

La colonne tutoriel mysql d'aujourd'hui vous présentera les règles d'optimisation d'index de MySQL.

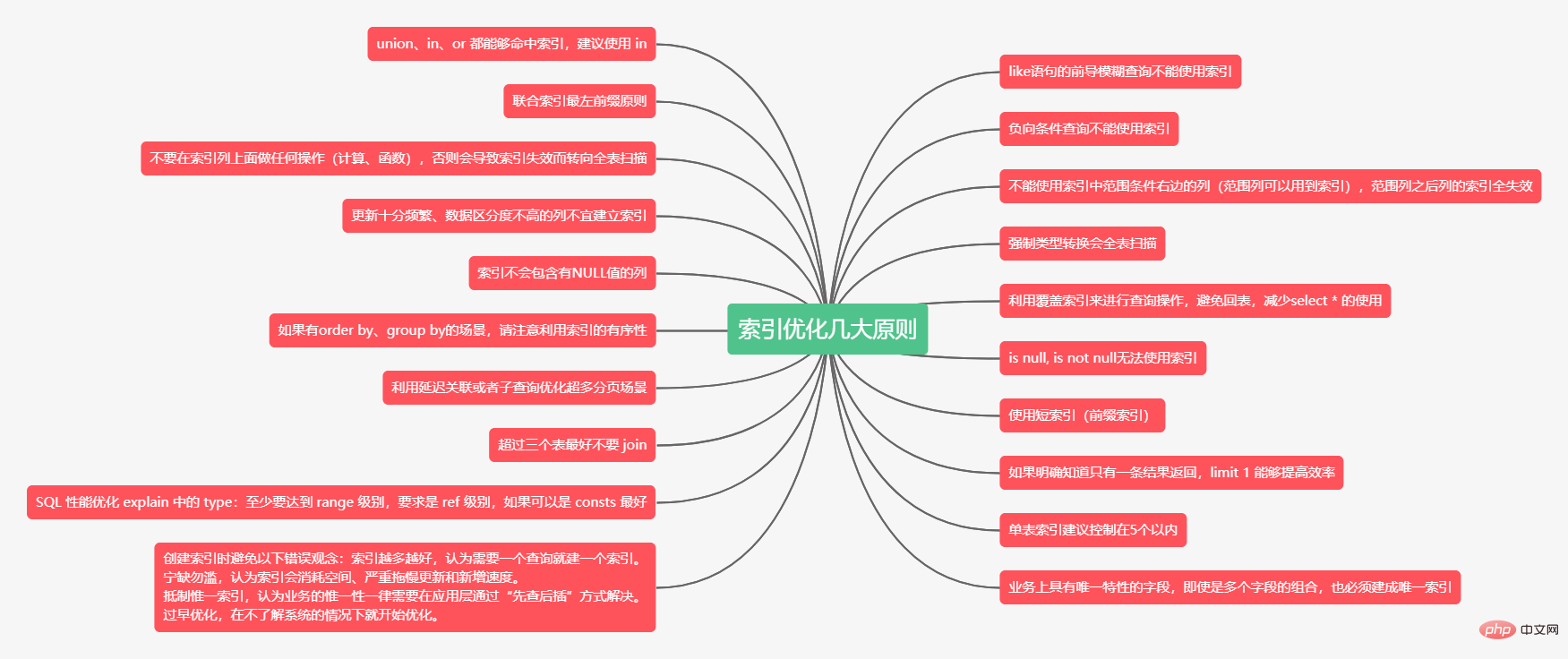
select * from doc where title like '%XX'; --不能使用索引select * from doc where title like 'XX%'; --非前导模糊查询,可以使用索引复制代码
union qui peut atteindre l'index et MySQL consomme le moins. Processeur. select * from doc where status=1union allselect * from doc where status=2;复制代码
in peut atteindre l'index. L'optimisation des requêtes consomme plus de CPU que union all, mais elle peut être ignorée en général, il est recommandé d'utiliser in. select * from doc where status in (1, 2);复制代码
or La nouvelle version de MySQL peut atteindre l'index. L'optimisation des requêtes consomme plus de CPU que in L'utilisation fréquente de or n'est pas recommandée. select * from doc where status = 1 or status = 2复制代码
where est utilisé dans la condition or, l'index deviendra invalide et provoquera une analyse complète de la table. Il s'agit d'un malentendu : ①Tous les champs utilisés dans la clause where doivent être indexés
②Si la quantité de données ; est trop petit, mysql Lors de la formulation du plan d'exécution, il a été constaté qu'une analyse complète de la table est plus rapide qu'une recherche d'index, donc l'index ne sera pas utilisé
③ Assurez-vous que le La version de MySQL est 5.0 ou supérieure, et l'optimiseur de requêtes est activé index_merge_union=on , c'est-à-dire que optimizer_switch existe dans la variable index_merge_union et est on.
Les conditions négatives incluent : !=, , not in, not exists, not like etc.
Par exemple, l'instruction SQL suivante :
select * from doc where status != 1 and status != 2;复制代码
select * from doc where status in (0,3,4);复制代码
Si un index conjoint est établi sur les trois champs de (a,b,c), alors il créera automatiquement un a(a,b) | (a,b,c) indice du groupe .
Connectez-vous aux exigences commerciales, l'instruction SQL est la suivante :
select uid, login_time from user where login_name=? andpasswd=?复制代码
(login_name, passwd)的联合索引。因为业务上几乎没有passwd 的单条件查询需求,而有很多login_name 的单条件查询需求,所以可以建立(login_name, passwd)的联合索引,而不是(passwd, login_name)。
- 建立联合索引的时候,区分度最高的字段在最左边
- 存在非等号和等号混合判断条件时,在建立索引时,把等号条件的列前置。如
where a>? and b=?,那么即使a的区分度更高,也必须把b放在索引的最前列。
- 最左前缀查询时,并不是指SQL语句的where顺序要和联合索引一致。
(login_name, passwd) 这个联合索引:select uid, login_time from user where passwd=? andlogin_name=?复制代码
where 后的顺序和联合索引一致,养成好习惯。
- 假如
index(a,b,c),where a=3 and b like 'abc%' and c=4,a能用,b能用,c不能用。
、>=、between等。(empno、title、fromdate),那么下面的 SQL 中 emp_no 可以用到索引,而title 和 from_date 则使用不到索引。select * from employees.titles where emp_no <h3 data-id="heading-7">6、不要在索引列上面做任何操作(计算、函数),否则会导致索引失效而转向全表扫描</h3>
date 上建立了索引,也会全表扫描:select * from doc where YEAR(create_time)
select * from doc where create_time
select * from order where date
select * from order where date <h3 data-id="heading-8">7、强制类型转换会全表扫描</h3>
phone 字段是 varchar 类型,则下面的 SQL 不能命中索引。select * from user where phone=13800001234复制代码
select * from user where phone='13800001234';复制代码
更新会变更 B+ 树,更新频繁的字段建立索引会大大降低数据库性能。
“性别”这种区分度不大的属性,建立索引是没有什么意义的,不能有效过滤数据,性能与全表扫描类似。
一般区分度在80%以上的时候就可以建立索引,区分度可以使用 count(distinct(列名))/count(*) 来计算。
Select uid, login_time from user where login_name=? and passwd=?复制代码
(login_name, passwd, login_time)的联合索引,由于 login_time 已经建立在索引中了,被查询的 uid 和 login_time 就不用去 row 上获取数据了,从而加速查询。NULL值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时,尽量使用not null 约束以及默认值。order by 最后的字段是组合索引的一部分,并且放在索引组合顺序的最后,避免出现file_sort 的情况,影响查询性能。where a=? and b=? order by c,可以建立联合索引(a,b,c)。 WHERE a>10 ORDER BY b;,索引(a,b)无法排序。对列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个CHAR(255)的列,如果该列在前10个或20个字符内,可以做到既使得前缀索引的区分度接近全列索引,那么就不要对整个列进行索引。因为短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作,减少索引文件的维护开销。可以使用count(distinct leftIndex(列名, 索引长度))/count(*) 来计算前缀索引的区分度。
但缺点是不能用于 ORDER BY 和 GROUP BY 操作,也不能用于覆盖索引。
不过很多时候没必要对全字段建立索引,根据实际文本区分度决定索引长度即可。
offset 行,而是取 offset+N 行,然后返回放弃前 offset 行,返回 N 行,那当 offset 特别大的时候,效率就非常的低下,要么控制返回的总页数,要么对超过特定阈值的页数进行 SQL 改写。id段,然后再关联:selecta.* from 表1 a,(select id from 表1 where 条件 limit100000,20 ) b where a.id=b.id;复制代码
select * from user where login_name=?;复制代码
select * from user where login_name=? limit 1复制代码
需要 join 的字段,数据类型必须一致,多表关联查询时,保证被关联的字段需要有索引。
例如:left join是由左边决定的,左边的数据一定都有,所以右边是我们的关键点,建立索引要建右边的。当然如果索引在左边,可以用right join。
consts:单表中最多只有一个匹配行(主键或者唯一索引),在优化阶段即可读取到数据。
ref:使用普通的索引(Normal Index)。
range:对索引进行范围检索。
当 type=index 时,索引物理文件全扫,速度非常慢。
insert 速度,这个速度损耗可以忽略,但提高查找速度是明显的。另外,即使在应用层做了非常完善的校验控制,只要没有唯一索引,根据墨菲定律,必然有脏数据产生。既然索引可以加快查询速度,那么是不是只要是查询语句需要,就建上索引?答案是否定的。因为索引虽然加快了查询速度,但索引也是有代价的:索引文件本身要消耗存储空间,同时索引会加重插入、删除和修改记录时的负担,另外,MySQL在运行时也要消耗资源维护索引,因此索引并不是越多越好。一般两种情况下不建议建索引。
第一种情况是表记录比较少,例如一两千条甚至只有几百条记录的表,没必要建索引,让查询做全表扫描就好了。至于多少条记录才算多,这个个人有个人的看法,我个人的经验是以2000作为分界线,记录数不超过 2000可以考虑不建索引,超过2000条可以酌情考虑索引。
另一种不建议建索引的情况是索引的选择性较低。所谓索引的选择性(Selectivity),是指不重复的索引值(也叫基数,Cardinality)与表记录数(#T)的比值:
Index Selectivity = Cardinality / #T复制代码
(0, 1]``,选择性越高的索引价值越大,这是由B+Tree的性质决定的。例如,employees.titles表,如果title`字段经常被单独查询,是否需要建索引,我们看一下它的选择性:SELECT count(DISTINCT(title))/count(*) AS Selectivity FROM employees.titles; +-------------+| Selectivity | +-------------+| 0.0000 | +-------------+复制代码
title的选择性不足0.0001(精确值为0.00001579),所以实在没有什么必要为其单独建索引。
有一种与索引选择性有关的索引优化策略叫做前缀索引,就是用列的前缀代替整个列作为索引key,当前缀长度合适时,可以做到既使得前缀索引的选择性接近全列索引,同时因为索引key变短而减少了索引文件的大小和维护开销。下面以employees.employees表为例介绍前缀索引的选择和使用。
假设employees表只有一个索引
EXPLAIN SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido'; +----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+| 1 | SIMPLE | employees | ALL | NULL | NULL | NULL | NULL | 300024 | Using where | +----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+复制代码
<first_name></first_name>或<first_name last_name></first_name>,看下两个索引的选择性:SELECT count(DISTINCT(first_name))/count(*) AS Selectivity FROM employees.employees; +-------------+| Selectivity | +-------------+| 0.0042 | +-------------+SELECT count(DISTINCT(concat(first_name, last_name)))/count(*) AS Selectivity FROM employees.employees; +-------------+| Selectivity | +-------------+| 0.9313 | +-------------+复制代码
<first_name></first_name>显然选择性太低,`<first_name last_name></first_name>选择性很好,但是first_name和last_name加起来长度为30,有没有兼顾长度和选择性的办法?可以考虑用first_name和last_name的前几个字符建立索引,例如<first_name left></first_name>,看看其选择性:SELECT count(DISTINCT(concat(first_name, left(last_name, 3))))/count(*) AS Selectivity FROM employees.employees; +-------------+ | Selectivity | +-------------+ | 0.7879 | +-------------+复制代码
SELECT count(DISTINCT(concat(first_name, left(last_name, 4))))/count(*) AS Selectivity FROM employees.employees; +-------------+| Selectivity | +-------------+| 0.9007 | +-------------+复制代码
18,比<first_name last_name></first_name>短了接近一半,我们把这个前缀索引建上:ALTER TABLE employees.employees ADD INDEX `first_name_last_name4` (first_name, last_name(4));复制代码
SHOW PROFILES; +----------+------------+---------------------------------------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+---------------------------------------------------------------------------------+ | 87 | 0.11941700 | SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido' | | 90 | 0.00092400 | SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido' | +----------+------------+---------------------------------------------------------------------------------+复制代码
性能的提升是显著的,查询速度提高了120多倍。
前缀索引兼顾索引大小和查询速度,但是其缺点是不能用于ORDER BY和GROUP BY操作,也不能用于Covering index(即当索引本身包含查询所需全部数据时,不再访问数据文件本身)。
本篇文章脑图和PDF文档已经准备好,有需要的伙伴可以回复关键词索引优化获取。
Plus de recommandations d'apprentissage gratuites associées : tutoriel mysql(vidéo)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié







![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



