
 développement back-end
tutoriel php
Partagez des idées pour implémenter la fonction de vente flash PHP
développement back-end
tutoriel php
Partagez des idées pour implémenter la fonction de vente flash PHP
Partagez des idées pour implémenter la fonction de vente flash PHP


Recommandé : "Tutoriel vidéo PHP"
1. Pourquoi le commerce de vente flash est-il si difficile ?
1) Système de messagerie instantanée, tel que QQ ou Weibo, Chacun lit ses propres données (liste d'amis, Liste de groupe, informations personnelles);
2) Système Weibo, tout le monde peut lire les données des personnes que vous suivez, Une personne peut lire les données de plusieurs personnes
3) Dans le système de vente flash, il n'y a qu'une seule copie de l'inventaire, et tout le monde lira et écrira les données à un moment concentréPlusieurs personnes liront une donnée.
Par exemple : les téléphones mobiles Xiaomi organisent une vente flash tous les mardis. Il n'y a peut-être que 10 000 téléphones mobiles, mais le trafic instantané peut atteindre des centaines ou des dizaines de millions. Autre exemple : 12306 tickets à récupérer, les tickets sont limités, il y a un seul inventaire, il y a beaucoup de trafic instantané, et ils lisent tous le même inventaire.Conflits de lecture et d'écriture, les verrous sont très graves, c'est là que le business de la vente instantanée est difficile. Alors, comment optimiser la structure de l’activité de vente flash ?
2. Directions d'optimisation
Il existe deux directions d'optimisation (nous parlerons de ces deux points aujourd'hui) : (1)Essayez d'intercepter les requêtes en amont du système (ne laissez pas les conflits de verrouillage tomber dans la base de données). La raison pour laquelle le système de vente flash traditionnel échoue est que les demandes submergent la couche de données back-end, les conflits de verrouillage en lecture-écriture des données sont graves, la concurrence est élevée et les réponses sont lentes et presque toutes les demandes expirent. Bien que le trafic soit important, le trafic effectif pour les commandes réussies est très faible. Prenons l'exemple de 12306. Il n'y a en réalité que 2 000 billets pour un train. Si 2 millions de personnes viennent l'acheter, presque personne ne peut l'acheter avec succès et le taux d'efficacité de la demande est de 0.
(2)Utilisez pleinement le cache et achetez des billets en un éclair Il s'agit d'un scénario d'application typique de lecture de plus en moins. La plupart des demandes sont des requêtes de numéro de train, des billets. requête, commande et paiement. C'est une demande d'écriture. Il n'y a en réalité que 2 000 billets pour un train, et 2 millions de personnes viennent l'acheter. Au maximum 2 000 personnes passent des commandes avec succès, et tout le monde interroge l'inventaire. Le taux d'écriture n'est que de 0,1 % et le taux de lecture est de 99,9 %. Il est très approprié pour l’optimisation de la mise en cache. Bon, parlons de la méthode « d’interception des requêtes le plus en amont possible dans le système » et de la méthode de « mise en cache » plus tard.
3. Architecture commune des ventes flash
L'architecture commune du site est fondamentalement comme ceci (ne dessinez absolument pas de schémas d'architecture trompeurs) 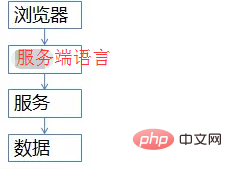 (1) Le côté navigateur, la couche supérieure, exécutera du code JS
(1) Le côté navigateur, la couche supérieure, exécutera du code JS
(3) Couche de service (serveur Web), protège les détails des données sous-jacentes de l'amont et fournit un accès aux données (4) Couche de données, l'inventaire final est stocké ici, MySQL est un typique une (bien sûr, il y en aura. Il y aura une mise en cache) Bien que cette image soit simple, elle peut illustrer de manière vivante l'architecture commerciale des ventes flash à fort trafic et à haute concurrence. Tout le monde devrait se souvenir de cette image. Ce qui suit expliquera en détail comment optimiser chaque niveau.
4. Détails de l'optimisation à chaque niveau
Le premier niveau, comment optimiser le client (couche navigateur, couche APP) Vous demander un Question , tout le monde a joué au shake de WeChat pour récupérer des enveloppes rouges, n'est-ce pasÀ chaque fois que vous secouez, une demande sera-t-elle envoyée au backend ? En repensant à la scène où nous avons passé une commande pour récupérer des billets, après avoir cliqué sur le bouton « Requête », le système est resté bloqué et la barre de progression a augmenté lentement en tant qu'utilisateur, je cliquais inconsciemment à nouveau sur « Requête », n'est-ce pas ? Continuez à cliquer, continuez à cliquer, cliquez, cliquez. . . Est-ce utile ? La charge du système est augmentée sans raison. Un utilisateur clique 5 fois, et 80% des requêtes sont générées. Comment y remédier ?
(a) Au niveau du produit, après que l'utilisateur a cliqué sur « Requête » ou « Acheter des billets », le boutonest grisé , interdisant à l'utilisateur de soumettre des demandes à plusieurs reprises ;
(b) JS Au niveau dex secondes, les utilisateurs ne peuvent soumettre qu'une seule demande au niveau
APP, des choses similaires peuvent être faites même si vous secouez WeChat comme. fou, cela prend en fait x secondes pour revenir en arrière. Le client lance une requête. C'est ce qu'on appelle « l'interception des requêtes le plus en amont possible dans le système ». Plus on est en amont, mieux c'est, la couche navigateur et la couche APP sont bloquées, de sorte que plus de 80 % des requêtes peuvent être bloquées. utilisateurs ordinaires (mais 99% % des utilisateurs sont des utilisateurs ordinaires) Il n'y a aucun moyen d'arrêter lesprogrammeurs haut de gamme du groupe. Dès que Firebug capture le paquet, tout le monde sait à quoi ressemble http. JS ne peut pas empêcher les programmeurs d'écrire des boucles for et d'appeler des interfaces http. Comment gérer cette partie de la requête ?
La deuxième couche, demande d'interception au niveau du serveurComment intercepter ? Comment empêcher les programmeurs d'écrire des appels en boucle Existe-t-il une base pour la déduplication ? IP ? identifiant de cookie ? ...C'est compliqué. Ce genre d'entreprise nécessite une connexion, utilisez simplement l'uid. Au niveau côté serveur, effectue le comptage des requêtes et la déduplication sur l'uid, et n'a même pas besoin de stocker le décompte de manière uniforme et de le stocker directement dans la mémoire côté serveur (ce décompte sera inexact, mais c'est le plus simple). Un uid ne peut transmettre qu'une seule requête en 5 secondes, ce qui peut bloquer 99 % des requêtes de boucle.
Une seule requête est passée en 5 secondes, qu'en est-il des autres requêtes ? Cache, Page Cache, le même uid, limiter la fréquence d'accès, faire la mise en cache des pages, toutes les requêtes arrivant au serveur dans les x secondes renverront la même page. Pour les requêtes sur le même élément, tel que les numéros de train, la mise en cache des pages est effectuée et les requêtes arrivant au serveur dans un délai de x secondes renverront toutes la même page. Une telle limite actuelle peut non seulement garantir aux utilisateurs une bonne expérience utilisateur (aucun 404 n'est renvoyé) mais également assurer la robustesse du système (en utilisant la mise en cache des pages pour intercepter les requêtes sur le serveur ) .
La mise en cache des pages ne garantit pas nécessairement que tous les serveurs renvoient des pages cohérentes. Elle peut également être placée directement dans la mémoire de chaque site. L'avantage est que c'est simple, mais l'inconvénient est que la requête http tombe sur différents serveurs, et les données du ticket renvoyées peuvent être différentes. Il s'agit de l'interception de la requête et de l'optimisation du cache du serveur. .
D'accord, cette méthode empêche les programmeurs qui écrivent des boucles for d'envoyer des requêtes http. Certains programmeurs haut de gamme (hackers) contrôlent 100 000 poulets de chair, ont 100 000 uids en main et envoient des requêtes en même temps (sans y penser). le système de nom réel pour l'instant) Le problème est que Xiaomi n'a pas besoin de système de nom réel pour récupérer les téléphones portables), que dois-je faire maintenant Le serveur ne peut pas l'arrêter selon la limite actuelle de l'uid ?
La troisième couche est la couche service à intercepter (de toute façon, ne laissez pas la requête tomber sur la base de données)
Comment intercepter la couche service ? Frère, je suis au niveau du service. Je sais clairement que Xiaomi n'a que 10 000 téléphones portables. Je sais qu'il n'y a que 2 000 billets pour un train. A quoi ça sert de faire 100 000 requêtes à la base de données ? C'est vrai, file d'attente des demandes !
Pour les demandes d'écriture, créez une file d'attente de demandes et ne transmettez à chaque fois qu'un nombre limité de demandes d'écriture à la couche de données (passez une commande, payez pour une telle activité d'écriture)
1w téléphones mobiles, seules les demandes de commande 1w vont à db
pour 3k billets de train, et seulement 3k demandes de commande vont à db
Si toutes réussissent, un autre lot sera placé. Si l'inventaire n'est pas suffisant, écrivez les demandes dans la file d'attente. Toutes renvoient « Épuisé ».
Comment optimiser les demandes de lecture ? La résistance du cache, qu'il soit Memcached ou Redis, ne devrait poser aucun problème si une seule machine peut résister 100 000 fois par seconde. Avec une telle limitation actuelle, seules très peu de requêtes d’écriture et très peu de requêtes erronées de lecture du cache pénétreront dans la couche de données, et 99,9 % des requêtes sont bloquées.
Bien sûr, il y a aussi quelques optimisations dans les règles métier. Rappelez-vous ce que faisait 12306, Vente de billets par heure et section Avant, ils vendaient des billets à 10 heures, mais maintenant ils vendent des billets à 8 heures, 8h30, 9 heures. .. et libèrent un lot toutes les demi-heures : le trafic se répartit uniformément.
Deuxièmement, Optimisation de la granularité des données : Lorsque vous allez acheter des billets, pour l'activité de requête de billets restante, il reste 58 billets, soit 26. Vous en souciez-vous vraiment ? nous seulement Êtes-vous préoccupé par le fait de voter ou de ne pas voter ? Lorsque le trafic est intense, créez simplement un cache à gros grains « avec ticket » et « sans ticket ».
Troisièmement, le caractère asynchrone de certaines logiques métier : comme la séparation des activités de commande et des activités de paiement. Ces optimisations sont toutes associées au business. J'ai déjà partagé un point selon lequel "toutes les conceptions architecturales qui sont séparées du business sont des voyous". L'optimisation de l'architecture doit également être ciblée sur le business.
D'accord, enfin la couche de base de données
le navigateur a intercepté 80%, le serveur a intercepté 99,9% et a mis la page en cache, et la couche de service a refait l'écriture avec le file d'attente de requêtes et cache de données, chaque requête adressée à la couche de base de données est contrôlable. Il n'y a fondamentalement aucune pression sur la base de données. Vous pouvez vous promener tranquillement et le gérer sur une seule machine. Encore une fois, l'inventaire est limité et la capacité de production de Xiaomi est limitée. Il ne sert à rien de faire autant de demandes à la base de données.
Toutes sont transmises à la base de données, 1 million de commandes sont passées, 0 sont réussies et l'efficacité des demandes est de 0%. 3 000 données ont été obtenues, toutes ont réussi et l'efficacité de la demande était de 100 %.
5. Résumé
La description ci-dessus doit être très claire, il n'y a pas de résumé Pour le système de vente flash, je vais répéter les deux idées d'optimisation d'architecture de mon. expérience personnelle :
(1) Essayez d'intercepter les requêtes en amont du système (plus en amont, mieux c'est
(2) Couramment utilisé pour) ; lire plus et écrire moins. Cache (le cache résiste à la pression de lecture)
Navigateurs et applications : limite de vitesse
Serveur : limite de vitesse basée sur l'uid et la page. mise en cache
Couche de service (serveur web) : Faire des files d'attente de requêtes d'écriture pour contrôler le trafic en fonction des affaires, et faire de la mise en cache des données
Couche de données : Flâner dans la cour
Et : Optimiser en fonction de l'activité
6. Questions et réponses
Question 1. Selon votre architecture, en fait, le plus stressant est le serveur En supposant que le nombre de requêtes réelles et effectives est de 10 millions, il est peu probable qu'il limite le nombre de requêtes. connexions, donc cette partie de la pression Comment y faire face ?
Réponse : La simultanéité par seconde peut ne pas être de 1 kW. En supposant qu'il y ait 1 kW, il existe 2 solutions :
(1) La couche de service (serveur Web) peut être étendue en ajoutant des machines. Il ne suffit pas d’avoir 1 000 machines.
(2) S'il n'y a pas assez de machines, abandonnez la demande et abandonnez 50% (50% seront restitués directement et réessayerez plus tard. Le principe est de protéger le système et de ne pas permettre à tous les utilisateurs d'échouer). .
Question 2. "Contrôler 100 000 poulets de chair, avoir 100 000 uides en main et envoyer des demandes en même temps." Comment résoudre ce problème ?
Réponse : Comme mentionné ci-dessus, le contrôle de la file d'attente des demandes d'écriture de la couche de service (serveur Web)
Question 3 : Le cache qui limite la fréquence d'accès peut-il également être utilisé pour la recherche ? Par exemple, si l'utilisateur A recherche « téléphone mobile » et que l'utilisateur B recherche « téléphone mobile », la page mise en cache générée par la recherche de A sera-t-elle utilisée en premier ?
Réponse : Ceci est possible. Cette méthode est également souvent utilisée dans les pages d'activité d'opération "dynamiques", telles que la diffusion d'activités d'opération push d'application utilisateur de 4 kW sur une courte période de temps et la mise en cache des pages.
Question 4 : Que faire si le traitement de la file d'attente échoue ? Que dois-je faire si les poulets de chair dépassent la file d'attente ?
Réponse : Si le traitement échoue, la commande échouera et l'utilisateur sera invité à réessayer. Le coût de la file d’attente est très faible, il serait donc difficile d’exploser. Dans le pire des cas, après la mise en cache de plusieurs requêtes, les requêtes suivantes renverront directement "aucun ticket" (il y a déjà 1 million de requêtes dans la file d'attente, et elles sont toutes en attente, il ne sert donc à rien d'accepter d'autres requêtes)
Question 5 :Si le serveur filtre, enregistre-t-il le nombre de requêtes uid séparément dans la mémoire de chaque site ? Si tel est le cas, comment gérer la situation dans laquelle plusieurs clusters de serveurs distribuent les réponses du même utilisateur à différents serveurs via l'équilibreur de charge ? Ou devrions-nous mettre en place un filtrage côté serveur avant l'équilibrage de charge ?
Réponse : Il peut être placé en mémoire. Dans ce cas, il semble qu'un serveur soit limité à une requête sur 5s. Globalement (en supposant qu'il y ait 10 machines), il est en réalité limité à 10 requêtes par seconde. 5s. Solution :
1) Augmenter la limite (c'est la solution recommandée, la plus simple)
2) Faire un équilibrage à 7 couches sur la couche nginx, pour que les demandes d'uid chutent sur la même machine autant que possible
Question 6 : Si la couche service (serveur web) filtre, la file d'attente est une file d'attente unifiée de la couche service (serveur web) ? Ou existe-t-il une file d'attente pour chaque serveur qui fournit des services ? S'il s'agit d'une file d'attente unifiée, est-il nécessaire d'effectuer un contrôle de verrouillage avant que les requêtes soumises par chaque serveur ne soient mises dans la file d'attente ?
Réponse : Vous n'avez pas besoin d'unifier une file d'attente. Dans ce cas, chaque service peut transmettre un plus petit nombre de demandes (nombre total de tickets/nombre de services). Unifier une file d’attente est encore une fois compliqué.
Question 7 : Une fois le paiement effectué après la vente flash et l'espace réservé annulé sans paiement, comment contrôler et mettre à jour l'inventaire restant en temps opportun ?
Réponse : Il y a un statut dans la base de données, impayé. Si le temps dépasse, par exemple, 45 minutes, l'inventaire sera à nouveau restauré (appelé "retour à l'entrepôt"). L'inspiration pour nous de récupérer les billets est qu'après avoir lancé la vente flash, réessayez après 45 minutes, peut-être. il y aura à nouveau des tickets~
Question 8 : Différents utilisateurs parcourent le même produit et l'inventaire affiché dans différentes instances de cache est complètement différent. Pourriez-vous s'il vous plaît me dire comment rendre les données du cache cohérentes ou autoriser des lectures sales ?
Réponse : Avec la conception actuelle de l'architecture, les requêtes tombent sur différents sites et les données peuvent être incohérentes (le cache des pages est différent). Ce scénario commercial est acceptable. Mais les données réelles au niveau de la base de données ne posent aucun problème.
Question 9 : Même si l'optimisation commerciale considère « 3 000 billets de train, seules 3 000 demandes de commandes vont à la base de données », ces 3 000 commandes ne provoqueront-elles pas de congestion ?
Réponse : (1) La base de données peut supporter 3 000 requêtes d'écriture ; (2) Les données peuvent être divisées ; (3) Si 3 000 requêtes ne peuvent pas être tolérées, la couche de service (serveur Web) Vous peut contrôler le nombre de connexions simultanées, sur la base du test de stress. 3k n'est qu'un exemple
Question 10 ; Si c'est sur le serveur ou la couche de service (serveur Web ; ) Si le traitement en arrière-plan échoue, devons-nous envisager de rejouer ce lot de requêtes ayant échoué ? Ou simplement le jeter ?
Réponse : Ne le rejouez pas. Revenez à l'échec de la requête de l'utilisateur ou à l'échec de la commande. L'un des principes de conception architecturale est « l'échec rapide ».
Question 11. Pour les ventes flash de gros systèmes, comme le 12306, il y a plusieurs ventes flash qui se déroulent en même temps. Comment les détourner ?
Réponse : Division verticale
Question 12. Une autre question me vient à l'esprit. Ce processus est-il synchrone ou asynchrone ? S'il est synchronisé, il devrait y avoir un retour de réponse lent. Mais s’il est asynchrone, comment contrôler si le résultat de la réponse peut être renvoyé au bon demandeur ?
Réponse : Le niveau utilisateur est définitivement synchrone (la requête http de l'utilisateur est supprimée), et la couche de service (serveur web) peut être synchrone ou asynchrone.
Question 13. Question du groupe de vente flash : A quel stade faut-il réduire les stocks ? Si vous passez une commande pour verrouiller l'inventaire, que devez-vous faire si un grand nombre d'utilisateurs malveillants passent des commandes pour verrouiller l'inventaire sans payer ?
Réponse : Le volume des demandes d'écriture au niveau de la base de données est très faible. Heureusement, la commande ne sera pas payée. Attendez que le délai soit écoulé avant de "revenir à la position".
Conseils : Points à prendre en compte
1 Déployez loin du site d'origine (le serveur pour la fonction de vente flash et le serveur du centre commercial ne doivent pas être placés sur. le même serveur pour éviter les ventes flash Crashé, le centre commercial n'est pas accessible...)
2. Surveillez davantage, faites attention au suivi, trouvez quelqu'un à surveiller
Points clés de vente flash :
1. Haute disponibilité : double actif
2. Concurrence élevée : équilibrage de charge, filtrage de sécurité
Idées de conception :
1. Page statique : cdn (utilisez ceux prêts à l'emploi des principaux fabricants), masquage d'URL, compression de page, mécanisme de mise en cache
2. Pages dynamiques : mise en file d'attente, asynchrone, capture de qualification
Autres suggestions :
1. Suggestions de Baidu : cache d'opcode, cdn, instance de serveur plus grande
2. Suggestions d'Alibaba : surveillance du cloud, bouclier cloud, ecs, oss, rds, cdn
Utilisation du Cdn. idées :
1. Téléchargez des ressources statiques (images, js, css, etc.) sur le cdn
2. Inconvénients : Mais veuillez noter que le cdn ne sera pas mis à jour à temps lors de la mise à jour, il faut donc pousser
Reconnaître la situation actuelle Environnement et forme :
1. Utilisateurs : un grand nombre de personnes normales/mauvaises (l'accélération cdn est aussi une diversion, car il accède au nœud cdn à proximité)
2. Région : dans tout le pays (un retard de 1,2 s n'est pas suffisant, car la vente flash peut se terminer avec un délai de 1 s, et un CDN est nécessaire pour permettre aux utilisateurs de sélectionner le plus proche). node)
3. Processus commercial : présentation du produit et enregistrement à la réception. Accès aux données backend et traitement des données
Ajouter une page avant la vente flash pour détourner et promouvoir d'autres produits
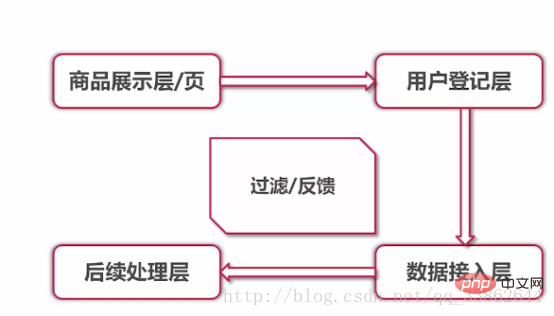
Produit architecture de la couche d'affichage
Trois états de la page :
1. Affichage du produit : page compte à rebours
2. Vente flash en cours : cliquez pour accéder à la vente flash page
3. L'événement de vente flash est terminé : Invite que l'événement est terminé
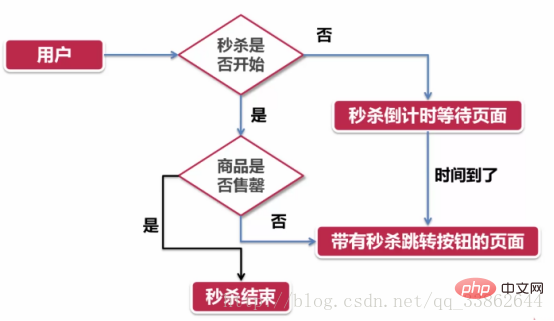
Nouvelle idée : réfléchir au problème en termes de chronologie
Supposons que ce que nous voyons soit la vente flash En cours, avancer est le compte à rebours, repousser est la fin
L'image suivante montre le problème du point de vue de l'utilisateur :
Code :

Ressources statiques, stockées dans oss pour le déploiement

Supprimez d'abord la page du compte à rebours, et copiez-la immédiatement sur la page de vente flash Venez
puis utilisez coretab pour exécuter ce script régulièrement

Résumé :
Du compte à rebours à la vente urgente : utilisez les tâches planifiées de Linux et le script Shell pour le faire
La ruée vers l'achat est terminée et la ruée vers l'achat est terminée : PHP est utilisé pour le faire, et il se termine lorsque la table est partie
Structure de la couche d'enregistrement des utilisateurs

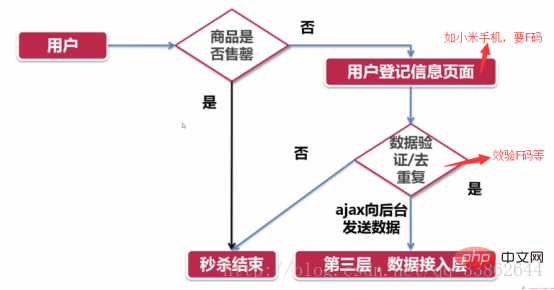
Code :

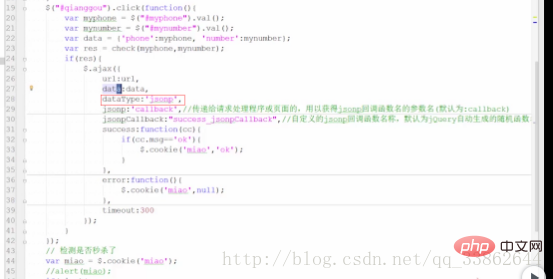
Package $.cookie
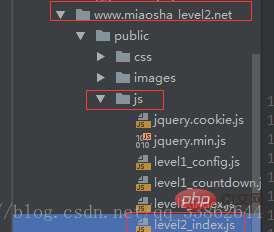
Couche d'accès aux données

Code :

Comment calculer le temps entre la couche 2 et la couche 3 ? ?
Quelle est la durée du retard total causé par la couche 2 envoyant des données à la couche 3 + la résolution DNS de transmission réseau et d'autres facteurs, afin que vous puissiez évaluer le nombre de serveurs qui doivent être configurés
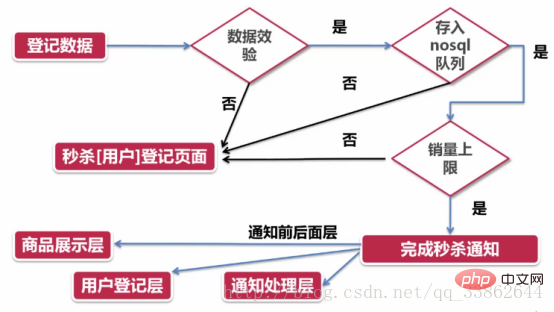
Résumé en 2 phrases :
1. Si vous échouez au point clé, revenez directement à la couche précédente (couche d'enregistrement des utilisateurs)
2. le point clé S'il est réussi, les autres couches seront notifiées
Effet : cryptage et déchiffrement similaires au numéro de série Microsoft
File d'attente : collection ordonnée à l'aide de redis
Limite supérieure : indicateur technique bit
Couche de traitement des données


Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Guide d'installation et de mise à niveau de PHP 8.4 pour Ubuntu et Debian
Dec 24, 2024 pm 04:42 PM
Guide d'installation et de mise à niveau de PHP 8.4 pour Ubuntu et Debian
Dec 24, 2024 pm 04:42 PM
PHP 8.4 apporte plusieurs nouvelles fonctionnalités, améliorations de sécurité et de performances avec une bonne quantité de dépréciations et de suppressions de fonctionnalités. Ce guide explique comment installer PHP 8.4 ou mettre à niveau vers PHP 8.4 sur Ubuntu, Debian ou leurs dérivés. Bien qu'il soit possible de compiler PHP à partir des sources, son installation à partir d'un référentiel APT comme expliqué ci-dessous est souvent plus rapide et plus sécurisée car ces référentiels fourniront les dernières corrections de bogues et mises à jour de sécurité à l'avenir.
 Date et heure de CakePHP
Sep 10, 2024 pm 05:27 PM
Date et heure de CakePHP
Sep 10, 2024 pm 05:27 PM
Pour travailler avec la date et l'heure dans cakephp4, nous allons utiliser la classe FrozenTime disponible.
 Discuter de CakePHP
Sep 10, 2024 pm 05:28 PM
Discuter de CakePHP
Sep 10, 2024 pm 05:28 PM
CakePHP est un framework open source pour PHP. Il vise à faciliter grandement le développement, le déploiement et la maintenance d'applications. CakePHP est basé sur une architecture de type MVC à la fois puissante et facile à appréhender. Modèles, vues et contrôleurs gu
 Téléchargement de fichiers CakePHP
Sep 10, 2024 pm 05:27 PM
Téléchargement de fichiers CakePHP
Sep 10, 2024 pm 05:27 PM
Pour travailler sur le téléchargement de fichiers, nous allons utiliser l'assistant de formulaire. Voici un exemple de téléchargement de fichiers.
 CakePHP créant des validateurs
Sep 10, 2024 pm 05:26 PM
CakePHP créant des validateurs
Sep 10, 2024 pm 05:26 PM
Le validateur peut être créé en ajoutant les deux lignes suivantes dans le contrôleur.
 Journalisation CakePHP
Sep 10, 2024 pm 05:26 PM
Journalisation CakePHP
Sep 10, 2024 pm 05:26 PM
Se connecter à CakePHP est une tâche très simple. Il vous suffit d'utiliser une seule fonction. Vous pouvez enregistrer les erreurs, les exceptions, les activités des utilisateurs, les actions entreprises par les utilisateurs, pour tout processus en arrière-plan comme cronjob. La journalisation des données dans CakePHP est facile. La fonction log() est fournie
 Comment configurer Visual Studio Code (VS Code) pour le développement PHP
Dec 20, 2024 am 11:31 AM
Comment configurer Visual Studio Code (VS Code) pour le développement PHP
Dec 20, 2024 am 11:31 AM
Visual Studio Code, également connu sous le nom de VS Code, est un éditeur de code source gratuit – ou environnement de développement intégré (IDE) – disponible pour tous les principaux systèmes d'exploitation. Avec une large collection d'extensions pour de nombreux langages de programmation, VS Code peut être c
 Guide rapide CakePHP
Sep 10, 2024 pm 05:27 PM
Guide rapide CakePHP
Sep 10, 2024 pm 05:27 PM
CakePHP est un framework MVC open source. Cela facilite grandement le développement, le déploiement et la maintenance des applications. CakePHP dispose d'un certain nombre de bibliothèques pour réduire la surcharge des tâches les plus courantes.
