

La colonne
tutoriel MySQL présente les connaissances pertinentes sur les index aujourd'hui.

Le deuxième article de la série MySQL, traitant principalement de certains problèmes liés aux index dans MySQL, notamment les types d'index, les modèles de données, les processus d'exécution d'index et le préfixe le plus à gauche Principe, échec de l'index et refoulement de l'index, etc.
La première fois que j'ai découvert les index, c'était dans le cours sur les principes des bases de données de ma deuxième année. Lorsqu'une instruction de requête est très lente, vous pouvez améliorer l'efficacité des requêtes en ajoutant des index à certains champs<.>.
Il existe un autre exemple très classique : on peut penser la base de données comme un dictionnaire et l'index comme un répertoire. Lorsque l'on utilise le répertoire du dictionnaire pour interroger un mot, le rôle de l'index peut être reflété. . 1. Types d'index Dans MySQL, en fonction des caractéristiques de la logique ou du champ de l'index, l'index est grossièrement divisé en types suivants : index ordinaire, index unique, index de clé primaire, Index d'union et index de préfixe.De plus, il existe un index de texte intégral, qui résout le problème de déterminer si un champ est inclus en établissant un index inversé.
L'index inversé est utilisé pour stocker le mappage de l'emplacement de stockage d'un mot dans un document ou un groupe de documents en recherche en texte intégral. Grâce à l'index inversé, vous pouvez obtenir rapidement une liste de documents contenant. ce mot basé sur le mot.
Lors d'une recherche par mots-clés, l'indexation en texte intégral s'avérera utile.
Il s'agit d'un arbre B+ relativement simple.
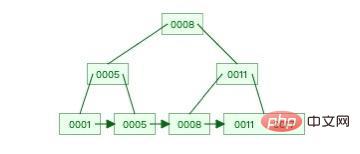
Source de l'image : Visualisations de la structure des données
Comme vous pouvez le voir sur l'image d'exemple ci-dessus, cet arbre B+ est en bas Les nœuds feuilles stockent tous les éléments et sont stockés dans l'ordre, tandis que les nœuds non-feuilles stockent uniquement la valeur de la colonne d'index.
Dans InnoDB, le modèle d'index basé sur BTree est le plus couramment utilisé. Ce qui suit utilise un exemple pratique pour illustrer la structure de l'index BTree dans InnoDB.
CREATE TABLE `user` ( `id` int(11) NOT NULL, `name` varchar(36) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, INDEX `nameIndex`(`name`) USING BTREE ) ENGINE = InnoDB;-- 插入数据insert into user1(id,name,age) values (1,'one',21),(2,'two',22),(3,'three',23),(4,'four',24),(5,'five',25);复制代码
Il n'y a que deux champs dans cette table : l'identifiant de clé primaire et le champ de nom, et un index BTree avec le champ de nom car la colonne d'index est établie.
Un index basé sur le champ d'identifiant de clé primaire est également appelé index de clé primaire. Sa structure arborescente d'index est la suivante : l'étape non-feuille de l'arborescence d'index stocke la valeur de l'identifiant de clé primaire et la valeur. stocké dans le nœud feuille est La ligne de données entière correspondant à l'identifiant de clé primaire , comme le montre la figure suivante :
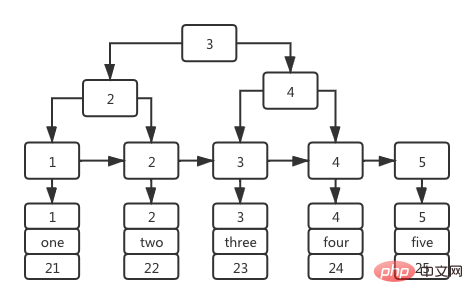
C'est précisément parce que le Les nœuds feuilles de l'index de clé primaire stockent l'identifiant de clé primaire correspondant. La ligne de données entière, l'index de clé primaire est également appelé index clusterisé.
Dans l'arborescence d'index avec le champ de nom comme colonne, les nœuds non-feuille stockent également la valeur de la colonne d'index, et la valeur stockée dans l'étape feuille est la valeur de la clé primaire id, comme le montre la figure ci-dessous Show.
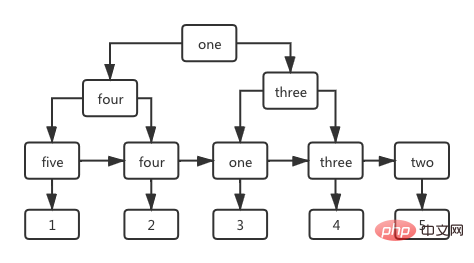
Regardez d'abord le SQL suivant pour interroger la ligne de données avec id=1 dans la table utilisateur.
select * from user where id=1;复制代码
Le processus d'exécution de ce SQL est très simple. Le moteur de stockage parcourra l'arborescence d'index de l'identifiant de clé primaire Lorsqu'il trouvera id=1, il renverra la ligne de données avec id=1 dans. l'arborescence d'index (en raison de la clé primaire La valeur est unique, donc si une cible touchée est trouvée, la recherche s'arrêtera et l'ensemble de résultats sera renvoyé directement).
Examinons ensuite la situation de l'utilisation d'un index ordinaire pour une requête. Sa situation est légèrement différente de celle de l'index de clé primaire.
select * from user where name='one';复制代码
Le processus de l'instruction de requête SQL ci-dessus est le suivant : Tout d'abord, le moteur de stockage recherchera l'arborescence d'index de la colonne de nom de l'index ordinaire. Lorsqu'un enregistrement dont le nom est égal à un est atteint, le. Le moteur de stockage doit passer par une étape très importante :réponse à la table.
Étant donné que les sous-nœuds de l'arborescence d'index des index ordinaires stockent les valeurs de clé primaire, lorsque l'instruction de requête doit interroger d'autres champs à l'exception de l'identifiant de clé primaire et de la colonne d'index, elle doit revenir à l'index de clé primaire. en fonction de la valeur de l'identifiant de clé primaire. Effectuez une requête dans l'arborescence pour obtenir la ligne de données entière correspondant à l'identifiant de clé primaire, puis obtenez les champs requis par le client avant d'ajouter cette ligne à l'ensemble de résultats.
Le moteur de stockage continuera ensuite à rechercher dans l'arborescence d'index jusqu'à ce qu'il rencontre le premier enregistrement qui ne satisfait pas name='one', et renverra enfin tous les enregistrements trouvés au client.
Nous appelons le processus d'interrogation de la ligne de données entière dans l'index de clé primaire en fonction de la valeur de l'identifiant de clé primaire interrogée à partir de l'index ordinaire comme retour de table.
Lorsque la quantité de données est très importante, le retour de table est un processus très long, nous devrions donc essayer d'éviter le retour de table, ce qui nous amène à la question suivante : utiliser un index de couverture pour éviter le retour de table.
Je ne sais pas si vous avez remarqué qu'il y a une telle description dans la question de retour de la table précédente : "Quand l'instruction de requête doit interroger la clé primaire id et colonne d'index "Autres champs autres que..." Dans ce scénario, vous devez obtenir d'autres champs de requête en renvoyant la table. En d’autres termes, si l’instruction de requête doit uniquement interroger les champs de l’identifiant de clé primaire et de la colonne d’index, n’est-il pas nécessaire de renvoyer la table ?
Analysons ce processus. Tout d’abord, créons un index commun.
alter table user add index name_age ('name','age');复制代码Ensuite, le schéma de structure de cet arbre d'indexation doit être le suivant :

L'ordre des nœuds enfants de l'arbre d'indexation conjoint est selon les champs lorsque l'index est déclaré. Pour trier, c'est similaire à order by name, age, et la valeur correspondant à son index est la valeur de la clé primaire comme un index normal.
select name,age from user where name='one';复制代码
上面这条 SQL 是查询所有 name='one' 记录的 name 和 age 字段,理想的执行计划应该是搜索刚刚建立的联合索引。
与普通索引一样,存储引擎会搜索联合索引,由于联合索引的顺序是先按照 name 再按照 age 进行排序的,所以当找到第一个 name 不是 one 的索引时,才会停止搜索。
而由于 SQL 语句查询的只是 name 和 age 字段,恰好存储引擎命中查询条件时得到的数据正是 name, age 和 id 字段,已经包含了客户端需要的字段了,所以就不需要再回表了。
我们把只需要在一棵索引树上就可以得到查询语句所需要的所有字段的索引成为覆盖索引,覆盖索引无须进行回表操作,速度会更快一些,所以我们在进行 SQL 优化时可以考虑使用覆盖索引来优化。
上面所举的例子都是使用索引的情况,事实上在项目中复杂的查询语句中,也可能存在不使用索引的情况。首先我们要知道,MySQL 在执行 SQL 语句的时候一张表只会选择一棵索引树进行搜索,所以一般在建立索引时需要尽可能覆盖所有的查询条件,建立联合索引。
而对于联合索引,MySQL 会遵循最左前缀原则:查询条件与联合索引的最左列或最左连续多列一致,那么就可以使用该索引。
为了详细说明最左前缀原则,同时说明最左前缀原则的一些特殊情况。
即便我们根据最左前缀的原则创建了联合索引,还是会有一些特殊的场景会导致索引失效,下面举例说明。
假设有一张 table 表,它有一个联合索引,索引列为 a,b,c 这三个字段,这三个字段的长度均为10。
CREATE TABLE `demo` ( `a` varchar(1) DEFAULT NULL, `b` varchar(1) DEFAULT NULL, `c` varchar(1) DEFAULT NULL, INDEX `abc_index`(`a`, `b`, `c`) USING BTREE ) ENGINE = InnoDB;复制代码
第一种情况是查询条件与索引字段全部一致,并且用的是等值查询,如:
select * from demo where a='1' and b='1' and c='1';select * from demo where c='1' and a='1' and b='1';复制代码
输出上述两条 SQL 的执行计划来看它们使用索引的情况。
mysql> explain select * from demo where a='1' and b='1' and c='1'; +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+| 1 | SIMPLE | demo | NULL | ref | abc_index | abc_index | 18 | const,const,const | 1 | 100.00 | Using index | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+1 row in set, 1 warning (0.00 sec) mysql> explain select * from demo where c='1' and a='1' and b='1'; +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+| 1 | SIMPLE | demo | NULL | ref | abc_index | abc_index | 18 | const,const,const | 1 | 100.00 | Using index | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+1 row in set, 1 warning (0.00 sec)复制代码
第一条 SQL 很显然能够用到联合索引。
从执行计划中可以看到,第二条 SQL 与第一条 SQL 使用的索引以及索引长度是一致的,都是使用 abc_index 索引,索引长度为 18 个字节。
按理说查询条件与索引的顺序不一致,应该不会用到索引,但是由于 MySQL 有优化器存在,它会把第二条 SQL 优化成第一条 SQL 的样子,所以第二条 SQL 也使用到了联合索引 abc_index。
综上所述,全字段匹配且为等值查询的情况下,查询条件的顺序不一致也能使用到联合索引。
第二种情况是查询条件与索引字段部分保持一致,这里就需要遵循最左前缀的原则,如:
select * from demo where a='1' and b='1';select * from demo where a='1' and c='1';复制代码
上述的两条查询语句分别对应三个索引字段只用到两个字段的情况,它们的执行计划是:
mysql> explain select * from demo where a='1' and b='1'; +----+-------------+-------+------------+------+---------------+-----------+---------+-------------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------+------+----------+-------------+| 1 | SIMPLE | demo | NULL | ref | abc_index | abc_index | 12 | const,const | 1 | 100.00 | Using index | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------+------+----------+-------------+1 row in set, 1 warning (0.00 sec) mysql> explain select * from demo where a='1' and c='1'; +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+--------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+--------------------------+| 1 | SIMPLE | demo | NULL | ref | abc_index | abc_index | 6 | const | 1 | 100.00 | Using where; Using index | +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+--------------------------+1 row in set, 1 warning (0.00 sec)复制代码
从它们的执行计划可以看到,这两条查询语句都使用到了 abc_index 索引,不同的是,它们使用到索引的长度分别是:12、6 字节。
在这里需要额外提一下索引长度的计算方式,对于本例中声明为 varchar(1) 类型的 a 字段,它的索引长度= 1 * (3) + 1 + 2 = 6。
所以这两条查询语句使用索引的情况是:
由此可见:最左前缀原则要求,查询条件必须是从索引最左列开始的连续几列。
第三种情况是查询条件用的是范围查询(,!=,=,between,like)时,如:
select * from demo where a='1' and b!='1' and c='1';复制代码
这两条查询语句的执行计划是:
mysql> EXPLAIN select * from demo where a='1' and b!='1' and c='1'; +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+--------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+--------------------------+| 1 | SIMPLE | demo | NULL | range | abc_index | abc_index | 12 | NULL | 2 | 10.00 | Using where; Using index | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+--------------------------+1 row in set, 1 warning (0.00 sec)复制代码
从执行计划可以看到,第一条 SQL 使用了联合索引,且索引长度为 12 字节,即用到了 a,b 两个字段;第二条 SQL 也使用了联合索引,索引长度为 6 字节,仅使用了联合索引中的 a 字段。
综上所述,在全字段匹配且为范围查询的情况下,也能使用联合索引,但只能使用到联合索引中第一个出现范围查询条件的字段。
需要注意的是:
第四种情况是查询条件中带有函数或特殊表达式的,比如:
select * from demo where id + 1 = 2;select * from demo where concat(a, '1') = '11';复制代码
可能由于数据的原因(空表),我输出的执行计划是使用了联合索引的,但是事实上,在查询条件中,等式不等式左侧的字段包含表达式或函数时,该字段是不会用到索引的。
至于原因,是因为使用函数或表达式的情况下,索引字段本身的值已不具备有序性。
上文中已经罗列了联合索引的实际结构、最左前缀原则以及索引失效的场景,这里再说一下索引下推这个重要的优化规则。
select * from demo where a > '1' and b='1'; mysql> explain select * from demo where a > '1' and b='1'; +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+| 1 | SIMPLE | demo | NULL | range | abc_index | abc_index | 6 | NULL | 1 | 10.00 | Using index condition | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+1 row in set, 1 warning (0.00 sec)复制代码
上面这条查询语句,从它的执行计划也可以看出,它使用的索引长度为 6 个字节,只用到了第一个字段。
所以 MySQL 在查询过程中,只会对第一个字段 a 进行 a > '1' 的条件判断,当满足条件后,存储引擎并不会进行 b=1 的判断, 而是通过回表拿到整个数据行之后再进行判断。
这好像很蠢,就算索引只用到了第一个字段,但明明索引树中就有 b 字段的数据,为什么不直接进行判断呢?
听上去好像是个 bug,其实在未使用索引下推之前整个查询逻辑是:由存储引擎检索索引树,就算索引树中存在 b 字段的值,但由于这条查询语句的执行计划使用了联合索引但没有用到 b 字段,所以也无法进行 b 字段的条件判断,当存储引擎拿到满足条件(a>'1')的数据后,再由 MySQL 服务器进行条件判断。
在 MySQL5.6 版本中对这样的情况进行优化,引入索引下推技术:在搜索索引树的过程中,就算没能用到联合索引的其他字段,也能优先对查询条件中包含且索引也包含的字段进行判断,减少回表次数,提高查询效率。
在使用索引下推优化之后,b 字段作为联合索引列,又存在于查询条件中,同时又没有在搜索索引树时被使用到,MySQL 服务器会把查询条件中关于 b 字段的部分也传给存储引擎,存储引擎会在搜索索引树命中数据之后再进行 b 字段查询条件的判断,满足的才会加入结果集。
Ps: 执行计划中 Extra 字段的值包含 Using index condition 就代表使用到了索引下推。
更多相关免费学习推荐:mysql教程(视频)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 qu'est-ce que l'index
qu'est-ce que l'index
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql










![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



