
 développement back-end
Tutoriel Python
Explication détaillée de la méthode d'exploration des données 51cto en Python et de leur stockage dans MySQL
développement back-end
Tutoriel Python
Explication détaillée de la méthode d'exploration des données 51cto en Python et de leur stockage dans MySQL
Explication détaillée de la méthode d'exploration des données 51cto en Python et de leur stockage dans MySQL


[Recommandations d'apprentissage associées : Tutoriel Python]
Environnement expérimental
1. 3.7
2. Requêtes d'installation, bs4, module pymysql
Étapes expérimentales 1. L'environnement d'installation et les modules
peuvent se référer à https://www . jb51.net/article/194104.htm
2. Écrivez le code
# 51cto 博客页面数据插入mysql数据库
# 导入模块
import re
import bs4
import pymysql
import requests
# 连接数据库账号密码
db = pymysql.connect(host='172.171.13.229',
user='root', passwd='abc123',
db='test', port=3306,
charset='utf8')
# 获取游标
cursor = db.cursor()
def open_url(url):
# 连接模拟网页访问
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/57.0.2987.98 Safari/537.36'}
res = requests.get(url, headers=headers)
return res
# 爬取网页内容
def find_text(res):
soup = bs4.BeautifulSoup(res.text, 'html.parser')
# 博客名
titles = []
targets = soup.find_all("a", class_="tit")
for each in targets:
each = each.text.strip()
if "置顶" in each:
each = each.split(' ')[0]
titles.append(each)
# 阅读量
reads = []
read1 = soup.find_all("p", class_="read fl on")
read2 = soup.find_all("p", class_="read fl")
for each in read1:
reads.append(each.text)
for each in read2:
reads.append(each.text)
# 评论数
comment = []
targets = soup.find_all("p", class_='comment fl')
for each in targets:
comment.append(each.text)
# 收藏
collects = []
targets = soup.find_all("p", class_='collect fl')
for each in targets:
collects.append(each.text)
# 发布时间
dates=[]
targets = soup.find_all("a", class_='time fl')
for each in targets:
each = each.text.split(':')[1]
dates.append(each)
# 插入sql 语句
sql = """insert into blog (blog_title,read_number,comment_number, collect, dates)
values( '%s', '%s', '%s', '%s', '%s');"""
# 替换页面 \xa0
for titles, reads, comment, collects, dates in zip(titles, reads, comment, collects, dates):
reads = re.sub('\s', '', reads)
comment = re.sub('\s', '', comment)
collects = re.sub('\s', '', collects)
cursor.execute(sql % (titles, reads, comment, collects,dates))
db.commit()
pass
# 统计总页数
def find_depth(res):
soup = bs4.BeautifulSoup(res.text, 'html.parser')
depth = soup.find('li', class_='next').previous_sibling.previous_sibling.text
return int(depth)
# 主函数
def main():
host = "https://blog.51cto.com/13760351"
res = open_url(host) # 打开首页链接
depth = find_depth(res) # 获取总页数
# 爬取其他页面信息
for i in range(1, depth + 1):
url = host + '/p' + str(i) # 完整链接
res = open_url(url) # 打开其他链接
find_text(res) # 爬取数据
# 关闭游标
cursor.close()
# 关闭数据库连接
db.close()
if __name__ == '__main__':
main()3. MySQL crée la table correspondante
CREATE TABLE `blog` ( `row_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `blog_title` varchar(52) DEFAULT NULL COMMENT '博客标题', `read_number` varchar(26) DEFAULT NULL COMMENT '阅读数量', `comment_number` varchar(16) DEFAULT NULL COMMENT '评论数量', `collect` varchar(16) DEFAULT NULL COMMENT '收藏数量', `dates` varchar(16) DEFAULT NULL COMMENT '发布日期', PRIMARY KEY (`row_id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;

. 4. Exécutez le code et vérifiez l'effet :
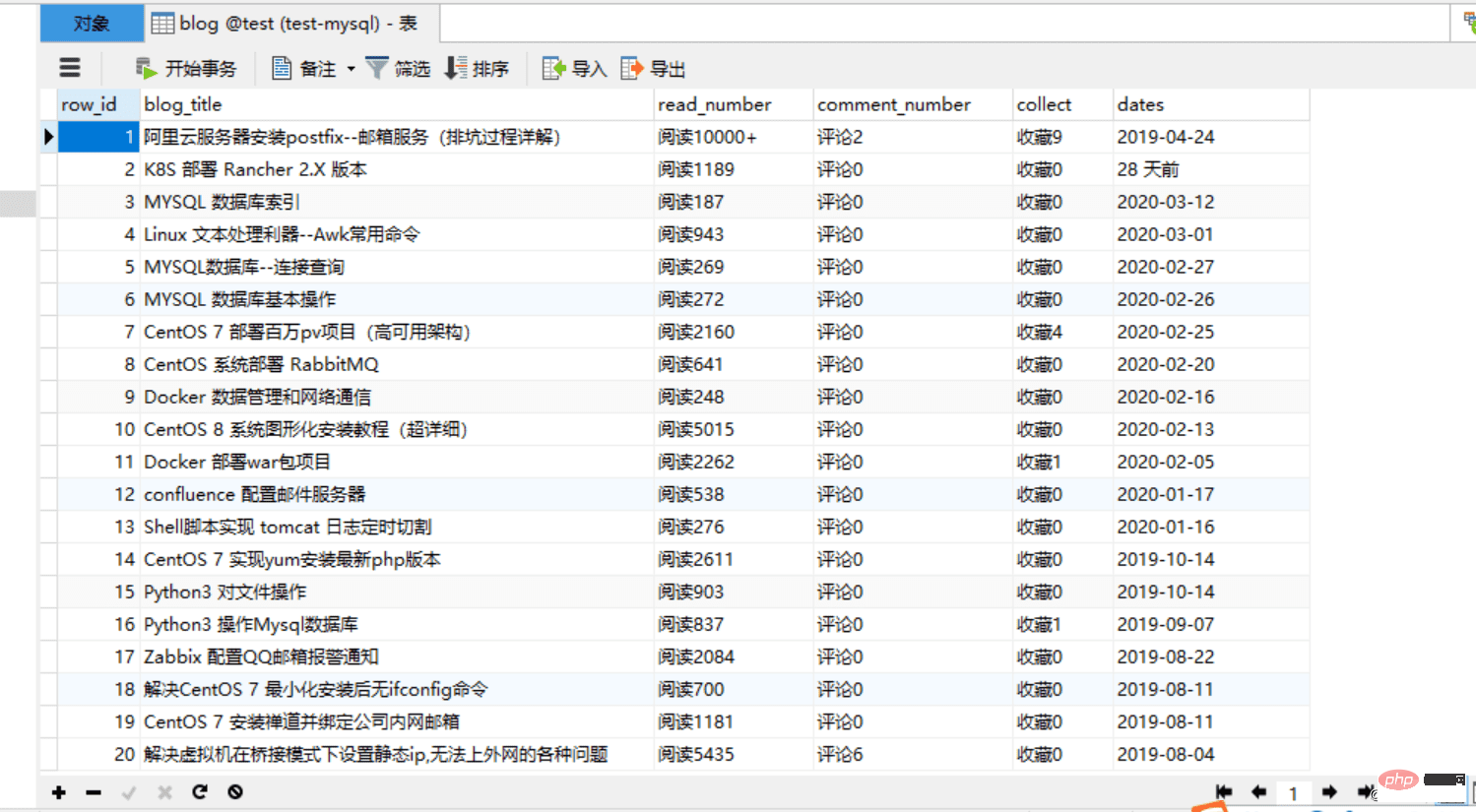
Version améliorée :
Contenu amélioré :
1. la base de données Certains champs ne peuvent conserver que des nombres
2 Par défaut, le contenu exploré est une chaîne, qui stocke certains champs de la base de données. Il est préférable de les remplacer par des nombres entiers pour faciliter les opérations ultérieures de la base de données. 🎜>
import re
import bs4
import pymysql
import requests
# 连接数据库
db = pymysql.connect(host='172.171.13.229',
user='root', passwd='abc123',
db='test', port=3306,
charset='utf8')
# 获取游标
cursor = db.cursor()
def open_url(url):
# 连接模拟网页访问
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/57.0.2987.98 Safari/537.36'}
res = requests.get(url, headers=headers)
return res
# 爬取网页内容
def find_text(res):
soup = bs4.BeautifulSoup(res.text, 'html.parser')
# 博客标题
titles = []
targets = soup.find_all("a", class_="tit")
for each in targets:
each = each.text.strip()
if "置顶" in each:
each = each.split(' ')[0]
titles.append(each)
# 阅读量
reads = []
read1 = soup.find_all("p", class_="read fl on")
read2 = soup.find_all("p", class_="read fl")
for each in read1:
reads.append(each.text)
for each in read2:
reads.append(each.text)
# 评论数
comment = []
targets = soup.find_all("p", class_='comment fl')
for each in targets:
comment.append(each.text)
# 收藏
collects = []
targets = soup.find_all("p", class_='collect fl')
for each in targets:
collects.append(each.text)
# 发布时间
dates=[]
targets = soup.find_all("a", class_='time fl')
for each in targets:
each = each.text.split(':')[1]
dates.append(each)
# 插入sql 语句
sql = """insert into blogs (blog_title,read_number,comment_number, collect, dates)
values( '%s', '%s', '%s', '%s', '%s');"""
# 替换页面 \xa0
for titles, reads, comment, collects, dates in zip(titles, reads, comment, collects, dates):
reads = re.sub('\s', '', reads)
reads=int(re.sub('\D', "", reads)) #匹配数字,转换为整型
comment = re.sub('\s', '', comment)
comment = int(re.sub('\D', "", comment)) #匹配数字,转换为整型
collects = re.sub('\s', '', collects)
collects = int(re.sub('\D', "", collects)) #匹配数字,转换为整型
dates = re.sub('\s', '', dates)
cursor.execute(sql % (titles, reads, comment, collects,dates))
db.commit()
pass
# 统计总页数
def find_depth(res):
soup = bs4.BeautifulSoup(res.text, 'html.parser')
depth = soup.find('li', class_='next').previous_sibling.previous_sibling.text
return int(depth)
# 主函数
def main():
host = "https://blog.51cto.com/13760351"
res = open_url(host) # 打开首页链接
depth = find_depth(res) # 获取总页数
# 爬取其他页面信息
for i in range(1, depth + 1):
url = host + '/p' + str(i) # 完整链接
res = open_url(url) # 打开其他链接
find_text(res) # 爬取数据
# 关闭游标
cursor.close()
# 关闭数据库连接
db.close()
#主程序入口
if __name__ == '__main__':
main()CREATE TABLE `blogs` ( `row_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `blog_title` varchar(52) DEFAULT NULL COMMENT '博客标题', `read_number` int(26) DEFAULT NULL COMMENT '阅读数量', `comment_number` int(16) DEFAULT NULL COMMENT '评论数量', `collect` int(16) DEFAULT NULL COMMENT '收藏数量', `dates` varchar(16) DEFAULT NULL COMMENT '发布日期', PRIMARY KEY (`row_id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
#末尾修改为:
if __name__ == '__main__':
main()
print("\n\t\t所有数据已成功存放数据库!!! \n")
time.sleep(5)pip install pyinstaller -i https://pypi.tuna.tsinghua.edu.cn/simple/
<.>
 5. Exécutez le package exe et vérifiez l'effet
5. Exécutez le package exe et vérifiez l'effet
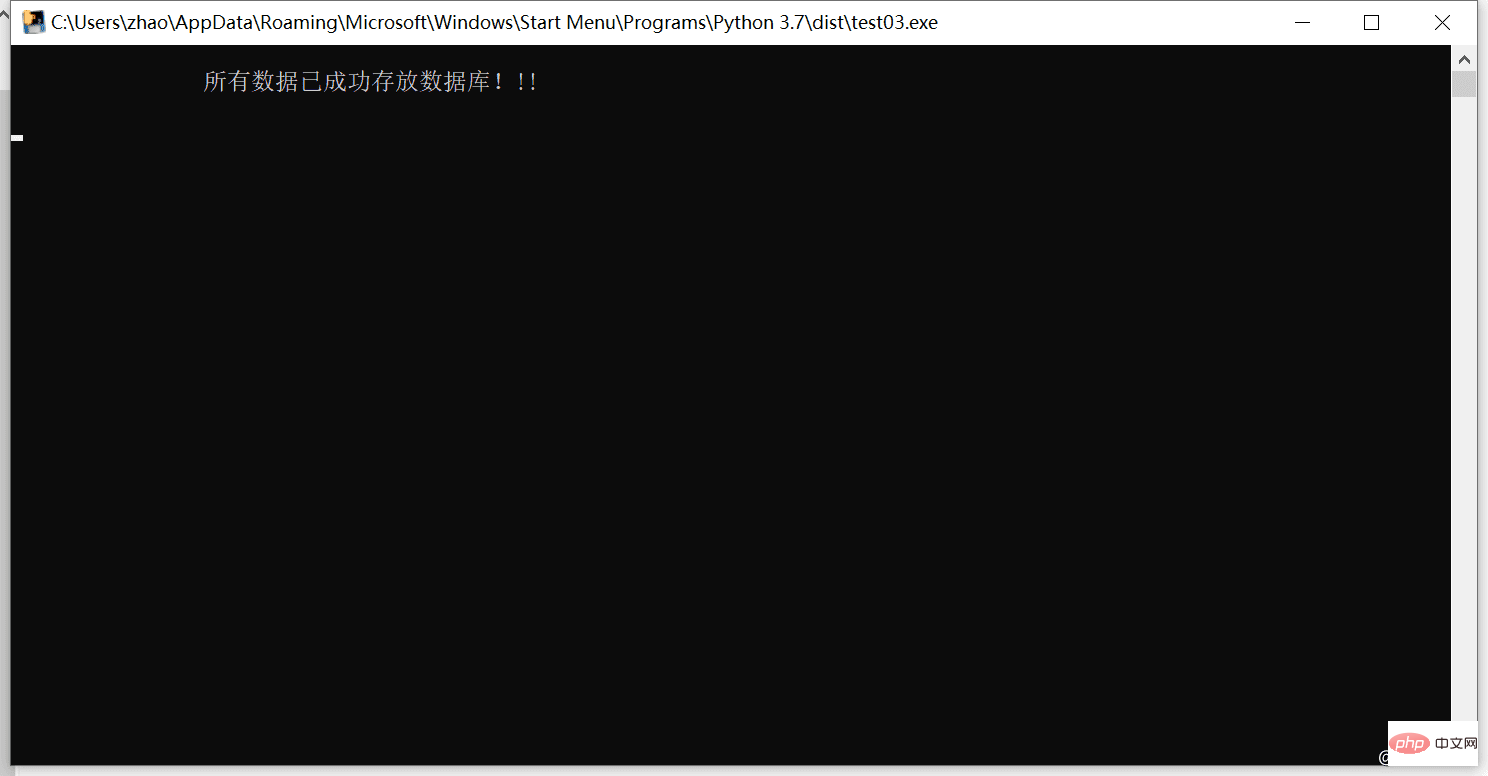 Vérifiez la base de données
Vérifiez la base de données
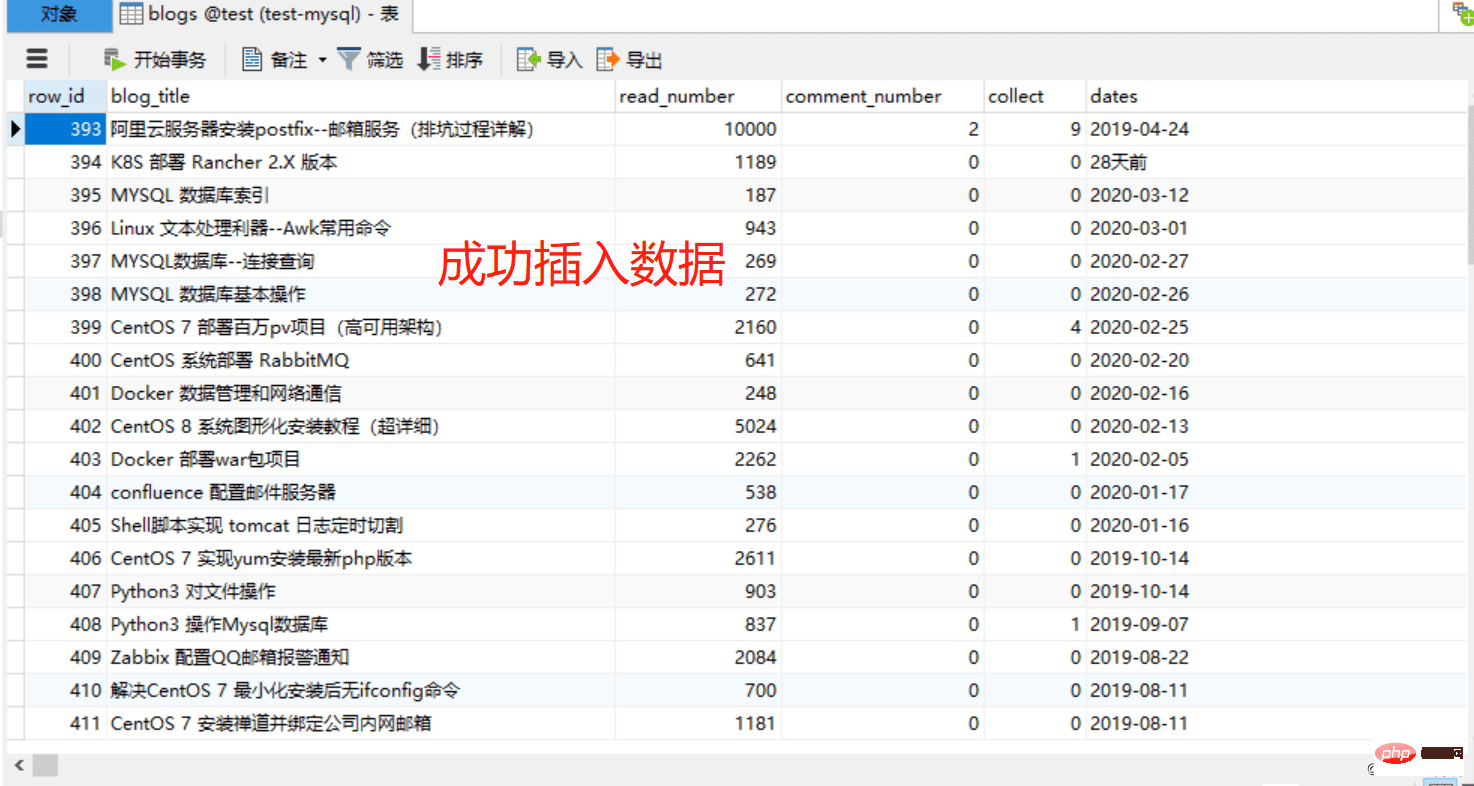
Tutoriel mysql
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 PHP et Python: différents paradigmes expliqués
Apr 18, 2025 am 12:26 AM
PHP et Python: différents paradigmes expliqués
Apr 18, 2025 am 12:26 AM
PHP est principalement la programmation procédurale, mais prend également en charge la programmation orientée objet (POO); Python prend en charge une variété de paradigmes, y compris la POO, la programmation fonctionnelle et procédurale. PHP convient au développement Web, et Python convient à une variété d'applications telles que l'analyse des données et l'apprentissage automatique.
 Choisir entre PHP et Python: un guide
Apr 18, 2025 am 12:24 AM
Choisir entre PHP et Python: un guide
Apr 18, 2025 am 12:24 AM
PHP convient au développement Web et au prototypage rapide, et Python convient à la science des données et à l'apprentissage automatique. 1.Php est utilisé pour le développement Web dynamique, avec une syntaxe simple et adapté pour un développement rapide. 2. Python a une syntaxe concise, convient à plusieurs champs et a un écosystème de bibliothèque solide.
 Rôle de MySQL: Bases de données dans les applications Web
Apr 17, 2025 am 12:23 AM
Rôle de MySQL: Bases de données dans les applications Web
Apr 17, 2025 am 12:23 AM
Le rôle principal de MySQL dans les applications Web est de stocker et de gérer les données. 1.MySQL traite efficacement les informations utilisateur, les catalogues de produits, les enregistrements de transaction et autres données. 2. Grâce à SQL Query, les développeurs peuvent extraire des informations de la base de données pour générer du contenu dynamique. 3.MySQL fonctionne basé sur le modèle client-serveur pour assurer une vitesse de requête acceptable.
 PHP et Python: une plongée profonde dans leur histoire
Apr 18, 2025 am 12:25 AM
PHP et Python: une plongée profonde dans leur histoire
Apr 18, 2025 am 12:25 AM
PHP est originaire en 1994 et a été développé par Rasmuslerdorf. Il a été utilisé à l'origine pour suivre les visiteurs du site Web et a progressivement évolué en un langage de script côté serveur et a été largement utilisé dans le développement Web. Python a été développé par Guidovan Rossum à la fin des années 1980 et a été publié pour la première fois en 1991. Il met l'accent sur la lisibilité et la simplicité du code, et convient à l'informatique scientifique, à l'analyse des données et à d'autres domaines.
 Comment exécuter Python avec le bloc-notes
Apr 16, 2025 pm 07:33 PM
Comment exécuter Python avec le bloc-notes
Apr 16, 2025 pm 07:33 PM
L'exécution du code Python dans le bloc-notes nécessite l'installation du plug-in exécutable Python et du plug-in NPEXEC. Après avoir installé Python et ajouté un chemin à lui, configurez la commande "python" et le paramètre "{current_directory} {file_name}" dans le plug-in nppexec pour exécuter le code python via la touche de raccourci "F6" dans le bloc-notes.
 Résolvez le problème de la connexion de la base de données: un cas pratique d'utilisation de la bibliothèque Minii / DB
Apr 18, 2025 am 07:09 AM
Résolvez le problème de la connexion de la base de données: un cas pratique d'utilisation de la bibliothèque Minii / DB
Apr 18, 2025 am 07:09 AM
J'ai rencontré un problème délicat lors du développement d'une petite application: la nécessité d'intégrer rapidement une bibliothèque d'opération de base de données légère. Après avoir essayé plusieurs bibliothèques, j'ai constaté qu'ils avaient trop de fonctionnalités ou ne sont pas très compatibles. Finalement, j'ai trouvé Minii / DB, une version simplifiée basée sur YII2 qui a parfaitement résolu mon problème.
 Exemple d'introduction de Laravel
Apr 18, 2025 pm 12:45 PM
Exemple d'introduction de Laravel
Apr 18, 2025 pm 12:45 PM
Laravel est un cadre PHP pour la création facile des applications Web. Il fournit une gamme de fonctionnalités puissantes, notamment: Installation: Installez le Laravel CLI globalement avec Composer et créez des applications dans le répertoire du projet. Routage: définissez la relation entre l'URL et le gestionnaire dans Routes / web.php. Voir: Créez une vue dans les ressources / vues pour rendre l'interface de l'application. Intégration de la base de données: fournit une intégration prête à l'emploi avec des bases de données telles que MySQL et utilise la migration pour créer et modifier des tables. Modèle et contrôleur: le modèle représente l'entité de la base de données et le contrôleur traite les demandes HTTP.
 Golang vs Python: concurrence et multithreading
Apr 17, 2025 am 12:20 AM
Golang vs Python: concurrence et multithreading
Apr 17, 2025 am 12:20 AM
Golang convient plus à des tâches de concurrence élevées, tandis que Python présente plus d'avantages dans la flexibilité. 1. Golang gère efficacement la concurrence par le goroutine et le canal. 2. Python repose sur le filetage et l'asyncio, qui est affecté par GIL, mais fournit plusieurs méthodes de concurrence. Le choix doit être basé sur des besoins spécifiques.
