

Explication détaillée de l'algorithme LRU de Redis

Ce qui suit est une explication détaillée de l'algorithme LRU de Redis tirée de la colonne Tutoriel Redis J'espère que cela sera utile aux amis dans le besoin !

Algorithme LRU de Redis
L'idée derrière l'algorithme LRU est omniprésente en informatique, et elle est très similaire au « principe de localité » du programme. Dans un environnement de production, bien qu'il existe des alarmes d'utilisation de la mémoire Redis, il est toujours utile de comprendre la stratégie d'utilisation du cache de Redis. Voici la stratégie d'utilisation de Redis dans l'environnement de production : la mémoire maximale disponible est limitée à 4 Go et la stratégie de suppression allkeys-lru est adoptée. La stratégie dite de suppression : lorsque l'utilisation de Redis a atteint la mémoire maximale, par exemple 4 Go, si une nouvelle clé est ajoutée à Redis à ce moment-là, Redis sélectionnera une clé à supprimer. Alors, comment choisir la clé appropriée à supprimer ?
CONFIG GET maxmemory
- "maxmemory"
- "4294967296"
CONFIG GET maxmemory-policy
- "maxmemory-policy"
- "allkeys-lru"
Dans le document officiel Utilisation de Redis comme description du cache LRU, plusieurs sont fournis A variété de stratégies de suppression, telles que allkeys-lru, volatile-lru, etc. À mon avis, trois facteurs sont pris en compte lors de la sélection : le caractère aléatoire, la dernière fois que la clé a été accédée et le délai d'expiration (TTL) de la clé
Par exemple : allkeys-lru, "Count all "Heure d'accès historique à la clé, supprimez la clé "la plus ancienne". Remarque : j'ai ajouté des guillemets ici. En fait, dans l'implémentation spécifique de Redis, il est très coûteux de compter le temps d'accès récent de toutes les clés. Pensez-y, comment faire ?
expulsez les clés en essayant de supprimer d'abord les clés les moins récemment utilisées (LRU), afin de libérer de l'espace pour les nouvelles données ajoutées.
Autre exemple : allkeys- Aléatoire signifie sélectionner une clé au hasard et la supprimer.
expulsez les clés de manière aléatoire afin de faire de la place pour les nouvelles données ajoutées.
Autre exemple : volatile-lru, qui supprime uniquement celles qui ont expiré à l'aide de la commande expire La clé temporelle est supprimée selon l'algorithme LRU.
expulsez les clés en essayant de supprimer d'abord les clés les moins récemment utilisées (LRU), mais uniquement parmi les clés qui ont un ensemble d'expiration, afin de faire de la place pour les nouvelles données ajouté.
Un autre exemple : volatile-ttl, qui supprime uniquement les clés dont le délai d'expiration est défini à l'aide de la commande expire. Quelle clé a un temps de survie plus court (plus la clé TTL est petite), sera. déplacé en premier.
expulsez les clés avec un ensemble d'expiration et essayez d'abord d'expulser les clés avec une durée de vie (TTL) plus courte, afin de libérer de l'espace pour les nouvelles données ajoutées.
Les clés sur lesquelles fonctionnent les stratégies volatiles (méthodes d'expulsion) sont les clés dont le délai d'expiration est défini. Dans la structure redisDb, un dictionnaire (dict) nommé expires est défini pour enregistrer toutes les clés dont le délai d'expiration est défini avec la commande expire, où les clés du dictionnaire expires pointent vers l'espace clé de la base de données redis ( redisServer-- ->redisDb--->redisObject), et la valeur du dictionnaire expires est le délai d'expiration de cette clé (entier de type long).
Une mention supplémentaire : l'espace clé de la base de données redis fait référence : à un pointeur nommé "dict" défini dans la structure redisDb et de type dictionnaire de hachage, qui sert à sauvegarder chaque objet clé dans la base de données redis et l'objet valeur correspondant. .
Comme il existe de nombreuses stratégies, laquelle dois-je utiliser ? Cela implique le modèle d'accès (modèle d'accès) de la clé dans Redis. Le modèle d'accès est lié à la logique métier du code. Par exemple, les clés qui répondent à certaines caractéristiques sont souvent consultées, tandis que d'autres clés sont rarement utilisées. Si toutes les clés ont la même chance d'être accessibles par notre application, alors son modèle d'accès obéit à une distribution uniforme ; dans la plupart des cas, le modèle d'accès obéit à une loi de puissance. De plus, le modèle d'accès de Key peut également changer au fil du temps. une stratégie de suppression appropriée est donc nécessaire pour attraper (capturer) diverses situations. Sous la distribution d'énergie, LRU est une bonne stratégie :
Bien que les caches ne puissent pas prédire l'avenir, ils peuvent raisonner de la manière suivante :les clés susceptibles d'être à nouveau demandées sont des clés qui ont été récemment demandés souventComme les modèles d'accès ne changent généralement pas très soudainement, il s'agit d'une stratégie efficace.
Mise en œuvre de la stratégie LRU dans Redis
La plus intuitive. idée : LRU, enregistrez l'heure d'accès la plus récente de chaque clé (comme l'horodatage Unix). La clé avec le plus petit horodatage Unix est celle qui n'a pas été utilisée récemment, et supprimez cette clé. Il semble qu'un HashMap puisse le faire. Oui, mais vous devez d'abord stocker chaque clé et son horodatage. Deuxièmement, l'horodatage doit être comparé pour obtenir la valeur minimale. Le coût est très élevé et irréaliste.
La deuxième méthode : d'un autre point de vue, n'enregistrez pas le point temporel d'accès spécifique (horodatage Unix), mais enregistrez le temps d'inactivité : plus le temps d'inactivité est petit, cela signifie qu'il a été consulté récemment.
L'algorithme LRU élimine la clé la moins récemment utilisée, c'est-à-dire celle avec le temps d'inactivité le plus long.
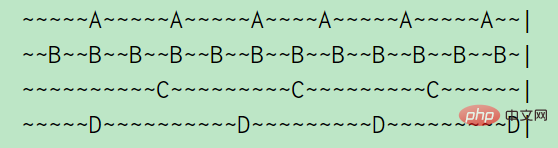
Par exemple, A, B , C, D quatre touches, A est accessible toutes les 5 secondes, B est accessible toutes les 2 secondes, C et D sont accessibles toutes les 10 secondes. (Un tilde représente 1 s), comme le montre l'image ci-dessus : le temps d'inactivité de A est de 2 s, le temps d'inactivité de B est de 1 s, le temps d'inactivité de C est de 5 s, D vient de visiter donc le temps d'inactivité est de 0 s
Ici , utilisez une liste doublement chaînée pour répertorier toutes les clés. Si une clé est accédée, déplacez la clé en tête de la liste chaînée. Lorsque vous souhaitez supprimer la clé, supprimez-la directement de la fin de la liste.
C'est simple à mettre en œuvre car tout ce que nous avons à faire est de suivre la dernière fois qu'une clé donnée a été accédée, ou parfois ce n'est même pas nécessaire : nous pouvons simplement avoir tous les objets que nous voulons expulser les liens dans une liste chaînée.
Mais dans Redis, il n'est pas implémenté de cette manière car il pense que LinkedList prend trop de place. Redis n'implémente pas la base de données KV directement sur la base de structures de données telles que des chaînes, des listes chaînées et des dictionnaires. Au lieu de cela, il crée un système d'objets Redis Object basé sur ces structures de données. Un champ de type non signé de 24 bits est défini dans la structure redisObject pour stocker la dernière fois que l'objet a été accédé par le programme de commande :
En modifiant un peu la structure Redis Object, j'ai pu créer 24 bits d'espace. Il n'y avait pas de place pour lier les objets dans une liste chaînée (gros pointeurs !)
Après tout, un algorithme LRU complètement précis n'est pas requis, même si le plus récent est supprimé. La clé consultée a peu d’impact.
Ajouter une autre structure de données pour prendre ces métadonnées n'était pas une option, mais puisque LRU est en soi une approximation de ce que nous voulons réaliser, qu'en est-il de l'approximation de LRU elle-même ?
Initialement, Redis a été implémenté comme ceci :
Sélectionnez au hasard trois clés et supprimez la clé avec le temps d'inactivité le plus long. Plus tard, 3 a été remplacé par un paramètre configurable, et la valeur par défaut était N=5 : maxmemory-samples 5
quand il faut expulser une clé, sélectionnez 3 clés aléatoires et expulsez celle avec le plus haut temps d'inactivité
C'est si simple, incroyablement simple et très efficace. Mais il présente encore des défauts : à chaque fois qu'il est sélectionné au hasard, les informations historiques ne sont pas utilisées. Lorsque vous supprimez (expulsez) une clé à chaque tour, sélectionnez au hasard une clé parmi N et retirez la clé avec le temps d'inactivité le plus long au tour suivant, sélectionnez au hasard une clé parmi N... Y avez-vous pensé ? le processus de suppression des clés lors du dernier tour, nous connaissions en fait le temps d'inactivité des N clés. Puis-je faire bon usage de certaines des informations que j'ai apprises lors du tour précédent lors de la suppression des clés au tour suivant ?
Cependant, si vous réfléchissez à cet algorithme à travers ses exécutions, vous pouvez voir à quel point nous détruisons beaucoup de données intéressantes. Peut-être que lors de l'échantillonnage des touches N, nous en rencontrons beaucoup. de bons candidats, mais nous éliminons ensuite les meilleurs et recommençons à zéro le cycle suivant.
repartir de zéro est trop idiot. Redis a donc apporté une autre amélioration : utiliser le pooling de tampons (pooling)
Lorsque la clé est supprimée à chaque tour, le temps d'inactivité de ces N clés est obtenu si son temps d'inactivité est plus long que la clé du pool If. le temps d'inactivité est encore plus long, ajoutez-le au pool. De cette façon, la clé supprimée à chaque fois est non seulement la plus grande parmi les N clés sélectionnées au hasard, mais également la plus grande période d'inactivité dans le pool, et : la clé dans le pool a été examinée à travers plusieurs cycles de comparaison, et son inactivité time Le temps est plus susceptible d'être plus long que le temps d'inactivité d'une clé obtenue aléatoirement. Cela peut être compris comme suit : la clé dans le pool conserve des « informations d'expérience historique ».
Fondamentalement, lorsque l'échantillonnage de N clés a été effectué, il a été utilisé pour remplir un plus grand pool de clés (seulement 16 clés par défaut). Ce pool a les clés triées par temps d'inactivité, donc les nouvelles clés uniquement. entrer dans la piscine lorsqu'ils ont un temps d'inactivité supérieur à une clé dans la piscine ou lorsqu'il y a de l'espace vide dans la piscine.
Grâce à "pool", un problème de tri global se transforme en un problème local Question de comparaison. (Bien que le tri soit essentiellement une comparaison, 囧). Pour connaître la clé avec le temps d'inactivité le plus long, un LRU précis doit trier le temps d'inactivité des clés globales, puis trouver la clé avec le temps d'inactivité le plus long. Cependant, une idée approximative peut être adoptée, c'est-à-dire échantillonner (échantillonner) de manière aléatoire plusieurs clés, qui représentent les clés globales, mettre les clés obtenues par échantillonnage dans le pool et mettre à jour le pool après chaque échantillonnage, de sorte que les clés du pool Les clés avec le temps d'inactivité le plus long parmi les clés sélectionnées aléatoirement sont toujours enregistrées. Lorsqu'une clé d'expulsion est nécessaire, retirez directement du pool la clé ayant le temps d'inactivité le plus long et expulsez-la. Cette idée mérite d’être apprise.
À ce stade, l'analyse de la stratégie de suppression basée sur LRU est terminée. Il existe également une stratégie de suppression basée sur LFU (fréquence d'accès) dans Redis, dont je parlerai plus tard.
Implémentation LRU en JAVA
LinkedHashMap dans JDK implémente l'algorithme LRU, en utilisant la méthode de construction suivante, accessOrder représente la norme de mesure "la moins récemment utilisée". Par exemple, accessOrder=true, lors de l'exécution de l'élément java.util.LinkedHashMap#get, cela signifie que cet élément a été accédé récemment.
/**
* Constructs an empty <tt>LinkedHashMap</tt> instance with the
* specified initial capacity, load factor and ordering mode.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @param accessOrder the ordering mode - <tt>true</tt> for
* access-order, <tt>false</tt> for insertion-order
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}Puis réécrivez : méthode java.util.LinkedHashMap#removeEldestEntry.
La méthode {@link #removeEldestEntry(Map.Entry)} peut être remplacée pour imposer une politique de suppression automatique des mappages obsolètes lorsque de nouveaux mappages sont ajoutés à la carte.
Afin de garantir la sécurité des threads, utilisez Collections.synchronizedMap pour envelopper l'objet LinkedHashMap :
Notez que cette implémentation n'est pas synchronisée si plusieurs threads accèdent simultanément à une carte de hachage liée, et au moins un. des threads modifie structurellement la carte, elle doit être synchronisée en externe. Ceci est généralement accompli en synchronisant sur un objet qui encapsule naturellement la carte >
Lorsque la capacité dépasse 100, commencez à exécuter la politique LRU : expulsez le moins récemment. objet TimeoutInfoHolder inutilisé.final Map<Long, TimeoutInfoHolder> timeoutInfoHandlers = Collections.synchronizedMap(new LinkedHashMap<Long, TimeoutInfoHolder>(100, .75F, true) { @Override protected boolean removeEldestEntry(Map.Entry eldest) { return size() > 100; } });Copier après la connexion
Liens de référence :
Notes aléatoires sur l'amélioration de l'algorithme Redis LRUUtiliser Redis comme cache LRU- Enfin, encore une fois Parlons de quelque chose sans rapport avec cet article : Quelques réflexions sur le traitement des données :
- La 5G a la capacité de permettre à toutes sortes de nœuds de se connecter au réseau, ce qui générera une grande quantité de données. Comment traiter et exploiter ces données. efficacement ? Les modèles cachés derrière (apprentissage automatique, apprentissage profond) sont une chose très intéressante, car ces données sont en réalité des reflets objectifs du comportement humain. Par exemple, la fonction de comptage de pas de WeChat Sports vous permettra de découvrir : Hé, il s'avère que mon niveau d'activité est d'environ 10 000 pas par jour. En allant plus loin, à l’avenir, divers équipements industriels et appareils électroménagers généreront une variété de données. Ces données sont le reflet des activités sociales et humaines. Comment faire un usage raisonnable de ces données ? Le système de stockage existant peut-il prendre en charge le stockage de ces données ? Existe-t-il un système informatique efficace (spark ou tensorflow...) pour analyser la valeur cachée dans les données ? De plus, le modèle d’algorithme formé sur la base de ces données entraînera-t-il un biais après application ? Y a-t-il une utilisation abusive des données ? Les algorithmes vous recommanderont des choses lorsque vous achetez des choses en ligne. Des publicités ciblées seront placées sur vous lors de la navigation dans Moments. Les modèles évalueront également le montant que vous devez emprunter et le montant que vous souhaitez emprunter lors de la lecture des actualités. et les potins de divertissement. La plupart des choses que vous voyez et avec lesquelles vous êtes en contact chaque jour sont des décisions prises par ces « systèmes de données ». Sont-ils vraiment justes ? En réalité, si vous faites une erreur et que vos professeurs, vos amis et votre famille vous donnent des commentaires et des corrections, et que vous la modifiez, vous pouvez repartir de zéro. Mais qu’en est-il de ces systèmes de données ? Existe-t-il un mécanisme de rétroaction pour la correction des erreurs ? Cela incitera-t-il les gens à s’enfoncer de plus en plus profondément ? Même si vous êtes honnête et avez un bon crédit, le modèle d'algorithme peut toujours avoir des biais probabilistes. Cela affecte-t-il les chances d'une « concurrence loyale » pour les humains ? Ce sont des questions qui méritent réflexion pour les développeurs de données.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données Redis: utilisez la commande flushall pour effacer toutes les valeurs de clé. Utilisez la commande flushdb pour effacer la valeur clé de la base de données actuellement sélectionnée. Utilisez SELECT pour commuter les bases de données, puis utilisez FlushDB pour effacer plusieurs bases de données. Utilisez la commande del pour supprimer une clé spécifique. Utilisez l'outil Redis-CLI pour effacer les données.
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
L'utilisation des opérations Redis pour verrouiller nécessite l'obtention du verrouillage via la commande setnx, puis en utilisant la commande Expire pour définir le temps d'expiration. Les étapes spécifiques sont les suivantes: (1) Utilisez la commande setnx pour essayer de définir une paire de valeurs de clé; (2) Utilisez la commande Expire pour définir le temps d'expiration du verrou; (3) Utilisez la commande del pour supprimer le verrouillage lorsque le verrouillage n'est plus nécessaire.
 Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Redis utilise des tables de hachage pour stocker les données et prend en charge les structures de données telles que les chaînes, les listes, les tables de hachage, les collections et les collections ordonnées. Redis persiste les données via des instantanés (RDB) et ajoutez les mécanismes d'écriture uniquement (AOF). Redis utilise la réplication maître-esclave pour améliorer la disponibilité des données. Redis utilise une boucle d'événement unique pour gérer les connexions et les commandes pour assurer l'atomicité et la cohérence des données. Redis définit le temps d'expiration de la clé et utilise le mécanisme de suppression paresseux pour supprimer la clé d'expiration.
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment faire du message middleware pour redis
Apr 10, 2025 pm 07:51 PM
Comment faire du message middleware pour redis
Apr 10, 2025 pm 07:51 PM
Redis, en tant que Message Middleware, prend en charge les modèles de consommation de production, peut persister des messages et assurer une livraison fiable. L'utilisation de Redis comme Message Middleware permet une faible latence, une messagerie fiable et évolutive.
