


La différence entre ==, égal et hashCode en java
(plus de recommandations de questions d'entretien : questions et réponses d'entretien Java)
Les types de données en Java peuvent être divisés en deux catégories :
Types de données de base, également appelés types de données primitifs. Pour comparer byte, short, char, int, long, float, double, boolean, utilisez le double signe égal (==) et comparez leurs valeurs.
Type de référence (classe, interface, tableau) Lorsqu'ils comparent en utilisant (==), ils comparent leurs adresses de stockage en mémoire. Par conséquent, à moins qu'il ne s'agisse du même nouvel objet, le résultat de leur comparaison est vrai, sinon le résultat de la comparaison est faux. Les objets sont placés sur le tas et la référence (adresse) de l'objet est stockée sur la pile. Regardez d'abord la carte mémoire et le code de la machine virtuelle :
public class testDay {
public static void main(String[] args) {
String s1 = new String("11");
String s2 = new String("11");
System.out.println(s1 == s2);
System.out.println(s1.equals(s2));
}
}Le résultat est :
false
true

s1 et s2 stockent respectivement les adresses des objets correspondants. Par conséquent, si s1== s2 est utilisé, les valeurs d'adresse des deux objets sont comparées (c'est-à-dire si les références sont les mêmes), ce qui est faux. Lors de l'appel dans le sens égal, la valeur dans l'adresse correspondante est comparée, la valeur est donc vraie. Ici, nous devons décrire equals() en détail.
La méthode equals() est utilisée pour déterminer si d'autres objets sont égaux à cet objet. Il est défini dans Object, donc tout objet a la méthode equals(). La différence est de savoir si la méthode est remplacée ou non.
Regardez d'abord le code source :
public boolean equals(Object obj) { return (this == obj);
}Évidemment, Object définit une comparaison des valeurs d'adresse de deux objets (c'est-à-dire comparer si les références sont les mêmes). Mais pourquoi l'appel d'equals() dans String ne compare-t-il pas l'adresse mais la valeur dans l'adresse de la mémoire tas ? Voici le point clé. Lorsque des classes d'encapsulation telles que String, Math, Integer, Double, etc. utilisent la méthode Equals(), elles ont déjà couvert la méthode Equals() de la classe d'objet. Jetez un œil à la fonction equals() réécrite dans String :
public boolean equals(Object anObject) { if (this == anObject) { return true;
} if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length; if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0; while (n-- != 0) { if (v1[i] != v2[i]) return false;
i++;
} return true;
}
} return false;
}Après la réécriture, il s'agit de la comparaison de contenu, et ce n'est plus la comparaison d'adresse précédente. Par analogie, les classes telles que Math, Integer, Double, etc. remplacent toutes la méthode equals() pour comparer les contenus. Bien entendu, les types de base effectuent des comparaisons de valeurs.
Il convient de noter que lorsque la méthode equals() est remplacée, hashCode() sera également remplacée. Selon l'implémentation de la méthode générale hashCode(), les objets égaux doivent avoir des codes de hachage égaux. Pourquoi en est-il ainsi ? Nous mentionnons ici brièvement le hashcode.
Il s'agit évidemment de la différence entre ==, égal et hashCode en Java, mais pourquoi est-il soudainement lié à hashcode(). Vous devez être très déprimé, d'accord, laissez-moi vous donner un exemple simple et vous saurez pourquoi hashCode est impliqué lorsque == ou égal.
Par exemple : Si vous souhaitez savoir si une collection contient un objet, comment devez-vous écrire le programme ? Si vous n'utilisez pas la méthode indexOf, parcourez simplement la collection et comparez si vous y pensez. Et s’il y avait 10 000 éléments dans la collection, ce serait fatiguant, non ? Par conséquent, afin d’améliorer l’efficacité, un algorithme de hachage a été créé. L'idée principale est de diviser la collection en plusieurs zones de stockage (peuvent être considérées comme des compartiments). Chaque objet peut calculer un code de hachage et peut être regroupé en fonction du code de hachage. un objet peut être regroupé selon le hash code. Son hash code peut être divisé en différentes zones de stockage (différentes zones).
Ainsi, lors de la comparaison d'éléments, le hashcode est en fait comparé en premier s'ils sont égaux, la méthode égale est comparée.
Regardez le diagramme du hashcode :

Un objet a généralement une clé et une valeur, et sa valeur hashCode peut être calculée en fonction de la clé, il est ensuite stocké dans différentes zones de stockage en fonction de sa valeur hashCode, comme indiqué ci-dessus. Différentes zones peuvent stocker plusieurs valeurs car des conflits de hachage sont impliqués. Simple : si le hashCode de deux objets différents est le même, ce phénomène est appelé conflit de hachage. En termes simples, cela signifie que le hashCode est le même mais que l'égalité est une valeur différente. Pour comparer 10 000 éléments, il n'est pas nécessaire de parcourir toute la collection. Il suffit de calculer le hashCode de la clé de l'objet que vous souhaitez rechercher, puis de trouver la zone de stockage correspondant au hashCode. La recherche est terminée.

大概可以知道,先通过hashcode来比较,如果hashcode相等,那么就用equals方法来比较两个对象是否相等。再重写了equals最好把hashCode也重写。其实这是一条规范,如果不这样做程序也可以执行,只不过会隐藏bug。一般一个类的对象如果会存储在HashTable,HashSet,HashMap等散列存储结构中,那么重写equals后最好也重写hashCode。
总结:
byte 是 字节
bit 是 位
1 byte = 8 bit
char在java中是2个字节,java采用unicode,2个字节来表示一个字符
short 2个字节
int 4个字节
long 8个字节
float 4个字节
double 8个字节
延伸: 关于Integer和int的比较
Integer i = new Integer(100); Integer j = new Integer(100); System.out.print(i == j); //false
Integer i = new Integer(100); int j = 100; System.out.print(i == j); //true
Integer i = new Integer(100); Integer j = 100; System.out.print(i == j); //false
Integer i = 100; Integer j = 100; System.out.print(i == j); //true
Integer i = 128; Integer j = 128; System.out.print(i == j); //false
对于第4条的原因: java在编译Integer i = 100 ;时,会翻译成为Integer i = Integer.valueOf(100);,而java API中对Integer类型的valueOf的定义如下:
public static Integer valueOf(int i){
assert IntegerCache.high >= 127; if (i >= IntegerCache.low && i <p>java对于-128到127之间的数,会进行缓存,Integer i = 127时,会将127进行缓存,下次再写Integer j = 127时,就会直接从缓存中取,就不会new了</p><h2 class="heading" data-id="heading-6">4. java多态的理解</h2><h3 class="heading" data-id="heading-7">1.多态概述</h3><ol>
<li><p>多态是继封装、继承之后,面向对象的第三大特性。</p></li>
<li><p>多态现实意义理解:</p></li>
</ol>现实事物经常会体现出多种形态,如学生,学生是人的一种,则一个具体的同学张三既是学生也是人,即出现两种形态。
Java作为面向对象的语言,同样可以描述一个事物的多种形态。如Student类继承了Person类,一个Student的对象便既是Student,又是Person。
多态体现为父类引用变量可以指向子类对象。
前提条件:必须有子父类关系。
注意:在使用多态后的父类引用变量调用方法时,会调用子类重写后的方法。
定义格式:父类类型 变量名=new 子类类型();
Fu f=new Zi();
System.out.println(f.num);//f是Fu中的值,只能取到父中的值
Fu f1=new Zi();
System.out.println(f1.show());//f1的门面类型是Fu,但实际类型是Zi,所以调用的是重写后的方法。
作用:用来判断某个对象是否属于某种数据类型。
* 注意: 返回类型为布尔类型
使用案例:
Fu f1=new Zi();
Fu f2=new Son();if(f1 instanceof Zi){
System.out.println("f1是Zi的类型");
}else{
System.out.println("f1是Son的类型");
}多态的转型分为向上转型和向下转型两种
向上转型:多态本身就是向上转型过的过程
使用格式:父类类型 变量名=new 子类类型();
适用场景:当不需要面对子类类型时,通过提高扩展性,或者使用父类的功能就能完成相应的操作。
向下转型:一个已经向上转型的子类对象可以使用强制类型转换的格式,将父类引用类型转为子类引用各类型
使用格式:子类类型 变量名=(子类类型)父类类型的变量;
适用场景:当要使用子类特有功能时。
例1:
package day0524;
public class demo04 {
public static void main(String[] args) {
People p=new Stu();
p.eat();
//调用特有的方法
Stu s=(Stu)p;
s.study();
//((Stu) p).study();
}
}
class People{
public void eat(){
System.out.println("吃饭");
}
}
class Stu extends People{
@Override
public void eat(){
System.out.println("吃水煮肉片");
}
public void study(){
System.out.println("好好学习");
}
}
class Teachers extends People{
@Override
public void eat(){
System.out.println("吃樱桃");
}
public void teach(){
System.out.println("认真授课");
}
}答案:吃水煮肉片 好好学习
例2:
请问题目运行结果是什么?
package day0524;
public class demo1 {
public static void main(String[] args) {
A a=new A();
a.show();
B b=new B();
b.show();
}
}
class A{
public void show(){
show2();
}
public void show2(){
System.out.println("A");
}
}
class B extends A{
public void show2(){
System.out.println("B");
}
}
class C extends B{
public void show(){
super.show();
}
public void show2(){
System.out.println("C");
}
}答案:A B
StringBuffer和StringBuilder区别
将一个类定义在另一个类里面或者一个方法里面,这样的类称为内部类。
成员内部类 成员内部类可以无条件访问外部类的所有成员属性和成员方法(包括private成员和静态成员)。 当成员内部类拥有和外部类同名的成员变量或者方法时,会发生隐藏现象,即默认情况下访问的是成员内部类的成员。
局部内部类 局部内部类是定义在一个方法或者一个作用域里面的类,它和成员内部类的区别在于局部内部类的访问仅限于方法内或者该作用域内。
匿名内部类 匿名内部类就是没有名字的内部类
静态内部类 指被声明为static的内部类,他可以不依赖内部类而实例,而通常的内部类需要实例化外部类,从而实例化。静态内部类不可以有与外部类有相同的类名。不能访问外部类的普通成员变量,但是可以访问静态成员变量和静态方法(包括私有类型) 一个 静态内部类去掉static 就是成员内部类,他可以自由的引用外部类的属性和方法,无论是静态还是非静态。但是不可以有静态属性和方法
(学习视频推荐:java课程)
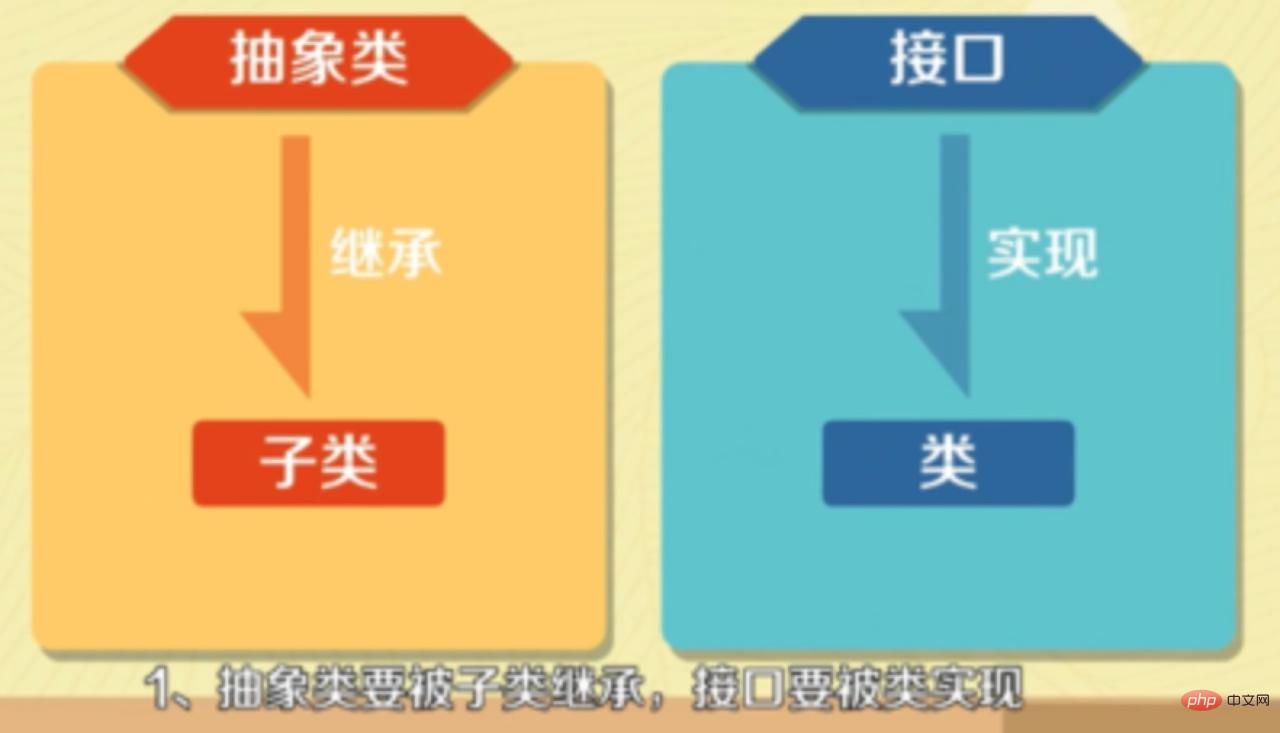
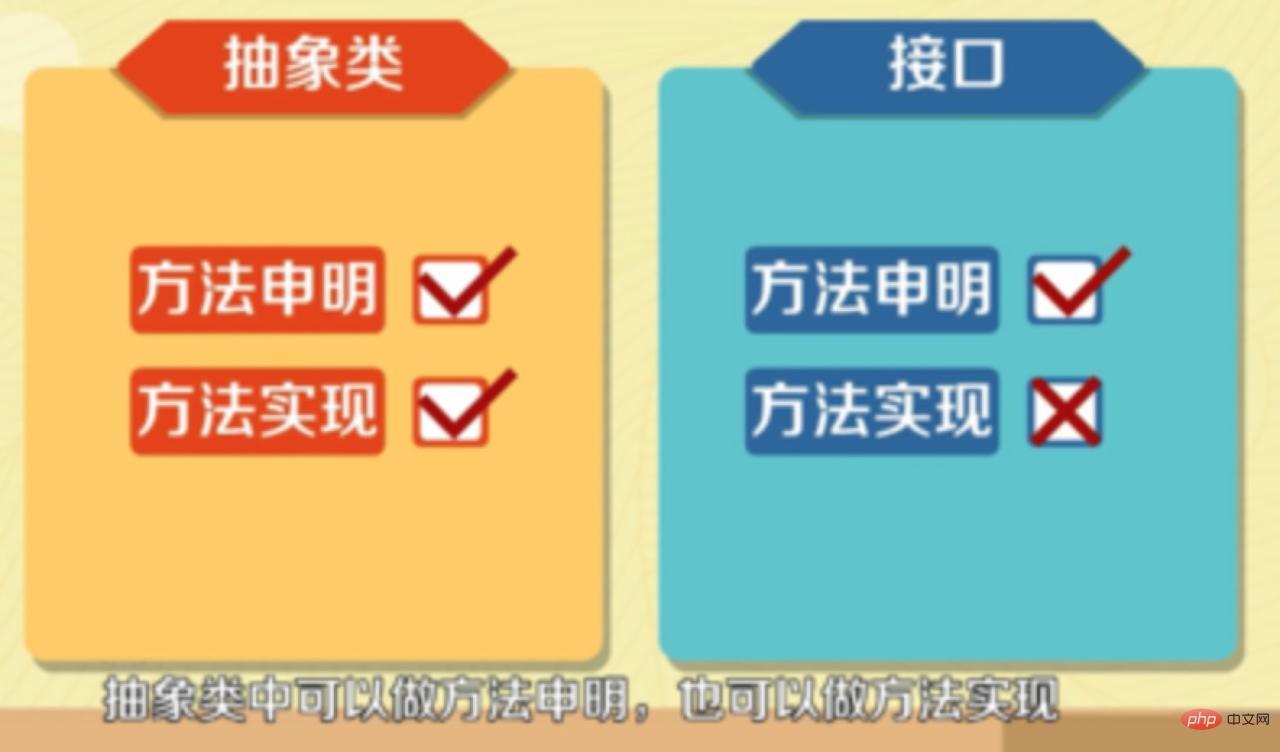
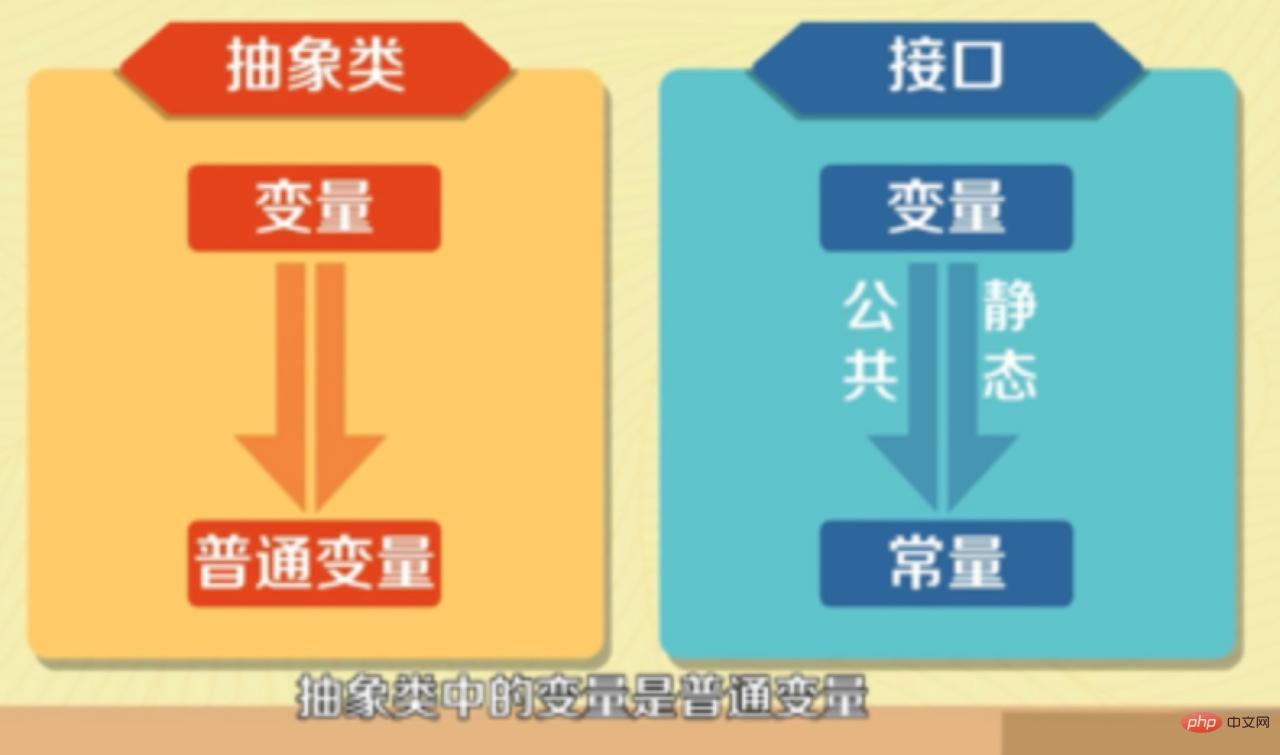
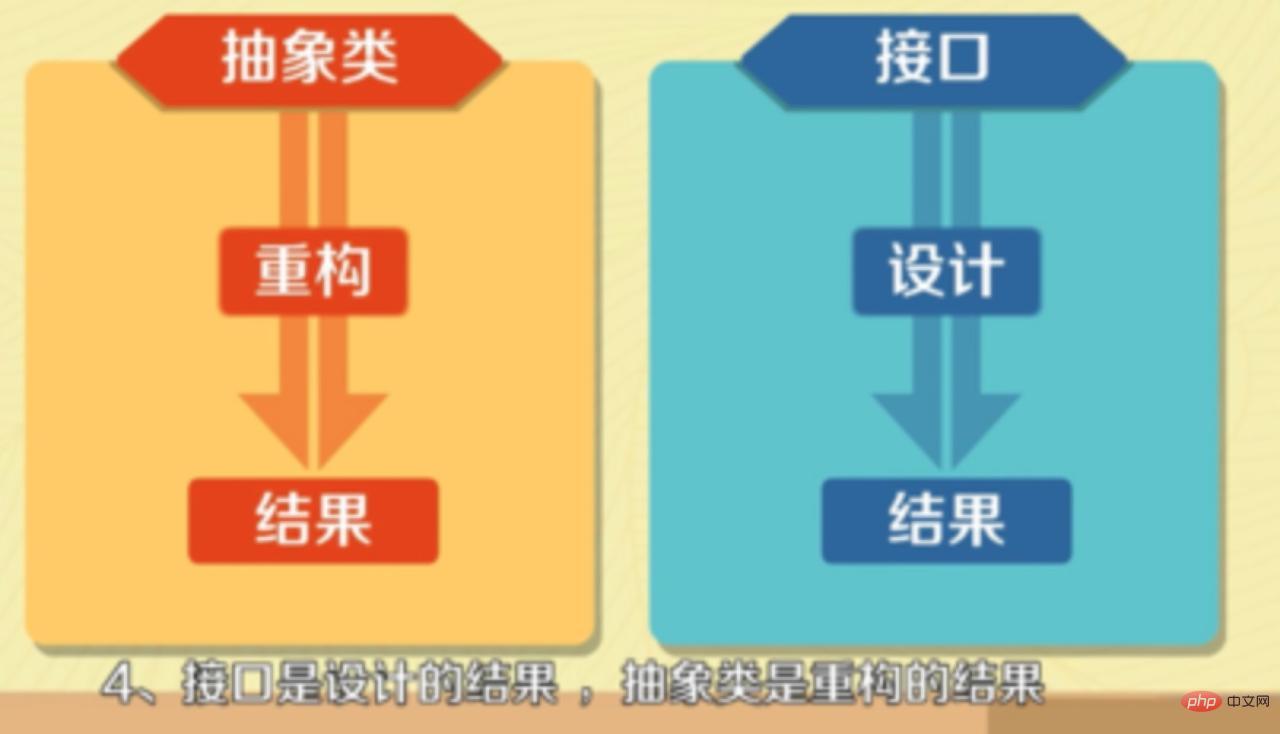
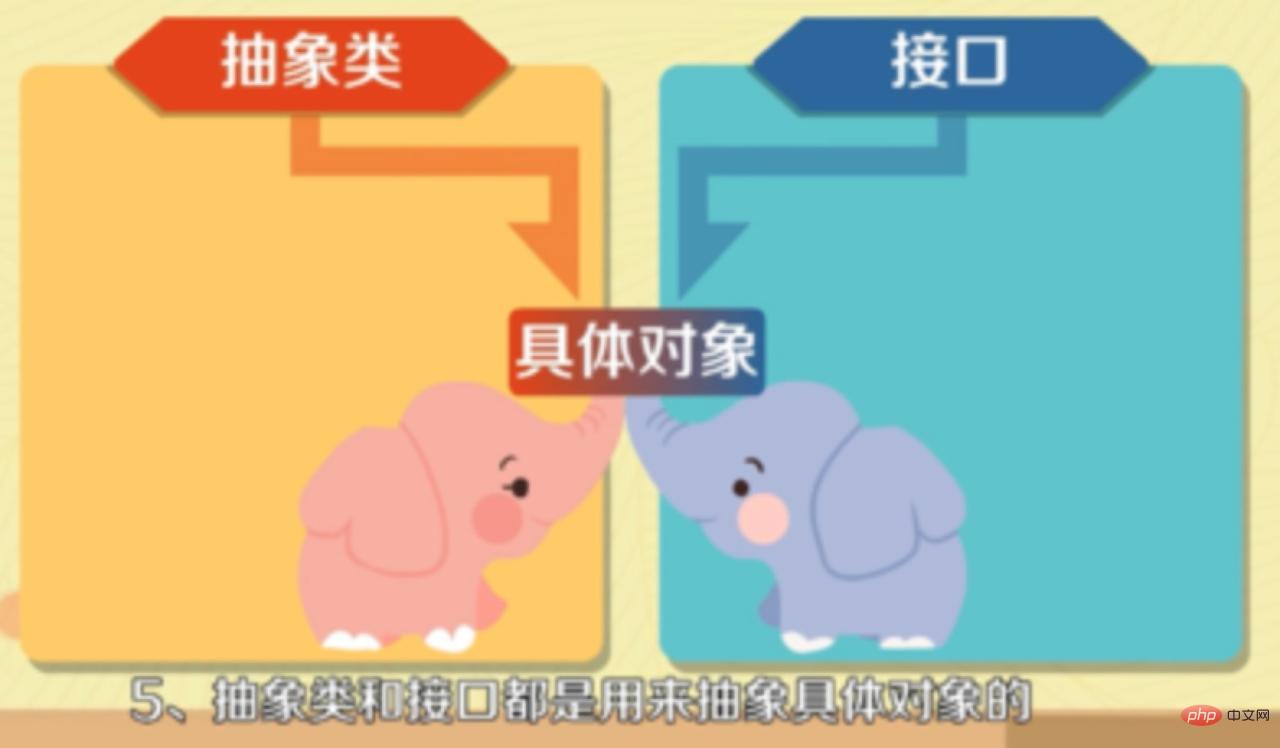
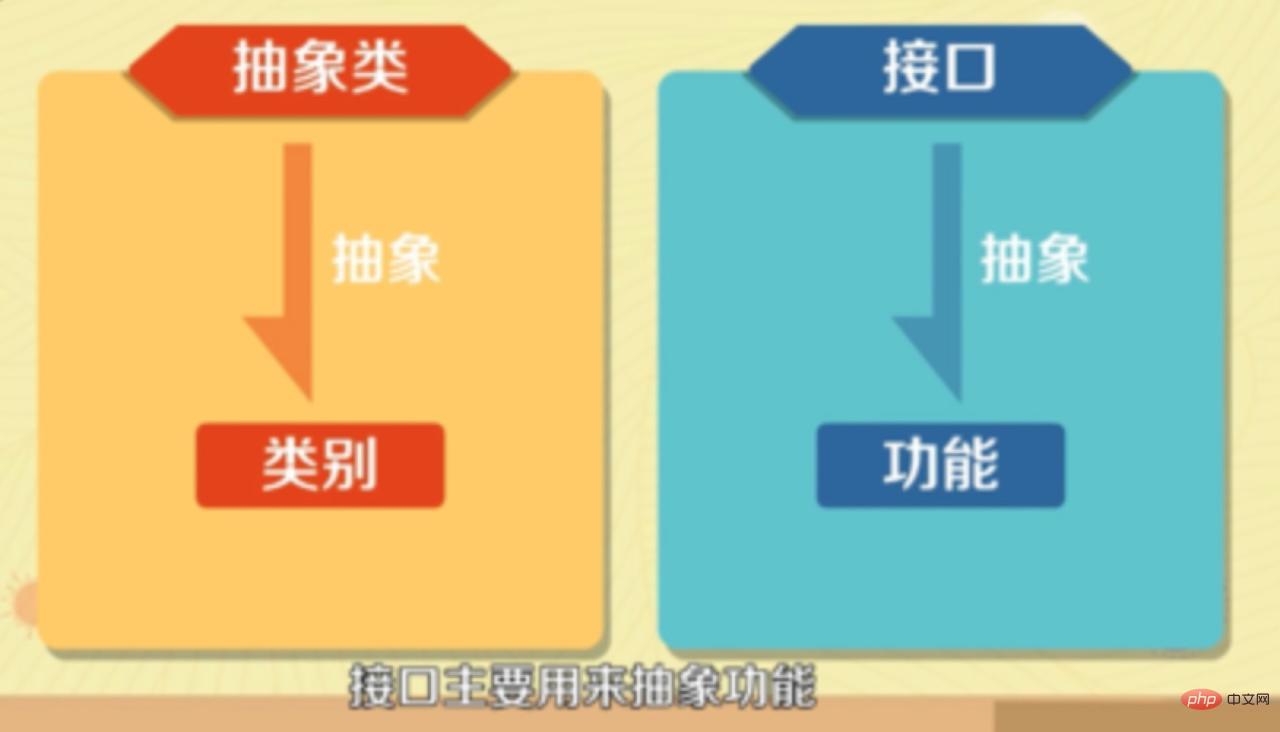
Classe abstraite : Si une classe contient des méthodes abstraites, la classe doit être déclarée comme classe abstraite à l'aide du mot-clé abstract.
Signification :
En un mot, lorsqu'à la fois une interface unifiée et des variables d'instance ou des méthodes par défaut sont nécessaires, vous pouvez l'utiliser . Les plus courants sont :
La réponse est : Oui
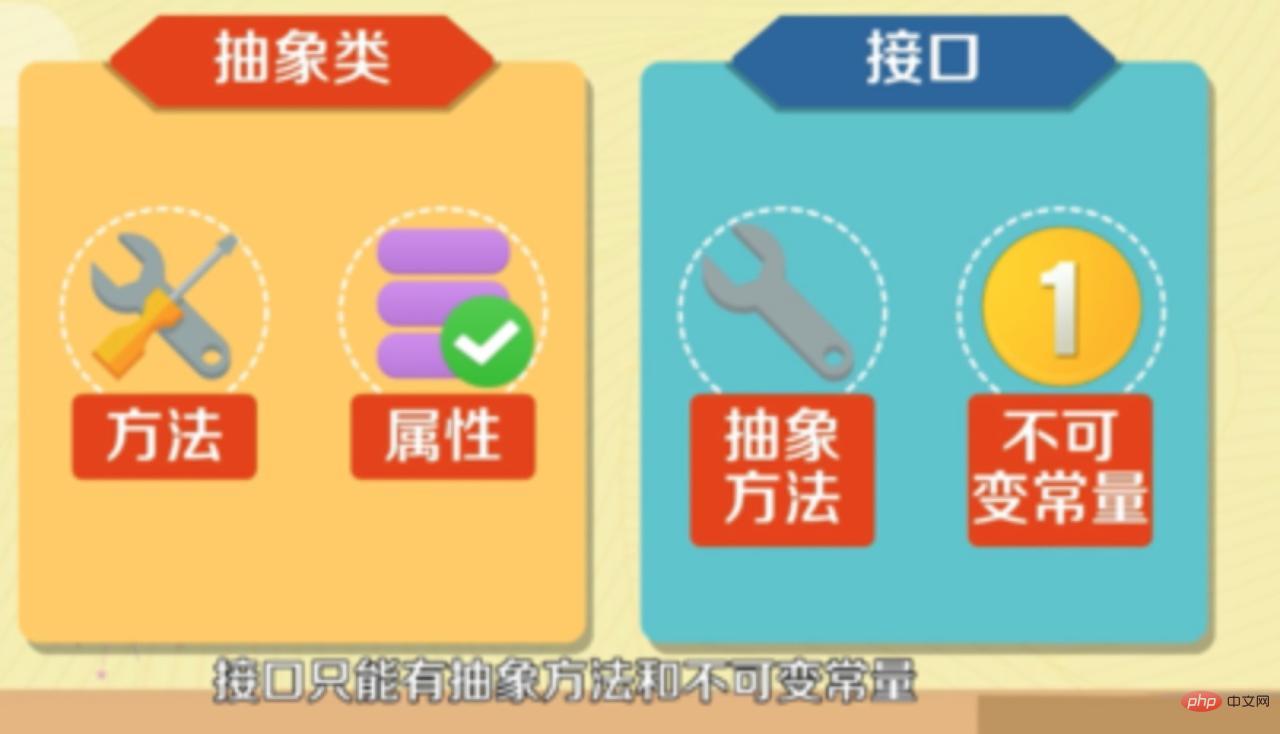
Il ne peut y avoir de méthodes abstraites dans les classes abstraites, mais celles qui ont des méthodes abstraites doivent être des classes abstraites. Par conséquent, il ne peut y avoir de méthodes abstraites dans les classes abstraites en Java. Notez que même les classes abstraites sans méthodes et propriétés abstraites ne peuvent pas être instanciées.
在平时看源码的时候我们经常看到泛型,且经常会看到extends和super的使用,看过其他的文章里也有讲到上界通配符和下届通配符,总感觉讲的不够明白。这里备注一下,以免忘记。
这两点不难理解,extends修饰的只能取,不能放,这是为什么呢? 先看一个列子:
public class Food {}
public class Fruit extends Food {}
public class Apple extends Fruit {}
public class Banana extends Fruit{}
public class GenericTest {
public void testExtends(List extends Fruit> list){
//报错,extends为上界通配符,只能取值,不能放.
//因为Fruit的子类不只有Apple还有Banana,这里不能确定具体的泛型到底是Apple还是Banana,所以放入任何一种类型都会报错
//list.add(new Apple());
//可以正常获取
Fruit fruit = list.get(1);
}
public void testSuper(List super Fruit> list){
//super为下界通配符,可以存放元素,但是也只能存放当前类或者子类的实例,以当前的例子来讲,
//无法确定Fruit的父类是否只有Food一个(Object是超级父类)
//因此放入Food的实例编译不通过
list.add(new Apple());
// list.add(new Food());
Object object = list.get(1);
}
}在testExtends方法中,因为泛型中用的是extends,在向list中存放元素的时候,我们并不能确定List中的元素的具体类型,即可能是Apple也可能是Banana。因此调用add方法时,不论传入new Apple()还是new Banana(),都会出现编译错误。
理解了extends之后,再看super就很容易理解了,即我们不能确定testSuper方法的参数中的泛型是Fruit的哪个父类,因此在调用get方法时只能返回Object类型。结合extends可见,在获取泛型元素时,使用extends获取到的是泛型中的上边界的类型(本例子中为Fruit),范围更小。
总结:在使用泛型时,存取元素时用super,获取元素时,用extends。
不能,父类的静态方法能够被子类继承,但是不能够被子类重写,即使子类中的静态方法与父类中的静态方法完全一样,也是两个完全不同的方法。
class Fruit{
static String color = "五颜六色";
static public void call() {
System.out.println("这是一个水果");
}
}
public class Banana extends Fruit{
static String color = "黄色";
static public void call() {
System.out.println("这是一个香蕉");
}
public static void main(String[] args) {
Fruit fruit = new Banana();
System.out.println(fruit.color); //五颜六色
fruit.call(); //这是一个水果
}
}如代码所示,如果能够被重写,则输出的应该是这是一个香蕉。与此类似的是,静态变量也不能够被重写。如果想要调用父类的静态方法,应该使用类来调用。 那为什么会出现这种情况呢? 我们要从重写的定义来说:
重写指的是根据运行时对象的类型来决定调用哪个方法,而不是根据编译时的类型。
对于静态方法和静态变量来说,虽然在上述代码中使用对象来进行调用,但是底层上还是使用父类来调用的,静态变量和静态方法在编译的时候就将其与类绑定在一起。既然它们在编译的时候就决定了调用的方法、变量,那就和重写没有关系了。
静态属性和静态方法是否可以被继承
可以被继承,如果子类中有相同的静态方法和静态变量,那么父类的方法以及变量就会被覆盖。要想调用就就必须使用父类来调用。
class Fruit{
static String color = "五颜六色";
static String xingzhuang = "奇形怪状";
static public void call() {
System.out.println("这是一个水果");
}
static public void test() {
System.out.println("这是没有被子类覆盖的方法");
}
}
public class Banana extends Fruit{
static String color = "黄色";
static public void call() {
System.out.println("这是一个香蕉");
}
public static void main(String[] args) {
Banana banana = new Banana();
banana.test(); //这是没有被子类覆盖的方法
banana.call(); //调用Banana类中的call方法 这是一个香蕉
Fruit.call(); //调用Fruit类中的方法 这是一个水果
System.out.println(banana.xingzhuang + " " + banana.color); //奇形怪状 黄色
}
}从上述代码可以看出,子类中覆盖了父类的静态方法的话,调用的是子类的方法,这个时候要是还想调用父类的静态方法,应该是用父类直接调用。如果子类没有覆盖,则调用的是父类的方法。静态变量与此相似。
Vous pouvez lire cet article : juejin.im/post/684490…
Méthode 1 : Sérialisable, la classe à passer implémente l'interface Serialisable pour passer l'objet, Méthode 2 : Parcelable, la classe à transférer implémente l'interface Parcelable pour transférer l'objet.
Sérialisable (livré avec Java) : Sérialisable signifie sérialisation, ce qui signifie convertir un objet en un état stockable ou transférable. Les objets sérialisés peuvent être transmis sur le réseau ou stockés localement. Serialisable est une interface balisée, ce qui signifie que Java peut sérialiser efficacement cet objet sans implémenter de méthodes.
Parcelable (exclusivement pour Android) : L'intention de conception originale de Parcelable d'Android est que Serialisable est trop lent (en utilisant la réflexion), afin de faciliter la communication entre les différents composants du programme et entre différents programmes Android (AIDL) Conçus pour transférer efficacement des données qui n'existent qu'en mémoire. Le principe d'implémentation de la méthode Parcelable est de décomposer un objet complet, et chaque partie après décomposition est un type de données pris en charge par Intent, réalisant ainsi la fonction de passage de l'objet.
Efficacité et sélection : Parcelable a de meilleures performances que Serialisable, car ce dernier est fréquemment GC pendant le processus de réflexion, il est donc recommandé d'utiliser Parcelable lors du transfert de données entre mémoires, comme le transfert de données entre les activités. Serialisable peut conserver les données pour un stockage facile, alors choisissez Serialisable lorsque vous devez enregistrer ou transmettre des données sur le réseau. Étant donné que Parcelable peut être différent selon les versions d'Android, il n'est pas recommandé d'utiliser Parcelable pour la persistance des données. Parcelable ne peut pas être utilisé lorsque les données doivent être stockées sur disque, car Parcelable ne peut pas garantir la persistance des données lorsque le monde extérieur change. Bien que Serialisable soit moins efficace, il est toujours recommandé d'utiliser Serialisable pour le moment. Lors du passage de types de données complexes via intent, l'une des deux interfaces doit être implémentée en premier. Les méthodes correspondantes sont getSerializingExtra() et getParcelableExtra(). 17. Les propriétés statiques et les méthodes statiques peuvent-elles être héritées ? Peut-il être réécrit ? Et pourquoi ?Les propriétés et méthodes statiques de la classe parent peuvent être héritées par la sous-classe
ne peuvent pas être remplacées par la sous-classe : Lorsque la référence de la classe parent pointe vers la sous-classe Lorsque vous utilisez un objet pour appeler une méthode statique ou une variable statique, la méthode ou la variable de la classe parent est appelée. Il n'est pas remplacé par les sous-classes.
Raison :
Parce que la méthode statique a alloué de la mémoire depuis le début de l'exécution du programme, ce qui signifie qu'elle a été codée en dur. Tous les objets qui font référence à cette méthode (soit les objets de la classe parent, soit les objets de la sous-classe) pointent vers la même donnée en mémoire, qui est la méthode statique. Si une méthode statique portant le même nom est définie dans une sous-classe, elle ne sera pas remplacée. Au lieu de cela, une autre méthode statique de la sous-classe doit être allouée en mémoire, et la substitution n'existe pas. 18. L'intention de conception des classes internes statiques en Java Classes internes Les classes internes sont des classes définies à l'intérieur d'une classe. Pourquoi y a-t-il des classes internes ? Nous savons qu'en Java, les classes sont à héritage unique et qu'une classe ne peut hériter qu'une autre classe concrète ou classe abstraite (qui peut implémenter plusieurs interfaces). Le but de cette conception est que dans l'héritage multiple, lorsqu'il y a des attributs ou des méthodes en double dans plusieurs classes parents, le résultat de l'appel de la sous-classe sera ambigu, donc un héritage unique est utilisé.La raison de l'utilisation des classes internes est que chaque classe interne peut hériter indépendamment d'une implémentation (de l'interface), donc si la classe externe a hérité d'une implémentation (de l'interface), cela n'a aucun effet sur la classe interne.
Dans notre programmation, il existe parfois des problèmes difficiles à résoudre à l'aide d'interfaces. À l'heure actuelle, nous pouvons utiliser la capacité fournie par les classes internes d'hériter de plusieurs classes concrètes ou abstraites pour résoudre ces problèmes de conception. . On peut dire que les interfaces ne résolvent qu'une partie du problème et que les classes internes rendent la solution de l'héritage multiple plus complète.
Avant de parler de classes internes statiques, comprenons d'abord les classes internes membres (classes internes non statiques).
Classe interne membre
La classe interne membre est également la classe interne la plus courante. Elle est membre de la classe externe, elle peut donc avoir un accès illimité à tous. classes externes. Bien que les propriétés et méthodes des membres soient privées, si la classe externe souhaite accéder aux propriétés et méthodes des membres de la classe interne, elle doit y accéder via l'instance de classe interne.
Deux points à noter dans les classes internes membres :
Il ne peut y avoir de variables ni de méthodes statiques dans les classes internes membres ;
La classe interne membre est attachée à la classe externe, donc la classe interne ne peut être créée qu'après la création préalable de la classe externe.
Classes internes statiques
Il existe une plus grande différence entre les classes internes statiques et les classes internes non statiques : les classes internes non statiques sont compilées après la compilation, une référence est alors implicitement liée au monde extérieur dans lequel elle a été créée, mais pas la classe interne statique.
L'absence de cette référence signifie :
Sa création n'a pas besoin de dépendre de la classe environnante.
Il ne peut pas utiliser de variables membres non statiques et de méthodes d'aucune classe périphérique.
Les deux autres classes internes : les classes internes locales et les classes internes anonymes
Les classes internes locales
Les classes internes locales sont Nichée dans des méthodes et des portées, l'utilisation de cette classe est principalement destinée à appliquer et à résoudre des problèmes plus complexes. Nous souhaitons créer une classe pour faciliter nos solutions, mais à ce stade, nous ne voulons pas que cette classe soit accessible au public, nous A. La classe interne locale est générée. La classe interne locale est compilée de la même manière que la classe interne membre, mais sa portée a changé. Elle ne peut être utilisée que dans cette méthode et cet attribut, et elle deviendra invalide en dehors de la méthode et de l'attribut.
Classes internes anonymes
Les classes internes anonymes n'ont aucun modificateur d'accès.
nouvelle classe interne anonyme, cette classe doit exister en premier.
Lorsque le paramètre formel de la méthode doit être utilisé par la classe interne anonyme, alors le paramètre formel doit être final.
Les classes internes anonymes n'ont pas de constructeur explicite et le compilateur générera automatiquement un constructeur qui fait référence à la classe externe.
Recommandations associées : Démarrer avec Java
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



