

Récemment, j'apprends l'optimisation MySQL. La colonne Tutoriel MySQL présente l'optimisation des types de données et du schéma.
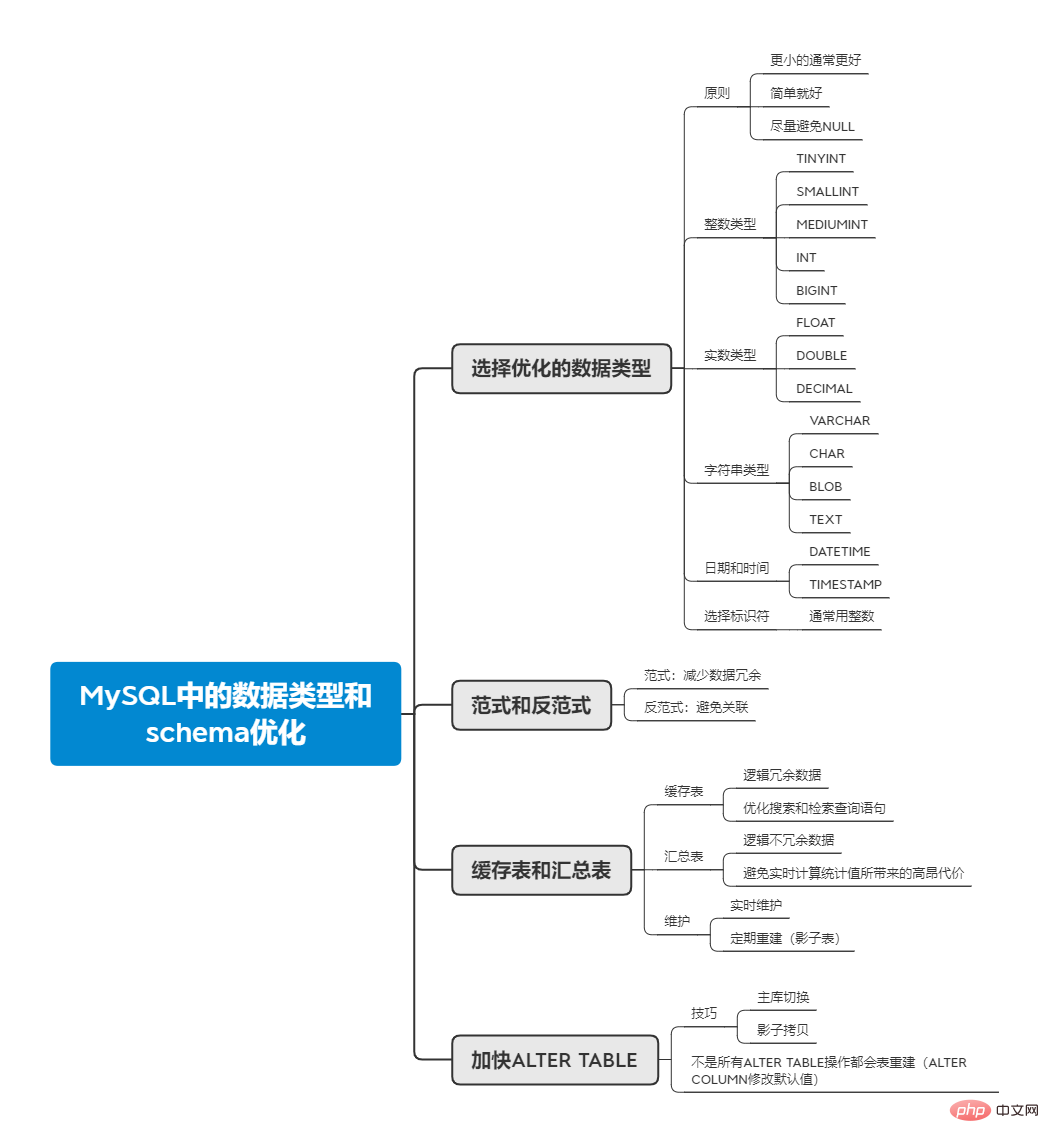
MySQL prend en charge de nombreux types de données, mais comment choisir le bon type de données ? critique pour la performance. Les principes suivants peuvent aider à déterminer les types de données :
Plus petit est généralement mieux
doit être utilisé autant que possible. Le plus petit un type de données capable de stocker correctement les données est suffisant. Cela prendra moins de disque, de mémoire et de cache, et prendra moins de temps à traiter.
Simple, c'est mieux
Lorsque les deux types de données sont capables de stocker un champ, choisissez le plus simple, souvent le meilleur choix. Par exemple, les entiers et les chaînes, car le coût de fonctionnement des entiers est inférieur à celui des caractères, donc lors du choix entre les deux, le choix des entiers entraîne généralement de meilleures performances.
Essayez d'éviter NULL
Quand une colonne peut être NULL, pour MySQL, il faut faire plus en termes d'indexation et de comparaison de valeurs . Bien que l'impact sur les performances ne soit pas important, vous devriez essayer d'éviter de le concevoir comme étant NULL.
En plus des principes ci-dessus, lors du choix d'un type de données, il y a étapes à suivre : déterminez d'abord le grand type approprié, tel que data, string, heure, etc. ; puis sélectionnez le type spécifique. Certains types spécifiques sous les grands types seront abordés ci-dessous. Le premier concerne les nombres, qui ont deux types : les nombres entiers et les nombres réels.
Le type entier et l'espace occupé sont les suivants :
| 整数类型 | 空间大小(bit) |
|---|---|
| TINYINT | 8 |
| SMALLINT | 16 |
| MEDIUMINT | 24 |
| INT | 32 |
| BIGINT | 64 |
La plage que le type entier peut stocker est liée à la taille de l'espace : -2^(N-1) à 2^(N-1)-1, où N est le nombre de chiffres dans la taille de l'espace.
Le type entier a l'attribut facultatif UNSIGNED. Lorsqu'il est déclaré, cela signifie que les nombres négatifs ne sont pas autorisés et la plage de stockage devient : 0 à 2^(N)-1, qui est doublée.
Dans MySQL, vous pouvez également spécifier la largeur des types entiers, tels que INT(1), mais cela a peu d'importance et ne limite pas la plage légale de valeurs. Il peut toujours stocker -2^31. à 2 La valeur de ^31-1 affecte le nombre de caractères affichés par l'outil interactif avec MySQL.
La comparaison des types de nombres réels est la suivante :
| 实数类型 | 空间大小(Byte) | 取值范围 | 计算精度 |
|---|---|---|---|
| FLOAT | 4 | 负数:-3.4E+38~-1.17E-38;非负数:0、1.17E-38~3.4E+38 | 近似计算 |
| DOUBLE | 8 | 负数:-1.79E+308~-2.22E-308;非负数:0、2.22E-308~1.79E+308 | 近似计算 |
| DECIMAL | 与精度有关 | 同DOUBLE | 精确计算 |
Comme le montre ce qui précède, FLOAT et DOUBLE ont tous deux un espace fixe tailles, mais en même temps, parce qu'ils sont L'arithmétique standard à virgule flottante est utilisée, de sorte que les calculs ne peuvent être qu'approximatifs. DECIMAL peut réaliser des calculs précis, mais en même temps, il prend plus de place et consomme plus de temps de calcul.
L'espace occupé par DECIMAL est lié à la précision spécifiée, par exemple, DECIMAL(M,D) :
MySQL stockera le type DECIMAL sous forme de chaîne binaire. Tous les 4 octets stockera 9 nombres. Lorsqu'il y a moins de 9 chiffres, l'espace occupé par le nombre est le suivant :
| 数字个数 | 占用空间(Byte) |
|---|---|
| 1、2 | 1 |
| 3、4 | 2 |
| 5、6 | 3 |
| 7、8 | 4 |
VARCHAR comme Chaîne de longueur variable utilisera 1 ou 2 octets supplémentaires pour enregistrer la longueur de la chaîne. Lorsque la longueur maximale ne dépasse pas 255, seul 1 octet sera enregistré. s'il dépasse 255, 2 octets sont requis. Les scénarios applicables de VARCHAR :
chaîne de longueur fixe. Un espace suffisant est alloué en fonction de la longueur de chaîne définie Scénarios applicables : est de longueur courte ;
binaire, tandis que TEXT est stocké au format caractère . Cela conduit également au fait que les données de type BLOB n'ont pas le concept de jeu de caractères et ne peuvent pas être triées par caractères, tandis que le type TEXT a le concept de jeu de caractères et peuvent être triés par caractères. Les scénarios d'utilisation des deux sont également déterminés par le format de stockage lors du stockage de données binaires, telles que des images, BLOB doit être utilisé, et lors du stockage de texte, tel que des articles, le type TEXT doit être utilisé. 1.4 Types de date et d'heure
La granularité temporelle minimale pouvant être stockée dans MySQL est de secondes. Les types de date couramment utilisés incluent DATETIME et TIMESTAMP.La valeur affichée par TIMESTAMP dépendra du fuseau horaire, ce qui signifie que la valeur interrogée dans différents fuseaux horaires sera différente. En plus des différences énumérées ci-dessus, TIMESTAMP possède également un attribut spécial lors de l'insertion et de la mise à jour, si la valeur de la première colonne TIMESTAMP n'est pas spécifiée, la valeur de cette colonne sera définie sur l'heure actuelle.
Pendant le processus de développement, nous devrions essayer d'utiliser TIMESTAMP autant que possible, principalement parce que sa taille d'espace n'est que la moitié de celle de DATETIME et que son efficacité spatiale est plus élevée.
Et si nous voulons stocker la date et l'heure avec une précision de quelques secondes plus tard ? Puisque MySQL ne le fournit pas, nous pouvons utiliser BIGINT pour stocker les horodatages au niveau micro, ou utiliser DOUBLE pour stocker la partie décimale après quelques secondes.
De manière générale, les entiers sont le meilleur choix pour les identifiants, principalement parce qu'ils sont simples, rapides à calculer et peuvent utiliser AUTO_INCREMENT.
En termes simples, le paradigme est le niveau d'une certaine norme de conception à laquelle se conforme la structure d'une table de données. Dans la première forme normale, les attributs sont indissociables. Les tables construites par le système SGBDR actuel sont toutes conformes à la première forme normale. La deuxième forme normale élimine la dépendance partielle des attributs non primaires à l'égard des codes (qui peuvent être compris comme des clés primaires). La troisième forme normale élimine la dépendance transitive des attributs non primaires aux codes. Pour une introduction spécifique, vous pouvez lire cette réponse sur Zhihu (https://www.zhihu.com/question/24696366/answer/29189700) Base de données
StricteNormalisée, chaque donnée de fait apparaîtra et n'apparaîtra qu'une seule fois, il n'y aura pas de redondance des données , les avantages que cela peut apporter sont :
Mais comme les données sont dispersées dans différentes tables, les tables doivent être liées lors de l'interrogation. L'avantage de anti-paradigme est que n'a pas besoin d'être associé et les données sont stockées de manière redondante.
Dans les applications pratiques, une normalisation complète ou une dénormalisation complète ne se produira pas. Il est souvent nécessaire de mélanger la normalisation et la dénormalisation. Concernant la conception de bases de données, j'ai vu ce paragraphe sur Internet et ça se sent.
La conception de bases de données doit être divisée en trois domaines :
Premier domaine : Au début de la conception de bases de données, l'importance des paradigmes n'a pas encore été profondément comprise. La conception anti-paradigme qui apparaît à ce moment-là posera généralement des problèmes.
Deuxième niveau : au fur et à mesure que vous rencontrez des problèmes et que vous les résolvez, vous comprenez progressivement les véritables avantages du paradigme, afin de pouvoir concevoir rapidement une base de données peu redondante et très efficace.
Le troisième domaine : Après N années de formation, vous découvrirez certainement les limites du paradigme. À ce stade, brisez le paradigme et concevez une partie anti-paradigme plus raisonnable.
Les paradigmes sont comme les mouvements des arts martiaux. Les débutants qui essaient de ne pas suivre les mouvements ne mourront que dans l'embarras. Après tout, les astuces sont l’essence résumée par les maîtres. Au fur et à mesure que vos arts martiaux s'améliorent et que vous maîtrisez les mouvements, vous découvrirez inévitablement les limites des mouvements et vous les oublierez ou créerez les vôtres.
Tant que vous travaillez dur et endurez encore quelques années, vous pouvez toujours atteindre le deuxième état, et vous aurez toujours le sentiment que le paradigme est un classique. À l’heure actuelle, ceux qui peuvent rapidement dépasser les limites du paradigme sans trop s’appuyer sur le paradigme sont naturellement des experts.
En plus de l'anti-paradigme évoqué ci-dessus, pour stocker les données redondantes dans la table, on peut également créer une table récapitulative totalement indépendante ou Mettez la table en cache pour répondre aux besoins de récupération.
Table de cache fait référence à une table qui stocke des données pouvant être obtenues à partir d'autres tables du schéma, c'est-à-dire des données logiquement redondantes. Le tableau récapitulatif fait référence au stockage de données non redondantes calculées en agrégeant les données à l'aide d'instructions telles que GROUP BY.
Les tables de cache peuvent être utilisées pour optimiser les instructions de requête de recherche et de récupération Les techniques qui peuvent être utilisées ici incluent l'utilisation de différents moteurs de stockage pour les tables de cache. Par exemple, la table principale utilise InnoDB, tandis que. la table de cache peut utiliser MyISAM pour obtenir une empreinte d'index plus petite. Vous pouvez même placer la table de cache dans un système de recherche spécialisé, tel que Lucene.
Le tableau récapitulatif vise à éviter le coût élevé du calcul des valeurs statistiques en temps réel Le coût vient de deux aspects. Le premier est que la plupart des données du tableau doivent être utilisées. être analysé, et l'autre consiste à créer un index spécifique. L'index aura un impact sur l'opération UPDATE. Par exemple, pour interroger le nombre de moments WeChat au cours des dernières 24 heures, vous pouvez analyser l'intégralité du tableau toutes les heures et écrire un enregistrement dans le tableau récapitulatif après les statistiques. Lors de l'interrogation, il vous suffit d'interroger les 24 derniers enregistrements du résumé. table au lieu de each. Lors de chaque requête, la table entière est analysée à la recherche de statistiques.
Lors de l'utilisation de tables de cache et de tables récapitulatives, nous devons décider s'il faut maintenir les données en temps réel ou reconstruire périodiquement, en fonction de nos besoins. Par rapport à la maintenance en temps réel, une reconstruction régulière peut économiser plus de ressources et entraîner moins de fragmentation des tables. Lors de la reconstruction, nous devons encore nous assurer que les données sont disponibles pendant le fonctionnement, ce qui doit être réalisé via la "table fantôme". Créez une table fantôme derrière la table réelle. Après avoir rempli les données, changez la table fantôme et la table d'origine via une opération de renommage atomique.
Lorsque MySQL effectue l'opération ALTER TABLE, il crée souvent une nouvelle table, puis récupère les données de l'ancienne table et les insère dans la nouvelle table, puis le supprime les anciennes tables. Si la table est volumineuse, cela prendra beaucoup de temps et entraînera une interruption du service MySQL. Afin d'éviter une interruption de service, vous pouvez généralement utiliser deux techniques :
Mais Toutes les opérations ALTER TABLE ne provoqueront pas une reconstruction de table Par exemple, lors de la modification de la valeur par défaut d'un champ, l'utilisation de MODIFY COLUMN entraînera une reconstruction de table, tandis que l'utilisation de ALTER COLUMN. will Aucune reconstruction de table n'est effectuée et l'opération est très rapide. En effet, lorsque ALTER COLUMN modifie la valeur par défaut, il modifie directement le fichier .frm de la table existante (qui stocke la valeur par défaut du champ) sans reconstruire la table.
Plus de recommandations d'apprentissage gratuites connexes : tutoriel MySQL(vidéo)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



