
 interface Web
Questions et réponses frontales
Une brève discussion sur les robots d'exploration et le contournement des mécanismes anti-crawling des sites Web
interface Web
Questions et réponses frontales
Une brève discussion sur les robots d'exploration et le contournement des mécanismes anti-crawling des sites Web
Une brève discussion sur les robots d'exploration et le contournement des mécanismes anti-crawling des sites Web


[Recommandations d'apprentissage associées : Tutoriel vidéo sur la production de sites Web]
Qu'est-ce qu'un robot ? Pour faire simple et unilatéralement, un robot est un outil qui permet à un ordinateur d'interagir automatiquement avec un serveur pour obtenir des données. La chose la plus fondamentale à propos d'un robot d'exploration est d'obtenir les données du code source d'une page Web. Si vous allez plus loin, vous aurez une interaction POST avec la page Web et obtiendrez les données renvoyées par le serveur après avoir reçu la requête POST. En un mot, le robot est utilisé pour obtenir automatiquement les données source. Quant au traitement supplémentaire des données, etc., il s'agit d'un travail de suivi. Cet article veut principalement parler de cette partie de l'obtention des données par le robot. Crawlers, veuillez faire attention au fichier Robot.txt du site Web. Ne laissez pas les robots enfreindre la loi ou causer des dommages au site Web.
Exemples inappropriés de concepts anti-crawling et anti-anti-crawling
Pour de nombreuses raisons (telles que les ressources du serveur, la protection des données, etc.), de nombreux sites Web limiter l'effet crawler.
Pensez-y, si un humain joue le rôle d'un robot, comment obtenons-nous le code source de la page Web ? Le plus couramment utilisé est bien sûr de cliquer avec le bouton droit sur le code source ?
Que dois-je faire si le clic droit est bloqué sur le site Web

Supprimez F12, l'outil le plus utile que nous utilisons en crawl (bienvenue sur discuter)
Appuyez sur F12 en même temps pour l'ouvrir (drôle)
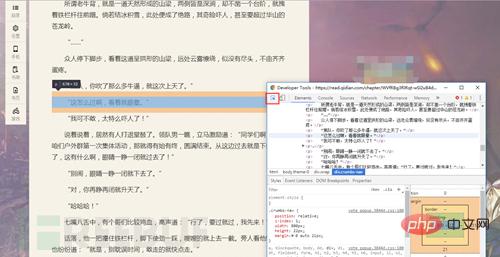
Le code source est sorti
Lors du traitement !! les gens en tant que robots d'exploration, bloquent le clic droit. C'est la stratégie anti-exploration, et F12 est la méthode anti-exploration.
Parlons de la stratégie anti-crawling formelle
En fait, il a dû y avoir des situations où aucune donnée n'a été renvoyée pendant le processus d'écriture d'un robot. Dans ce cas, il s'agit peut-être du serveur. Limiter l'en-tête UA (user-agent), c'est un anti-crawling très basique. Il suffit d'ajouter l'en-tête UA lors de l'envoi de la requête... N'est-ce pas très simple
En fait, ce n'est pas du tout nécessaire. Ajouter tous les en-têtes de requête requis est une méthode simple et grossière... Avez-vous trouvé que le code de vérification du site Web est également une stratégie anti-crawling ? pour garantir que les utilisateurs du site Web sont de vraies personnes, le code de vérification est vraiment fait. Une grande contribution. Parallèlement au code de vérification, la reconnaissance du code de vérification est apparue. En parlant de ça, je me demande quelle reconnaissance de code de vérification ou reconnaissance d'image est arrivée en premier. Il est très simple de reconnaître des codes de vérification simples maintenant. Il y a trop de tutoriels sur Internet, dont un. petits concepts avancés tels que le débruitage, le binaire, la segmentation et la réorganisation. Mais maintenant, la reconnaissance homme-machine des sites Web est devenue de plus en plus terrifiante, comme ceci :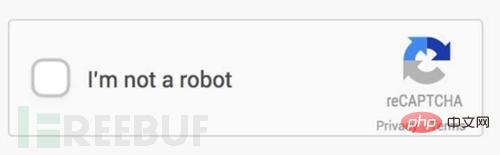
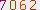
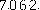


for x in range(0,image.size[0]): for y in range(0,image.size[1]): # print arr2[x][y] if arr[x][y].tolist()==底色: arr[x][y]=0 elif arr[x][y].tolist()[0] in range(200,256) and arr[x][y].tolist()[1] in range(200,256) and arr[x][y].tolist()[2] in range(200,256): arr[x][y]=0 elif arr[x][y].tolist()==[0,0,0]: arr[x][y]=0 else: arr[x][y]=255
Dans le développement du code de vérification, il existe des chiffres et des lettres relativement clairs, des additions, soustractions, multiplications et divisions simples. Il existe des roues sur Internet qui peuvent être utilisées pour certains nombres, lettres et caractères chinois difficiles. fabriquez également vos propres roues (comme celle ci-dessus), mais il y en a plus. Des choses suffisent pour écrire une intelligence artificielle... (Un type de travail consiste à reconnaître les codes de vérification...)
Ajoutez un peu astuce : certains sites internet ont des codes de vérification côté PC, mais pas côté téléphone portable...
Sujet suivant !
L'un des anti- Les stratégies d'exploration sont la stratégie de blocage IP. Généralement, trop de visites sur une courte période sont bloquées. C'est très simple de limiter la fréquence d'accès ou d'ajouter un pool de proxy IP. ..
Pool de proxy IP-> tournez à gauche vers Google et à droite vers baidu. Il existe de nombreux sites Web proxy, bien qu'ils soient gratuits. Pas beaucoup utilisés mais toujours ok.
Un autre type de stratégie anti-crawler est celui des données asynchrones. Avec l'approfondissement progressif des robots (il s'agit évidemment d'une mise à jour du site !), le chargement asynchrone est un problème qui sera certainement rencontré, et la solution est. c'est toujours F12. Prenons l'exemple du site Web anonyme NetEase Cloud Music. Après avoir fait un clic droit pour ouvrir le code source, essayez de rechercher des commentaires

Où sont les données ?! après la montée en puissance des fonctionnalités JS et Ajax. Mais ouvrez F12, passez à l'onglet NetWork, actualisez la page et recherchez attentivement, il n'y a pas de secret.
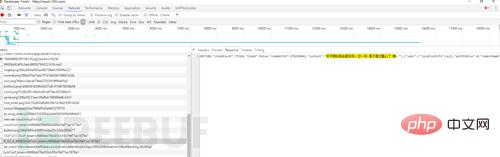
Oh, au fait, si vous écoutez la chanson, vous pouvez la télécharger en cliquant sur...
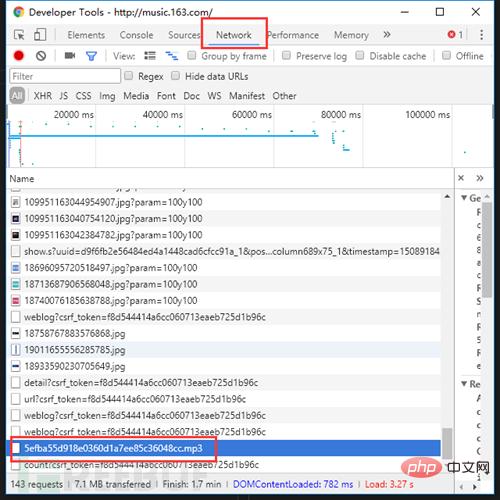
Uniquement Pour vulgariser la structure du site Web, veuillez résister consciemment au piratage, protéger les droits d'auteur et protéger les intérêts du créateur original.
Et si ce site Web vous restreint ? Nous avons un dernier plan, une combinaison invincible : sélénium + PhantomJs
Cette combinaison est très puissante et peut parfaitement simuler le comportement du navigateur. Veuillez vous référer à Baidu pour plus de détails. Cette méthode n’est pas recommandée. Elle est très lourde et concerne uniquement la science populaire.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Combien de temps faut-il pour apprendre le robot d'exploration Python
Oct 25, 2023 am 09:44 AM
Combien de temps faut-il pour apprendre le robot d'exploration Python
Oct 25, 2023 am 09:44 AM
Le temps nécessaire pour apprendre les robots d'exploration Python varie d'une personne à l'autre et dépend de facteurs tels que la capacité d'apprentissage personnelle, les méthodes d'apprentissage, le temps d'apprentissage et l'expérience. L'apprentissage des robots d'exploration Python ne consiste pas seulement à apprendre la technologie elle-même, mais nécessite également de bonnes compétences en matière de collecte d'informations, de résolution de problèmes et de travail d'équipe. Grâce à un apprentissage et à une pratique continus, vous deviendrez progressivement un excellent développeur de robots Python.
 Pratique du robot d'exploration PHP : analyser les données sur Twitter
Jun 13, 2023 pm 01:17 PM
Pratique du robot d'exploration PHP : analyser les données sur Twitter
Jun 13, 2023 pm 01:17 PM
À l’ère du numérique, les médias sociaux sont devenus un élément indispensable de la vie des gens. Twitter en fait partie, avec des centaines de millions d'utilisateurs qui y partagent chaque jour diverses informations. Pour certains besoins de recherche, d’analyse, de promotion et autres, il est indispensable d’obtenir des données pertinentes sur Twitter. Cet article explique comment utiliser PHP pour écrire un simple robot d'exploration Twitter afin d'explorer certaines données liées aux mots clés et de les stocker dans la base de données. 1. TwitterAPI fournie par Twitter
 Conseils pour les robots : comment gérer les cookies en PHP
Jun 13, 2023 pm 02:54 PM
Conseils pour les robots : comment gérer les cookies en PHP
Jun 13, 2023 pm 02:54 PM
Dans le développement de robots d'exploration, la gestion des cookies est souvent une partie essentielle. En tant que mécanisme de gestion d'état dans HTTP, les cookies sont généralement utilisés pour enregistrer les informations de connexion et le comportement des utilisateurs. Ils constituent la clé permettant aux robots d'exploration de gérer l'authentification des utilisateurs et de maintenir l'état de connexion. Dans le développement de robots PHP, la gestion des cookies nécessite de maîtriser certaines compétences et de prêter attention à certains pièges. Ci-dessous, nous expliquons en détail comment gérer les cookies en PHP. 1. Comment obtenir un cookie lors de l'écriture en PHP
 Analyse et solutions aux problèmes courants des robots PHP
Aug 06, 2023 pm 12:57 PM
Analyse et solutions aux problèmes courants des robots PHP
Aug 06, 2023 pm 12:57 PM
Analyse des problèmes courants et solutions pour les robots PHP Introduction : Avec le développement rapide d'Internet, l'acquisition de données réseau est devenue un maillon important dans divers domaines. En tant que langage de script largement utilisé, PHP possède de puissantes capacités d’acquisition de données. L’une des technologies couramment utilisées est celle des robots d’exploration. Cependant, lors du développement et de l’utilisation des robots d’exploration PHP, nous rencontrons souvent des problèmes. Cet article analysera et proposera des solutions à ces problèmes et fournira des exemples de code correspondants. 1. Description du problème selon lequel les données de la page Web cible ne peuvent pas être correctement analysées.
 Pratique efficace du robot d'exploration Java : partage des techniques d'exploration de données Web
Jan 09, 2024 pm 12:29 PM
Pratique efficace du robot d'exploration Java : partage des techniques d'exploration de données Web
Jan 09, 2024 pm 12:29 PM
Pratique du robot d'exploration Java : Comment explorer efficacement les données d'une page Web Introduction : Avec le développement rapide d'Internet, une grande quantité de données précieuses est stockée dans diverses pages Web. Pour obtenir ces données, il est souvent nécessaire d’accéder manuellement à chaque page web et d’en extraire les informations une par une, ce qui est sans doute une tâche fastidieuse et chronophage. Afin de résoudre ce problème, les utilisateurs ont développé divers outils de robots d'exploration, parmi lesquels le robot d'exploration Java est l'un des plus couramment utilisés. Cet article amènera les lecteurs à comprendre comment utiliser Java pour écrire un robot d'exploration Web efficace et à démontrer la pratique à travers des exemples de code spécifiques. 1. La base du reptile
 Exploration efficace des données de pages Web : utilisation combinée de PHP et Selenium
Jun 15, 2023 pm 08:36 PM
Exploration efficace des données de pages Web : utilisation combinée de PHP et Selenium
Jun 15, 2023 pm 08:36 PM
Avec le développement rapide de la technologie Internet, les applications Web sont de plus en plus utilisées dans notre travail et notre vie quotidienne. Dans le processus de développement d’applications Web, l’exploration des données des pages Web est une tâche très importante. Bien qu’il existe de nombreux outils de web scraping sur le marché, ces outils ne sont pas très efficaces. Afin d'améliorer l'efficacité de l'exploration des données des pages Web, nous pouvons utiliser la combinaison de PHP et Selenium. Tout d’abord, nous devons comprendre ce que sont PHP et Selenium. PHP est un puissant
 Pratique pratique du robot d'exploration : utiliser PHP pour explorer les informations boursières
Jun 13, 2023 pm 05:32 PM
Pratique pratique du robot d'exploration : utiliser PHP pour explorer les informations boursières
Jun 13, 2023 pm 05:32 PM
La bourse a toujours été un sujet de grande préoccupation. Les hausses, baisses et variations quotidiennes des actions affectent directement les décisions des investisseurs. Si vous souhaitez comprendre les derniers développements du marché boursier, vous devez obtenir et analyser les informations boursières en temps opportun. La méthode traditionnelle consiste à ouvrir manuellement les principaux sites Web financiers pour afficher les données boursières une par une. Cette méthode est évidemment trop lourde et inefficace. À l’heure actuelle, les robots d’exploration sont devenus une solution très efficace et automatisée. Ensuite, nous montrerons comment utiliser PHP pour écrire un programme simple d'analyse des actions afin d'obtenir des données boursières. permettre
 Pratique PHP : exploration des données du barrage Bilibili
Jun 13, 2023 pm 07:08 PM
Pratique PHP : exploration des données du barrage Bilibili
Jun 13, 2023 pm 07:08 PM
Bilibili est un site Web de vidéos de barrage populaire en Chine. C'est également un trésor contenant toutes sortes de données. Parmi elles, les données de barrage sont une ressource très précieuse, c'est pourquoi de nombreux analystes de données et chercheurs espèrent obtenir ces données. Dans cet article, je présenterai l'utilisation du langage PHP pour explorer les données du barrage Bilibili. Travail de préparation Avant de commencer à explorer les données du barrage, nous devons installer un framework de robot d'exploration PHP Symphony2. Vous pouvez entrer via la commande suivante
