
 base de données
Redis
Une introduction simple et facile à comprendre aux principes de mise en cache Redis
base de données
Redis
Une introduction simple et facile à comprendre aux principes de mise en cache Redis
Une introduction simple et facile à comprendre aux principes de mise en cache Redis

Ce qui suit est une introduction au principe de mise en cache Redis de la colonne Tutoriel Redis J'espère que cela sera utile aux amis dans le besoin !

1. Qu'est-ce que Redis
Redis est un Nosql (base de données non relationnelle) open source hautes performances écrit en langage C, et les données sont stockées en mémoire. Redis est stocké au format clé-valeur, ce qui est différent des bases de données relationnelles traditionnelles. Elle ne respecte pas nécessairement certaines exigences de base des bases de données traditionnelles, par exemple, elle ne respecte pas les normes SQL, les transactions, les structures de tables, etc. Les bases de données non relationnelles ne sont strictement pas une base de données, mais un ensemble de méthodes de stockage de données structurées. Structures de données en Java : chaîne, tableau, liste, set map... Redis propose de nombreuses méthodes qui peuvent être utilisées pour accéder aux données dans diverses structures de données.
2. Fonctionnalités (Avantages)
1. Les données sont stockées en mémoire, avec une vitesse d'accès rapide et une forte concurrence
2. Il prend en charge les types de valeurs stockées là-bas. sont relativement plus nombreux, notamment string (string), list (liste chaînée), set (set), zset (ensemble trié - ensemble ordonné) et hash (type de hachage).
3. L'émergence de redis a largement compensé les défauts du stockage clé/valeur comme memcached. Dans certains cas, il peut jouer un très bon rôle complémentaire aux bases de données relationnelles (comme MySQL).
4. Il fournit des clients Java, C/C++, C#, PHP, JavaScript et autres, ce qui est très pratique à utiliser.
5.Redis prend en charge le clustering (synchronisation maître-esclave, équilibrage de charge). Les données peuvent être synchronisées du serveur maître vers n'importe quel nombre de serveurs esclaves, et le serveur esclave peut être le serveur maître associé à d'autres serveurs esclaves.
6. Prend en charge la persistance et peut enregistrer des données dans des fichiers sur le disque dur
7. Prend en charge la fonction d'abonnement/publication du groupe QQ
1. Stockage des données : stocké en mémoire et persiste occasionnellement sur le disque. La vitesse d'accès est rapide, la capacité de concurrence est forte et les données ne seront pas perdues après une panne de courant.
2. Prend en charge plus de types de valeur.
3. Clients multiples (langage java php c# js)
4. Cluster de support pour étendre l'espace 8G+8G+16G
5. Open source (gratuit et maintenu par de nombreuses personnes)
3. Installez le serveur Redis
Le site de téléchargement officiel de Redis est http://redis.io/download, vous pouvez y aller pour télécharger le dernier programme d'installation
3.1. Windows Installation et utilisation sous
1. Téléchargez le logiciel du programme redis
et utilisez redisbin32 ou redisbin64
2. Logiciel vert, aucune installation requise, utilisez-le directement 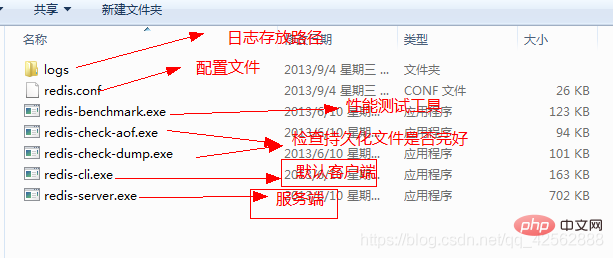
3. Démarrer le service redis (Démarrer avec le fichier de configuration et démarrer sans fichier de configuration) 
4. Connectez-vous à redis pour l'opération
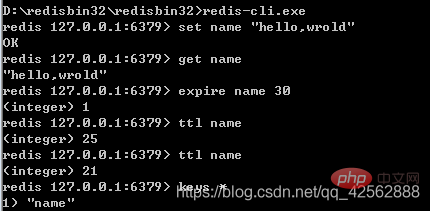
cmd>{%redis%}/redis-cli -h adresse IP - p numéro de port
ip par défaut est local -p default 6379
redis-cli -h 172.16.6.248 -p 6379
cmd>{%redis%}/redis-cli
- Utilisation de base

2. Configuration de la persistance de Redis

Redis fournit deux niveaux différents de Méthode de persistance : RDB et AOF, qui peuvent être configurées en modifiant redis.conf 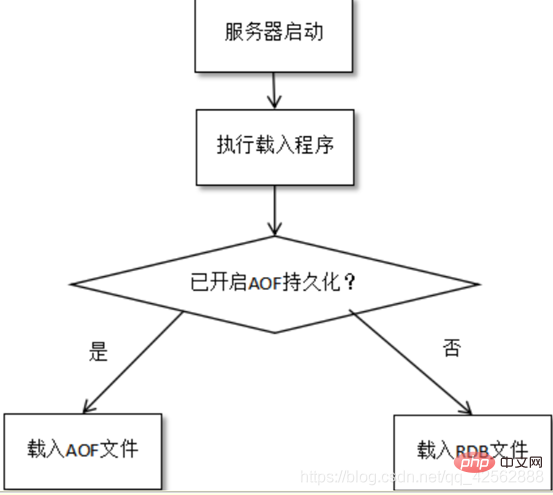
Lorsque les conditions de persistance sont remplies, la persistance sera enregistrée. Les données qui n'ont pas encore été enregistrées seront enregistrées dans AOF. moyen de le préserver.
Lorsque Redis démarre, il analyse d'abord le fichier journal (un tas de commandes) et restaure les données. Ensuite, chargez également le fichier rdb (prenez l'union).
4.Mode RDB
La persistance RDB peut générer des instantanés ponctuels de l'ensemble de données dans un intervalle de temps spécifié. 🎜> Comment désactiver le mode rdb :
save ""
save 900 1 //Au moins un changement de synchronisation de stockage se produit dans un délai de 900 secondes
save xxx save 60 10000
5 Mode d'ajout de journal .AOF
AOF enregistre de manière persistante toutes les commandes d'opération d'écriture exécutées par le serveur et restaure l'ensemble de données en réexécutant ces commandes au démarrage du serveur. Ce mode est désactivé par défaut.
Comment activer le mode aof :
appendonly yes //yes on, no off
#appendfsync always //Exécutez fsync à chaque fois qu'il y a une nouvelle commande et placez les données du tampon dans le fichier aof
#Ici, nous activons Everysec
appendfsync Everysec //fsync une fois par seconde
#appendfsync no //Jamais fsync (laissez le soin au système d'exploitation de le gérer, l'exécution de fsync peut prendre beaucoup de temps)
Veuillez fournir d'autres paramètres. Jetons un coup d'œil à l'explication détaillée du fichier de configuration redis.conf
6 Scénario pratique classique Redis - cache
- 6.1 Pourquoi utiliser le cache Stockez les données fréquemment interrogées et les données rarement modifiées dans le cache pour réduire l'accès à la base de données et réduire la pression sur la base de données. Le cache est généralement en mémoire et la vitesse d'accès est relativement rapide.
- 6.2 Quelles données conviennent au cache Requête fréquente : la mise en cache consiste à fournir un accès efficace aux requêtes de données.
Rarement modifié : le cache et la base de données doivent être modifiés simultanément lors de la modification
Par exemple : données régionales, classification des produits, menu du dictionnaire de données (quelles que soient les autorisations) - 6.3 Choisir le approprié CacheCache de deuxième niveau Hibernate, cache de deuxième niveau mybatis, cache central redis
Cache de deuxième niveau Hibernate, le cache de deuxième niveau mybatis ne prend pas en charge le cache de cluster par défaut, utilisez redis
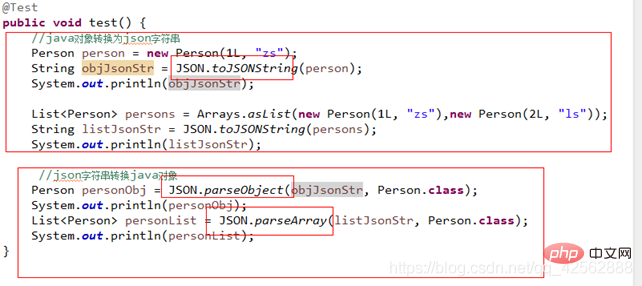
- 6.4 Comment stocker les données1) json : Convertir les données à stocker en chaîne de type json
Lors de la sauvegarde du cache :
Objet Java --------- -->chaîne json
Obtenir le cache :
chaîne json-------->Objet Java-
Framework Json : jdk-json-lib jackson gson fastjson
2) Stockage binaire : sérialisez les données à stocker dans un cadre de sérialisation binaire pour implémenter
7. Implémenter la mise en cache des menus
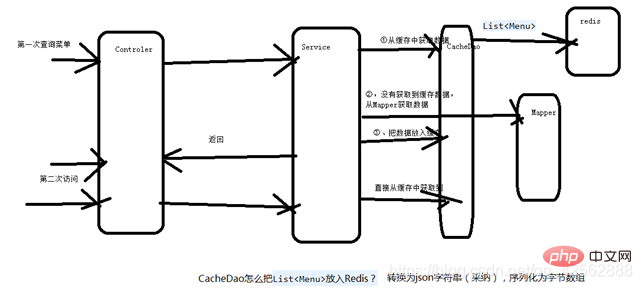
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données Redis: utilisez la commande flushall pour effacer toutes les valeurs de clé. Utilisez la commande flushdb pour effacer la valeur clé de la base de données actuellement sélectionnée. Utilisez SELECT pour commuter les bases de données, puis utilisez FlushDB pour effacer plusieurs bases de données. Utilisez la commande del pour supprimer une clé spécifique. Utilisez l'outil Redis-CLI pour effacer les données.
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
L'utilisation des opérations Redis pour verrouiller nécessite l'obtention du verrouillage via la commande setnx, puis en utilisant la commande Expire pour définir le temps d'expiration. Les étapes spécifiques sont les suivantes: (1) Utilisez la commande setnx pour essayer de définir une paire de valeurs de clé; (2) Utilisez la commande Expire pour définir le temps d'expiration du verrou; (3) Utilisez la commande del pour supprimer le verrouillage lorsque le verrouillage n'est plus nécessaire.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Redis utilise des tables de hachage pour stocker les données et prend en charge les structures de données telles que les chaînes, les listes, les tables de hachage, les collections et les collections ordonnées. Redis persiste les données via des instantanés (RDB) et ajoutez les mécanismes d'écriture uniquement (AOF). Redis utilise la réplication maître-esclave pour améliorer la disponibilité des données. Redis utilise une boucle d'événement unique pour gérer les connexions et les commandes pour assurer l'atomicité et la cohérence des données. Redis définit le temps d'expiration de la clé et utilise le mécanisme de suppression paresseux pour supprimer la clé d'expiration.
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment faire du message middleware pour redis
Apr 10, 2025 pm 07:51 PM
Comment faire du message middleware pour redis
Apr 10, 2025 pm 07:51 PM
Redis, en tant que Message Middleware, prend en charge les modèles de consommation de production, peut persister des messages et assurer une livraison fiable. L'utilisation de Redis comme Message Middleware permet une faible latence, une messagerie fiable et évolutive.
