


Le robot d'exploration Web est également appelé araignée Web. Nous pouvons imaginer Internet comme une toile d'araignée, et chaque site Web est un nœud. nous pouvons utiliser une araignée pour récupérer les ressources souhaitées sur chaque page Web. Pour donner l'exemple le plus simple, si vous saisissez « Python » dans Baidu et Google, un grand nombre de pages Web liées à Python seront récupérées. Comment Baidu et Google récupèrent-ils les ressources souhaitées à partir des pages Web massives ? Ce que fait est d'envoyer un grand nombre d'araignées pour explorer la page Web, rechercher des mots-clés, créer une base de données d'index, et après un algorithme de tri complexe, les résultats vous sont affichés en fonction de la pertinence des mots-clés de recherche.
Un voyage de mille kilomètres commence par une seule étape. Apprenons à écrire un robot d'exploration Web à partir des bases et à utiliser Python pour l'implémenter.
Si vous souhaitez écrire un robot d'exploration Web, la première étape consiste à accéder à Internet.
En Python, nous utilisons le package urllib pour accéder à Internet. (En Python3, ce module a été considérablement ajusté. Il y avait urllib et urllib2. En 3, ces deux modules ont été unifiés et fusionnés, appelé le package urllib. Le package contient quatre modules, urllib.request, urllib. erreur, urllib.parse, urllib.robotparser) , actuellement urllib.request est principalement utilisé.
Nous donnons d'abord l'exemple le plus simple, comment obtenir le code source d'une page web :
import urllib.request response = urllib.request.urlopen('https://docs.python.org/3/') html = response.read()print(html.decode('utf-8'))
Tout d'abord, nous utilisons deux petits. démos pour s'entraîner Pour commencer, l'une consiste à utiliser du code python pour télécharger une image en local, et l'autre consiste à appeler Youdao Translation pour écrire un petit logiciel de traduction.
3.1 Téléchargez l'image selon le lien de l'image, le code est le suivant :
import urllib.request
response = urllib.request.urlopen('http://www.3lian.com/e/ViewImg/index.html?url=http://img16.3lian.com/gif2016/w1/3/d/61.jpg')
image = response.read()
with open('123.jpg','wb') as f:
f.write(image)Où la réponse est un objet
Entrée : response.geturl()
->'http://www.3lian.com/e/ViewImg/index.html?url=http://img16.3lian.com/gif2016/w1/ 3/d/61. jpg'
Entrée : response.info()
->
Entrée : print(response.info())
->Content-Type : text/html
Dernière modification : lundi 27 septembre 2004 01:23:20 GMT
Plages acceptées : octets
ETag : "0f4b59230a4c41:0"
Serveur : Microsoft-IIS /8.0 <<>
Date : dim. 14 août 2016 07:16:01 gmt
Connexion : Fermer
Entrée : response.getcode()
- >2003.1 Utiliser le dictionnaire Youdao pour implémenter la fonction de traduction
Nous voulons implémenter la fonction de traduction, nous devons obtenir le lien de demande . Tout d'abord, nous devons accéder à la page d'accueil de Youdao, cliquer sur Traduire, saisir le contenu à traduire dans l'interface de traduction, cliquer sur le bouton Traduire et une demande sera adressée au serveur. Tout ce que nous avons à faire est d'obtenir l'adresse de la demande et. paramètres de requête.
我在此使用谷歌浏览器实现拿到请求地址和请求参数。首先点击右键,点击检查(不同浏览器点击的选项可能不同,同一浏览器的不同版本也可能不同),进入图一所示,从中我们可以拿到请求请求地址和请求参数,在Header中的Form Data中我们可以拿到请求参数。 (图一) 代码段如下: 上述代码执行如下: {"type":"EN2ZH_CN","errorCode":0,"elapsedTime":0,"translateResult":[[{"src":"i love you","tgt":"我爱你"}]],"smartResult":{"type":1,"entries":["","我爱你。"]}} 对于上述结果,我们可以看到是一个json串,我们可以对此解析一下,并且对代码进行完善一下: 服务器检测出请求不是来自浏览器,可能会屏蔽掉请求,服务器判断的依据是使用‘User-Agent',我们可以修改改字段的值,来隐藏自己。代码如下: View Code 上述做法虽然可以隐藏自己,但是还有很大问题,例如一个网络爬虫下载图片软件,在短时间内大量下载图片,服务器可以可以根据IP访问次数判断是否是正常访问。所有上述做法还有很大的问题。我们可以通过两种做法解决办法,一是使用延迟,例如5秒内访问一次。另一种办法是使用代理。 延迟访问(休眠5秒,缺点是访问效率低下): View Code 代理访问:让代理访问资源,然后讲访问到的资源返回。服务器看到的是代理的IP地址,不是自己地址,服务器就没有办法对你做限制。 步骤: 1,参数是一个字典{'类型' : '代理IP:端口号' } //类型是http,https等 proxy_support = urllib.request.ProxyHandler({}) 2,定制、创建一个opener opener = urllib.request.build_opener(proxy_support) 3,安装opener(永久安装,一劳永逸) urllib.request.install_opener(opener) 3,调用opener(调用的时候使用) opener.open(url) 图片下载来源为煎蛋网(http://jandan.net) 图片下载的关键是找到图片的规律,如找到当前页,每一页的图片链接,然后使用循环下载图片。下面是程序代码(待优化,正则表达式匹配,IP代理): 代码运行效果如下: 更多相关免费学习推荐:python视频教程 Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!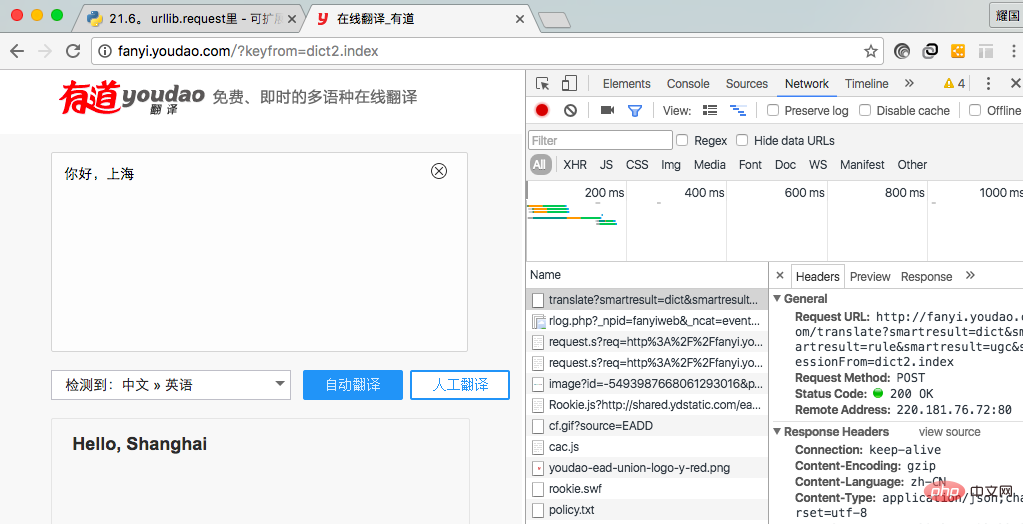
import urllib.requestimport urllib.parse
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=dict2.index'data = {}
data['type'] = 'AUTO'data['i'] = 'i love you'data['doctype'] = 'json'data['xmlVersion'] = '1.8'data['keyfrom'] = 'fanyi.web'data['ue'] = 'UTF-8'data['action'] = 'FY_BY_CLICKBUTTON'data['typoResult'] = 'true'data = urllib.parse.urlencode(data).encode('utf-8')
response = urllib.request.urlopen(url,data)
html = response.read().decode('utf-8')print(html)import urllib.requestimport urllib.parseimport json
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=dict2.index'data = {}
data['type'] = 'AUTO'data['i'] = 'i love you'data['doctype'] = 'json'data['xmlVersion'] = '1.8'data['keyfrom'] = 'fanyi.web'data['ue'] = 'UTF-8'data['action'] = 'FY_BY_CLICKBUTTON'data['typoResult'] = 'true'data = urllib.parse.urlencode(data).encode('utf-8')
response = urllib.request.urlopen(url,data)
html = response.read().decode('utf-8')
target = json.loads(html)print(target['translateResult'][0][0]['tgt'])四、规避风险
import urllib.requestimport urllib.parseimport json
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=dict2.index'data = {}
data['type'] = 'AUTO'data['i'] = 'i love you'data['doctype'] = 'json'data['xmlVersion'] = '1.8'data['keyfrom'] = 'fanyi.web'data['ue'] = 'UTF-8'data['action'] = 'FY_BY_CLICKBUTTON'data['typoResult'] = 'true'data = urllib.parse.urlencode(data).encode('utf-8')
req = urllib.request.Request(url, data)
req.add_header('User-Agent','Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36')
response = urllib.request.urlopen(url, data)
html = response.read().decode('utf-8')
target = json.loads(html)print(target['translateResult'][0][0]['tgt'])import urllib.requestimport urllib.parseimport jsonimport timewhile True:
content = input('please input content(input q exit program):') if content == 'q': break;
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=dict2.index'
data = {}
data['type'] = 'AUTO'
data['i'] = content
data['doctype'] = 'json'
data['xmlVersion'] = '1.8'
data['keyfrom'] = 'fanyi.web'
data['ue'] = 'UTF-8'
data['action'] = 'FY_BY_CLICKBUTTON'
data['typoResult'] = 'true'
data = urllib.parse.urlencode(data).encode('utf-8')
req = urllib.request.Request(url, data)
req.add_header('User-Agent','Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36')
response = urllib.request.urlopen(url, data)
html = response.read().decode('utf-8')
target = json.loads(html) print(target['translateResult'][0][0]['tgt'])
time.sleep(5)五、批量下载网络图片
import urllib.requestimport osdef url_open(url):
req = urllib.request.Request(url)
req.add_header('User-Agent','Mozilla/5.0')
response = urllib.request.urlopen(req)
html = response.read() return htmldef get_page(url):
html = url_open(url).decode('utf-8')
a = html.find('current-comment-page') + 23
b = html.find(']',a) return html[a:b]def find_image(url):
html = url_open(url).decode('utf-8')
image_addrs = []
a = html.find('img src=') while a != -1:
b = html.find('.jpg',a,a + 150) if b != -1:
image_addrs.append(html[a+9:b+4]) else:
b = a + 9
a = html.find('img src=',b) for each in image_addrs: print(each) return image_addrsdef save_image(folder,image_addrs): for each in image_addrs:
filename = each.split('/')[-1]
with open(filename,'wb') as f:
img = url_open(each)
f.write(img)def download_girls(folder = 'girlimage',pages = 20):
os.mkdir(folder)
os.chdir(folder)
url = 'http://jandan.net/ooxx/'
page_num = int(get_page(url)) for i in range(pages):
page_num -= i
page_url = url + 'page-' + str(page_num) + '#comments'
image_addrs = find_image(page_url)
save_image(folder,image_addrs)if __name__ == '__main__':
download_girls()

















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



