返回的值正在记录到控制台。现在我们可以开始补充我们的scrape函数。
步骤1:设置
我们需要做的第一件事是创建浏览器实例,打开一个新页面,然后导航到URL。我们的操作方法如下:
let scrape = async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('http://books.toscrape.com/');
await page.waitFor(1000); // Scrape browser.close();
return result;};太棒了!让我们逐行学习它:
首先,我们创建浏览器,并将headless模式设置为false。这使我们可以准确地观察发生了什么:
const browser = await puppeteer.launch({headless: false});然后,我们在浏览器中创建一个新页面:
const page = await browser.newPage();
接下来,我们转到books.toscrape.com URL:
await page.goto('http://books.toscrape.com/');我选择性地添加了1000毫秒的延迟。尽管通常没有必要,但这将确保页面上的所有内容都加载:
await page.waitFor(1000);
最后,完成所有操作后,我们将关闭浏览器并返回结果。
browser.close(); return result;
步骤2:抓取
正如您现在可能已经确定的那样,Books to Scrape 拥有大量的真实书籍和这些书籍的伪造数据。我们要做的是选择页面上的第一本书,然后返回该书的标题和价格。这是要抓取的图书的主页。我有兴趣点第一本书(下面红色标记)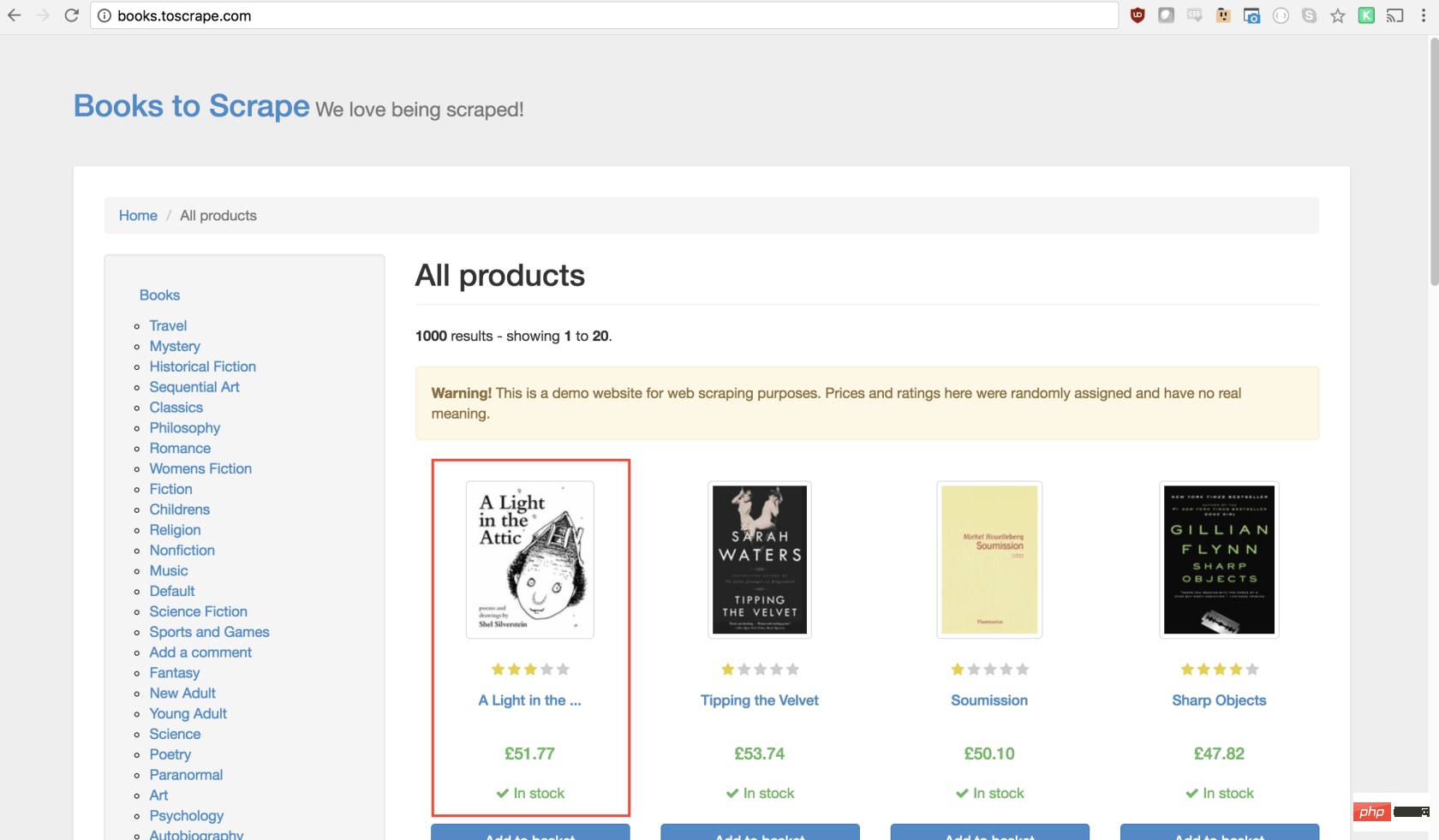
查看 Puppeteer API,我们可以找到单击页面的方法:
page.click(selector[, options])
-
selector用于选择要单击的元素的选择器,如果有多个满足选择器的元素,则将单击第一个。
幸运的是,使用 Google Chrome 开发者工具可以非常轻松地确定特定元素的选择器。只需右键单击图像并选择检查: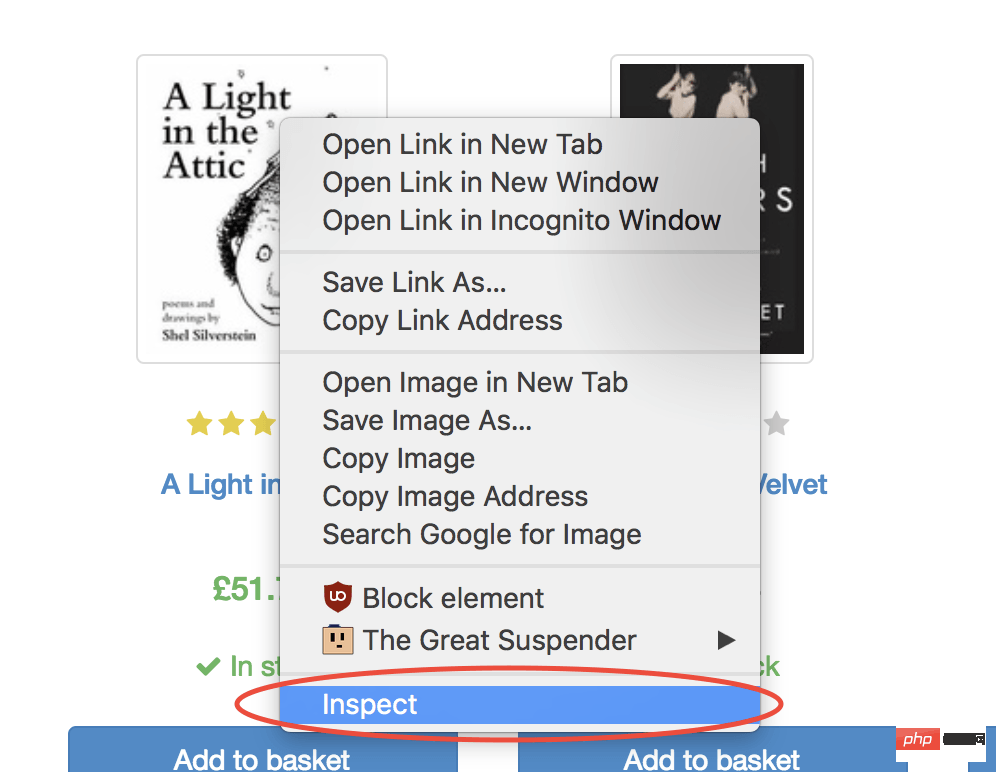
这将打开元素面板,突出显示该元素。现在,您可以单击左侧的三个点,选择复制,然后选择复制选择器:
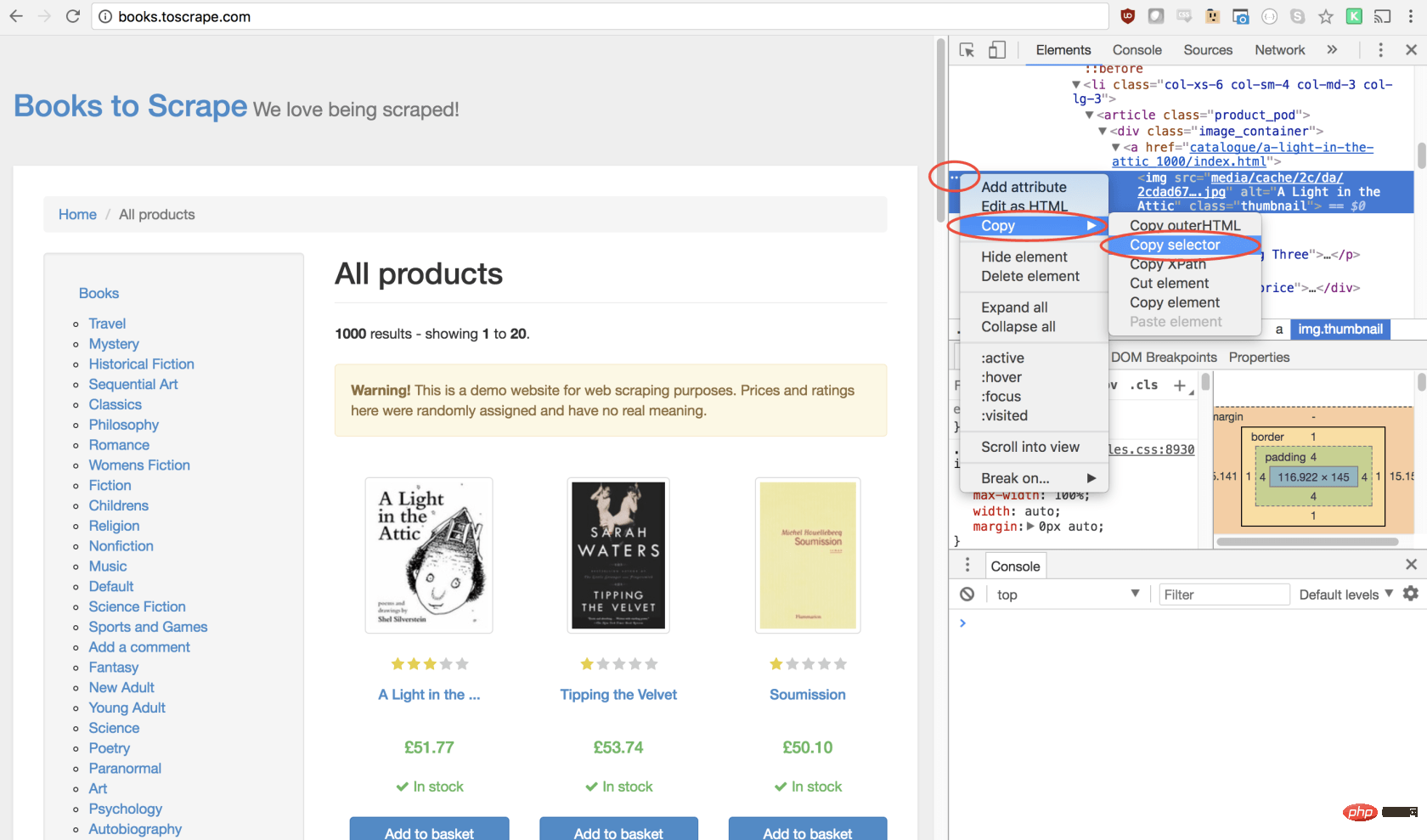
太棒了!现在,我们复制了选择器,并且可以将click方法插入程序。像这样:
await page.click('#default > p > p > p > p > section > p:nth-child(2) > ol > li:nth-child(1) > article > p.image_container > a > img');我们的窗口将单击第一个产品图像并导航到该产品页面!
在新页面上,我们对商品名称和商品价格均感兴趣(以下以红色概述)
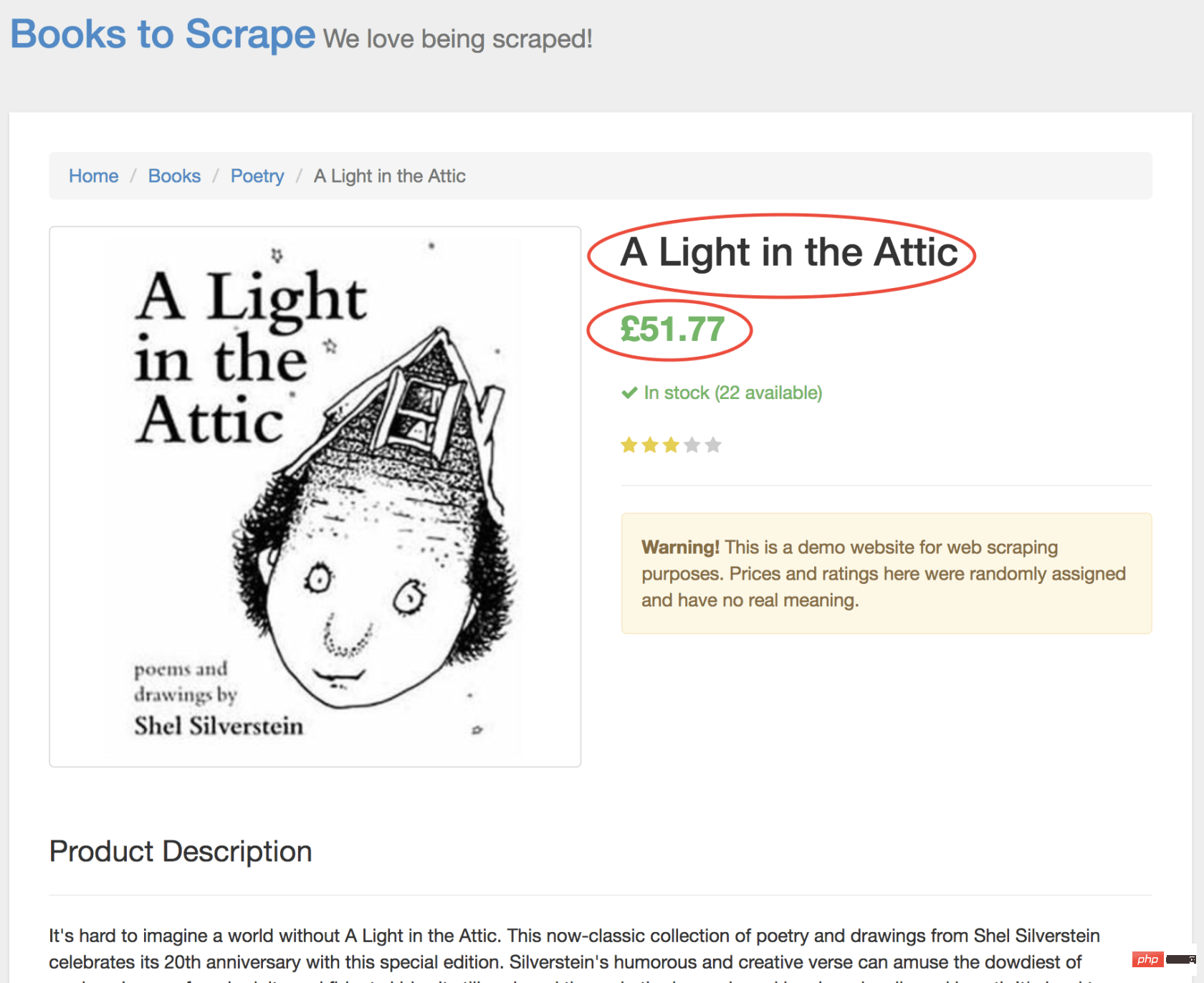
为了检索这些值,我们将使用page.evaluate()方法。此方法使我们可以使用内置的 DOM 选择器,例如querySelector()。
我们要做的第一件事是创建page.evaluate()函数,并将返回值保存到变量result中:
const result = await page.evaluate(() => {// return something});在函数里,我们可以选择所需的元素。我们将使用 Google Developers 工具再次解决这一问题。右键单击标题,然后选择检查:
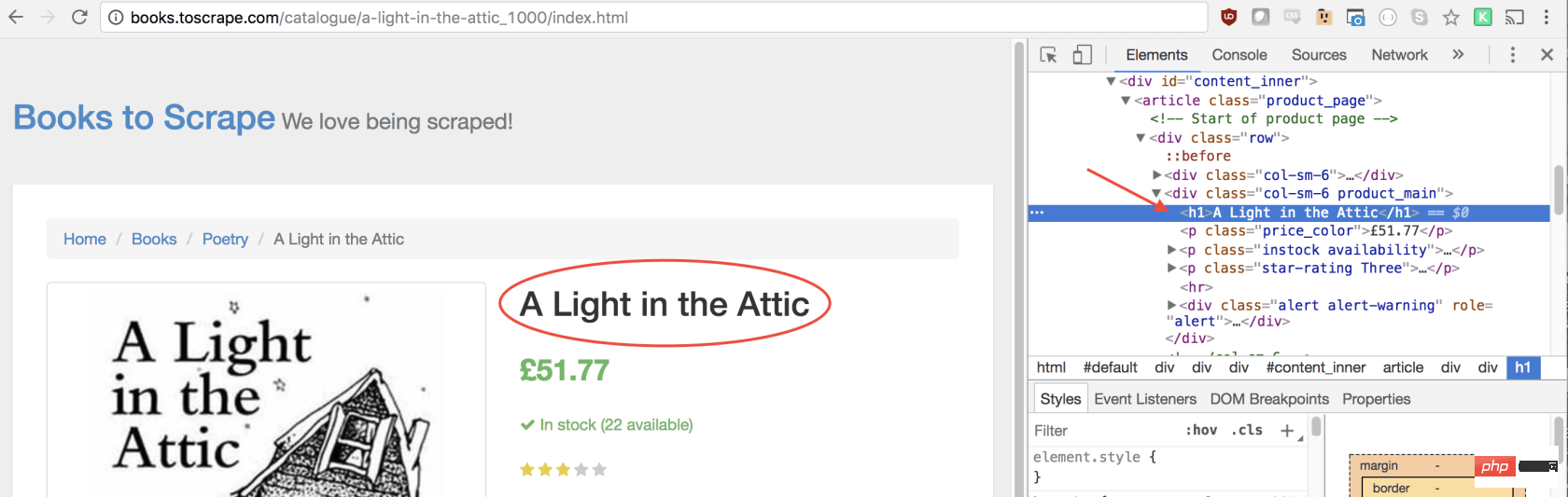
正如您将在 elements 面板中看到的那样,标题只是一个h1元素。我们可以使用以下代码选择此元素:
let title = document.querySelector('h1');由于我们希望文本包含在此元素中,因此我们需要添加.innerText-最终代码如下所示:
let title = document.querySelector('h1').innerText;同样,我们可以通过单击右键检查元素来选择价格:
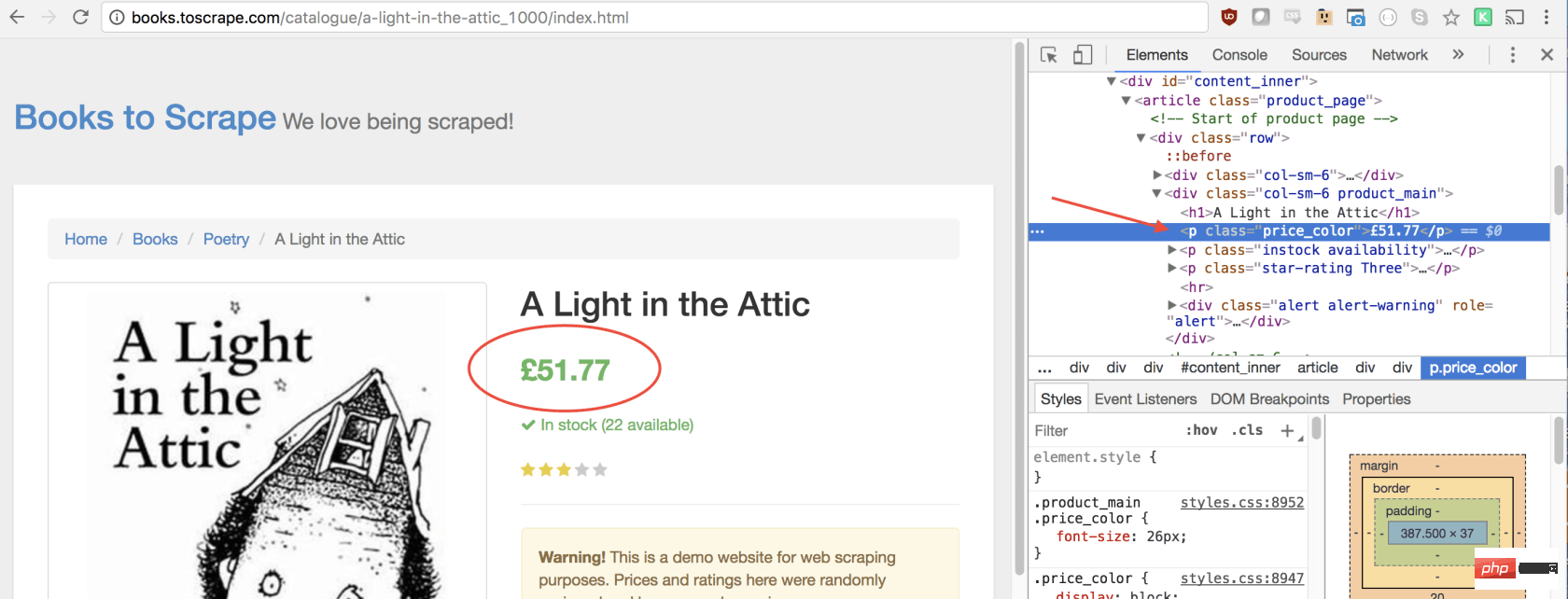
如您所见,我们的价格有price_color类,我们可以使用此类选择元素及其内部文本。这是代码:
let price = document.querySelector('.price_color').innerText;现在我们有了所需的文本,可以将其返回到一个对象中:
return {
title,
price
}太棒了!我们选择标题和价格,将其保存到一个对象中,然后将该对象的值返回给result变量。放在一起是这样的:
const result = await page.evaluate(() => {
let title = document.querySelector('h1').innerText;
let price = document.querySelector('.price_color').innerText;
return {
title,
price
}});剩下要做的唯一一件事就是返回result,以便可以将其记录到控制台:
return result;
您的最终代码应如下所示:
const puppeteer = require('puppeteer');
let scrape = async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('http://books.toscrape.com/');
await page.click('#default > p > p > p > p > section > p:nth-child(2) > ol > li:nth-child(1) > article > p.image_container > a > img');
await page.waitFor(1000);
const result = await page.evaluate(() => {
let title = document.querySelector('h1').innerText;
let price = document.querySelector('.price_color').innerText;
return {
title,
price
}
});
browser.close();
return result;
};
scrape().then((value) => {
console.log(value); // 成功!
});您可以通过在控制台中键入以下内容来运行 Node 文件:
node scrape.js // { 书名: 'A Light in the Attic', 价格: '£51.77' }您应该看到所选图书的标题和价格返回到屏幕上!您刚刚抓取了网页!
示例 #3 ——完善它
现在您可能会问自己,当标题和价格都显示在主页上时,为什么我们要点击书?为什么不从那里抓取呢?而在我们尝试时,为什么不抓紧所有书籍的标题和价格呢?
因为有很多方法可以抓取网站! (此外,如果我们留在首页上,我们的标题将被删掉)。但是,这为您提供了练习新的抓取技能的绝好机会!
挑战
目标 ——从首页抓取所有书名和价格,并以数组形式返回。这是我最终的输出结果:

开始!看看您是否可以自己完成此任务。与我们刚创建的上述程序非常相似,如果卡住,请向下滚动…
GO! See if you can accomplish this on your own. It’s very similar to the above program we just created. Scroll down if you get stuck…
提示:
此挑战与上一个示例之间的主要区别是需要遍历大量结果。您可以按照以下方法设置代码来做到这一点:
const result = await page.evaluate(() => {
let data = []; // 创建一个空数组
let elements = document.querySelectorAll('xxx'); // 选择全部
// 遍历每一个产品
// 选择标题
// 选择价格
data.push({title, price}); // 将数据放到数组里, 返回数据;
// 返回数据数组
});如果您不明白,没事!这是一个棘手的问题…… 这是一种可能的解决方案。在以后的文章中,我将深入研究此代码及其工作方式,我们还将介绍更高级的抓取技术。如果您想收到通知,请务必 在此处输入您的电子邮件 。
方案:
const puppeteer = require('puppeteer');
let scrape = async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('http://books.toscrape.com/');
const result = await page.evaluate(() => {
let data = []; // 创建一个空数组, 用来存储数据
let elements = document.querySelectorAll('.product_pod'); // 选择所有产品
for (var element of elements){ // 遍历每个产品
let title = element.childNodes[5].innerText; // 选择标题
let price = element.childNodes[7].children[0].innerText; // 选择价格
data.push({title, price}); // 将对象放进数组 data
}
return data; // 返回数组 data
});
browser.close();
return result; // 返回数据
};
scrape().then((value) => {
console.log(value); // 成功!
});结束语:
感谢您的阅读!
原文地址:https://codeburst.io/a-guide-to-automati...
译文地址:https://learnku.com/nodejs/t/44845
更多编程相关知识,可访问:编程入门!!
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Qu'est-ce que Updater.exe dans Windows 11/10 ? Est-ce le processus Chrome ?
Mar 21, 2024 pm 05:36 PM
Qu'est-ce que Updater.exe dans Windows 11/10 ? Est-ce le processus Chrome ?
Mar 21, 2024 pm 05:36 PM
Chaque application que vous exécutez sous Windows dispose d'un programme de composants pour la mettre à jour. Ainsi, si vous utilisez Google Chrome ou Google Earth, il exécutera une application GoogleUpdate.exe, vérifiera si une mise à jour est disponible, puis la mettra à jour en fonction des paramètres. Cependant, si vous ne le voyez plus et voyez à la place un processus updater.exe dans le Gestionnaire des tâches de Windows 11/10, il y a une raison à cela. Qu'est-ce que Updater.exe dans Windows 11/10 ? Google a déployé des mises à jour pour toutes ses applications comme Google Earth, Google Drive, Chrome, etc. Cette mise à jour apporte
 Quel fichier est crdownload ?
Mar 08, 2023 am 11:38 AM
Quel fichier est crdownload ?
Mar 08, 2023 am 11:38 AM
crdownload est un fichier cache de téléchargement du navigateur Chrome, qui est un fichier qui n'a pas été téléchargé ; le fichier crdownload est un format de fichier temporaire utilisé pour stocker les fichiers téléchargés à partir du disque dur. Il peut aider les utilisateurs à protéger l'intégrité des fichiers lors du téléchargement de fichiers et à éviter d'être endommagé. . Interruption ou arrêt inattendu. Les fichiers CRDownload peuvent également être utilisés pour sauvegarder des fichiers, permettant aux utilisateurs de sauvegarder des copies temporaires de fichiers ; si une erreur inattendue se produit pendant le téléchargement, les fichiers CRDownload peuvent être utilisés pour restaurer les fichiers téléchargés.
 Que faire si Chrome ne peut pas charger les plugins
Nov 06, 2023 pm 02:22 PM
Que faire si Chrome ne peut pas charger les plugins
Nov 06, 2023 pm 02:22 PM
L'incapacité de Chrome à charger les plug-ins peut être résolue en vérifiant si le plug-in est installé correctement, en désactivant et en activant le plug-in, en vidant le cache du plug-in, en mettant à jour le navigateur et les plug-ins, en vérifiant la connexion réseau et essayer de charger le plug-in en mode navigation privée. La solution est la suivante : 1. Vérifiez si le plug-in a été installé correctement et réinstallez-le ; 2. Désactivez et activez le plug-in, cliquez sur le bouton Désactiver, puis cliquez à nouveau sur le bouton Activer. 3. Supprimez le plug-in ; -dans le cache, sélectionnez Options avancées > Effacer les données de navigation, vérifiez les images et les fichiers du cache et effacez tous les cookies, cliquez sur Effacer les données.
 Un article pour parler du contrôle de la mémoire dans Node
Apr 26, 2023 pm 05:37 PM
Un article pour parler du contrôle de la mémoire dans Node
Apr 26, 2023 pm 05:37 PM
Le service Node construit sur une base non bloquante et piloté par les événements présente l'avantage d'une faible consommation de mémoire et est très adapté à la gestion de requêtes réseau massives. Dans le contexte de demandes massives, les questions liées au « contrôle de la mémoire » doivent être prises en compte. 1. Le mécanisme de récupération de place du V8 et les limitations de mémoire Js sont contrôlés par la machine de récupération de place
 Quel est le répertoire d'installation de l'extension du plug-in Chrome ?
Mar 08, 2024 am 08:55 AM
Quel est le répertoire d'installation de l'extension du plug-in Chrome ?
Mar 08, 2024 am 08:55 AM
Quel est le répertoire d’installation de l’extension du plug-in Chrome ? Dans des circonstances normales, le répertoire d'installation par défaut des extensions de plug-in Chrome est le suivant : 1. L'emplacement du répertoire d'installation par défaut des plug-ins Chrome dans Windows XP : C:\DocumentsandSettings\username\LocalSettings\ApplicationData\Google\Chrome\UserData\ Default\Extensions2. chrome dans Windows7 Emplacement du répertoire d'installation par défaut du plug-in : C:\Users\username\AppData\Local\Google\Chrome\User
 Explication graphique détaillée de la mémoire et du GC du moteur Node V8
Mar 29, 2023 pm 06:02 PM
Explication graphique détaillée de la mémoire et du GC du moteur Node V8
Mar 29, 2023 pm 06:02 PM
Cet article vous donnera une compréhension approfondie de la mémoire et du garbage collector (GC) du moteur NodeJS V8. J'espère qu'il vous sera utile !
 Comment résoudre le problème selon lequel Google Chrome ne peut pas ouvrir les pages Web
Jan 04, 2024 pm 10:18 PM
Comment résoudre le problème selon lequel Google Chrome ne peut pas ouvrir les pages Web
Jan 04, 2024 pm 10:18 PM
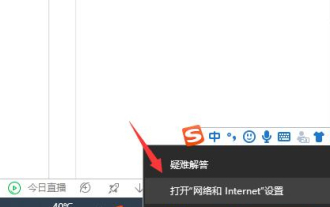
Que dois-je faire si la page Web de Google Chrome ne peut pas être ouverte ? De nombreux amis aiment utiliser Google Chrome. Bien sûr, certains amis constatent qu'ils ne peuvent pas ouvrir les pages Web normalement ou que les pages Web s'ouvrent très lentement pendant l'utilisation. Alors, que devez-vous faire si vous rencontrez cette situation ? Jetons un coup d'œil à la solution au problème selon lequel les pages Web de Google Chrome ne peuvent pas être ouvertes avec l'éditeur. Solution au problème selon lequel la page Web de Google Chrome ne peut pas être ouverte Méthode 1. Afin d'aider les joueurs qui n'ont pas encore réussi le niveau, découvrons les méthodes spécifiques de résolution du puzzle. Tout d'abord, cliquez avec le bouton droit sur l'icône du réseau dans le coin inférieur droit et sélectionnez « Paramètres réseau et Internet ». 2. Cliquez sur « Ethernet », puis cliquez sur « Modifier les options de l'adaptateur ». 3. Cliquez sur le bouton "Propriétés". 4. Double-cliquez pour ouvrir i
 Comment utiliser Express pour gérer le téléchargement de fichiers dans un projet de nœud
Mar 28, 2023 pm 07:28 PM
Comment utiliser Express pour gérer le téléchargement de fichiers dans un projet de nœud
Mar 28, 2023 pm 07:28 PM
Comment gérer le téléchargement de fichiers ? L'article suivant vous expliquera comment utiliser Express pour gérer les téléchargements de fichiers dans le projet de nœud. J'espère qu'il vous sera utile !
