


Recommandations d'apprentissage associées : Tutoriel Python
Python est open source, c'est génial, mais l'open source ne peut pas l'être évité. Quelques problèmes inhérents : De nombreux packages font (ou tentent de faire) la même chose. Si vous êtes nouveau sur Python, il est difficile de savoir quel package est le meilleur pour une tâche spécifique. Vous avez besoin de quelqu'un d'expérimenté pour vous le dire. Il existe un package pour la science des données qui est absolument indispensable, et ce sont les pandas.
La chose la plus intéressante à propos des pandas est qu'il y a de nombreux paquets cachés à l'intérieur. Il s'agit d'un package de base avec de nombreuses fonctionnalités d'autres packages. C'est génial car vous pouvez simplement utiliser des pandas et faire le travail.
Pandas est équivalent à Excel en Python : il utilise des tables (c'est-à-dire des dataframes) et peut effectuer diverses transformations sur les données, mais il a également de nombreuses autres fonctions.
Si vous êtes déjà familier avec l'utilisation de python, vous pouvez passer directement au troisième paragraphe.
Commençons :
import pandas as pd复制代码
Ne demandez pas pourquoi "pd" au lieu de "p", c'est tout. Utilisez-le simplement :)
Lire les données
data = pd.read_csv( my_file.csv ) data = pd.read_csv( my_file.csv , sep= ; , encoding= latin-1 , nrows=1000, skiprows=[2,5])复制代码
sep représente le séparateur. Si vous utilisez des données françaises, le délimiteur csv dans Excel est ";", vous devez donc le spécifier explicitement. L'encodage est défini sur latin-1 pour lire les caractères français. nrows=1000 signifie lire les 1000 premières lignes de données. skiprows=[2,5] signifie que vous supprimerez les lignes 2 et 5 lors de la lecture du fichier.
Fonctions les plus couramment utilisées : read_csv, read_excel
Quelques autres fonctions intéressantes : read_clipboard, read_sql
Écrire les données
data.to_csv( my_new_file.csv , index=None)复制代码
index=Aucun signifie que les données seront écrites telles quelles. Si vous n'écrivez pas index=None, vous aurez une première colonne supplémentaire avec le contenu 1, 2, 3,..., jusqu'à la dernière ligne.
Je n'utilise généralement pas d'autres fonctions, comme .to_excel, .to_json, .to_pickle, etc., car .to_csv peut bien faire le travail et csv est le moyen le plus couramment utilisé pour enregistrer des tables.
Vérifiez les données

Gives (#rows, #columns)复制代码
Donnez le nombre de lignes et de colonnes
data.describe()复制代码
Calculer les statistiques de base
Afficher les données
data.head(3)复制代码
Imprimez les 3 premières lignes de données. De même, .tail() correspond à la dernière ligne de données.
data.loc[8]复制代码
Imprimer la huitième ligne
data.loc[8, column_1 ]复制代码
Imprimer la huitième ligne de la colonne nommée "column_1"
data.loc[range(4,6)]复制代码
La quatrième à la sixième lignes (gauche fermée, droite ouverte) Sous-ensemble de données
Opérations logiques
data[data[ column_1 ]== french ] data[(data[ column_1 ]== french ) & (data[ year_born ]==1990)] data[(data[ column_1 ]== french ) & (data[ year_born ]==1990) & ~(data[ city ]== London )]复制代码
Récupérer des sous-ensembles de données via des opérations logiques. Pour utiliser & (AND), ~ (NOT) et | (OR), vous devez ajouter « et » avant et après l'opération logique.
data[data[ column_1 ].isin([ french , english ])]复制代码
En plus d'utiliser plusieurs OR sur la même colonne, vous pouvez également utiliser la fonction .isin().
Traçage de base
Le package matplotlib rend cela possible. Comme nous le disions en introduction, il peut être utilisé directement chez les pandas.
data[ column_numerical ].plot()复制代码
().plot() Exemple de sortie
data[ column_numerical ].hist()复制代码
Tracer la distribution des données (histogramme)
.hist() Exemple de sortie
%matplotlib inline复制代码
Si vous utilisez Jupyter, n'oubliez pas d'ajouter le code ci-dessus avant de dessiner.
Mettre à jour les données
data.loc[8, column_1 ] = english 将第八行名为 column_1 的列替换为「english」复制代码
Modifier les valeurs de plusieurs colonnes sur une seule ligne de code
Eh bien, maintenant vous pouvez faire quelque chose qui est facilement accessible dans Excel chose. Examinons quelques choses étonnantes que vous ne pouvez pas faire dans Excel.
Compter le nombre d'occurrences
data.loc[data[ column_1 ]== french , column_1 ] = French复制代码
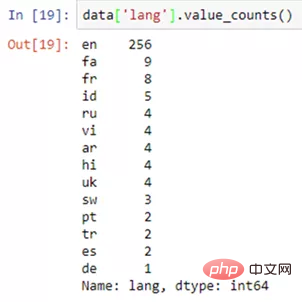
Exemple de sortie de fonction .value_counts()
Opération sur toutes les lignes, colonnes ou sur l'ensemble des données
data[ column_1 ].value_counts()复制代码
la fonction len() est appliquée à chaque élément de la colonne "column_1"
.map () applique une fonction à chaque élément d'une colonne
data[ column_1 ].map(len)复制代码
Une fonctionnalité intéressante des pandas est la méthode de chaîne (tomaugspurger.github.io/method-chai… et .plot()).
data[ column_1 ].map(len).map(lambda x: x/100).plot()复制代码
.apply() appliquera une fonction à une colonne.
.applymap() appliquera une fonction à toutes les cellules du tableau (DataFrame).
tqdm, le seul
在处理大规模数据集时,pandas 会花费一些时间来进行.map()、.apply()、.applymap() 等操作。tqdm 是一个可以用来帮助预测这些操作的执行何时完成的包(是的,我说谎了,我之前说我们只会使用到 pandas)。
from tqdm import tqdm_notebook tqdm_notebook().pandas()复制代码
用 pandas 设置 tqdm
data[ column_1 ].progress_map(lambda x: x.count( e ))复制代码
用 .progress_map() 代替.map()、.apply() 和.applymap() 也是类似的。

在 Jupyter 中使用 tqdm 和 pandas 得到的进度条
相关性和散射矩阵
data.corr() data.corr().applymap(lambda x: int(x*100)/100)复制代码
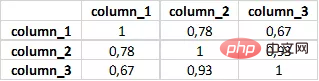
.corr() 会给出相关性矩阵
pd.plotting.scatter_matrix(data, figsize=(12,8))复制代码
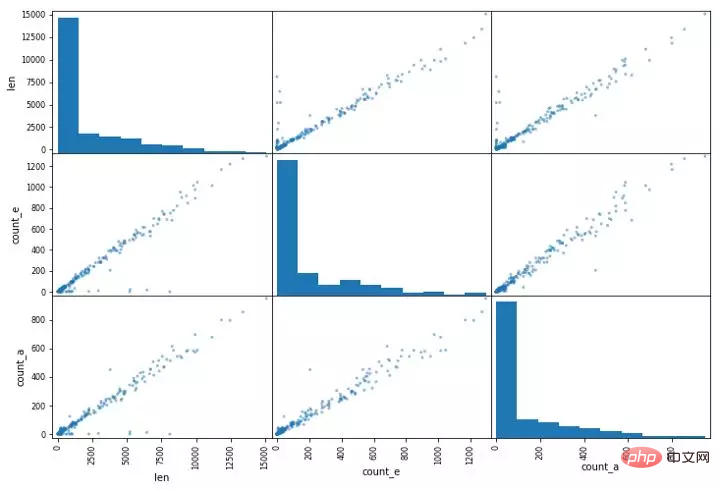
散点矩阵的例子。它在同一幅图中画出了两列的所有组合。
The SQL 关联
在 pandas 中实现关联是非常非常简单的
data.merge(other_data, on=[ column_1 , column_2 , column_3 ])复制代码
关联三列只需要一行代码
分组
一开始并不是那么简单,你首先需要掌握语法,然后你会发现你一直在使用这个功能。
data.groupby( column_1 )[ column_2 ].apply(sum).reset_index()复制代码
按一个列分组,选择另一个列来执行一个函数。.reset_index() 会将数据重构成一个表。
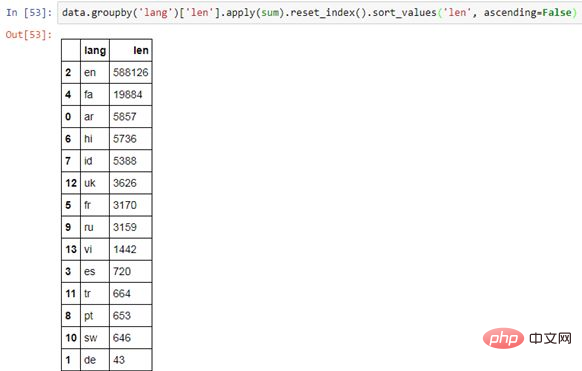
正如前面解释过的,为了优化代码,在一行中将你的函数连接起来。
行迭代
dictionary = {}
for i,row in data.iterrows():
dictionary[row[ column_1 ]] = row[ column_2 ]复制代码.iterrows() 使用两个变量一起循环:行索引和行的数据 (上面的 i 和 row)
总而言之,pandas 是 python 成为出色的编程语言的原因之一
我本可以展示更多有趣的 pandas 功能,但是已经写出来的这些足以让人理解为何数据科学家离不开 pandas。总结一下,pandas 有以下优点:
易用,将所有复杂、抽象的计算都隐藏在背后了;
直观;
快速,即使不是最快的也是非常快的。
它有助于数据科学家快速读取和理解数据,提高其工作效率
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!


















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



