

En tant que développeur dans la colonne JavaScript, une compréhension approfondie du fonctionnement du moteur JavaScript vous aidera à comprendre les caractéristiques de performances de votre code. Cet article couvre quelques principes de base communs à tous les moteurs JavaScript, pas seulement au V8.
Tout commence par le code JavaScript que vous écrivez. Le moteur JavaScript analyse le code source et le convertit en un arbre de syntaxe abstraite (AST). Sur la base de l'AST, l'interpréteur peut commencer à travailler et générer du bytecode. À ce stade, le moteur commence à exécuter du code JavaScript. 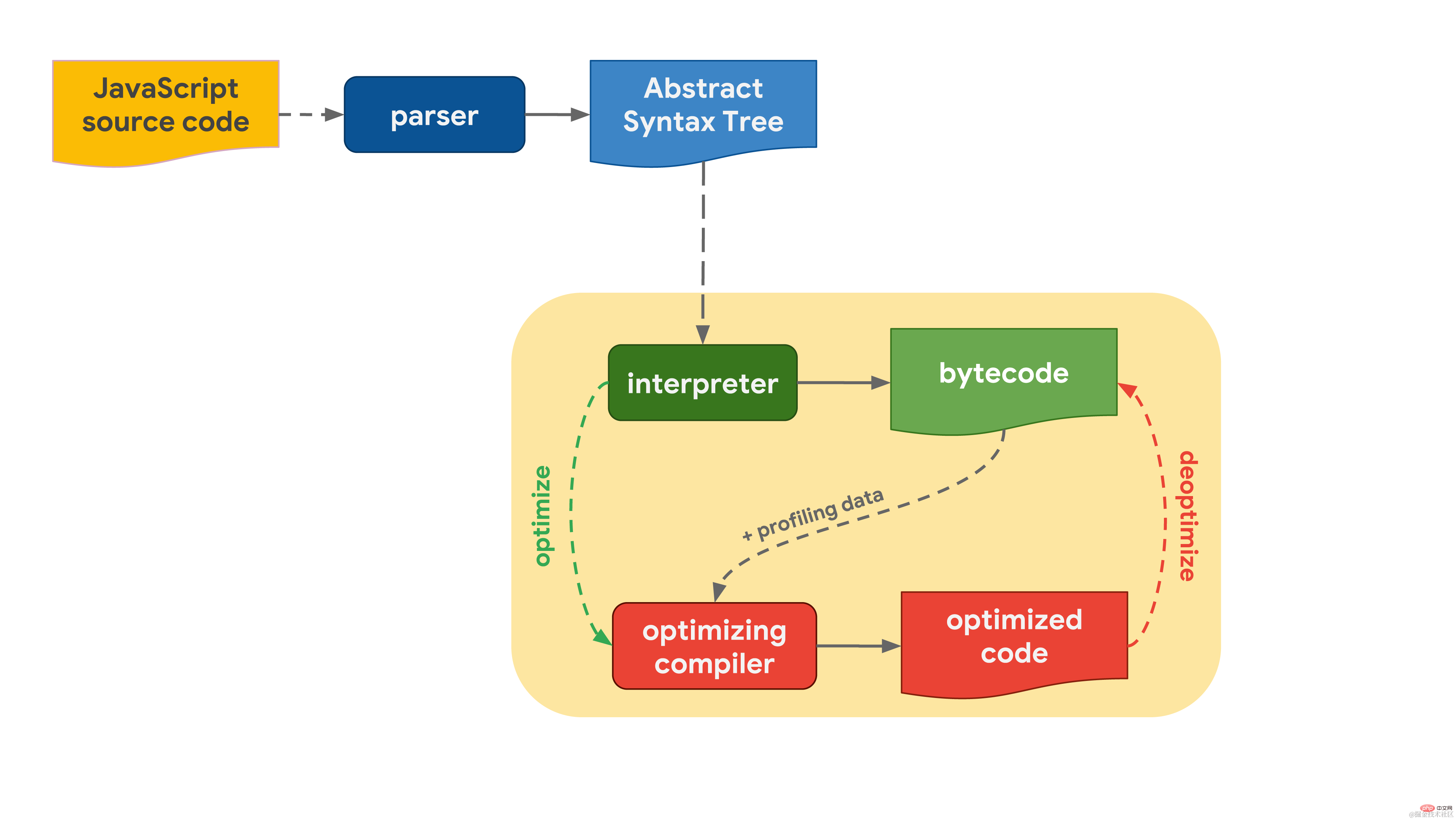 Pour le rendre plus rapide, le bytecode peut être envoyé au compilateur d'optimisation avec les données de profilage. Un compilateur d'optimisation fait certaines hypothèses sur la base des données de profilage disponibles, puis génère un code machine hautement optimisé.
Pour le rendre plus rapide, le bytecode peut être envoyé au compilateur d'optimisation avec les données de profilage. Un compilateur d'optimisation fait certaines hypothèses sur la base des données de profilage disponibles, puis génère un code machine hautement optimisé.
Si à un moment donné une hypothèse s'avère incorrecte, le compilateur d'optimisation annulera l'optimisation et reviendra à l'étape de l'interprète.
Maintenant, regardons la partie du processus qui exécute réellement le code JavaScript, la partie où le code est interprété et optimisé, et discutons-en. quelques différences entre les principaux moteurs JavaScript.
De manière générale, le moteur JavaScript dispose d'un flux de traitement qui comprend un interpréteur et un compilateur d'optimisation. Parmi eux, l'interpréteur peut générer rapidement du bytecode non optimisé, tandis que le compilateur d'optimisation prendra plus de temps, mais peut finalement générer du code machine hautement optimisé. 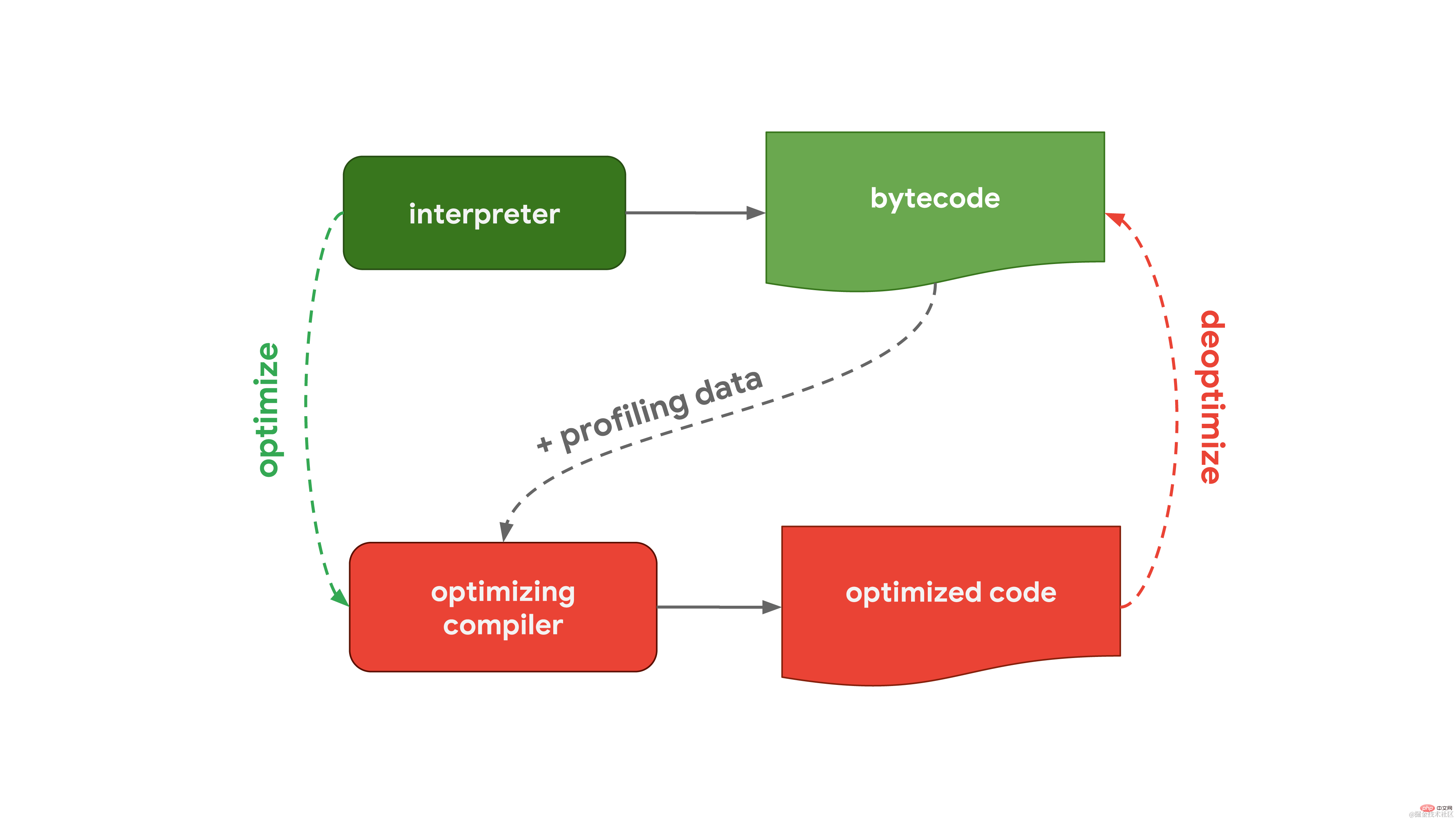 Ce processus général est presque le même que le workflow de V8, le moteur Javascript utilisé dans Chrome et Node.js :
Ce processus général est presque le même que le workflow de V8, le moteur Javascript utilisé dans Chrome et Node.js : 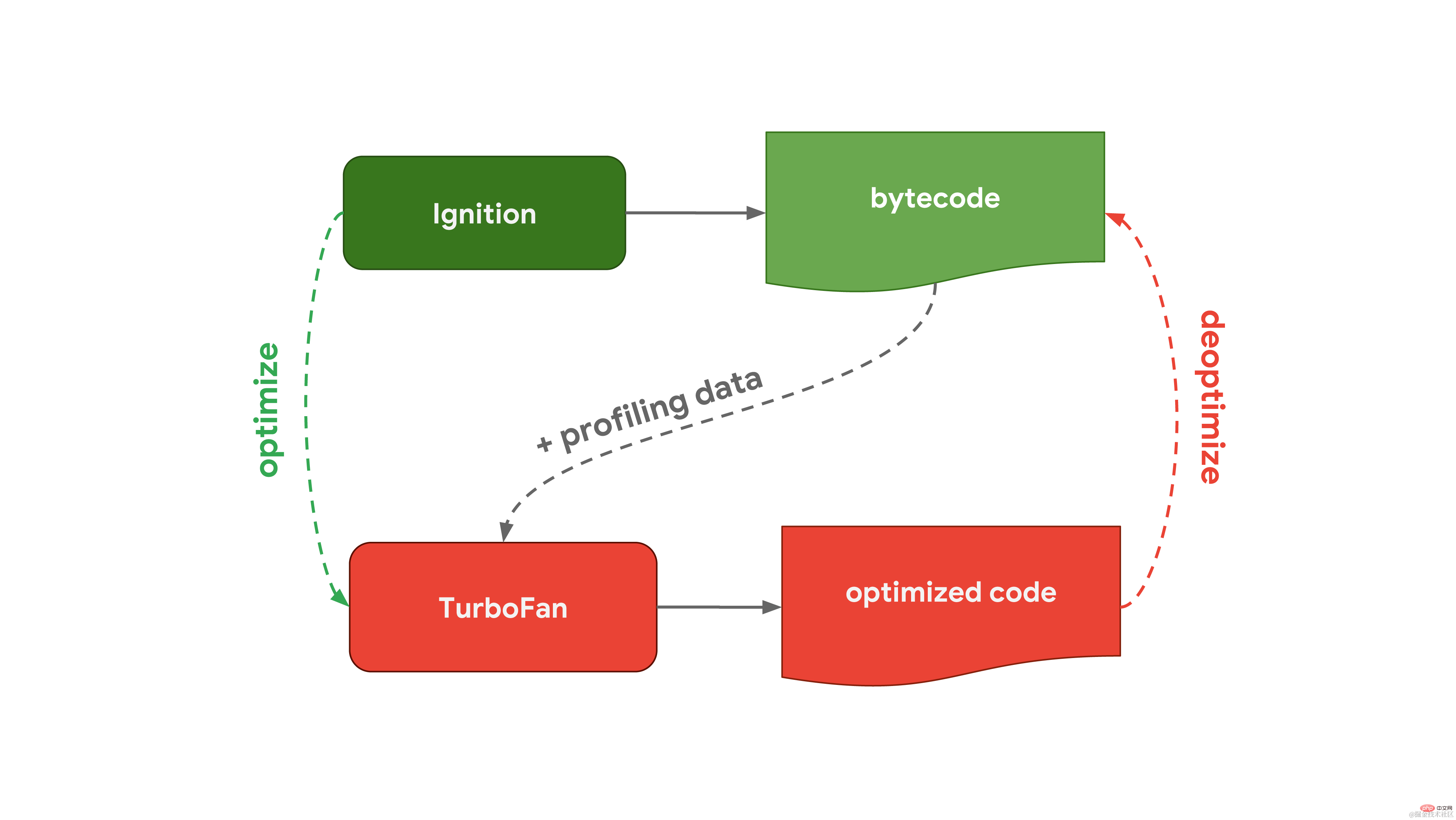 L'interpréteur de V8 s'appelle Ignition, qui est responsable de la génération et de l'exécution du bytecode. Lors de l'exécution du bytecode, il collecte des données de profilage qui peuvent être utilisées ultérieurement pour accélérer l'exécution du code. Lorsqu'une fonction devient chaude, par exemple lorsqu'elle est exécutée fréquemment, le bytecode généré et les données de profilage sont transmis à Turbofan, notre compilateur d'optimisation, pour générer un code machine hautement optimisé basé sur les données de profilage.
L'interpréteur de V8 s'appelle Ignition, qui est responsable de la génération et de l'exécution du bytecode. Lors de l'exécution du bytecode, il collecte des données de profilage qui peuvent être utilisées ultérieurement pour accélérer l'exécution du code. Lorsqu'une fonction devient chaude, par exemple lorsqu'elle est exécutée fréquemment, le bytecode généré et les données de profilage sont transmis à Turbofan, notre compilateur d'optimisation, pour générer un code machine hautement optimisé basé sur les données de profilage. 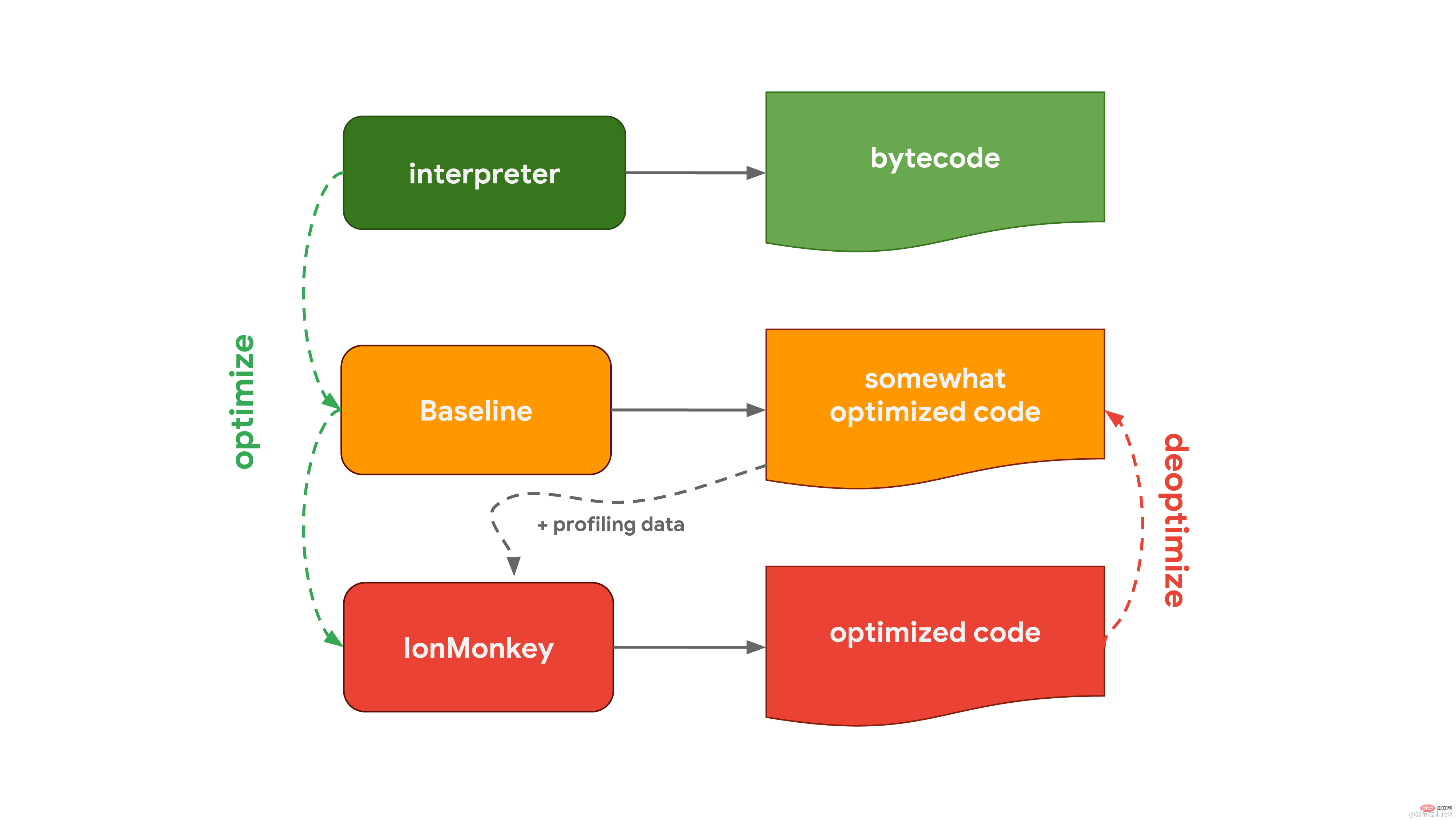 SpiderMonkey, le moteur JavaScript utilisé par Mozilla dans Firefox et Spidernode, est différent. Ils ont deux compilateurs d'optimisation au lieu d'un. L'interpréteur passe d'abord par le compilateur Baseline pour générer du code optimisé. Ensuite, combiné aux données de profilage collectées lors de l'exécution du code, le compilateur IonMonkey peut générer un code plus optimisé. Si la tentative d'optimisation échoue, IonMonkey reviendra au code de l'étape de base.
SpiderMonkey, le moteur JavaScript utilisé par Mozilla dans Firefox et Spidernode, est différent. Ils ont deux compilateurs d'optimisation au lieu d'un. L'interpréteur passe d'abord par le compilateur Baseline pour générer du code optimisé. Ensuite, combiné aux données de profilage collectées lors de l'exécution du code, le compilateur IonMonkey peut générer un code plus optimisé. Si la tentative d'optimisation échoue, IonMonkey reviendra au code de l'étape de base.
Chakra, le moteur JavaScript de Microsoft utilisé dans Edge, est très similaire et dispose également de 2 compilateurs d'optimisation. L'interpréteur optimise le code dans SimpleJIT (JIT signifie compilateur Just-In-Time, compilateur juste-à-temps), qui produit un code légèrement optimisé. FullJIT combine les données d'analyse pour générer un code plus optimisé. 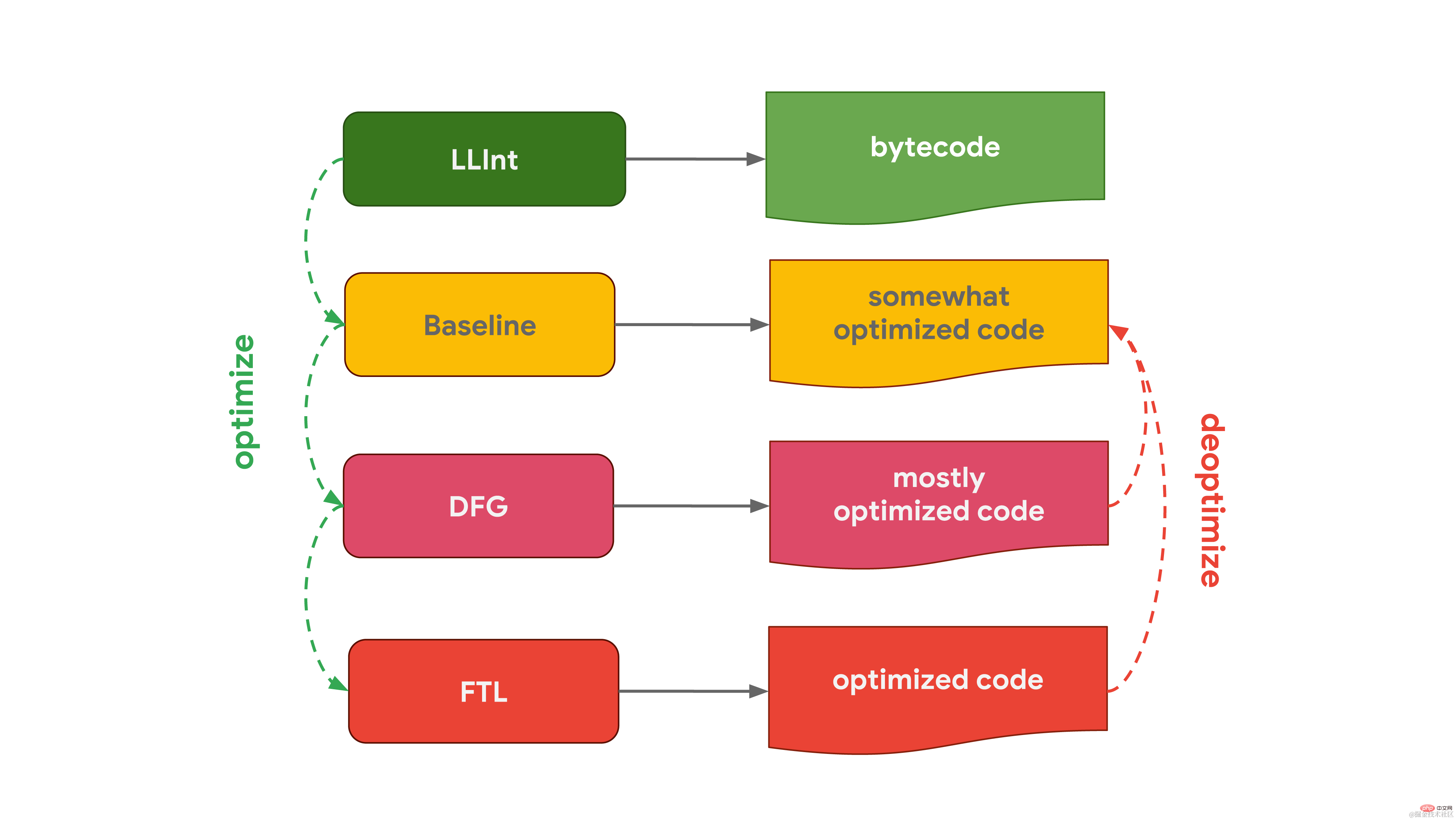 JavaScriptCore (en abrégé JSC), le moteur JavaScript d'Apple utilisé dans Safari et React Native, le pousse à l'extrême avec trois compilateurs d'optimisation différents. L'interpréteur de bas niveau LLInt optimise le code dans le compilateur Baseline, puis optimise le code dans le compilateur DFG (Data Flow Graph). Le compilateur DFG (Data Flow Graph) peut à son tour transmettre le code optimisé à FTL (Faster Than Light). ) pour compilation dans le navire.
JavaScriptCore (en abrégé JSC), le moteur JavaScript d'Apple utilisé dans Safari et React Native, le pousse à l'extrême avec trois compilateurs d'optimisation différents. L'interpréteur de bas niveau LLInt optimise le code dans le compilateur Baseline, puis optimise le code dans le compilateur DFG (Data Flow Graph). Le compilateur DFG (Data Flow Graph) peut à son tour transmettre le code optimisé à FTL (Faster Than Light). ) pour compilation dans le navire.
Pourquoi certains moteurs ont-ils des compilateurs plus optimisants ? C’est le résultat d’une pesée du pour et du contre. Les interprètes peuvent générer du bytecode rapidement, mais le bytecode n'est généralement pas très efficace. L'optimisation des compilateurs, en revanche, prend plus de temps mais produit finalement un code machine plus efficace. Il existe un compromis entre l'exécution rapide du code (interprète) ou le fait de prendre plus de temps, mais finalement l'exécution du code avec des performances optimales (optimisation du compilateur). Certains moteurs choisissent d'ajouter plusieurs compilateurs d'optimisation avec des caractéristiques temps/efficacité différentes, permettant un contrôle plus fin de ces compromis au prix d'une complexité supplémentaire. Un autre aspect à prendre en compte est lié à l’utilisation de la mémoire, qui sera détaillée ultérieurement dans un article dédié.
Nous venons de souligner les différences majeures dans les processus d'interprétation et d'optimisation du compilateur dans chaque moteur JavaScript. Hormis ces différences, à un niveau élevé, tous les moteurs JavaScript ont la même architecture : il existe un analyseur et une sorte de processus interpréteur/compilateur.
Voyons quels autres moteurs JavaScript ont en commun en zoomant sur certains aspects de leur implémentation.
Par exemple, comment les moteurs JavaScript implémentent-ils le modèle objet JavaScript et quelles astuces utilisent-ils pour accélérer l'accès aux propriétés des objets JavaScript ? Il s’avère que tous les principaux moteurs ont actuellement des implémentations similaires.
La spécification ECMAScript définit essentiellement tous les objets comme des dictionnaires avec des clés de chaîne mappées aux propriétés de propriété.
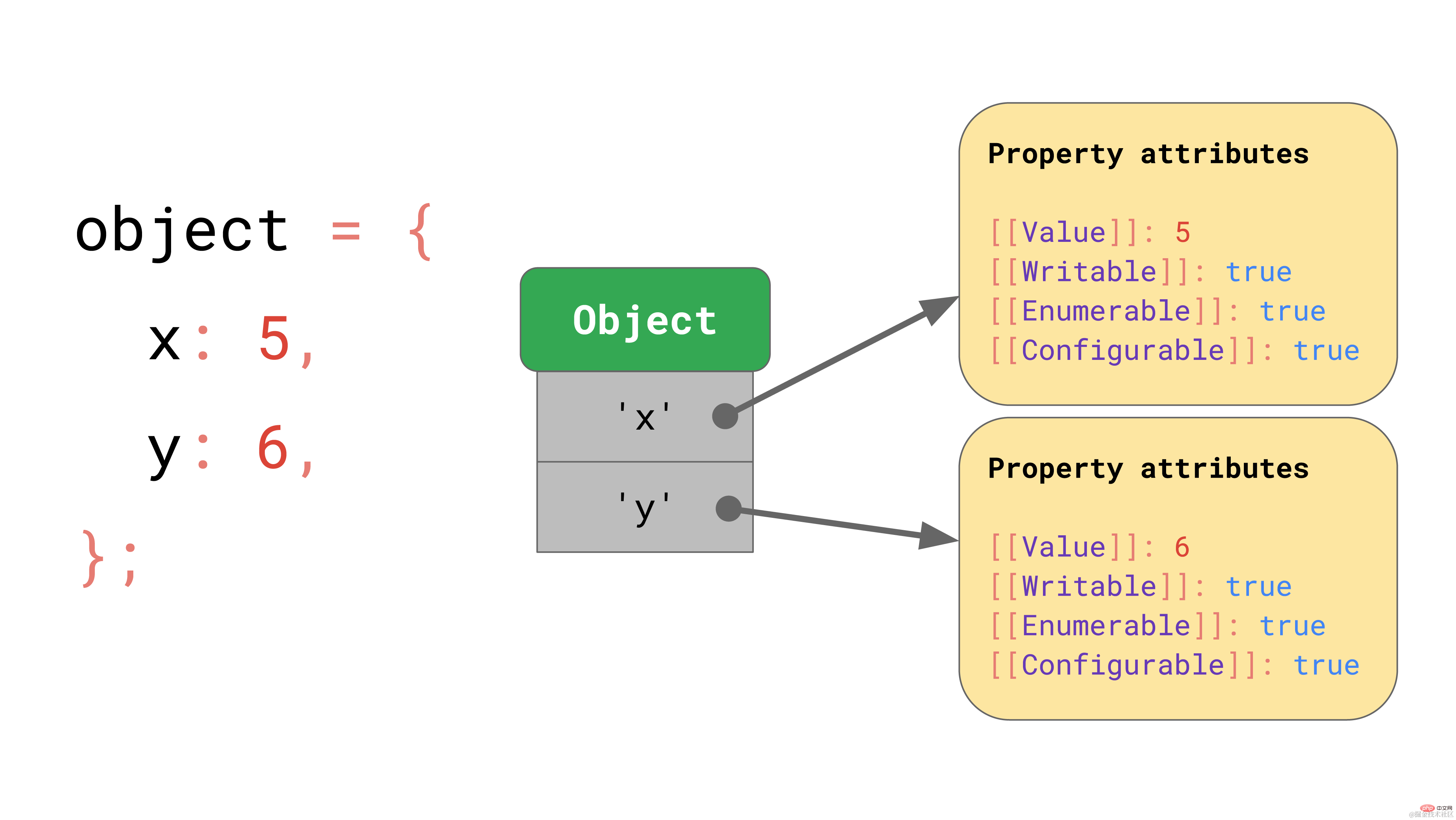 En plus de [[Value]] lui-même, la spécification définit également ces propriétés :
En plus de [[Value]] lui-même, la spécification définit également ces propriétés :
[[crochets]] peut sembler un peu inhabituelle, mais c'est exactement ainsi que la spécification définit les propriétés qui ne peuvent pas être directement exposées à JavaScript. En JavaScript, vous pouvez toujours obtenir la valeur de propriété d'un objet spécifié via l'API Object.getOwnPropertyDescriptor :
const object = { foo: 42 };Object.getOwnPropertyDescriptor(object, 'foo');// → { value: 42, writable: true, enumerable: true, configurable: true }复制代码C'est ainsi que JavaScript définit les objets, mais qu'en est-il des tableaux ?
Vous pouvez considérer un tableau comme un objet spécial. L'une des différences est que les tableaux effectuent un traitement spécial sur les index du tableau. L'indexation de tableaux est ici un terme spécial dans la spécification ECMAScript. Les tableaux sont limités en JavaScript à avoir au plus 2³²−1 éléments, et l'index du tableau est tout index valide dans cette plage, c'est-à-dire tout entier compris entre 0 et 2³²−2.
Une autre différence est que les tableaux ont également une propriété de longueur spéciale.
const array = ['a', 'b']; array.length; // → 2array[2] = 'c'; array.length; // → 3复制代码
Dans cet exemple, le tableau est créé avec une longueur de 2. Lorsque nous attribuons un autre élément à l'index 2, la longueur est automatiquement mise à jour.
JavaScript définit les tableaux de la même manière que les objets. Par exemple, toutes les valeurs clés, y compris les indices de tableau, sont explicitement représentées sous forme de chaînes. Le premier élément du tableau est stocké sous la valeur clé « 0 ». 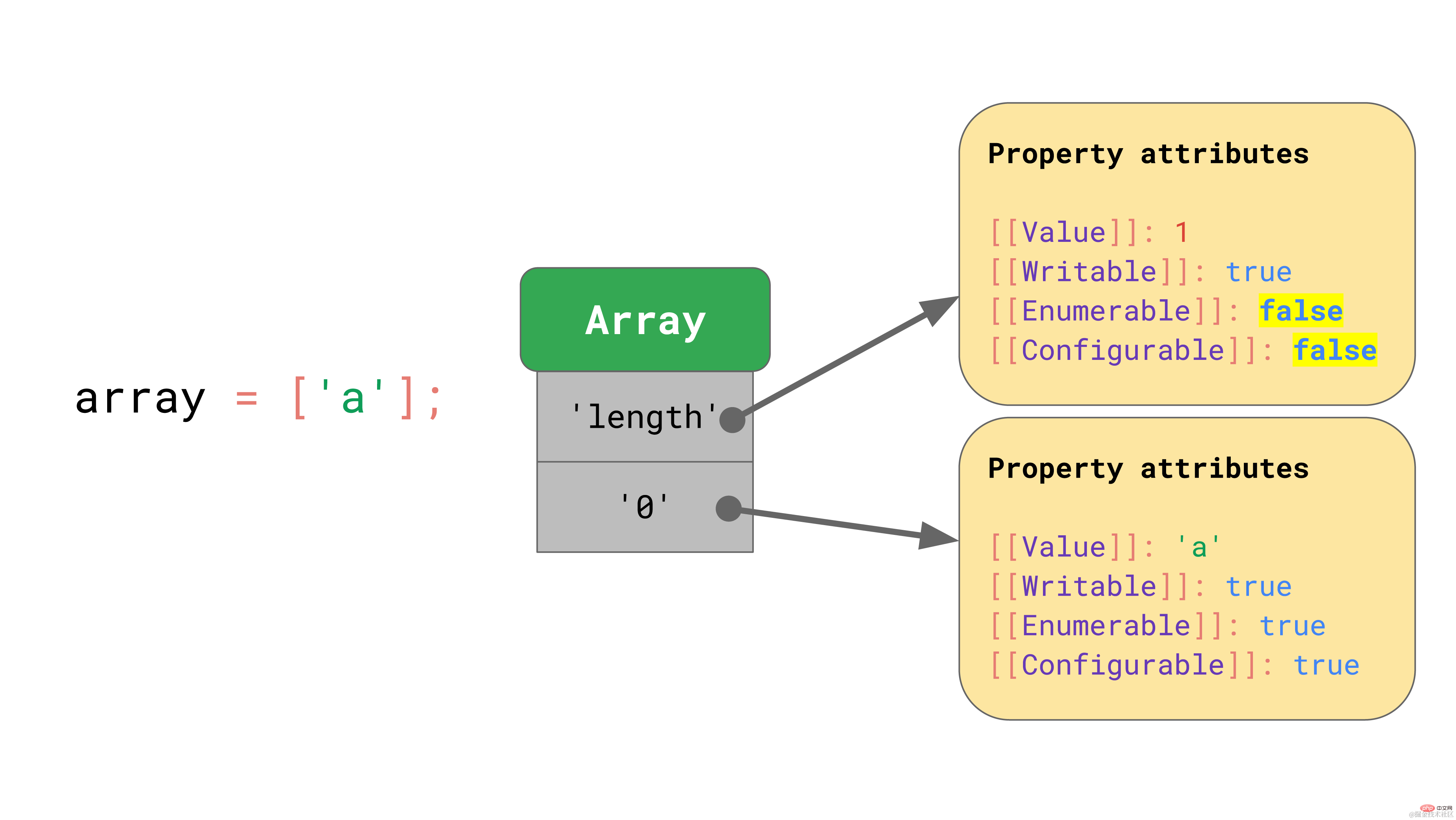 La propriété "length" est une autre propriété non énumérable et non configurable.
Lorsqu'un élément est ajouté au tableau, JavaScript met automatiquement à jour la propriété [[value]] de la propriété « length ».
La propriété "length" est une autre propriété non énumérable et non configurable.
Lorsqu'un élément est ajouté au tableau, JavaScript met automatiquement à jour la propriété [[value]] de la propriété « length ». 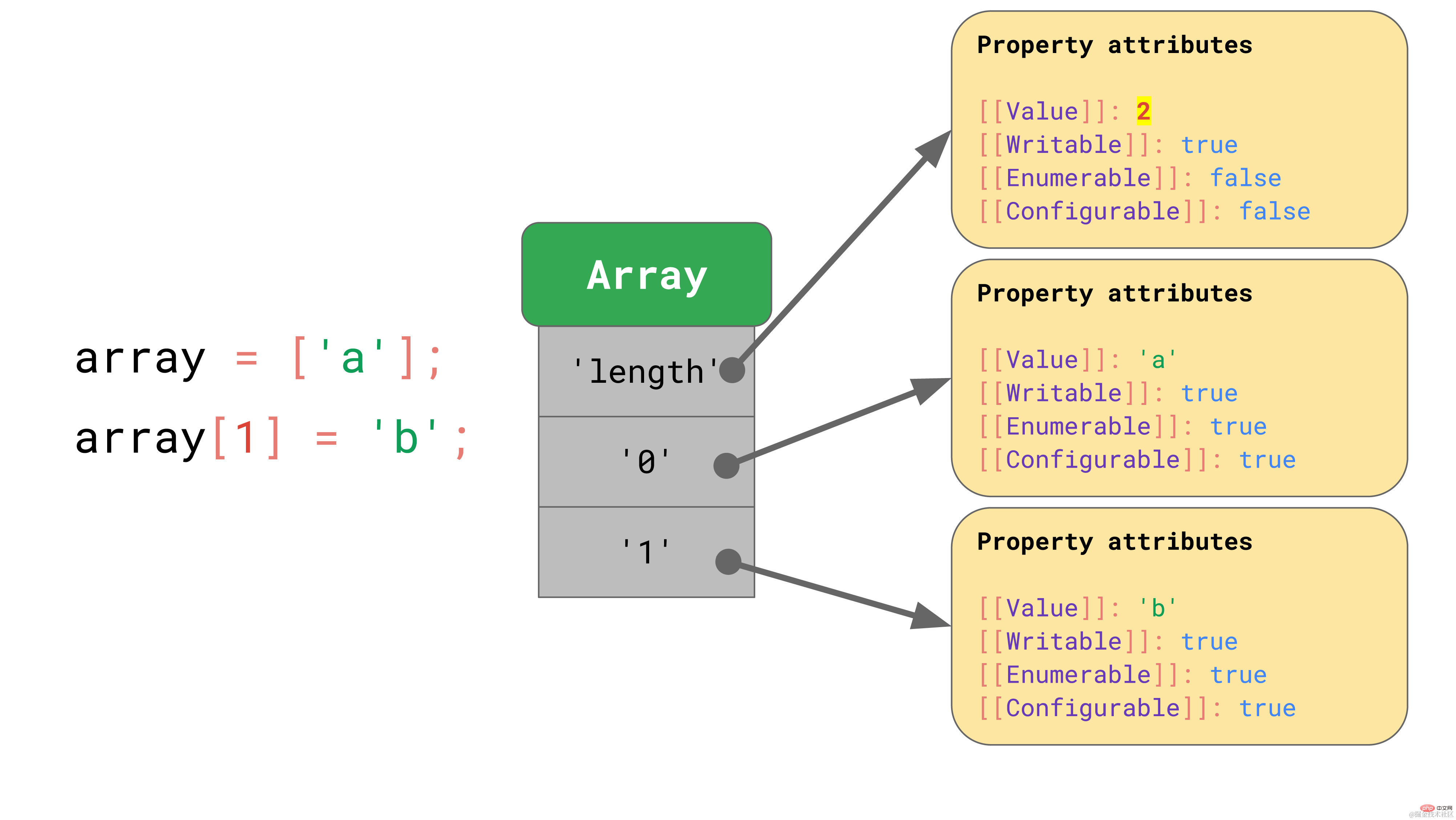
Maintenant que nous savons comment les objets sont définis en JavaScript, examinons de plus près la façon dont le moteur JavaScript utilise efficacement les objets. Dans l'ensemble, l'accès aux propriétés est de loin l'opération la plus courante dans les programmes JavaScript. Il est donc crucial que le moteur JavaScript puisse accéder rapidement aux propriétés.
Dans les programmes JavaScript, il est très courant que plusieurs objets aient les mêmes propriétés clé-valeur. On peut dire que ces objets ont la même forme.
const object1 = { x: 1, y: 2 };const object2 = { x: 3, y: 4 };// object1 and object2 have the same shape.复制代码Il est également très courant d'accéder aux mêmes propriétés d'objets ayant la même forme :
function logX(object) { console.log(object.x);
}const object1 = { x: 1, y: 2 };const object2 = { x: 3, y: 4 };
logX(object1);
logX(object2);复制代码Dans cette optique, les moteurs JavaScript peuvent optimiser l'accès aux propriétés des objets en fonction de la forme de l'objet. Nous présenterons ci-dessous son principe.
Supposons que nous ayons un objet avec les attributs x et y qui utilise la structure de données du dictionnaire dont nous avons parlé plus tôt : il contient des clés sous la forme de chaînes qui pointent vers leurs valeurs d'attribut respectives. 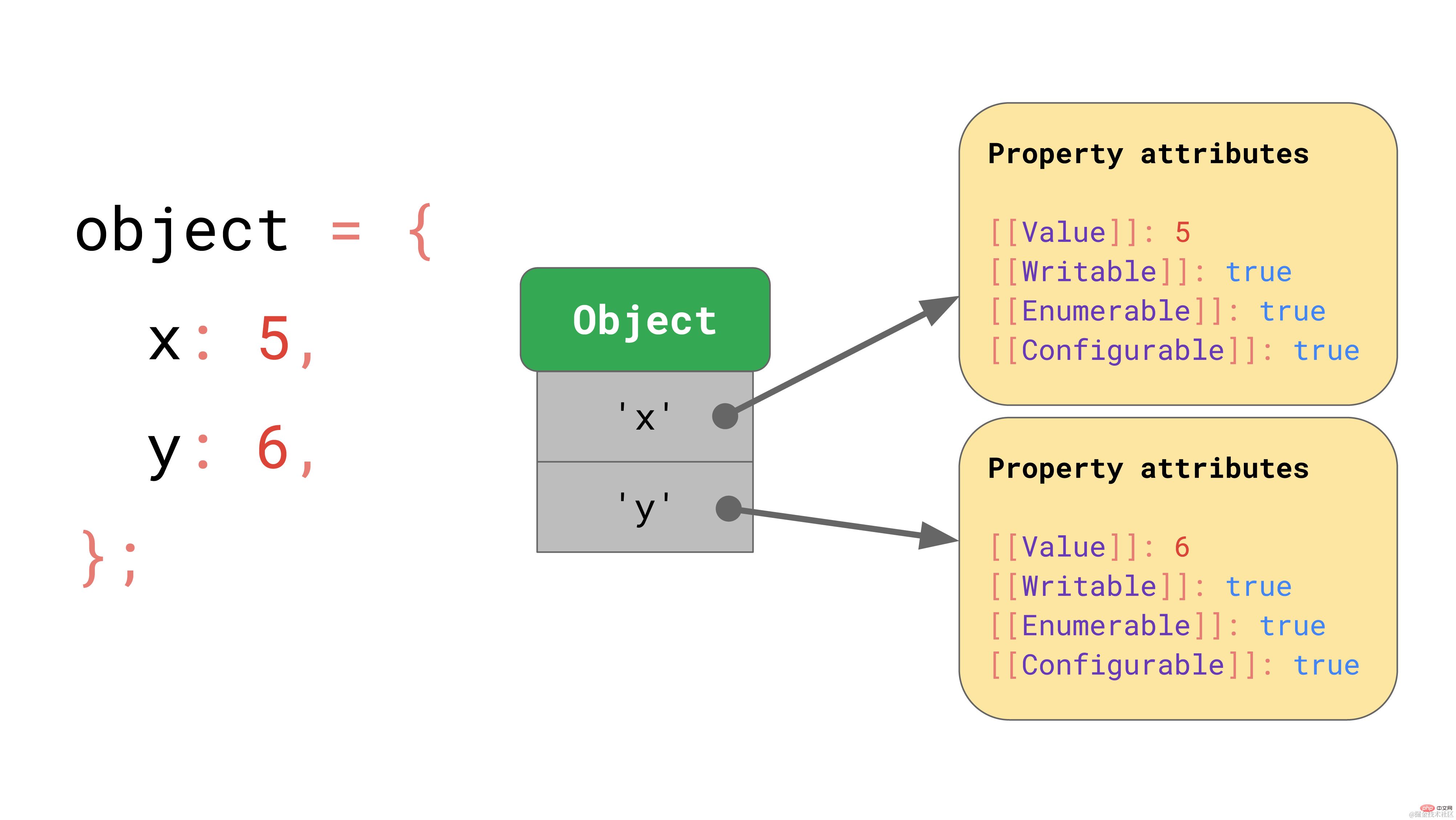
Si vous accédez à une propriété, telle que object.y, le moteur JavaScript recherchera la valeur clé 'y' dans le JSObject, puis chargera la valeur de propriété correspondante, et enfin retournera [[Value ]].
Mais où sont stockées ces valeurs d'attribut en mémoire ? Devrions-nous les stocker dans le cadre de JSObject ? En supposant que nous rencontrerons plus d'objets de même forme plus tard, ce serait un gaspillage de stocker un dictionnaire complet contenant les noms de propriétés et les valeurs de propriétés dans le JSObject lui-même, car les noms de propriétés seront répétés pour tous les objets avec le même forme. Cela représente beaucoup de duplication et une utilisation inutile de la mémoire. À titre d'optimisation, le moteur stocke la forme de l'objet séparément. 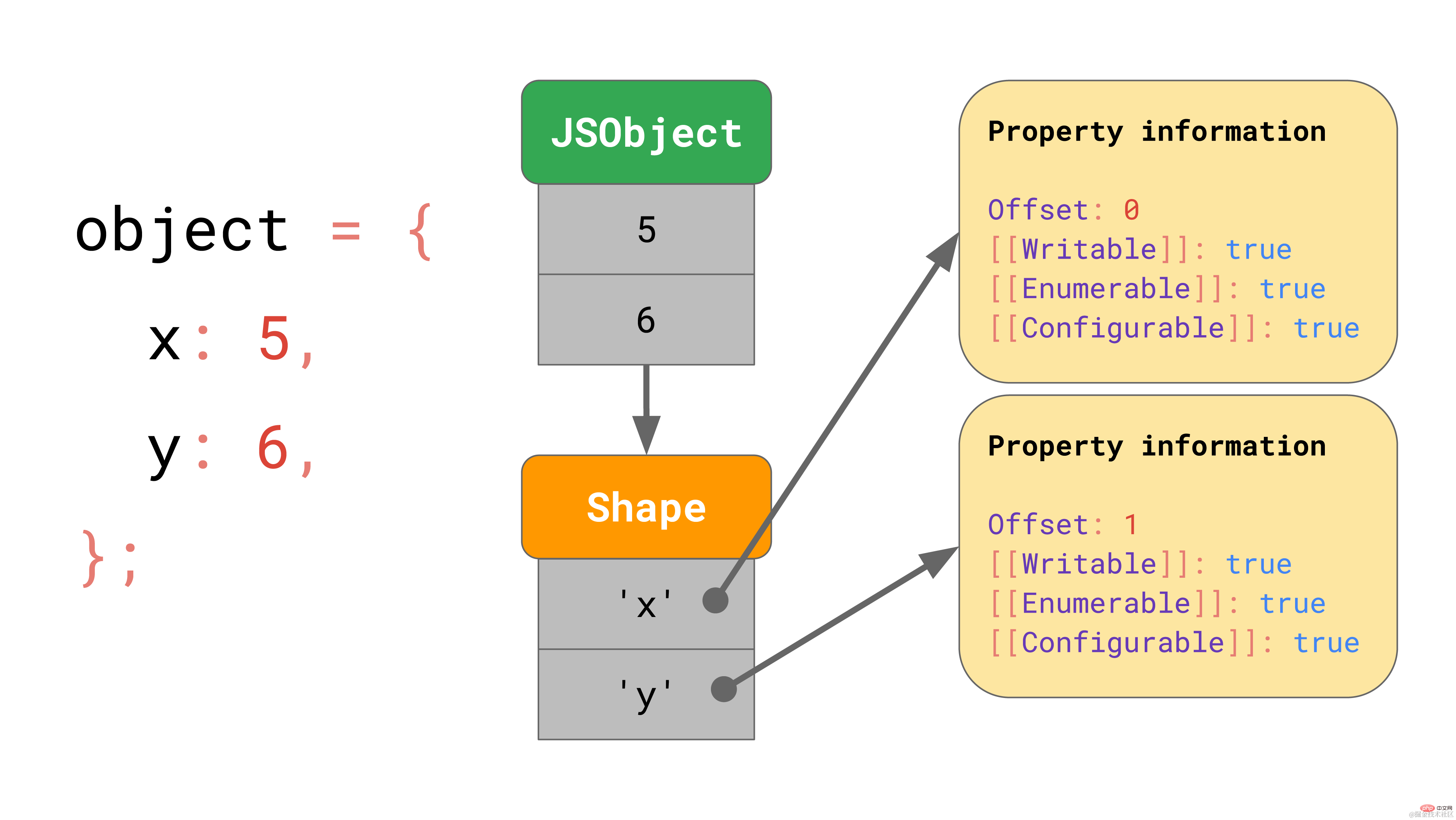 la forme contient tous les noms d'attributs et propriétés à l'exception de [[Valeur]]. De plus, la forme contient le décalage de la valeur interne du JSObject afin que le moteur JavaScript sache où chercher la valeur. Chaque JSObject ayant la même forme pointe vers cette instance de forme. Désormais, chaque JSObject n'a besoin que de stocker une valeur unique à cet objet.
la forme contient tous les noms d'attributs et propriétés à l'exception de [[Valeur]]. De plus, la forme contient le décalage de la valeur interne du JSObject afin que le moteur JavaScript sache où chercher la valeur. Chaque JSObject ayant la même forme pointe vers cette instance de forme. Désormais, chaque JSObject n'a besoin que de stocker une valeur unique à cet objet. 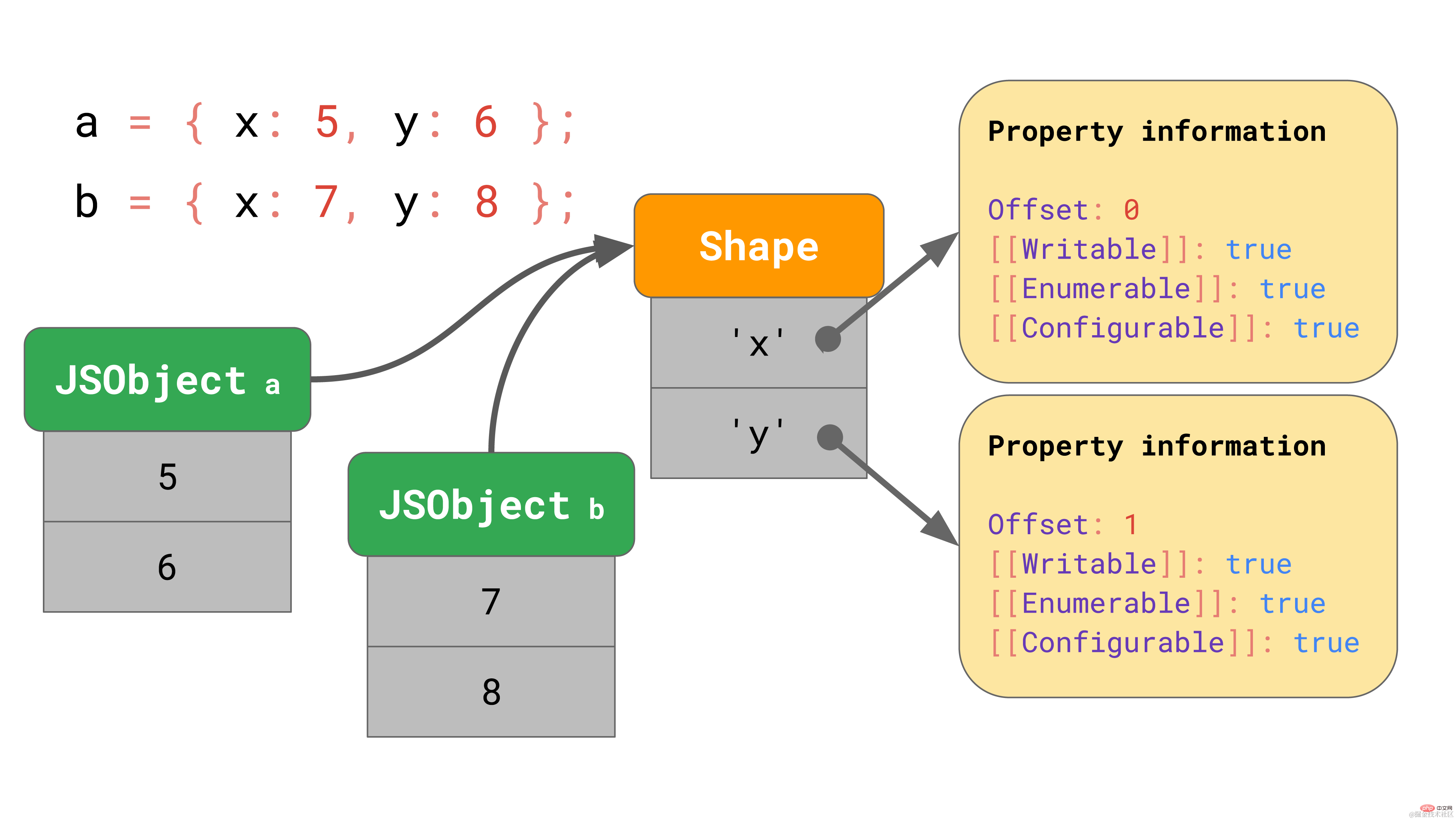 Les avantages sont évidents lorsque nous avons plusieurs objets. Quel que soit le nombre d'objets, tant qu'ils ont la même forme, nous n'avons besoin de stocker les informations sur la forme et les attributs qu'une seule fois !
Les avantages sont évidents lorsque nous avons plusieurs objets. Quel que soit le nombre d'objets, tant qu'ils ont la même forme, nous n'avons besoin de stocker les informations sur la forme et les attributs qu'une seule fois !
Tous les moteurs JavaScript utilisent des formes comme optimisation, mais elles portent des noms différents :
本文中,我们将继续使用术语 shapes.
如果你有一个具有特定 shape 的对象,但你又向它添加了一个属性,此时会发生什么? JavaScript 引擎是如何找到这个新 shape 的?
const object = {};
object.x = 5;
object.y = 6;复制代码这些 shapes 在 JavaScript 引擎中形成所谓的转换链(transition chains)。下面是一个例子:
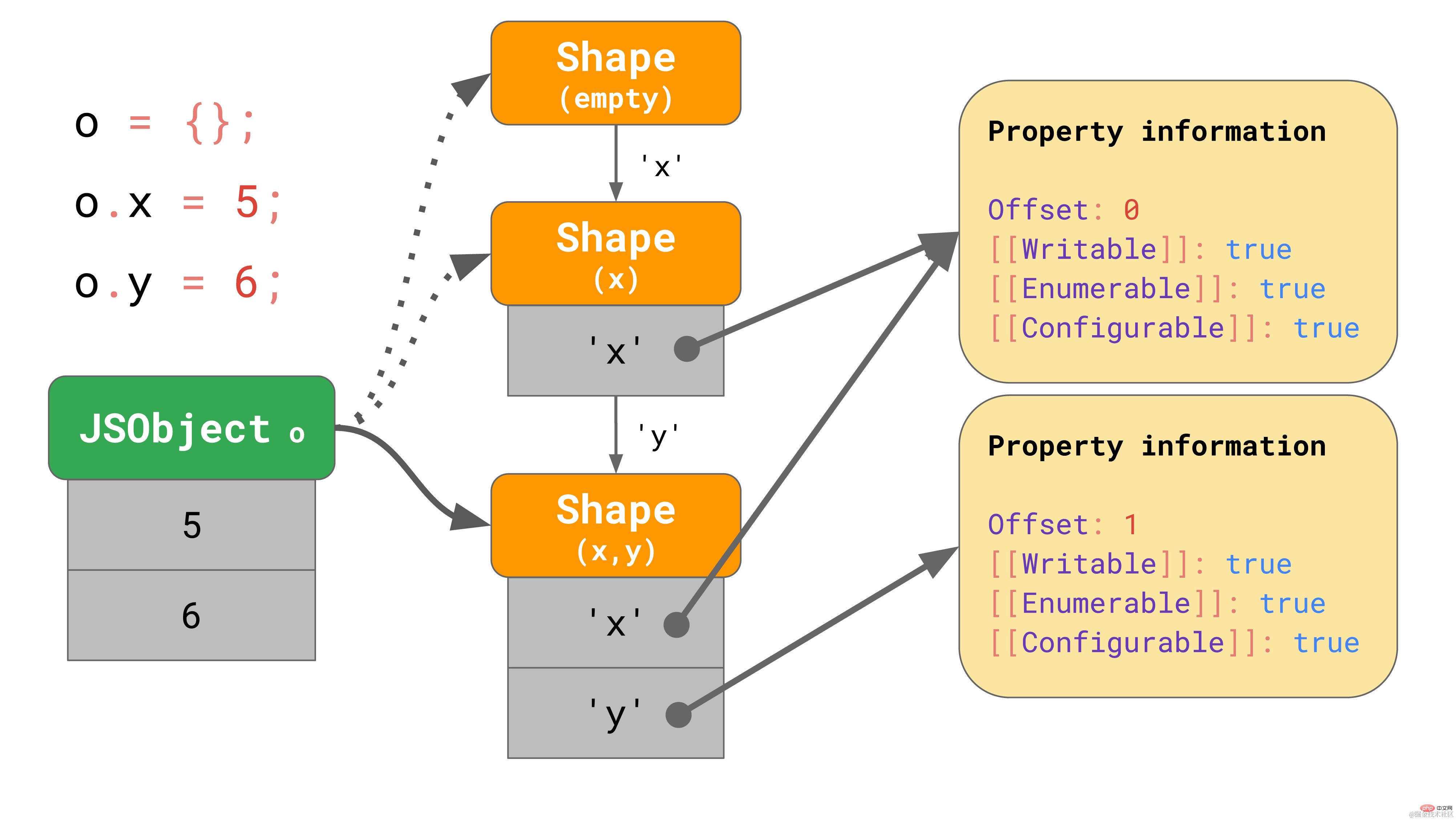
该对象开始没有任何属性,因此它指向一个空的 shape。下一个语句为该对象添加一个值为 5 的属性 "x",所以 JavaScript 引擎转向一个包含属性 "x" 的 shape,并在第一个偏移量为 0 处向 JSObject 添加了一个值 5。 下一行添加了一个属性 'y',引擎便转向另一个包含 'x' 和 'y' 的 shape,并将值 6 添加到 JSObject(位于偏移量 1 处)。
我们甚至不需要为每个 shape 存储完整的属性表。相反,每个shape 只需要知道它引入的新属性。例如,在本例中,我们不必将有关 “x” 的信息存储在最后一个 shape 中,因为它可以在更早的链上找到。要实现这一点,每个 shape 都会链接回其上一个 shape: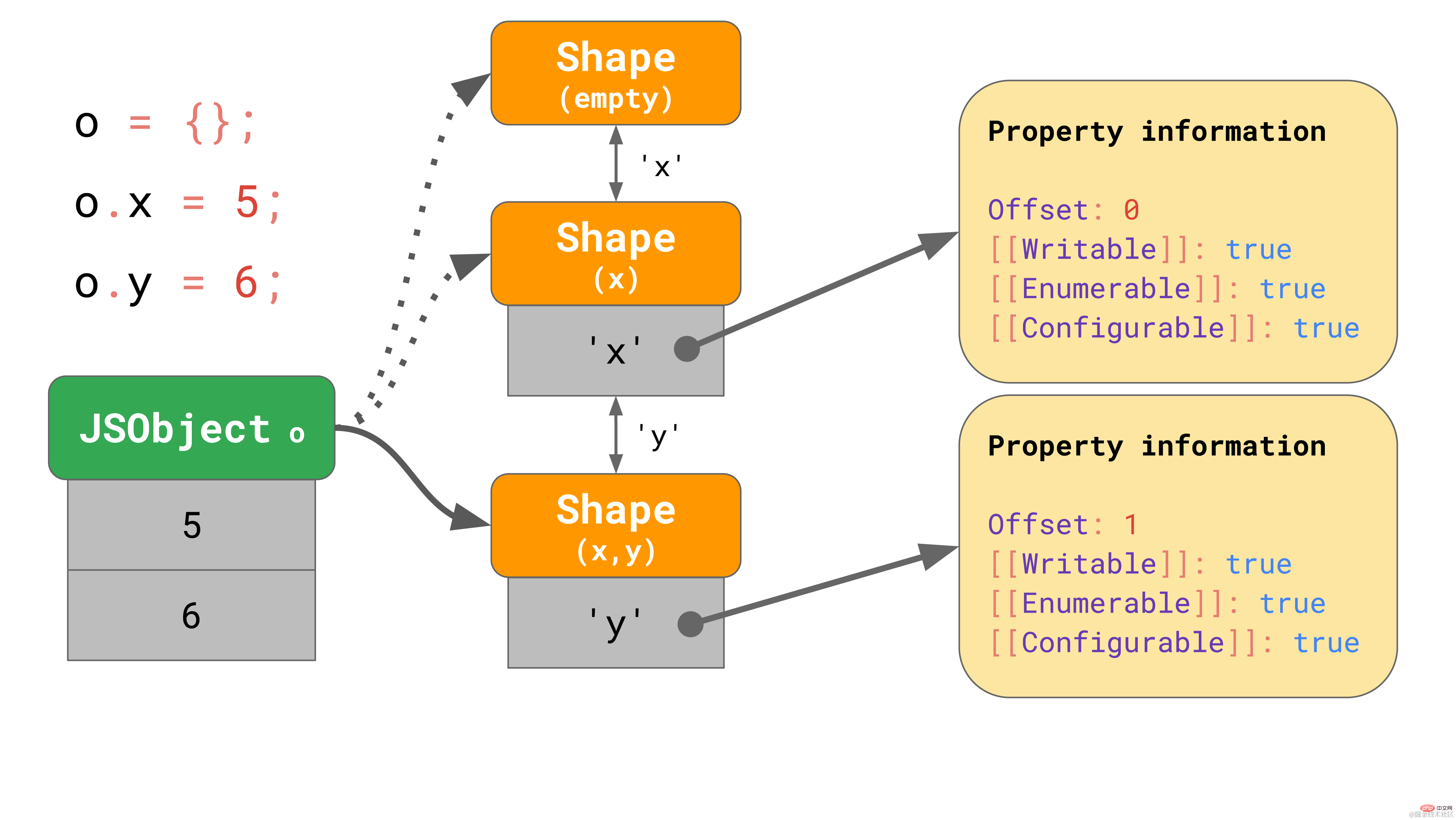
如果你在 JavaScript 代码中写 o.x,JavaScript 引擎会沿着转换链去查找属性 "x",直到找到引入属性 "x" 的 Shape。
但是如果没有办法创建一个转换链会怎么样呢?例如,如果有两个空对象,并且你为每个对象添加了不同的属性,该怎么办?
const object1 = {};
object1.x = 5;const object2 = {};
object2.y = 6;复制代码在这种情况下,我们必须进行分支操作,最终我们会得到一个转换树而不是转换链。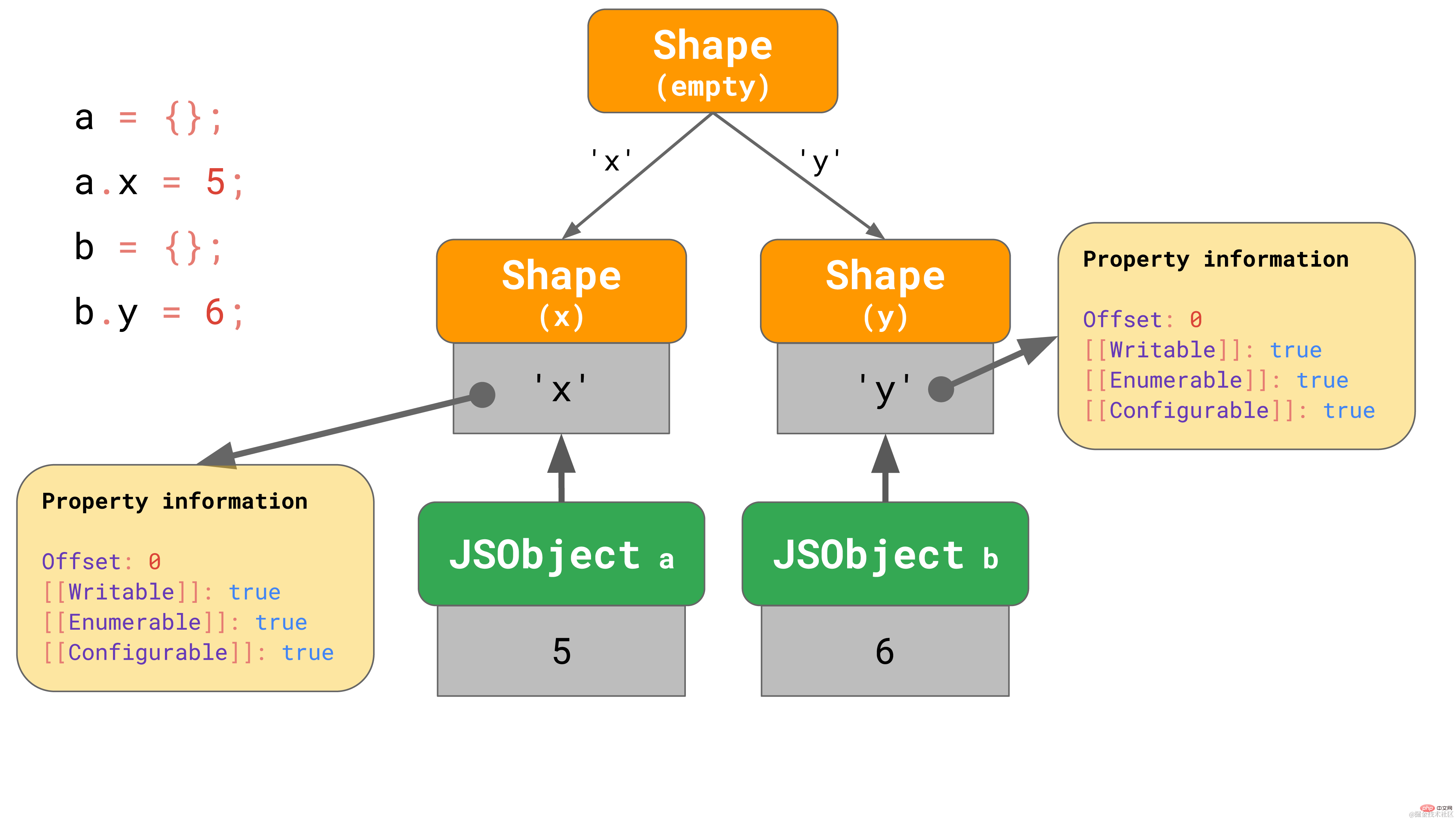
这里,我们创建了一个空对象 a,然后给它添加了一个属性 ‘x’。最终,我们得到了一个包含唯一值的 JSObject 和两个 Shape :空 shape 以及只包含属性 x 的 shape。
第二个例子也是从一个空对象 b 开始的,但是我们给它添加了一个不同的属性 ‘y’。最终,我们得到了两个 shape 链,总共 3 个 shape。
这是否意味着我们总是需要从空 shape 开始呢? 不一定。引擎对已含有属性的对象字面量会进行一些优化。比方说,我们要么从空对象字面量开始添加 x 属性,要么有一个已经包含属性 x 的对象字面量:
const object1 = {};
object1.x = 5;const object2 = { x: 6 };复制代码在第一个例子中,我们从空 shape 开始,然后转到包含 x 的shape,这正如我们之前所见那样。
在 object2 的例子中,直接在一开始就生成含有 x 属性的对象,而不是生成一个空对象是有意义的。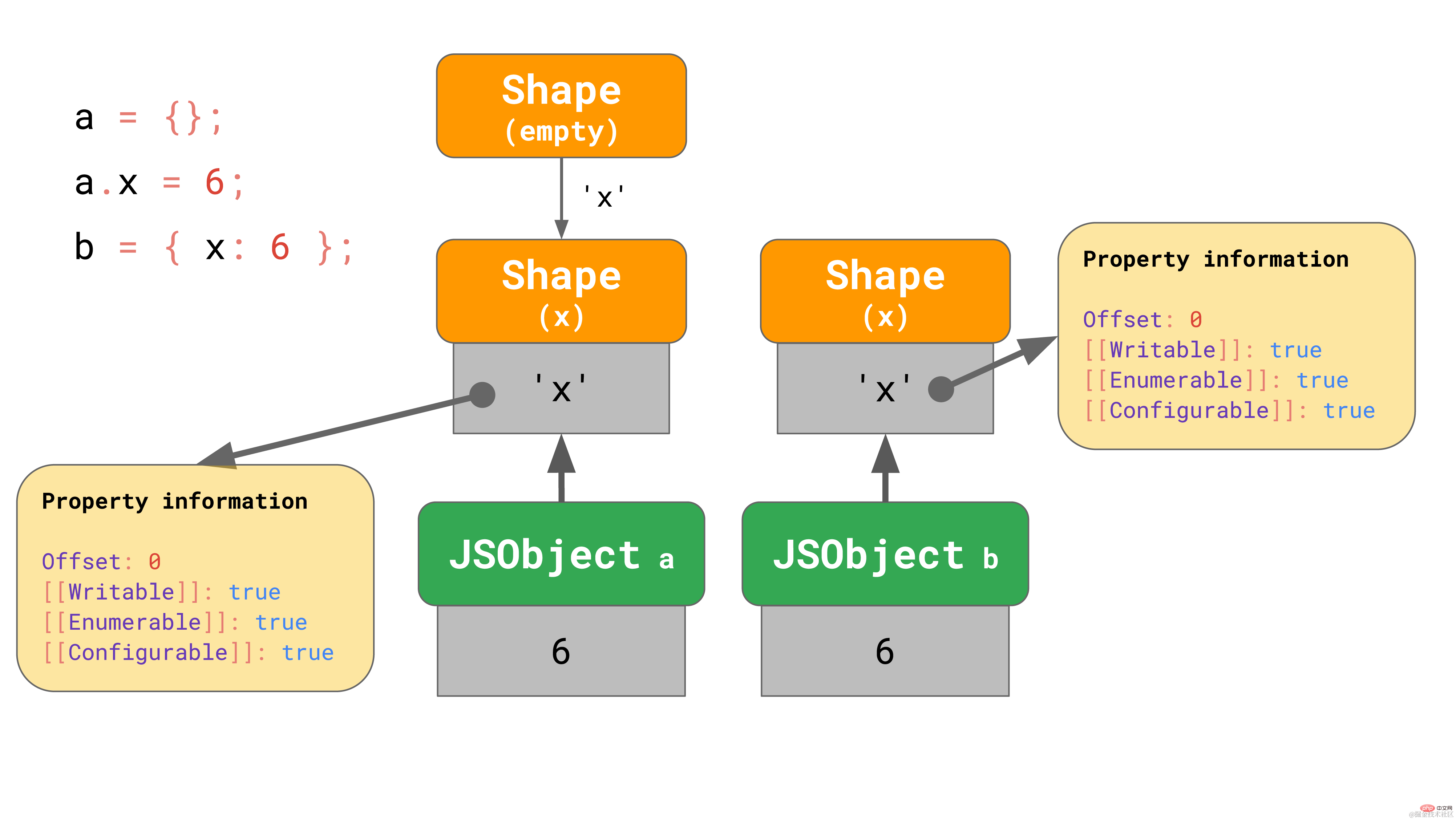
包含属性 ‘x’ 的对象字面量从含有 ‘x’ 的 shape 开始,有效地跳过了空 shape。V8 和 SpiderMonkey (至少)正是这么做的。这种优化缩短了转换链并且使从字面量构建对象更加高效。
下面是一个包含属性 ‘x'、'y' 和 'z' 的 3D 点对象的示例。
const point = {};
point.x = 4;
point.y = 5;
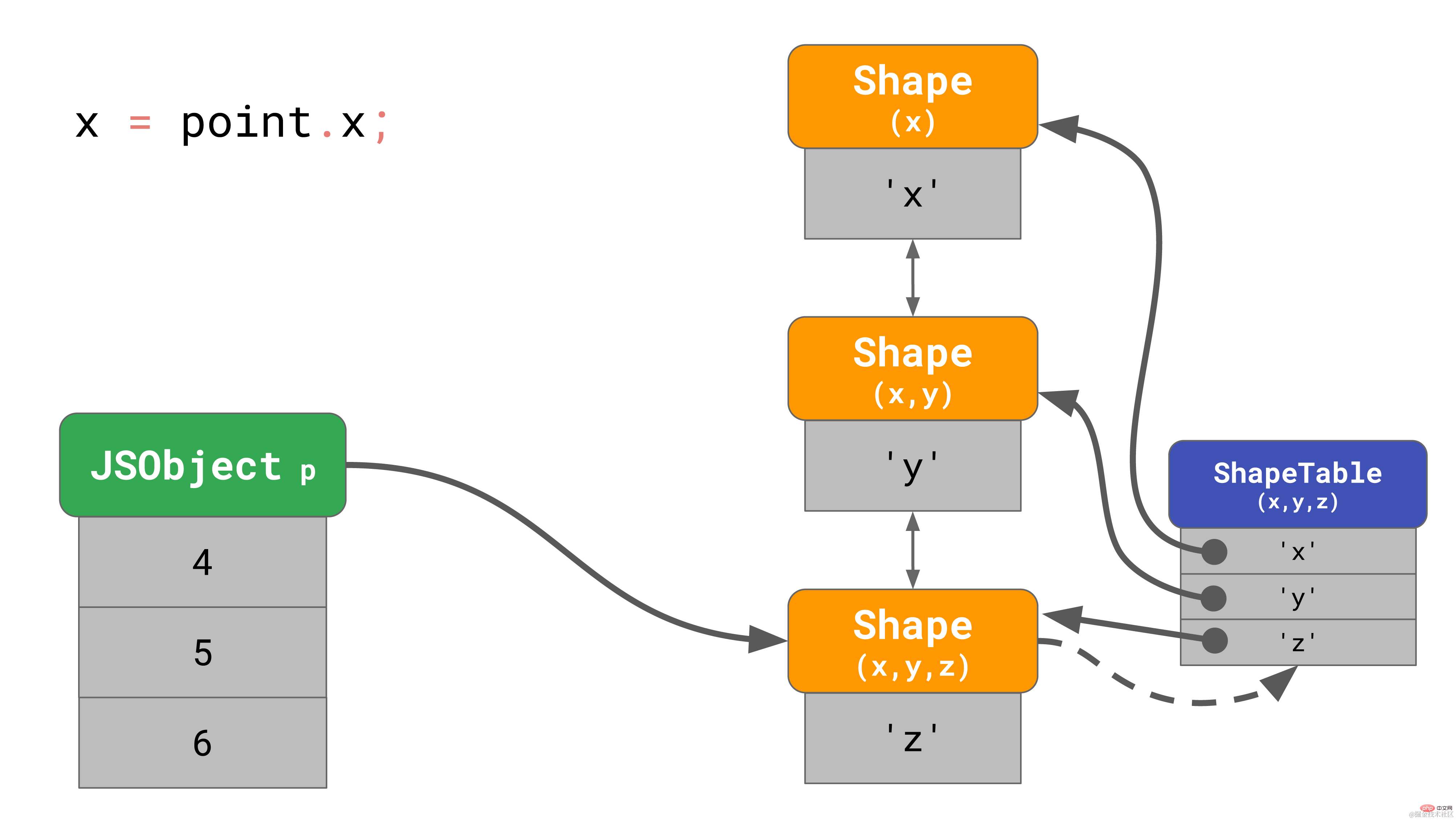
point.z = 6;复制代码正如我们之前所了解的, 这会在内存中创建一个有3个 shape 的对象(不算空 shape 的话)。 当访问该对象的属性 ‘x’ 的时候,比如, 你在程序里写 point.x,javaScript 引擎需要循着链接列表寻找:它会从底部的 shape 开始,一层层向上寻找,直到找到顶部包含 ‘x’ 的 shape。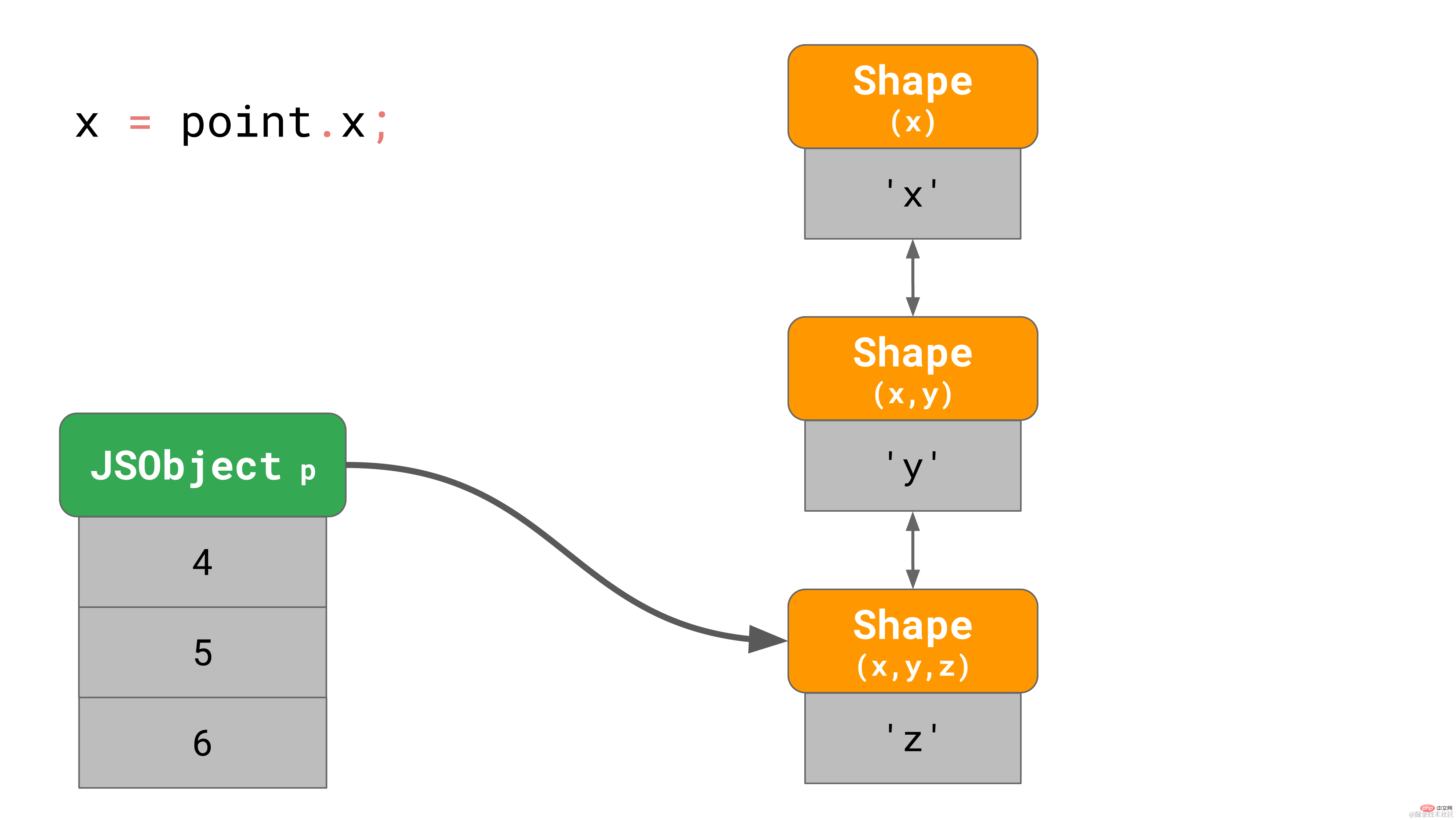
当这样的操作更频繁时, 速度会变得非常慢,特别是当对象有很多属性的时候。寻找属性的时间复杂度为 O(n), 即和对象上的属性数量线性相关。为了加快属性的搜索速度, JavaScript 引擎增加了一种 ShapeTable 的数据结构。这个 ShapeTable 是一个字典,它将属性键映射到描述对应属性的 shape 上。
现在我们又回到字典查找了我们添加 shape 就是为了对此进行优化!那我们为什么要去纠结 shape 呢? 原因是 shape 启用了另一种称为 Inline Caches 的优化。
shapes 背后的主要动机是 Inline Caches 或 ICs 的概念。ICs 是让 JavaScript 快速运行的关键要素!JavaScript 引擎使用 ICs 来存储查找到对象属性的位置信息,以减少昂贵的查找次数。
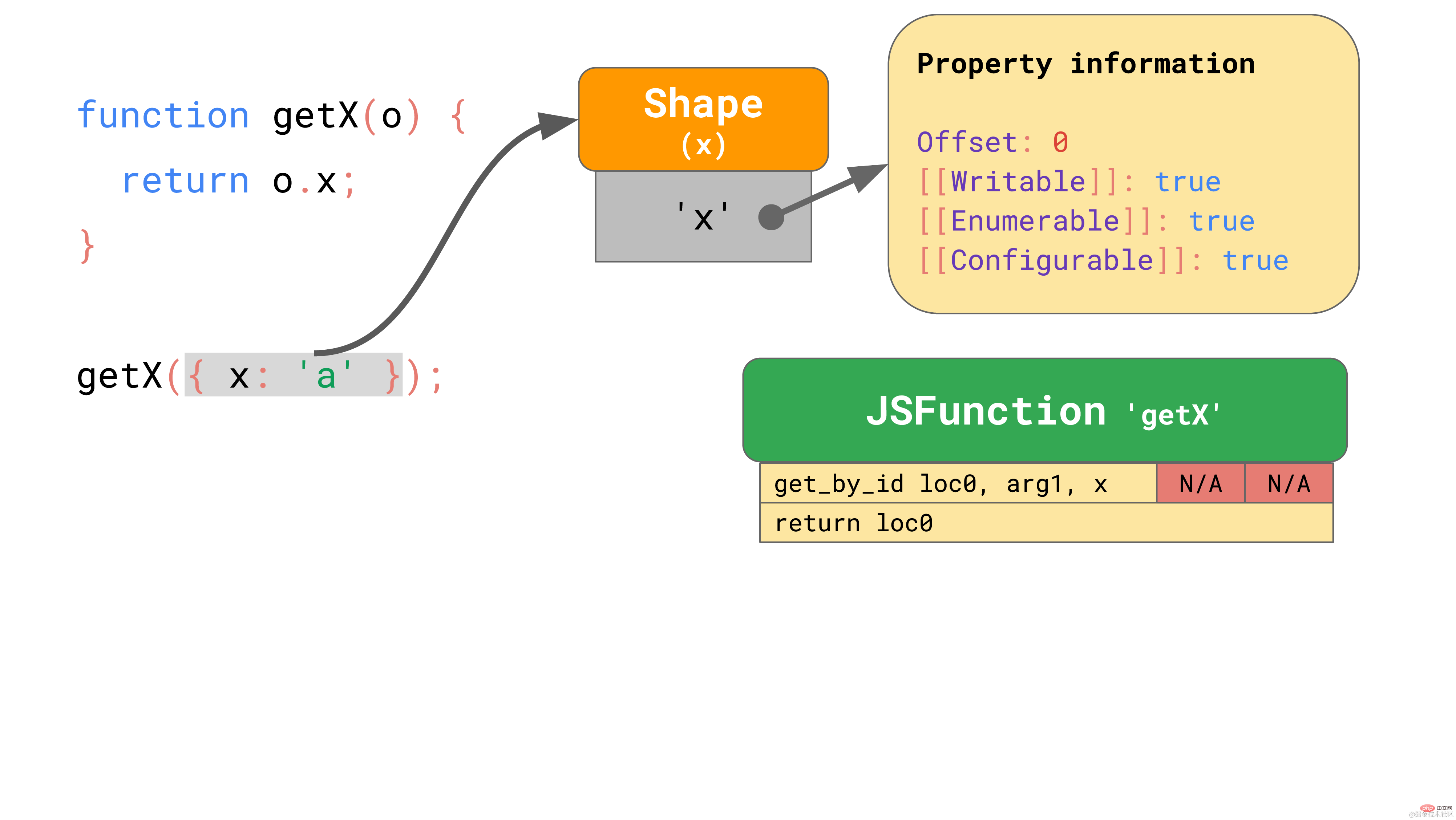
这里有一个函数 getX,该函数接收一个对象并从中加载属性 x:
function getX(o) { return o.x;
}复制代码如果我们在 JSC 中运行该函数,它会产生以下字节码:
第一条 get_by_id 指令从第一个参数(arg1)加载属性 ‘x’,并将结果存储到 loc0 中。第二条指令将存储的内容返回给 loc0。
JSC 还将一个 Inline Cache 嵌入到 get_by_id 指令中,该指令由两个未初始化的插槽组成。
 现在, 我们假设用一个对象 { x: 'a' },来执行 getX 这个函数。正如我们所知,,这个对象有一个包含属性 ‘x’ 的 shape, 该 shape存储了属性 ‘x’ 的偏移量和特性。当你在第一次执行这个函数的时候,get_by_id 指令会查找属性 ‘x’,然后发现其值存储在偏移量为 0 的位置。
现在, 我们假设用一个对象 { x: 'a' },来执行 getX 这个函数。正如我们所知,,这个对象有一个包含属性 ‘x’ 的 shape, 该 shape存储了属性 ‘x’ 的偏移量和特性。当你在第一次执行这个函数的时候,get_by_id 指令会查找属性 ‘x’,然后发现其值存储在偏移量为 0 的位置。
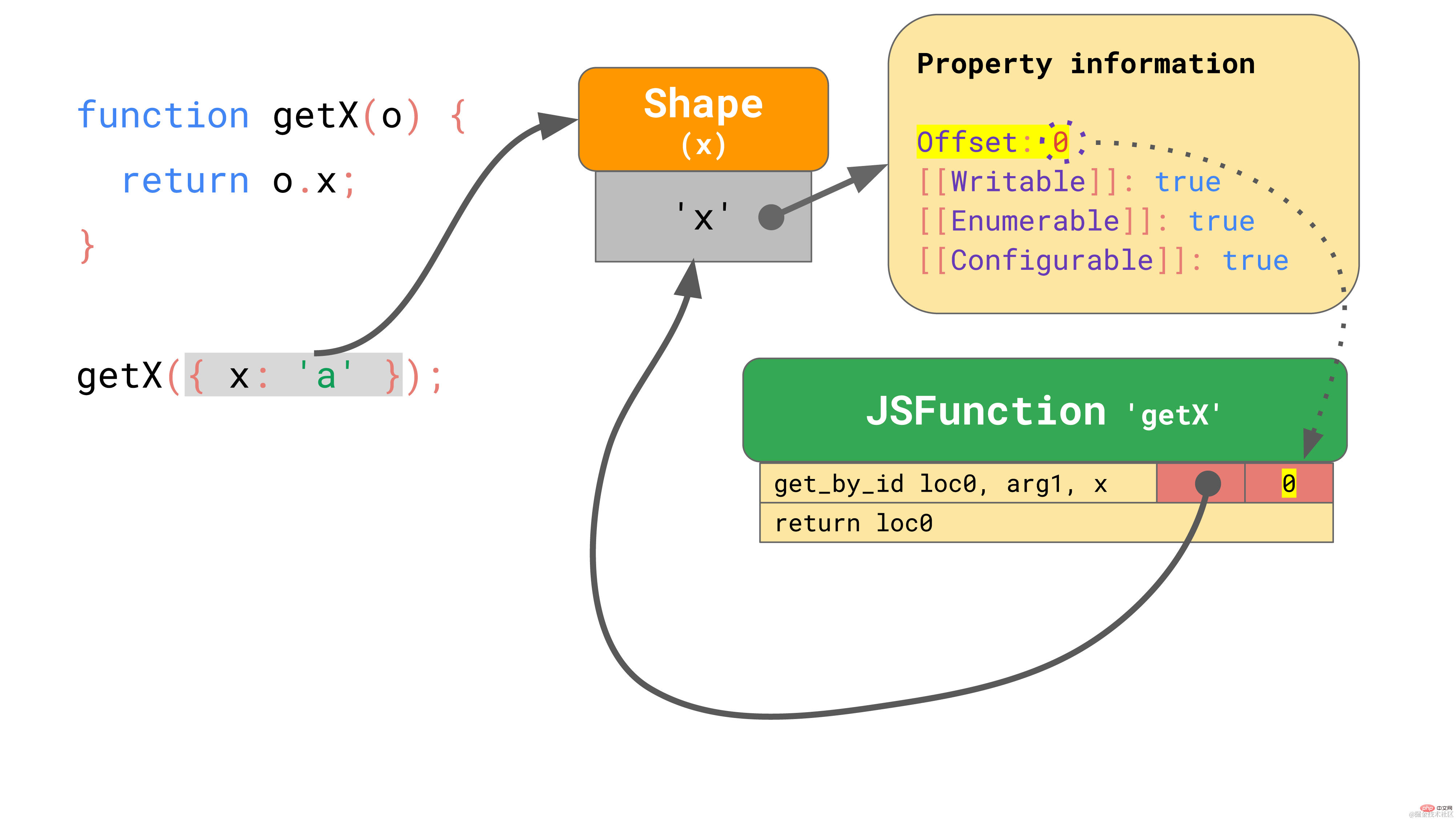
嵌入到 get_by_id 指令中的 IC 存储了 shape 和该属性的偏移量:
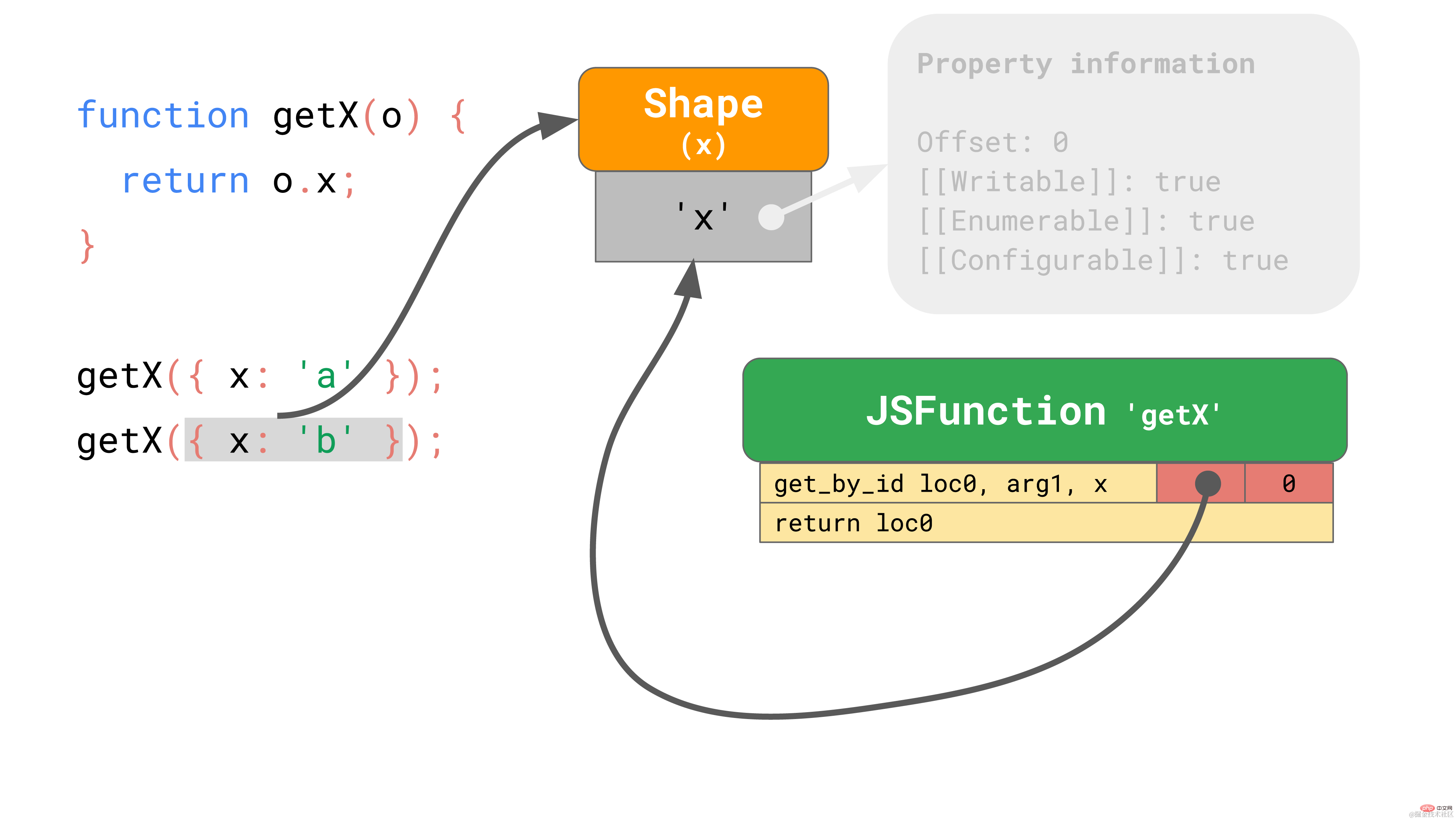
对于后续运行,IC 只需要比较 shape,如果 shape 与之前相同,只需从存储的偏移量加载值。具体来说,如果 JavaScript 引擎看到对象的 shape 是 IC 以前记录过的,那么它根本不需要接触属性信息,相反,可以完全跳过昂贵的属性信息查找过程。这要比每次都查找属性快得多。
对于数组,存储数组索引属性是很常见的。这些属性的值称为数组元素。为每个数组中的每个数组元素存储属性特性是非常浪费内存的。相反,默认情况下,数组索引属性是可写的、可枚举的和可配置的,JavaScript 引擎基于这一点将数组元素与其他命名属性分开存储。
思考下面的数组:
const array = [ '#jsconfeu', ];复制代码
引擎存储了数组长度(1),并指向包含偏移量和 'length' 属性特性的 shape。
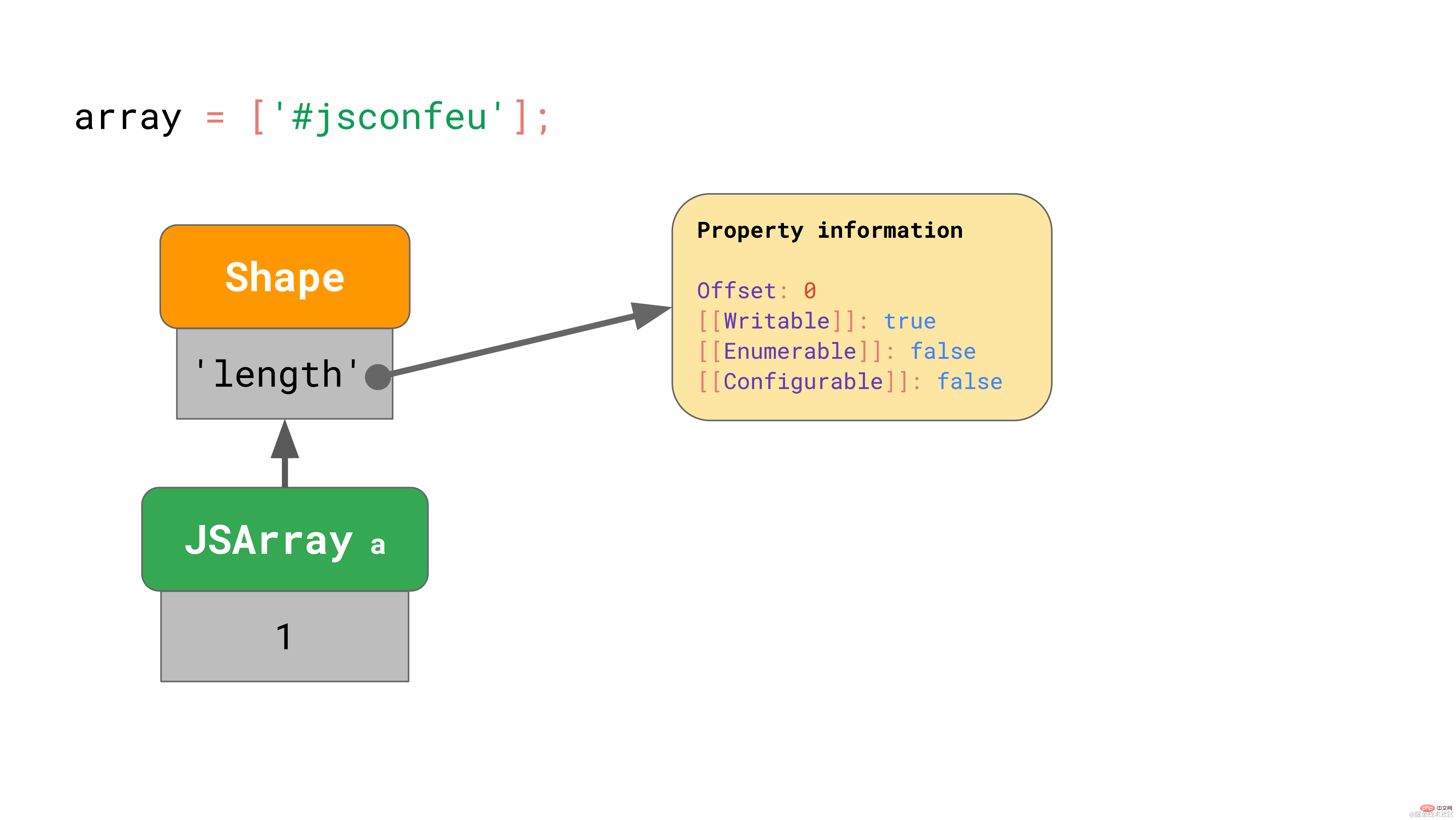
这和我们之前看到的很相似……但是数组的值存到哪里了呢?
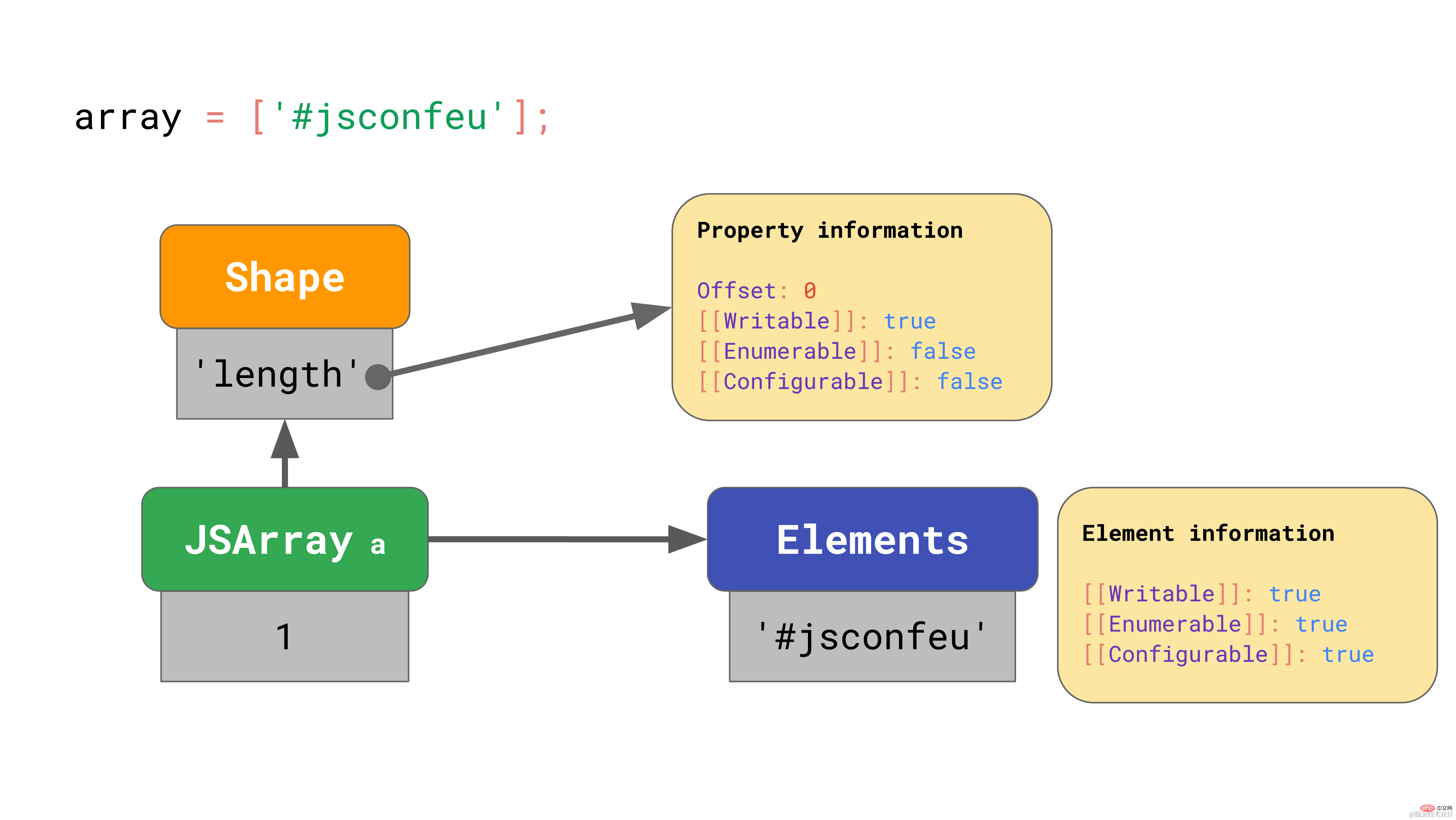
每个数组都有一个单独的元素备份存储区,包含所有数组索引的属性值。JavaScript 引擎不必为数组元素存储任何属性特性,因为它们通常都是可写的、可枚举的和可配置的。
那么,在非通常情况下会怎么样呢?如果更改了数组元素的属性特性,该怎么办?
// Please don’t ever do this!const array = Object.defineProperty(
[], '0',
{
value: 'Oh noes!!1',
writable: false,
enumerable: false,
configurable: false,
});复制代码上面的代码片段定义了名为 “0” 的属性(恰好是数组索引),但将其特性设置为非默认值。
在这种边缘情况下,JavaScript 引擎将整个元素备份存储区表示成一个字典,该字典将数组索引映射到属性特性。
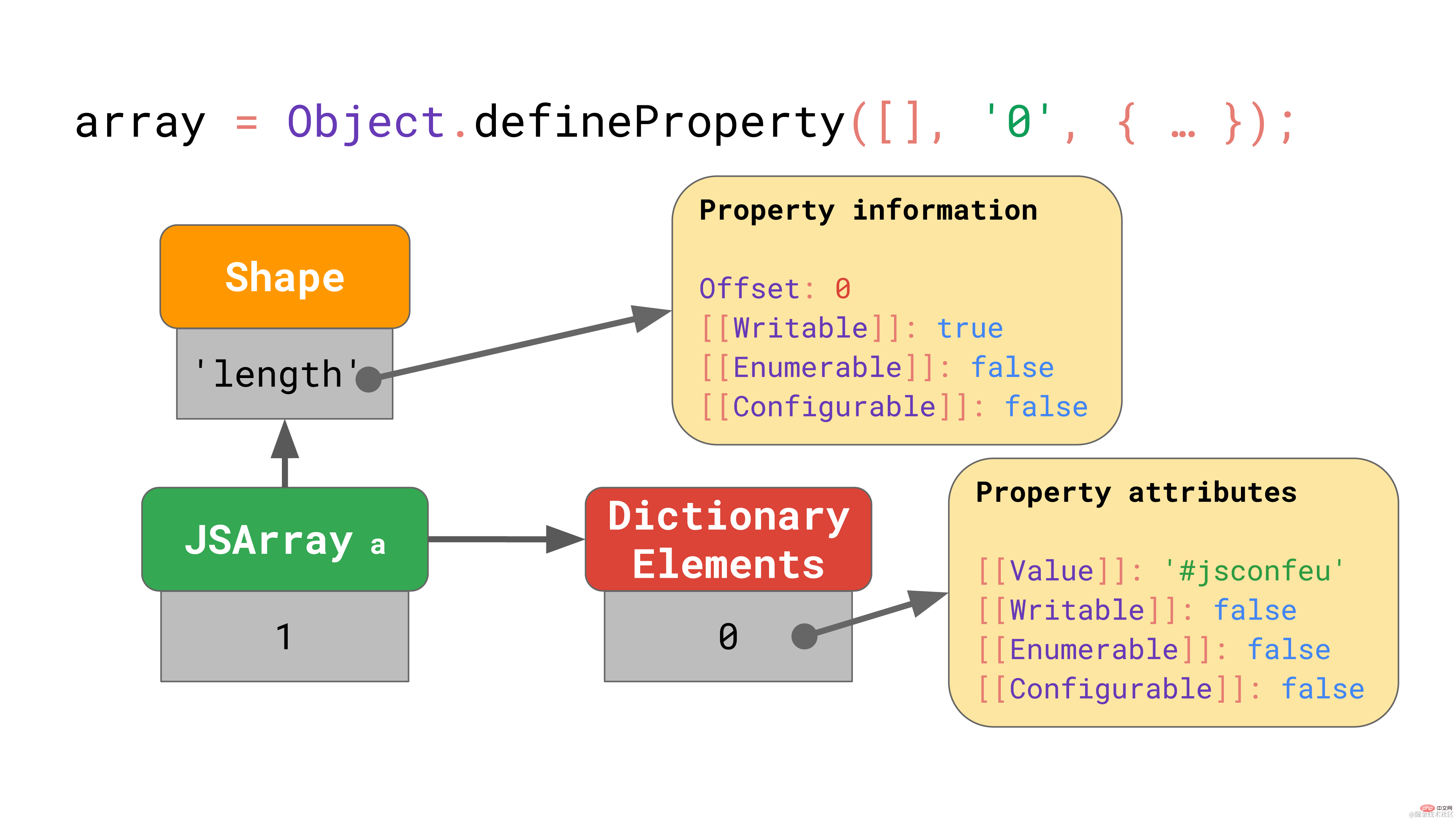
即使只有一个数组元素具有非默认特性,整个数组的备份存储区也会进入这种缓慢而低效的模式。避免对数组索引使用Object.defineProperty!
我们已经了解了 JavaScript 引擎如何存储对象和数组,以及 shape 和 ICs 如何优化对它们的常见操作。基于这些知识,我们确定了一些可以帮助提高性能的实用的 JavaScript 编码技巧:
Recommandations d'apprentissage gratuites associées : javascript(vidéo)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Liste de prix du niveau Douyin 1-75
Liste de prix du niveau Douyin 1-75
 Qu'est-ce que la carte de contrôle d'accès NFC
Qu'est-ce que la carte de contrôle d'accès NFC
 Les photos Windows ne peuvent pas être affichées
Les photos Windows ne peuvent pas être affichées
 Qu'est-ce que le courrier électronique
Qu'est-ce que le courrier électronique
 Quels sont les cinq types de fonctions d'agrégation ?
Quels sont les cinq types de fonctions d'agrégation ?
 Site officiel de Binance
Site officiel de Binance
 Comment faire défiler les images en ppt
Comment faire défiler les images en ppt
 Comment résoudre le problème selon lequel le raccourci IE ne peut pas être supprimé
Comment résoudre le problème selon lequel le raccourci IE ne peut pas être supprimé









![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



