
La colonne
Tutoriel de base de Java présente comment des milliards de données doivent être migrées.

Il y a une phrase très célèbre dans "Westward Journey" de Xingye : "Il était une fois un amour sincère que je faisais Je ne chérissais pas la relation avant moi et je l'ai regretté quand je l'ai perdue. La chose la plus douloureuse au monde est la suivante. Si Dieu pouvait me donner une autre chance, je dirais trois mots à n'importe quelle fille : « Je t'aime. Je dois ajouter une limite de temps à cet amour, j'espère que ce sera dix mille ans ! " Aux yeux de nos développeurs, ce sentiment est le même que les données de notre base de données. Comme nous souhaitons qu'il dure dix mille ans ! Non changeant, mais se retourne souvent contre nous. À mesure que l'entreprise continue de se développer et que l'activité continue d'évoluer, nos besoins en données changent également constamment. Il existe probablement les situations suivantes :
Dans le développement commercial réel, nous élaborerons différents plans de migration en fonction de différentes situations. Discutons ensuite de la manière de migrer les données.
La migration des données ne se fait pas du jour au lendemain. Chaque migration de données prend beaucoup de temps, cela peut prendre une semaine, cela peut prendre plusieurs mois. De manière générale, nous migrons les données. est fondamentalement similaire à l'image ci-dessous : 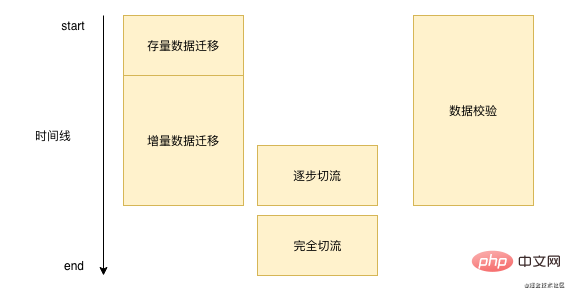 '
Tout d'abord, nous devons migrer par lots les données existantes dans notre base de données, puis nous devons traiter les nouvelles données. Nous devons écrire cette partie des données dans notre nouveau stockage en temps réel après avoir écrit la base de données d'origine. vérifier en permanence les données pendant le processus. Lorsque nous vérifions que les problèmes de base ne sont pas graves, nous effectuerons alors l’opération de coupure de flux. Une fois la coupure de flux terminée, nous n’aurons plus besoin d’effectuer de vérification des données ni de migration incrémentielle des données.
'
Tout d'abord, nous devons migrer par lots les données existantes dans notre base de données, puis nous devons traiter les nouvelles données. Nous devons écrire cette partie des données dans notre nouveau stockage en temps réel après avoir écrit la base de données d'origine. vérifier en permanence les données pendant le processus. Lorsque nous vérifions que les problèmes de base ne sont pas graves, nous effectuerons alors l’opération de coupure de flux. Une fois la coupure de flux terminée, nous n’aurons plus besoin d’effectuer de vérification des données ni de migration incrémentielle des données.
Tout d'abord, parlons de la façon de migrer des données existantes. Après avoir effectué des recherches dans la communauté open source, nous avons constaté qu'il n'existait pas d'outil facile à utiliser. Migration de données existantes.À l'heure actuelle, le DTS du cloud d'Alibaba fournit la migration de données existantes. DTS prend en charge la migration entre des sources de données homogènes et hétérogènes et prend essentiellement en charge les bases de données courantes de l'industrie telles que Mysql, Orcale, SQL Server, etc. DTS est plus adapté aux deux premiers scénarios que nous avons mentionnés précédemment. L'un est le scénario de sous-base de données. Si vous utilisez le DRDS d'Alibaba Cloud, vous pouvez directement migrer les données vers DRDS via DTS. qu'il s'agisse de Redis, ES et DTS, tous prennent en charge la migration directe.
Alors comment migrer le stock DTS ? En fait, c'est relativement simple et comprend probablement les étapes suivantes :
select * from table_name where id > curId and id < curId + 10000;复制代码
3 Lorsque l'id est supérieur ou égal à maxId, la tâche de migration de données existante se termine
.Bien sûr, nous ne pouvons pas utiliser Alibaba Cloud dans le processus de migration réel, ou dans notre troisième scénario, nous devons faire beaucoup de conversions entre les champs de base de données, et DTS ne le prend pas en charge, alors nous pouvons imiter l'approche de DTS est de migrez les données en lisant les données par lots dans les segments. Ce qu'il faut noter ici, c'est que lorsque nous migrons des données par lots, nous devons contrôler la taille et la fréquence des segments pour éviter qu'ils n'affectent le fonctionnement normal de nos opérations en ligne.
Les solutions de migration des données existantes sont relativement limitées, mais les méthodes de migration incrémentielle des données sont en plein essor. De manière générale, nous disposons des méthodes suivantes :
Avec autant de méthodes, laquelle devrions-nous utiliser ? Personnellement, je recommande la méthode de surveillance du binlog. La surveillance du binlog réduit les coûts de développement. Il suffit d'implémenter la logique du consommateur, et les données peuvent garantir la cohérence. Puisqu'il s'agit d'un binlog surveillé, il n'y a pas lieu de s'inquiéter de la double écriture précédente. étant différents.
Toutes les solutions mentionnées ci-dessus, bien que beaucoup d'entre elles soient des services cloud matures (dts) ou des middlewares (canal), peuvent entraîner certaines pertes de données. La perte de données est généralement relativement rare, mais il est très difficile de dépanner. Il se peut que le dts ou le canal ait accidentellement tremblé, ou que les données aient été accidentellement perdues lors de la réception des données. Puisque nous n'avons aucun moyen d'empêcher la perte de nos données pendant le processus de migration, nous devons les corriger par d'autres moyens.
De manière générale, lorsque nous migrerons des données, il y aura une étape de vérification des données, mais différentes équipes peuvent choisir différentes solutions de vérification des données :
Bien sûr, nous devons également prêter attention aux points suivants pendant le processus de développement proprement dit :
Lorsque notre vérification des données ne comporte fondamentalement aucune erreur, cela signifie que notre programme de migration est relativement stable, alors nous pouvons utiliser nos nouvelles données directement ? Bien sûr, ce n'est pas possible. Si nous changeons tout en même temps, ce serait formidable si tout se passait bien. Mais si quelque chose ne va pas, cela affectera tous les utilisateurs.
Nous devons donc ensuite faire des niveaux de gris, c'est-à-dire couper le flux. Les dimensions des différentes coupes de flux métier seront différentes. Pour les coupes de flux de dimension utilisateur, nous utilisons généralement la méthode modulo de userId pour couper les flux. Pour les entreprises de dimension locataire ou commerçant, nous devons prendre la méthode de coupe modulo de l'identifiant du locataire. le flux. Pour cette réduction du trafic, vous devez élaborer un plan de réduction du trafic, dans quelle période, quelle quantité de trafic libérer, et lors de la réduction du trafic, vous devez choisir un moment où le trafic est relativement faible. Chaque fois que vous réduisez le trafic, vous en avez besoin. pour faire des observations détaillées des journaux, résoudre les problèmes dès que possible. Le processus de libération du trafic est un processus de lent à rapide. Par exemple, au début, nous utilisons 1% du volume pour le superposer en continu. utilisez directement 10 % ou 20 % du volume pour augmenter rapidement le volume. Parce que s'il y a un problème, il sera souvent découvert lorsque le trafic est faible. S'il n'y a pas de problème avec le faible trafic, le volume peut alors être augmenté rapidement.
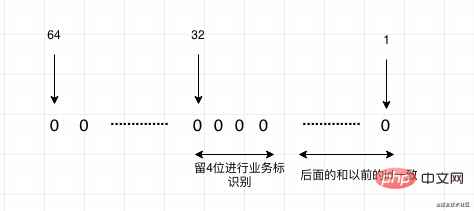
Dans le processus de migration des données, une attention particulière doit être accordée à l'ID de clé primaire Dans la solution de double écriture ci-dessus, il est également mentionné que. l'ID de clé primaire doit être écrit deux fois manuellement pour éviter les erreurs de séquence de génération d'ID.
Si nous migrons en raison de sous-bases de données et de tables, nous devons considérer que notre futur ID de clé primaire ne peut pas être un ID à incrémentation automatique, et nous devons utiliser des ID distribués. Celui le plus recommandé ici est le plus recommandé. Feuille open source de Meituan. Elle prend en charge deux modes. L'un est la tendance croissante de l'algorithme de flocon de neige, mais tous les identifiants sont de type Long, ce qui convient à certaines applications qui prennent en charge Long as id. Il existe également un mode segment de nombre, qui continuera à augmenter d'en haut en fonction d'un identifiant de base que vous définissez. Et fondamentalement, tous utilisent la génération de mémoire, et les performances sont également très rapides.
Bien sûr, nous avons toujours une situation dans laquelle nous devons migrer le système. L'identifiant de clé primaire du système précédent existe déjà dans le nouveau système, notre identifiant doit donc être mappé. Si nous savons déjà quels systèmes seront migrés à l'avenir lors de la migration du système, nous pouvons utiliser la méthode de réservation, par exemple, les données actuelles du système A sont de 100 millions à 100 millions, et les données du système B sont également de 100 millions. à 100 millions. Nous devons maintenant fusionner les deux systèmes A et B en un nouveau système, puis nous pouvons estimer légèrement le tampon, par exemple en laissant 100 à 150 millions pour le système A, afin que A n'ait pas besoin d'être cartographié, et le système B est de 150 millions à 300 millions. Ensuite, lorsque nous convertissons à l'ancien identifiant du système, nous devons soustraire 150 millions. Enfin, le nouvel identifiant de notre nouveau système passera de 300 millions. Mais que se passe-t-il s’il n’y a pas de segment réservé prévu dans le système ? Vous pouvez le faire des deux manières suivantes :
Enfin, résumons brièvement cette routine. Il s'agit en fait de quatre étapes, une seule note : stock, incrément, vérification, coupe. Stream, faites enfin attention à l'identifiant. Quelle que soit la quantité de données, il n’y aura fondamentalement aucun problème majeur lors de la migration selon cette routine. J'espère que cet article pourra vous aider dans vos travaux ultérieurs de migration de données.
Si vous pensez que cet article vous est utile, votre attention et votre transmission sont pour moi le plus grand soutien, O(∩_∩)O :
Recommandations d'apprentissage gratuites associées : Tutoriel de base Java
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 La différence entre le magasin phare autogéré de JD.com et son magasin phare officiel
La différence entre le magasin phare autogéré de JD.com et son magasin phare officiel
 Tableau de comparaison des codes ASCII
Tableau de comparaison des codes ASCII
 Quel fichier est .exe
Quel fichier est .exe
 La différence entre une pression sur une touche et une touche enfoncée
La différence entre une pression sur une touche et une touche enfoncée
 Pilote d'appareil photo numérique
Pilote d'appareil photo numérique
 Qu'est-ce que Spring MVC
Qu'est-ce que Spring MVC
 commande telnet
commande telnet
 Combien vaut un Bitcoin en RMB ?
Combien vaut un Bitcoin en RMB ?











![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



