


Je pense que tout le monde parlera d'index lors de l'optimisation des bases de données, et je ne fais pas exception. Tout le monde peut essentiellement répondre à une question sur l'optimisation des structures de données. ou trois, et la mise en cache des pages, etc., je peux en parler quelques mots, mais un jour, un intervieweur d'Alibaba P9 m'a demandé : pouvez-vous parler du processus de chargement des données d'index à partir du niveau de l'ordinateur ? (Je voulais juste que je parle d'IO)
Je suis mort sur le coup.... Parce que les connaissances de base des réseaux informatiques et des systèmes d'exploitation sont vraiment mon point aveugle, mais je me suis rattrapé plus tard, alors j'ai Je ne dirai pas de bêtises, commençons par le chargement des données par l'ordinateur et parlons de l'indexation sous un autre angle.
L'index MySQL est essentiellement une structure de données
Comprenons d'abord le chargement des données de l'ordinateur.

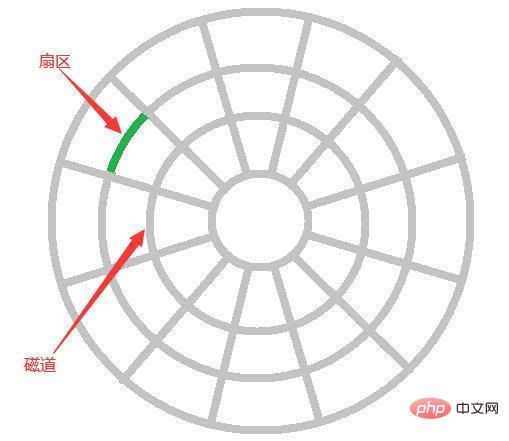
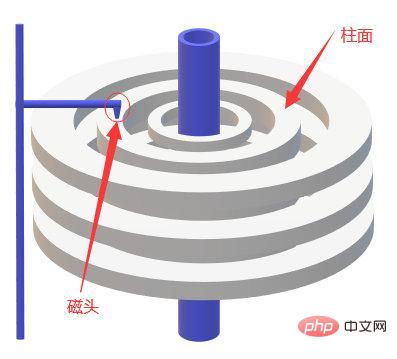
Parlons d'abord de l'E/S disque. Le disque lit les données par lecture de mouvement mécanique. les données à la fois nécessitent trois étapes de recherche, recherche d'un point et copie dans la mémoire . Le
Le temps de recherche est le temps nécessaire au bras magnétique pour se déplacer vers la piste spécifiée, généralement inférieur à 5 ms. Le
Le point de recherche est à partir de ; la piste Le temps moyen pour trouver le point où les données existent est d'un demi-tour. S'il s'agit d'un disque à 7200 tr/min, le temps moyen pour trouver le point est de 600000/7200/2=4,17 ms ; 🎜>Copier en mémoire Le temps de
est très rapide, ce qui est négligeable par rapport aux deux fois précédentes, donc le temps moyen d'unIO est d'environ 9 ms . Cela semble rapide, mais il faut 9 000 secondes pour parcourir des millions de données dans la base de données, ce qui est évidemment un niveau désastreux.
 de
de Nous appelons les données lues par IO à chaque fois une page. La taille spécifique des données sur une page dépend du système d'exploitation, généralement 4k ou 8k, c'est-à-dire que nous lisons les données sur une seule page. fois, une seule IO s’est réellement produite.
(J'ai soudain pensé à une question qu'on m'avait posée juste après l'obtention de mon diplôme. Dans un système d'exploitation 64 bits, combien d'octets le type int en Java occupe-t-il ? Quel est le maximum ? Pourquoi ?)Ensuite, si nous voulons optimiser les requêtes de base de données, nous devons
minimiser les opérations d'E/S disque
, pour que les index apparaissent.Qu'est-ce qu'un indice ?
MySQLMySQL sont physiquement divisés en deux catégories, les index B-tree et les index de hachage.
Cette fois-ci, nous parlons principalement de MySQL indice.
L'index BTree BTree
BTreeChacun. Le nœud de l’arborescence contient au plus m enfants.
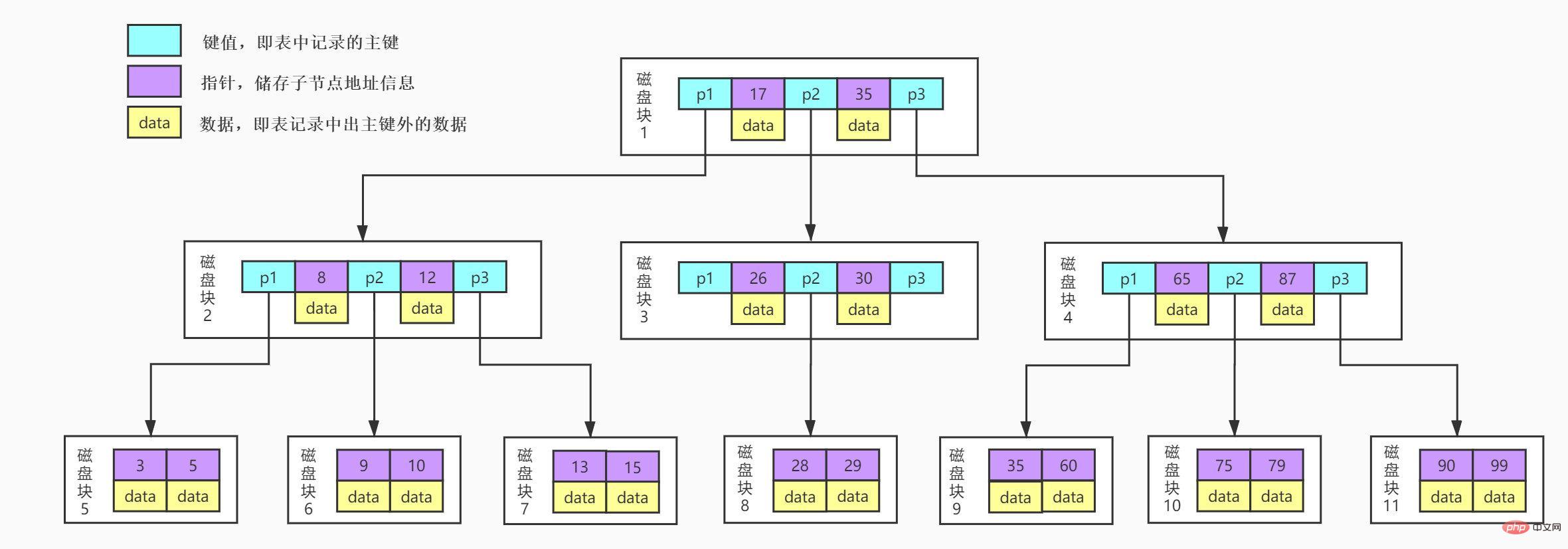
1 fois
]2. Le bloc de disque 1 stocke 17, 35 et trois données de pointeur. On trouve 17<29<35, on trouve donc le pointeur p2.
3. D'après le pointeur p2, nous localisons et lisons le bloc disque 3. [Opérations d'E/S sur disque2 fois
]4. Le bloc de disque 3 stocke 26, 30 et trois données de pointeur. On trouve 26<29<30, on trouve donc le pointeur p2.
5. D'après le pointeur p2, nous localisons et lisons le bloc disque 8. [Opérations d'E/S disque 3 fois ]
6. Stockage de 28 et 29 dans le bloc disque 8. Nous trouvons 29 et obtenons les données correspondant à 29.
On peut voir que l'index BTree fait jouer un rôle aux données extraites de la mémoire dans chaque E/S du disque, améliorant ainsi l'efficacité des requêtes.
Mais y a-t-il quelque chose qui puisse être optimisé ?
Nous pouvons voir sur l'image que chaque nœud contient non seulement la valeur clé des données, mais également la valeur des données. L'espace de stockage de chaque page est limité. Si les données sont volumineuses, le nombre de clés pouvant être stockées dans chaque nœud (c'est-à-dire une page) sera très faible. Lorsque la quantité de données stockées est importante, cela entraînera également. à B- La profondeur de l'arborescence est plus grande, ce qui augmente le nombre d'E/S disque pendant la requête, affectant ainsi l'efficacité de la requête.
B+Tree est une optimisation basée sur B-Tree, ce qui le rend plus adapté à la mise en œuvre d'une structure d'index de stockage externe. Dans B+Tree, tous les nœuds d'enregistrement de données sont stockés sur les nœuds feuilles dans la même couche par ordre de valeur clé. Seules les informations sur les valeurs clés sont stockées sur les nœuds non feuilles. Cela peut augmenter considérablement le nombre de valeurs clés stockées dans chacun. node. , réduisez la hauteur de B+Tree.
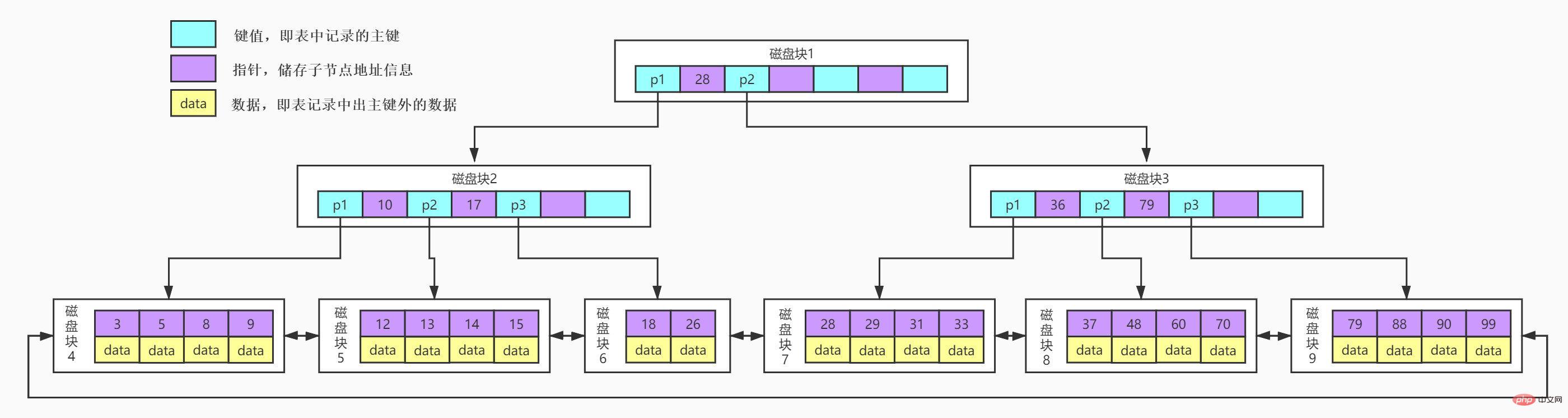
B+Tree présente plusieurs différences par rapport à B-Tree :
Les nœuds non-feuilles stockent uniquement des informations sur les valeurs clés, des données Les enregistrements sont stockés dans les nœuds feuilles. Optimisez le B-Tree dans la section précédente Étant donné que les nœuds non-feuilles de B+Tree stockent uniquement les informations sur les valeurs clés, la hauteur de B+Tree peut être compressée à un niveau particulièrement bas.
Les données spécifiques sont les suivantes :
La taille de la page dans le moteur de stockage InnoDB est de 16 Ko. Le type de clé primaire de la table générale est INT (occupe 4 octets) ou BIGINT. (occupe 8 octets), le type de pointeur est généralement de 4 ou 8 octets, ce qui signifie qu'une page (un nœud dans B+Tree) stocke environ 16 Ko/(8B+8B)=1K valeurs de clé (car elle est une estimation, pour faciliter le calcul, la valeur de K est ici 〖10〗^3).
C'est-à-dire qu'un index B+Tree d'une profondeur de 3 peut maintenir 10^3 10^3 10^3 = 1 milliard d'enregistrements. (Il y a des erreurs dans cette méthode de calcul et les nœuds feuilles ne sont pas calculés. Si les nœuds feuilles sont calculés, la profondeur est en fait de 4)
Nous n'avons besoin d'effectuer que trois opérations d'E/S pour extraire les données à partir d'un milliard de données. Pour trouver les données que nous voulons, nous ne savons pas combien de Wallaces il vaut mieux que le million initial de données de 9 000 secondes.
Et il y a généralement deux pointeurs de tête sur B+Tree, l'un pointe vers le nœud racine et l'autre pointe vers le nœud feuille avec le plus petit mot-clé, et il y a un anneau de chaîne entre tous les nœuds feuilles (c'est-à-dire les données nœuds). Par conséquent, en plus d'effectuer une recherche par plage de clés primaires et une recherche de pagination sur B+Tree, nous pouvons également effectuer des recherches aléatoires à partir du nœud racine.
L'index B+Tree dans la base de données peut être divisé en index clusterisé et index secondaire.
L'implémentation de l'exemple de diagramme B+Tree ci-dessus dans la base de données est un index clusterisé. Les nœuds feuilles dans le B+Tree de l'index cluster stockent les données d'enregistrement de ligne de la table entière. l'index clusterisé La différence est que les nœuds feuilles de l'index auxiliaire ne contiennent pas toutes les données de l'enregistrement de ligne, mais la clé d'index clusterisé qui stocke les données de ligne correspondantes, c'est-à-dire la clé primaire.
Lors de l'interrogation de données via l'index auxiliaire, le moteur de stockage InnoDB parcourra l'index auxiliaire pour trouver la clé primaire, puis trouvera les données complètes de l'enregistrement de ligne dans l'index clusterisé via la clé primaire.
Cependant, bien que les index puissent accélérer les requêtes et améliorer les performances de traitement de MySQL, une utilisation excessive des index peut également entraîner les inconvénients suivants :
Remarque : Les index peuvent accélérer les requêtes dans certains cas, mais dans certains cas, ils réduiront l'efficacité.
L'indexation n'est qu'un facteur parmi d'autres pour améliorer l'efficacité, les principes suivants doivent donc être suivis lors de la création d'un index :
Maintenant, tout le monde sait pourquoi l'index peut être si rapide. En fait, il ne s'agit que d'une seule phrase. La structure de l'index peut minimiser le nombre d'E/S dans la base de données. IO est vraiment trop long. . .
En ce qui concerne les entretiens, nous pouvons en fait maîtriser facilement beaucoup de connaissances, mais dans le but d'apprendre, vous constaterez qu'il y a beaucoup de choses que nous devons faire En approfondissant les bases des ordinateurs pour les découvrir, beaucoup de gens me demandent comment je me souviens de tant de choses. En fait, l'apprentissage en soi est une chose très impuissante. Puisque nous devons apprendre, pourquoi ne pas l'apprendre durement ? Pour apprendre à en profiter ? Récemment, j'ai également étudié les bases et je commencerai plus tard à mettre à jour mes bases informatiques et mes connaissances liées aux réseaux.
Je suis Ao Bing. Plus vous en savez, plus vous n'en savez pas. À la prochaine fois ! Les
【三连】de Talents sont la plus grande motivation pour la création d'Ao Bing. S'il y a des erreurs ou des suggestions dans ce blog, les talents sont invités à partir. un message !
Plus de recommandations d'apprentissage gratuites connexes : tutoriel MySQL(vidéo)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Index MySQL
Index MySQL
 ASUS f83se
ASUS f83se
 Comment résoudre l'erreur 500 du serveur interne
Comment résoudre l'erreur 500 du serveur interne
 Supprimer les fichiers Internet temporaires
Supprimer les fichiers Internet temporaires
 méthode d'ouverture du fichier pkg
méthode d'ouverture du fichier pkg
 Comment résoudre le problème des caractères tronqués lors de l'ouverture d'une page Web
Comment résoudre le problème des caractères tronqués lors de l'ouverture d'une page Web
 Comment lire une vidéo avec python
Comment lire une vidéo avec python
 Comment désactiver l'invite de mise à niveau Win10
Comment désactiver l'invite de mise à niveau Win10








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



