
 base de données
tutoriel mysql
La base de données MVCC la plus complète de tout le réseau, je suis responsable de toute explication incomplète.
base de données
tutoriel mysql
La base de données MVCC la plus complète de tout le réseau, je suis responsable de toute explication incomplète.
La base de données MVCC la plus complète de tout le réseau, je suis responsable de toute explication incomplète.

Recommandations d'apprentissage associées : Tutoriel MySQL
Qu'est-ce que MVCC
Le nom complet est Multi-Version Concurrency Control, qui est 多版本并发控制, principalement pour améliorer le 并发性能 de la base de données. Les articles suivants concernent uniquement le moteur InnoDB, car myIsam ne prend pas en charge les transactions.
Lorsqu'une demande de lecture ou d'écriture se produit pour la même ligne de données, elle 上锁阻塞 se fige. Mais mvcc utilise une meilleure façon de gérer les requêtes de lecture-écriture, de sorte que lorsqu'un conflit de requête de lecture-écriture se produit 不用加锁.
Cette lecture fait référence à 快照读, pas à 当前读. La lecture actuelle est une opération de verrouillage, qui est 悲观锁.
Alors comment lit-on et écrit 不用加锁 ? Qu'est-ce que c'est que 快照读 et 当前读 Suivez votre 贴心老哥 et continuez à lire.

Que sont la lecture actuelle et la lecture d'instantané
Que sont la lecture actuelle et la lecture d'instantané sous MySQL InnoDB ?
Lecture actuelle
Les enregistrements de base de données qu'il lit sont tous 当前最新 de 版本, et les données actuellement lues seront 加锁éditées pour empêcher d'autres transactions de modifier les données. C'est une opération de 悲观锁.
Les opérations suivantes sont des lectures actuelles :
sélectionner le verrouillage en mode partage (verrouillage partagé)
sélectionner pour la mise à jour ( verrouillage exclusif)
mettre à jour (verrouillage exclusif)
insérer (verrouillage exclusif)
supprimer (Verrouillage exclusif)
Niveau d'isolement des transactions sérialisées
Lecture d'instantané
La mise en œuvre de la lecture d'instantané est basée sur 多版本 Contrôle de concurrence, c'est-à-dire MVCC, puisqu'il est multi-version, les données lues par l'instantané ne sont pas forcément les dernières données, il peut s'agir des 历史版本 données précédentes.
Les opérations suivantes sont des lectures d'instantanés :
- Sélectionner l'opération sans verrouillage (remarque : le niveau de transaction n'est pas sérialisé)
Lecture d'instantané et mvcc La relation
MVCCC est un 抽象概念 qui "conserve plusieurs versions d'une donnée afin que les opérations de lecture et d'écriture soient sans conflit".
Ce concept nécessite la mise en œuvre de fonctions spécifiques, et cette implémentation spécifique est 快照读. (La mise en œuvre spécifique est discutée ci-dessous)
Après avoir écouté l'explication de 贴心老哥, c'était instantanément 茅厕顿开.

Scénario de concurrence de base de données
读-读: Il n'y a aucun problème et aucun contrôle de concurrence n'est requis读-写: Il existe des problèmes de sécurité des threads, qui peuvent entraîner des problèmes d'isolation des transactions et rencontrer des lectures sales, des lectures fantômes et des lectures non répétables-
写-写: Il existe des problèmes de sécurité des threads et il peut y avoir des problèmes de perte de mise à jour, tels que le premier type de perte de mise à jour, le deuxième type de perte de mise à jour
Quels problèmes de concurrence MVCC résout-il ?
Le contrôle de concurrence sans verrouillage utilisé par mvcc pour résoudre les conflits de lecture-écriture consiste à allouer 单向增长 aux transactions. Enregistrez un 时间戳, un horodatage de version et de transaction 版本 pour chaque modification de données. 相关联
de la transaction 只读取. 开始前数据库快照
- : L'opération de lecture peut être réalisée sans bloquer l'opération d'écriture, et l'écriture L'opération ne bloquera pas l'opération de lecture.
并发读-写时 résout les problèmes d'isolation des transactions tels que - ,
,
脏读, etc., mais ne peut pas résoudre le problème幻读ci-dessus.不可重复读写-写 更新丢失
pour améliorer les performances de concurrence : 组合拳
- : MVCC résout la lecture et conflit d'écriture, le verrouillage pessimiste résout les conflits d'écriture-écriture
MVCC + 悲观锁 - : MVCC résout les conflits de lecture-écriture, le verrouillage optimiste résout les conflits d'écriture-écriture
MVCC + 乐观锁Principe de mise en œuvre de MVCC
Son principe de mise en œuvre est principalement mis en œuvre par
,, 版本链 undo日志Read View Chaîne de versions
Chaque ligne de données de notre base de données, En plus des données visibles à l'œil nu, il existe plusieurs
, qui ne peuvent être vues qu'en ouvrant. Ce sont respectivement 隐藏字段, 天眼 et db_trx_id. db_roll_pointerdb_row_id
- db_trx_id
6octets, dernière modification (modification/insertion)
事务ID: enregistrement创建cet enregistrement/最后一次修改事务IDde cet enregistrement.-
db_roll_pointer (clé de chaîne de version)
7 octets,
回滚指针, pointant vers这条记录de上一个版本(stocké dans le segment de restauration) -
db_row_id
6 octets, implicite
自增ID(clé primaire cachée), si la table de données est没有主键, InnoDB générera automatiquement un聚簇索引avec db_row_id. a effectivement un
删除flagchamp caché. L'enregistrement étant更新ou删除ne signifie pas qu'il est réellement supprimé, mais que le删除flaga changé

est le db_row_id généré par la base de données par défaut pour cette ligne d'enregistrements, et 唯一隐式主键 est l'opération actuelle de cet enregistrement db_trx_id, et 事务ID est un db_roll_pointer utilisé pour faire correspondre 回滚指针 et pointer vers le undo日志 précédent. 旧版本
sera enregistré. Chaque journal d'annulation possède également un attribut undo日志 (le journal d'annulation correspondant à l'opération INSERT n'a pas cet attribut car l'enregistrement l'a). pas été mis à jour (version antérieure), vous pouvez ajouter ces roll_pointer, undo日志都连起来, donc la situation actuelle est comme l'image ci-dessous : 串成一个链表
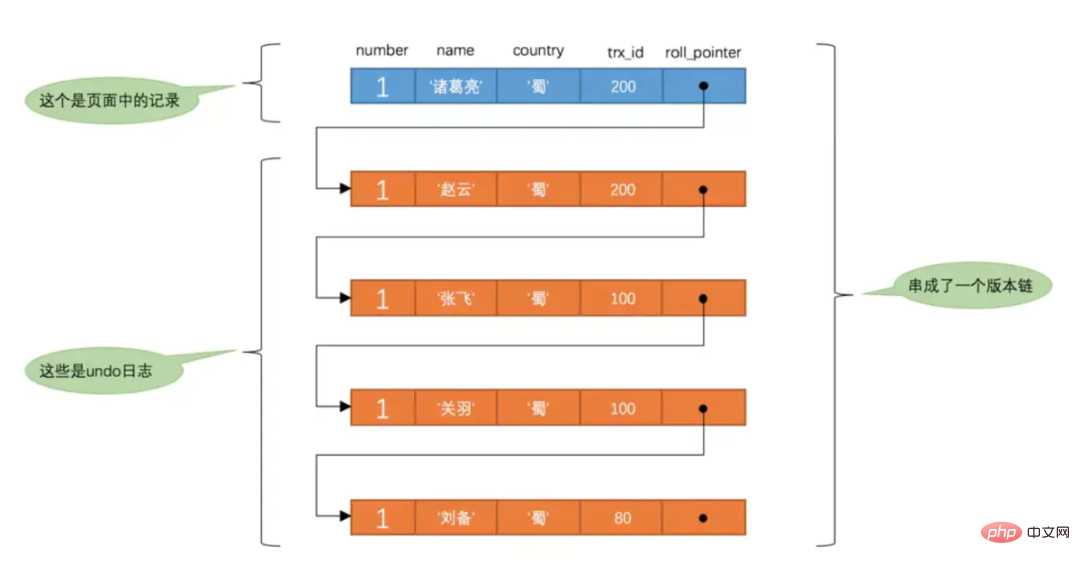
par le <.> attribut.Nous mettons Cette liste chaînée est appelée roll_pointer, et le nœud principal de la chaîne de versions est la dernière valeur de l'enregistrement actuel. De plus, chaque version contient également l'identifiant de transaction correspondant au moment où la version a été générée. Ces informations sont très importantes et seront utilisées pour juger de la visibilité de la version basée sur ReadView. 链表版本链Annuler le journal
Le journal d'annulation est principalement utilisé pour les journaux où
les données sont Les données seront copiées dans 记录 avant que les informations de la table ne soient modifiées. 修改之前undo logLorsque
peut être effectué 事务 via le journal d'annulation de connexion. 回滚时数据还原
- Garantie
- lorsque
est en cours
事务, lorsque la transaction est en coursrollbackVous pouvez utiliser les données d'annulation du journal原子性和一致性.回滚恢复 est utilisé pour les données de MVCC - Dans le contrôle multi-version MVCC, en lisant le
de
快照读, on peut se rendre compte queundo loga. le sien历史版本数据.不同事务版本号独立的快照数据版本
- insérer le journal d'annulation
-
représente le transaction dans Le journal d'annulation généré lors de l'insertion de nouveaux enregistrements n'est nécessaire que lorsque la transaction est annulée et peut être supprimé immédiatement après la validation de la transaction
mettre à jour le journal d'annulation (principal) -
Le journal d'annulation généré lorsqu'une transaction est mise à jour ou supprimée ; non seulement nécessaire lorsqu'une transaction est annulée, mais également lorsqu'un instantané est lu
afin qu'il ne puisse pas être supprimé par hasard, et ce journal ; n'est utilisé que lorsque la lecture rapide ou l'annulation de transaction ne l'implique pas, les journaux correspondants seront effacés uniformément par le fil de purge
Read View (Read View)
Produit lorsque la transaction effectue l'
opération( Read View), au moment où l'instantané de l'exécution de la transaction est lu, un 快照读 actuel du système de base de données sera généré. 读视图快照Enregistrer et maintenir le
actuellement dans le système qui ne devrait pas être vu par 活跃事务的ID. 本事务其他事务id列表Read View est principalement utilisé pour
exécutons 可见性, nous créons une Read View pour l'enregistrement et la comparons à une condition de jugement 某个事务. peut voir les données de 快照读, qui peuvent être les données du 当前事务 actuel ou les données de 哪个版本 dans le journal d'annulation enregistré dans cette ligne. 最新某个版本
- : Une collection de numéros de version de transaction actifs (
) dans le système actuel.
trx_ids未提交 - : "Système actuel
+1" lors de la création de la vue de lecture actuelle.
low_limit_id up_limit_id: "Le système est en transaction active最小版本号" lors de la création de la vue de lecture actuellecreator_trx_id: Création de la transaction de le numéro de version actuel de la vue en lecture ;
Condition de jugement de visibilité de la vue en lecture
-
db_trx_id<up_limit_id||db_trx_id==creator_trx_id(affichage)Si l'ID de transaction de données est plus petit que le
最小活跃事务IDdans la vue de lecture, vous pouvez être sûr que les données sont déjà dans当前事务启之前存在Oui, donc ça va显示.ou le
事务IDdes données est égal àcreator_trx_id, alors ces données sont la transaction en cours自己生成的Bien sûr, les données que vous générez peuvent être vues par vous-même, donc dans ce cas, ces données peuvent également être显示. db_trx_id>=low_limit_id(non affiché)Si l'ID de transaction de données est supérieur au
最大事务IDdu système actuel dans la lecture vue, cela signifie que les données sont créées之后才产生dans la vue de lecture actuelle, donc les données sont不显示. S'il est inférieur à, entrez le jugement suivant si-
db_trx_idest dans活跃事务(trx_ids)不存在: alors cela signifie lire La transaction est已经commitlorsque la vue est générée. Dans ce cas, les données peuvent être显示.已存在: Cela signifie que lorsque ma vue de lecture est générée, votre transaction est toujours active et n'a pas encore été validée. Les données que vous avez modifiées sont également invisibles pour ma transaction en cours.

MVCC et niveau d'isolement des transactions
Comme mentionné ci-dessusRead View Utilisé pour prendre en charge RC (Lecture validée, soumission de lecture) et RR (Lecture répétable, lecture répétable) 隔离级别 pour 实现.
Calendrier des générations RR et RC
RCSous le niveau d'isolement, chaque快照读sera生成并获取最新Read View > ; Sous le niveau d'isolement
RR, seul同一个事务中de第一个快照读créeraRead View,之后的les lectures d'instantanés obtiendront tous les同一个Read View, et les requêtes suivantes seront不会重复生成, donc les résultats de la requête d'une transaction sont都是一样的à chaque fois.
Résoudre le problème de lecture fantôme
快照读: Contrôlé via MVCC, aucun verrouillage requis. Effectuez des opérations telles que des ajouts, des suppressions, des modifications et des recherches selon la « grammaire » spécifiée dans MVCC pour éviter la lecture fantôme.当前读: résolvez le problème grâce au verrouillage de la touche suivante (verrouillage de rangée + verrouillage d'espace).
La différence entre la lecture d'instantanés InnoDB aux niveaux RC et RR
La première lecture d'un certain enregistrement par une certaine transaction au niveau RR La deuxième lecture d'instantané créera un instantané et une vue de lecture pour enregistrer d'autres transactions actives dans le système actuel. Après cela, lors de l'appel de la lecture d'instantané, la même vue de lecture sera toujours utilisée, tant que la transaction en cours est utilisée avant les autres. les transactions soumettent des mises à jour Lecture d'instantané, puis les lectures d'instantané suivantes utilisent la même vue de lecture, donc les modifications ultérieures ne sont pas visibles
C'est-à-dire, au niveau RR, lorsque la lecture d'instantané génère une lecture ; View, Read View enregistrera des instantanés de toutes les autres transactions actives à ce moment-là, et les modifications de ces transactions ne seront pas visibles pour la transaction en cours. Les modifications apportées par les transactions créées avant la Read View sont visibles
Au niveau RC, dans une transaction, chaque lecture d'instantané générera un nouvel instantané et une nouvelle Read View. peut voir les mises à jour soumises par d'autres transactions dans les transactions au niveau RC
Résumé
Comme nous pouvons le voir dans la description ci-dessus, le soi-disant MVCC fait référence au processus d'utiliser les deux niveaux d'isolement de READ COMMITTD et REPEATABLE READ pour accéder aux SEELCT enregistrés lors de l'exécution d'opérations 版本链 ordinaires. De cette façon, les 读-写 des différentes transactions sont accessibles, 写-读 opère , donc 并发执行. 提升系统性能
Si vous souhaitez en savoir plus sur la programmation, faites attention à la rubriqueFormation php !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Compétences de traitement de structures de données volumineuses de PHP
May 08, 2024 am 10:24 AM
Compétences de traitement de structures de données volumineuses de PHP
May 08, 2024 am 10:24 AM
Compétences en matière de traitement de la structure des Big Data : Chunking : décomposez l'ensemble de données et traitez-le en morceaux pour réduire la consommation de mémoire. Générateur : générez des éléments de données un par un sans charger l'intégralité de l'ensemble de données, adapté à des ensembles de données illimités. Streaming : lisez des fichiers ou interrogez les résultats ligne par ligne, adapté aux fichiers volumineux ou aux données distantes. Stockage externe : pour les ensembles de données très volumineux, stockez les données dans une base de données ou NoSQL.
 Comment optimiser les performances des requêtes MySQL en PHP ?
Jun 03, 2024 pm 08:11 PM
Comment optimiser les performances des requêtes MySQL en PHP ?
Jun 03, 2024 pm 08:11 PM
Les performances des requêtes MySQL peuvent être optimisées en créant des index qui réduisent le temps de recherche d'une complexité linéaire à une complexité logarithmique. Utilisez PreparedStatements pour empêcher l’injection SQL et améliorer les performances des requêtes. Limitez les résultats des requêtes et réduisez la quantité de données traitées par le serveur. Optimisez les requêtes de jointure, notamment en utilisant des types de jointure appropriés, en créant des index et en envisageant l'utilisation de sous-requêtes. Analyser les requêtes pour identifier les goulots d'étranglement ; utiliser la mise en cache pour réduire la charge de la base de données ; optimiser le code PHP afin de minimiser les frais généraux.
 Comment utiliser la sauvegarde et la restauration MySQL en PHP ?
Jun 03, 2024 pm 12:19 PM
Comment utiliser la sauvegarde et la restauration MySQL en PHP ?
Jun 03, 2024 pm 12:19 PM
La sauvegarde et la restauration d'une base de données MySQL en PHP peuvent être réalisées en suivant ces étapes : Sauvegarder la base de données : Utilisez la commande mysqldump pour vider la base de données dans un fichier SQL. Restaurer la base de données : utilisez la commande mysql pour restaurer la base de données à partir de fichiers SQL.
 Comment insérer des données dans une table MySQL en utilisant PHP ?
Jun 02, 2024 pm 02:26 PM
Comment insérer des données dans une table MySQL en utilisant PHP ?
Jun 02, 2024 pm 02:26 PM
Comment insérer des données dans une table MySQL ? Connectez-vous à la base de données : utilisez mysqli pour établir une connexion à la base de données. Préparez la requête SQL : Écrivez une instruction INSERT pour spécifier les colonnes et les valeurs à insérer. Exécuter la requête : utilisez la méthode query() pour exécuter la requête d'insertion en cas de succès, un message de confirmation sera généré.
 Comment corriger les erreurs mysql_native_password non chargé sur MySQL 8.4
Dec 09, 2024 am 11:42 AM
Comment corriger les erreurs mysql_native_password non chargé sur MySQL 8.4
Dec 09, 2024 am 11:42 AM
L'un des changements majeurs introduits dans MySQL 8.4 (la dernière version LTS en 2024) est que le plugin « MySQL Native Password » n'est plus activé par défaut. De plus, MySQL 9.0 supprime complètement ce plugin. Ce changement affecte PHP et d'autres applications
 Comment utiliser les procédures stockées MySQL en PHP ?
Jun 02, 2024 pm 02:13 PM
Comment utiliser les procédures stockées MySQL en PHP ?
Jun 02, 2024 pm 02:13 PM
Pour utiliser les procédures stockées MySQL en PHP : Utilisez PDO ou l'extension MySQLi pour vous connecter à une base de données MySQL. Préparez l'instruction pour appeler la procédure stockée. Exécutez la procédure stockée. Traitez le jeu de résultats (si la procédure stockée renvoie des résultats). Fermez la connexion à la base de données.
 Comment créer une table MySQL en utilisant PHP ?
Jun 04, 2024 pm 01:57 PM
Comment créer une table MySQL en utilisant PHP ?
Jun 04, 2024 pm 01:57 PM
La création d'une table MySQL à l'aide de PHP nécessite les étapes suivantes : Connectez-vous à la base de données. Créez la base de données si elle n'existe pas. Sélectionnez une base de données. Créer un tableau. Exécutez la requête. Fermez la connexion.
 La différence entre la base de données Oracle et MySQL
May 10, 2024 am 01:54 AM
La différence entre la base de données Oracle et MySQL
May 10, 2024 am 01:54 AM
La base de données Oracle et MySQL sont toutes deux des bases de données basées sur le modèle relationnel, mais Oracle est supérieur en termes de compatibilité, d'évolutivité, de types de données et de sécurité ; tandis que MySQL se concentre sur la vitesse et la flexibilité et est plus adapté aux ensembles de données de petite et moyenne taille. ① Oracle propose une large gamme de types de données, ② fournit des fonctionnalités de sécurité avancées, ③ convient aux applications de niveau entreprise ; ① MySQL prend en charge les types de données NoSQL, ② a moins de mesures de sécurité et ③ convient aux applications de petite et moyenne taille.
