

Comprendre la technologie Checkpoint d'InnoDB

La colonne
tutoriel mysql amène tout le monde à comprendre la technologie Checkpoint d'InnoDB.

En une phrase, La technologie Checkpoint consiste à vider les pages sales du pool de cache sur le disque à un moment donné
Des problèmes rencontrés ?
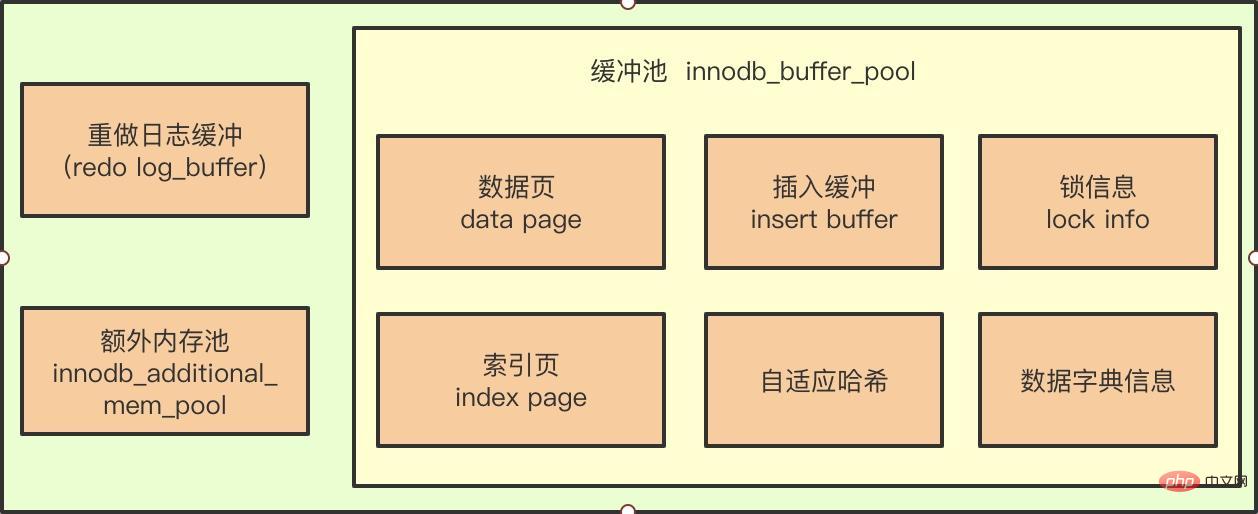
Nous savons tous que l'émergence du pool de mémoire tampon vise à résoudre l'écart entre la vitesse du processeur et celle du disque, de sorte que nous n'ayons pas besoin d'effectuer des opérations d'E/S sur disque lors de la lecture et écrire la base de données. Avec le pool de mémoire tampon, toutes les opérations de page sont d'abord effectuées dans le pool de mémoire tampon.
Par exemple, dans une instruction DML, lors de l'exécution d'une opération de mise à jour ou de suppression de données, l'enregistrement dans la page du pool de mémoire tampon est modifié à ce moment-là, car les données de la page du pool de mémoire tampon sont plus récentes que celles de la page du pool de mémoire tampon. le disque, la page à ce moment est appelée page sale.
Quoi qu'il en soit, les données de la page mémoire après l'assemblée générale doivent être renvoyées sur le disque. Plusieurs problèmes sont impliqués ici :
- Si une page change à chaque fois, la page change. la nouvelle page sera Si la version de la page est vidée sur le disque, alors cette surcharge est très importante
- Si les données chaudes sont concentrées dans certaines pages, les performances de la base de données deviendront très mauvaises
- Si le tampon esclave Un temps d'arrêt s'est produit lorsque le pool a vidé la nouvelle version de la page sur le disque et que les données n'ont pas pu être récupérées
Write Ahead Log (journal d'écriture anticipée)
La politique WAL a résolu le problème de rafraîchissement. Il s'agit d'une série de technologies utilisées dans les systèmes de bases de données relationnelles pour fournir l'atomicité et la durabilité (deux des propriétés ACID).
Le point central de la stratégie WAL est
redo log Chaque fois qu'une transaction est soumise, redo log (redo log) est d'abord écrit, puis la page de données du pool de tampons est modifiée, afin que lorsqu'une transaction se produit En cas de panne de courant, le système peut continuer à fonctionner après le redémarrage
Principe du mécanisme de politique WAL
InnoDB maintient un journal redo pour garantir que les données ne sont pas perdues . Avant que la page de données du pool de mémoire tampon ne soit modifiée, le contenu modifié doit être enregistré dans le journal redo et le journal redo doit être vidé sur le disque avant la page de données correspondante. Il s'agit de la stratégie WAL.
Lorsqu'une panne se produit et que les données de la mémoire sont perdues, InnoDB restaurera les pages de données du pool de tampons à l'état d'avant le crash en rejouant le journal redo lors du redémarrage.
Checkpoint
Il va de soi qu'avec la stratégie WAL, nous pouvons nous asseoir et nous détendre. Mais le problème apparaît à nouveau dans le redo log :
- Le redo log ne peut pas être infini, et nous ne pouvons pas stocker indéfiniment nos données en attendant d'être actualisées sur le disque ensemble
- Lorsque la base de données est inactif et restauré, si le journal de rétablissement est trop volumineux, le coût de récupération sera également très élevé
Donc, afin de résoudre les performances de rafraîchissement des pages sales, quand et dans quelles circonstances devrait être sale les pages doivent-elles être actualisées ? L'actualisation utilise la technologie Checkpoint.
Objectif de Checkpoint
1. Raccourcir le temps de récupération de la base de données
Lorsque la base de données est inactive et restaurée, il n'est pas nécessaire de refaire toutes les informations du journal. Parce que la page de données avant Checkpoint a été renvoyée sur le disque. Restaurez simplement le journal redo après le point de contrôle.
2. Lorsque le pool de tampons n'est pas suffisant, videz les pages sales sur le disque.
Lorsque l'espace du pool de tampons est insuffisant, la page la moins récemment utilisée débordera en fonction de l'algorithme LRU. Si cette page est une page sale, vous devez donc forcer un point de contrôle à vider la page sale, c'est-à-dire la nouvelle version de la page, sur le disque.
3. Lorsque le journal de rétablissement n'est pas disponible, actualisez les pages sales
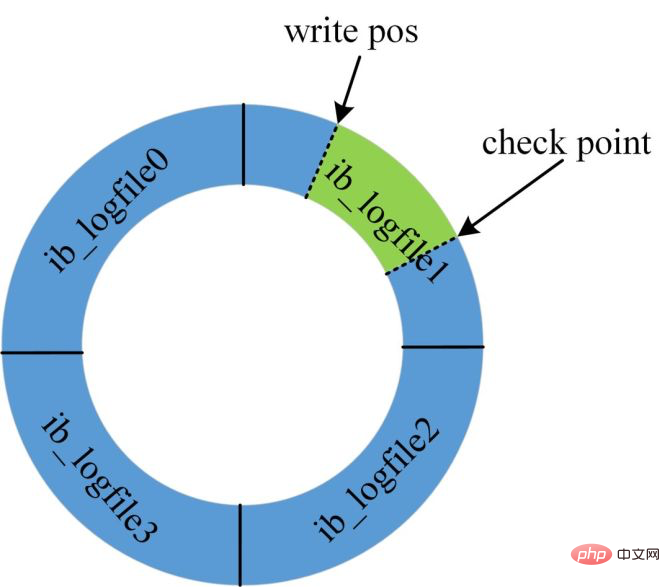
Comme le montre la figure, le journal de rétablissement est indisponible car la base de données actuelle n'est pas disponible pour cela. Les designs sont tous recyclés, donc l'espace n'est pas infini.
Lorsque le journal redo est plein, parce que le système ne peut pas accepter les mises à jour pour le moment, toutes les instructions de mise à jour seront bloquées.
À ce stade, un point de contrôle doit être forcé pour être généré. La position d'écriture doit être poussée vers l'avant et les pages sales dans la plage de poussée doivent être vidées sur le disque.
Type de point de contrôle
Heure à laquelle le point de contrôle se produit, les conditions et la sélection des pages sales sont très complexes.
Combien de pages sales Checkpoint vide-t-il sur le disque à chaque fois ?
D'où Checkpoint obtient-il des pages sales à chaque fois ?
Quand le point de contrôle est-il déclenché ?
Face aux problèmes ci-dessus, le moteur de stockage InnoDB nous fournit deux points de contrôle en interne :
-
Sharp Checkpoint
Lorsque la base de données est arrêtée, toutes les pages sales sont renvoyées sur le disque. Il s'agit de la méthode de travail par défaut. Le paramètre innodb_fast_shutdown=1
-
Fuzzy Checkpoint
À l'intérieur du. Moteur de stockage InnoDB En utilisant ce mode, videz uniquement une partie des pages sales au lieu de vider toutes les pages sales sur le disque
Que se passe-t-il avec FuzzyCheckpoint
-
Master Thread Checkpoint
vide une certaine proportion de pages sur le disque à partir de la liste des pages sales dans le pool de mémoire tampon presque toutes les secondes ou toutes les dix secondes.
Ce processus est asynchrone, c'est-à-dire que le moteur de stockage InnoDB peut effectuer d'autres opérations à ce moment-là, et le fil de requête de l'utilisateur ne sera pas bloqué
-
FLUSH_LRU_LIST Checkpoint
Parce que la liste LRU doit garantir qu'un certain nombre de pages libres peuvent être utilisées, s'il n'y en a pas assez, des pages seront supprimées de la queue. Si les pages supprimées ont des pages sales, ce Checkpoint sera effectué.
Après la version 5.6, ce point de contrôle est placé dans un fil de discussion Page Cleaner séparé, et les utilisateurs peuvent contrôler le nombre de pages disponibles dans la liste LRU via le paramètre innodb_lru_scan_degree. La valeur par défaut est 1024
. -
Async/Sync Flush Checkpoint
fait référence à la situation dans laquelle le fichier de journalisation n'est pas disponible à ce stade, certaines pages doivent être forcées à être renvoyées sur le disque et les pages sales. les pages sont supprimées de la liste des pages sales. La
version 5.6 sélectionnée ne bloquera pas les requêtes des utilisateurs
-
Page sale trop Checkpoint. Autrement dit, le nombre de pages sales est trop important, ce qui oblige le moteur de stockage InnoDB à forcer un point de contrôle.
L'objectif général est de garantir qu'il y a suffisamment de pages disponibles dans le pool tampon.
Il peut être contrôlé par le paramètre innodb_max_dirty_pages_pct. Par exemple, la valeur est de 75, ce qui signifie que lorsque les pages sales dans le pool de tampons occupent 75%, CheckPoint est forcé d'être exécuté
Résumé
En raison de l'écart entre le processeur et le disque, les pages de données du pool de mémoire tampon semblent accélérer les opérations DML de la base de données
Parce que les pages de données du pool de tampons sont cohérentes avec les données du disque. La stratégie WAL (le noyau est le redo log)
En raison du problème de performances de rafraîchissement des pages sales dans le pool de tampons, technologie Checkpoint
InnoDB Afin d'améliorer l'efficacité d'exécution, chaque opération DML n'interagit pas avec le disque pour la persistance. Au lieu de cela, écrivez d'abord le journal de rétablissement via le journal Write Ahead pour garantir la persistance des choses.
Pour les pages sales du pool de mémoire tampon modifiées lors des transactions, le disque sera vidé de manière asynchrone et la disponibilité des pages libres de mémoire et des journaux de rétablissement est garantie grâce à la technologie Checkpoint.
Plus de recommandations d'apprentissage gratuites connexes : tutoriel MySQL(vidéo)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 qu'est-ce que mysql innodb
Apr 14, 2023 am 10:19 AM
qu'est-ce que mysql innodb
Apr 14, 2023 am 10:19 AM
InnoDB est l'un des moteurs de base de données de MySQL. C'est désormais le moteur de stockage par défaut de MySQL et l'une des normes pour les versions binaires de MySQL AB adopte un système d'autorisation à double voie, l'une est une autorisation GPL et l'autre est un logiciel propriétaire. autorisation. InnoDB est le moteur préféré pour les bases de données transactionnelles et prend en charge les tables de sécurité des transactions (ACID) ; InnoDB prend en charge les verrous au niveau des lignes, qui peuvent prendre en charge dans la plus grande mesure la concurrence. Les verrous au niveau des lignes sont implémentés par la couche moteur de stockage.
 Comment MySQL voit le format de ligne InnoDB à partir du contenu binaire
Jun 03, 2023 am 09:55 AM
Comment MySQL voit le format de ligne InnoDB à partir du contenu binaire
Jun 03, 2023 am 09:55 AM
InnoDB est un moteur de stockage qui stocke les données dans des tables sur disque, de sorte que nos données existeront toujours même après l'arrêt et le redémarrage. Le processus réel de traitement des données se produit en mémoire, de sorte que les données du disque doivent être chargées dans la mémoire. S'il traite une demande d'écriture ou de modification, le contenu de la mémoire doit également être actualisé sur le disque. Et nous savons que la vitesse de lecture et d'écriture sur le disque est très lente, ce qui est plusieurs ordres de grandeur différents de la lecture et de l'écriture en mémoire. Ainsi, lorsque nous voulons obtenir certains enregistrements de la table, le moteur de stockage InnoDB doit-il lire. les enregistrements du disque un par un ? La méthode adoptée par InnoDB consiste à diviser les données en plusieurs pages et à utiliser les pages comme unité de base d'interaction entre le disque et la mémoire. La taille d'une page dans InnoDB est généralement de 16.
 Comment gérer l'exception mysql innodb
Apr 17, 2023 pm 09:01 PM
Comment gérer l'exception mysql innodb
Apr 17, 2023 pm 09:01 PM
1. Restaurez et réinstallez MySQL Afin d'éviter d'avoir à importer ces données depuis d'autres endroits, effectuez d'abord une sauvegarde du fichier de base de données de la bibliothèque actuelle (/var/lib/mysql/location). Ensuite, j'ai désinstallé le package Perconaserver5.7, réinstallé l'ancien package 5.1.71 d'origine, démarré le service mysql, et il a demandé Unknown/unsupportedtabletype:innodb et n'a pas pu démarrer normalement. 11050912:04:27InnoDB : initialisation du pool de tampons, taille = 384,0 M11050912:04:27InnoDB : terminé
 Comparaison de sélection du moteur de stockage MySQL : évaluation de l'indice de performance InnoDB, MyISAM et mémoire
Jul 26, 2023 am 11:25 AM
Comparaison de sélection du moteur de stockage MySQL : évaluation de l'indice de performance InnoDB, MyISAM et mémoire
Jul 26, 2023 am 11:25 AM
Comparaison de sélection du moteur de stockage MySQL : évaluation de l'indice de performance InnoDB, MyISAM et mémoire Introduction : Dans la base de données MySQL, le choix du moteur de stockage joue un rôle essentiel dans les performances du système et l'intégrité des données. MySQL fournit une variété de moteurs de stockage, les moteurs les plus couramment utilisés incluent InnoDB, MyISAM et Memory. Cet article évaluera les indicateurs de performances de ces trois moteurs de stockage et les comparera à travers des exemples de code. 1. Moteur InnoDB InnoDB est mon
 Comment résoudre la lecture fantôme dans innoDB dans Mysql
May 27, 2023 pm 03:34 PM
Comment résoudre la lecture fantôme dans innoDB dans Mysql
May 27, 2023 pm 03:34 PM
1. Niveau d'isolement des transactions Mysql Ces quatre niveaux d'isolement, lorsqu'il y a plusieurs conflits de concurrence de transactions, certains problèmes de lecture sale, de lecture non répétable et de lecture fantôme peuvent survenir, et innoDB les résout en mode niveau d'isolement de lecture répétable. de la lecture fantôme, 2. Qu'est-ce que la lecture fantôme ? La lecture fantôme signifie que dans la même transaction, les résultats obtenus en interrogeant la même plage deux fois avant et après sont incohérents, comme le montre la figure. Dans la première transaction, nous exécutons une requête de plage. À l'heure actuelle, il n'y a qu'une seule donnée qui remplit les conditions. Dans la deuxième transaction, il insère une ligne de données et la soumet. Ensuite, lorsque la première transaction est à nouveau interrogée, le résultat obtenu est un de plus que le résultat de. la première requête Data, notez que les première et deuxième requêtes de la première transaction sont toutes deux identiques.
 Expliquez les capacités de recherche en texte intégral InNODB.
Apr 02, 2025 pm 06:09 PM
Expliquez les capacités de recherche en texte intégral InNODB.
Apr 02, 2025 pm 06:09 PM
Les capacités de recherche en texte intégral d'InNODB sont très puissantes, ce qui peut considérablement améliorer l'efficacité de la requête de la base de données et la capacité de traiter de grandes quantités de données de texte. 1) INNODB implémente la recherche de texte intégral via l'indexation inversée, prenant en charge les requêtes de recherche de base et avancées. 2) Utilisez la correspondance et contre les mots clés pour rechercher, prendre en charge le mode booléen et la recherche de phrases. 3) Les méthodes d'optimisation incluent l'utilisation de la technologie de segmentation des mots, la reconstruction périodique des index et l'ajustement de la taille du cache pour améliorer les performances et la précision.
 Comment utiliser les moteurs de stockage MyISAM et InnoDB pour optimiser les performances de MySQL
May 11, 2023 pm 06:51 PM
Comment utiliser les moteurs de stockage MyISAM et InnoDB pour optimiser les performances de MySQL
May 11, 2023 pm 06:51 PM
MySQL est un système de gestion de bases de données largement utilisé et différents moteurs de stockage ont des impacts différents sur les performances des bases de données. MyISAM et InnoDB sont les deux moteurs de stockage les plus couramment utilisés dans MySQL. Ils ont des caractéristiques différentes et une mauvaise utilisation peut affecter les performances de la base de données. Cet article explique comment utiliser ces deux moteurs de stockage pour optimiser les performances de MySQL. 1. Moteur de stockage MyISAM MyISAM est le moteur de stockage le plus couramment utilisé pour MySQL. Ses avantages sont une vitesse rapide et un petit espace de stockage. MonISA
 Conseils et stratégies pour améliorer les performances de lecture du moteur de stockage MySQL : analyse comparative de MyISAM et InnoDB
Jul 26, 2023 am 10:01 AM
Conseils et stratégies pour améliorer les performances de lecture du moteur de stockage MySQL : analyse comparative de MyISAM et InnoDB
Jul 26, 2023 am 10:01 AM
Conseils et stratégies pour améliorer les performances de lecture du moteur de stockage MySQL : Analyse comparative de MyISAM et InnoDB Introduction : MySQL est l'un des systèmes de gestion de bases de données relationnelles open source les plus couramment utilisés, principalement utilisé pour stocker et gérer de grandes quantités de données structurées. Dans les applications, les performances de lecture de la base de données sont souvent très importantes, car les opérations de lecture constituent le principal type d'opérations dans la plupart des applications. Cet article se concentrera sur la façon d'améliorer les performances de lecture du moteur de stockage MySQL, en se concentrant sur une analyse comparative de MyISAM et InnoDB, deux moteurs de stockage couramment utilisés.
