


Recommandations d'apprentissage associées : tutoriel Python
Aujourd'hui, c'est le traitement des données Pandas Dans le sixième article du sujet, parlons des opérations de tri et de synthèse de DataFrame.
Dans l'article précédent, nous avons principalement présenté la méthode apply dans DataFrame, comment effectuer des opérations de diffusion sur chaque ligne ou colonne d'un DataFrame, afin que nous puissions effectuer un traitement très court du des données entières dans un certain laps de temps. Aujourd'hui, nous allons parler de comment trier un DataFrame en fonction de nos besoins et comment utiliser certaines opérations récapitulatives.
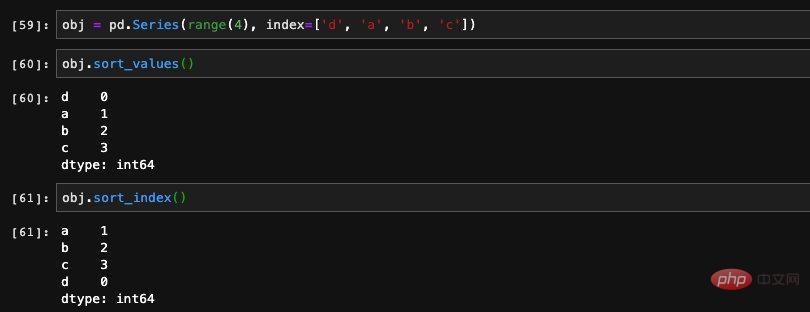
Le tri est un besoin très fondamental pour nous Chez les pandas, nous. will Cette exigence est subdivisée en tri basé sur index et tri basé sur valeur. Jetons d'abord un coup d'œil à la méthode de tri dans Series.
Il existe deux méthodes de tri dans Series. L'une est sort_index. Comme son nom l'indique, ces valeurs sont triées en fonction de l'index dans Series. L'autre est sort_values, qui est trié en fonction des valeurs de la série. Les deux méthodes renvoient une nouvelle série :
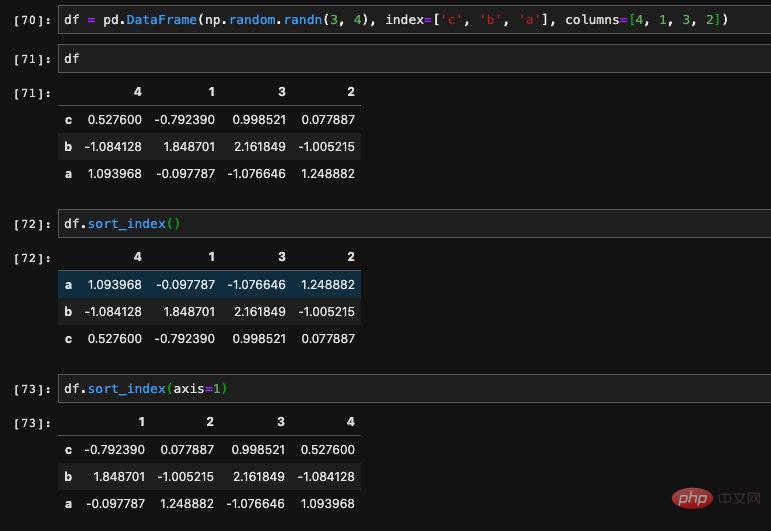
Le même est vrai pour DataFrame, qui a également deux fonctions : le tri par valeur et le tri par index. Mais comme DataFrame est une donnée bidimensionnelle, il y aura quelques différences d'utilisation. La différence la plus simple est que Series n'a qu'une seule colonne. Nous connaissons clairement l'objet de tri, mais pas DataFrame. Les index qu'il contient sont divisés en deux types, à savoir l'index de ligne et l'index de colonne. Ainsi, lorsque nous trions , nous devons spécifier l'axe sur lequel nous voulons trier, c'est-à-dire l'axe.
Par défaut, nous trions en fonction de l'index des lignes. Si nous voulons spécifier un tri basé sur l'index des colonnes, nous devons passer le paramètre axis=1.
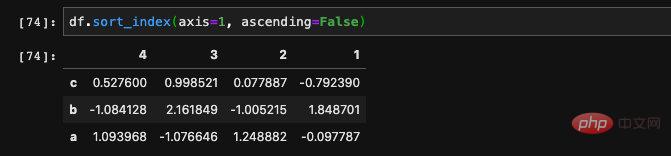
Nous pouvons également passer le paramètre ascendant pour préciser si l'ordre de tri que nous souhaitons est ordre direct ou ordre inverse.
Le tri des valeurs de DataFrame est différent, nous Les lignes ne peuvent pas être triées, ne peuvent être triées que sur les colonnes . Nous passons la colonne sur laquelle nous voulons trier via le paramètre by, qui peut être une ou plusieurs colonnes.

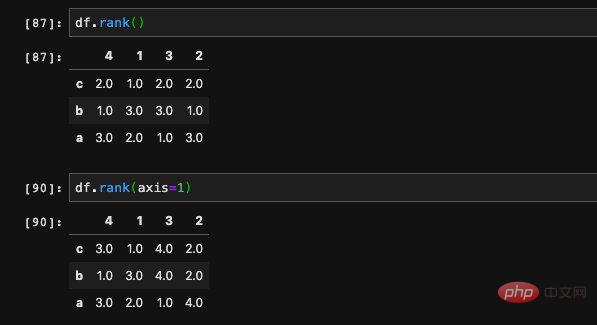
Parfois, nous voulons l'élément Classement , nous aimerions savoir où se classe l'élément actuel parmi l'ensemble. Cette fonction est également fournie dans pandas, qui est la méthode de classement.

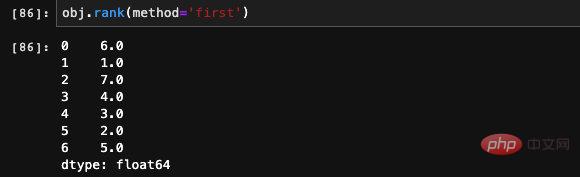
Nous pouvons constater que la chaîne de nombres que nous saisissons par hasard contient deux 7. 7 est le plus grand nombre de la série, mais pourquoi leur classement est-il 6,5 ?
En fait, c'est très simple, car 7 apparaît deux fois, en 6ème et 7ème positions. Ici, le classement de toutes ses occurrences est moyenné, il est donc de 6,5. Si on ne veut pas qu'il soit moyenné, mais que donne un classement selon l'ordre d'apparition, on peut utiliser le paramètre méthode pour préciser l'effet souhaité.
Les paramètres juridiques de la méthode ne se limitent pas au premier, il existe également d'autres utilisations légèrement moins populaires, que nous énumérerons ensemble.

S'il s'agit d'un DataFrame, la valeur par défaut est de calculer le classement global des éléments de chaque ligne en unités de ligne. Nous pouvons également spécifier les calculs en unités de colonne via le paramètre axis :
Enfin, introduisons l'opération récapitulative dans DataFrame. L'opération récapitulative est également l'opération d'agrégation, telle que notre méthode de somme la plus courante, pour. les données d'un lot sont agrégées et additionnées. Il existe des méthodes similaires dans DataFrame, examinons-les une par une.
Le premier est sum. Nous pouvons utiliser sum pour additionner le DataFrame. Si aucun paramètre n'est transmis, la valeur par défaut est de additionner chaque ligne.

En plus de la somme, une autre couramment utilisée est la moyenne, qui peut faire la moyenne d'une ligne ou d'une colonne.

Comme il y a souvent des éléments NA dans le DataFrame, nous pouvons utiliser le paramètre skipna pour exclure les valeurs manquantes puis calculer la moyenne.
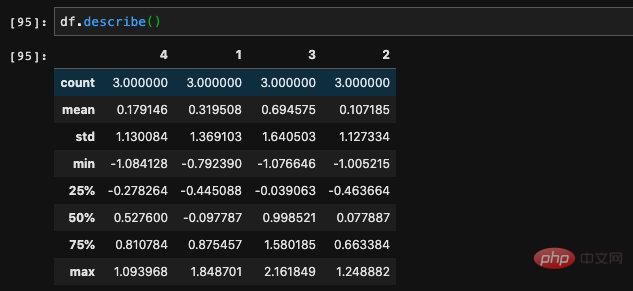
Une autre méthode que je trouve personnellement très utile est descirbe, qui peut renvoyer les informations globales dans le DataFrame. Par exemple, la moyenne, la taille de l'échantillon, l'écart type, la valeur minimale, la valeur maximale, etc. de chaque colonne. Il s'agit d'une méthode statistique couramment utilisée qui peut être utilisée pour comprendre la distribution des données dans DataFrame.
En plus des méthodes présentées, il existe de nombreuses méthodes d'opérations récapitulatives similaires dans DataFrame, telles que idxmax, idxmin, var, std, etc. Si vous êtes intéressé, vous pouvez consulter le documents pertinents, mais d'après mon expérience, il n'est généralement pas utilisé.
Si vous souhaitez en savoir plus sur la programmation, faites attention à la rubrique Formation php !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



